CODEIE: Large Code Generation Models are Better Few-Shot Information Extractors
- 写在最前面
- 汇报
- 研究背景
- 命名实体识别(NER)和关系抽取(RE)
- 相关工作
- 作者动机
- 研究方案
- 实例
- 研究方案
- 方案预览
- 实验
- 数据集和基线模型
- 评价指标
- 实验方案对比
- 1、(表3)LLMs (GPT-3和Codex)在少样本设置下,比中等大小的模型(T5和UIE)实现了优越的性能。
- 2、比较不同提示设计的效果
- 3、控制变量对比实验
- 第一个是格式一致性Format Consistency
- 第二个是模型忠实度
- 第三个,细粒度性能Fine-grained Performance
- 研究总结
- 未来的工作可考虑:
- 补充
- 条件困惑度
写在最前面
这次该我汇报啦
许愿明天讲的顺利,问的都会
汇报
CODEIE:代码生成大模型能更好的进行少样本信息提取这项工作
接下来我将从这四个板块展开介绍
研究背景
这篇论文于2023年5月发布在arXiv,随后9月发表在ACL-NLP顶刊。其作者来自复旦大学和华师大学。

命名实体识别(NER)和关系抽取(RE)
首先,让我们了解一些自然语言处理(NLP)的背景知识。
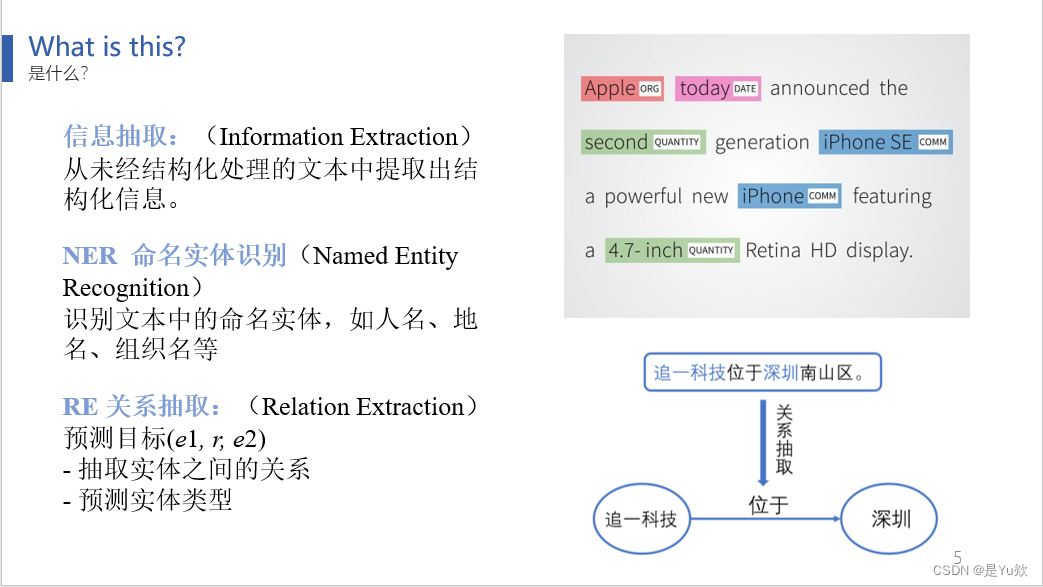
信息抽取的目标是从未经结构化处理的文本中提取出结构化信息。这个领域涵盖了各种任务,包括命名实体识别(NER)和关系抽取(RE)。
NER用于识别文本中的命名实体,例如人名、地名和组织名,
而RE则用于提取文本中实体之间的关系信息。
相关工作
- 为了在一个统一框架内处理这些不同的任务,近期的研究建议将输出结构线性化为非结构化字符串,并采用
序列生成模型来解决信息抽取(IE)任务。
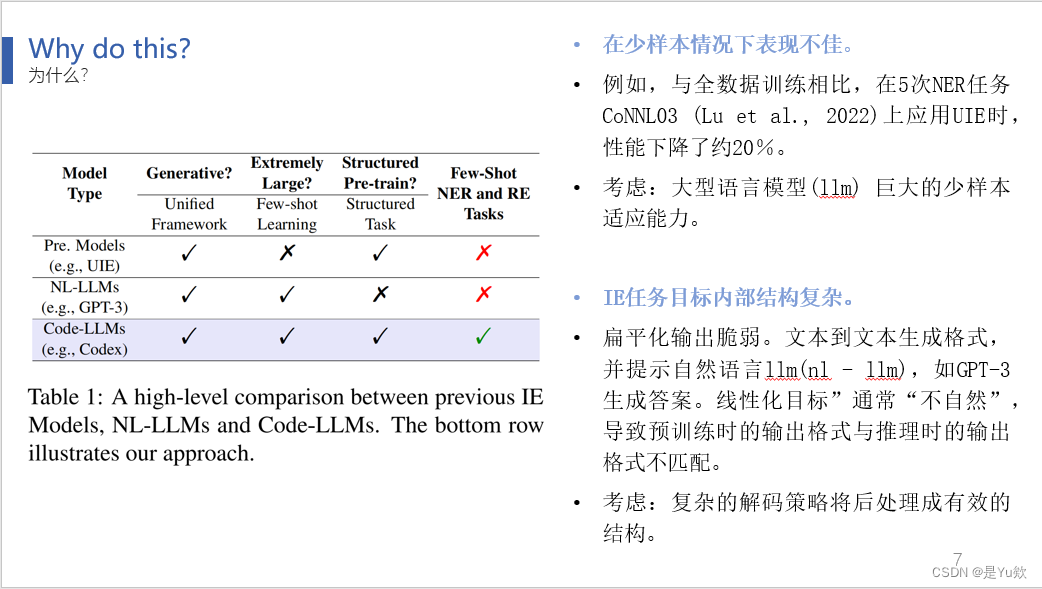
尽管这种线性化方法在具有充足训练数据的情况下取得了良好的成果,但在少样本情况下性能不佳。 - 鉴于
大型语言模型具有强大的少样本学习能力,本论文旨在充分利用它们来解决少样本IE任务,特别是NER和RE任务。
通常,对于文本分类等NLP任务,以前的工作将任务重新构建为文本到文本生成的形式,并利用自然语言-llm(如GPT-3)来生成答案。 - 然而,由于IE任务具有复杂的内部结构,以往的线性化方法的输出结构通常显得不够自然,导致了预训练时的输出格式与推理时的输出格式不匹配。
因此,在使用这些扁平化方法时,通常需要复杂的解码策略来将输出后处理为有效的结构。
作者动机
总结一下为什么作者选择了这一方法。
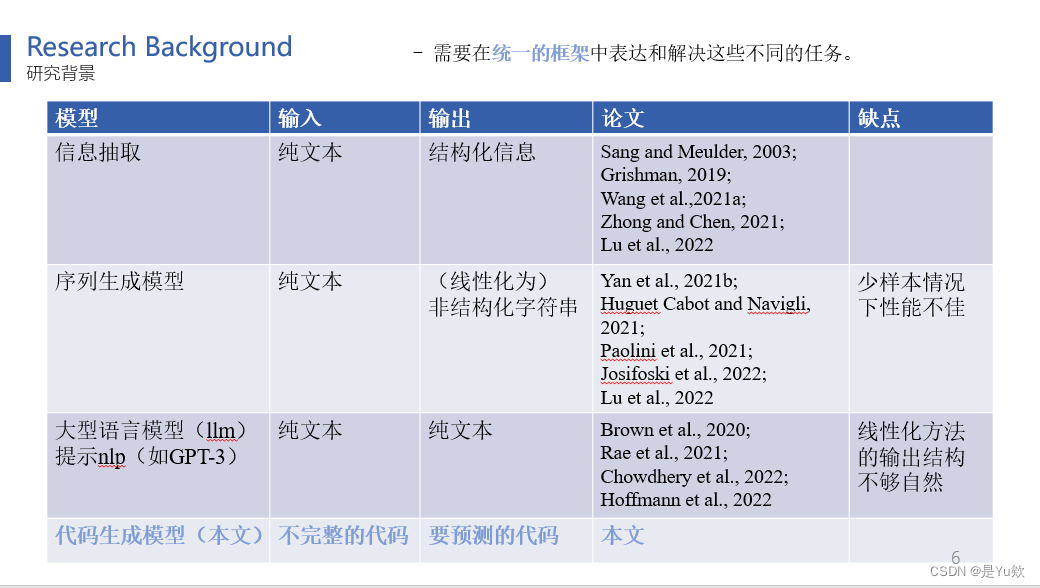
表1总结了用于IE任务的中等规模模型、NL-LLM和Code-LLM之间的高层次差异。
此前的工作未能在一个统一的框架下充分利用大型模型进行少样本学习,特别是在处理结构化任务方面。这篇论文的模型成功弥补了这两个限制。
为什么这两个限制会对结果产生重大影响呢?
首先,大型模型具有适应少样本数据的能力
其次,由于线性输出不够自然,通常需要更复杂的解码策略。
研究方案
因此,这篇论文提出了一种全新的思路,通过使用带有结构化代码风格提示的Code-LLM,来弥合预训练和推理阶段之间的输出差异,从而实现了IE任务的统一框架并获得更出色的结果。
这一方法的核心思想是将这两个IE任务框架化为代码生成任务,并借助代码-LLM中的编码丰富结构化代码信息,从而使这些IE任务有更好的结果。

实例
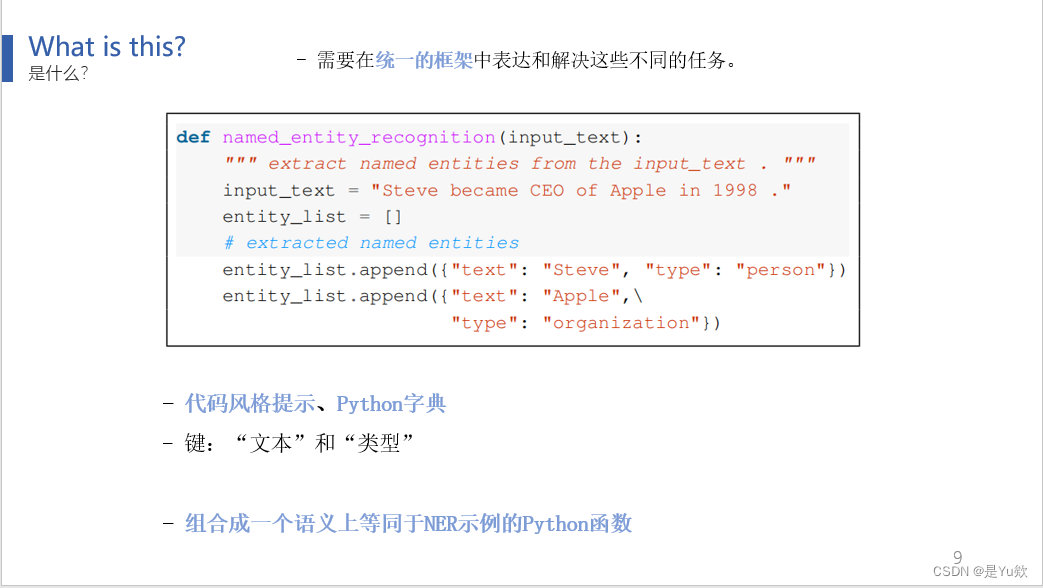
这是一个示例:
通过代码风格提示和Python字典的键,如“文本”和“类型”,可以组合它们成一个与NER(命名实体识别)示例等价的Python函数。
研究方案
下面我们对具体方案展开介绍。
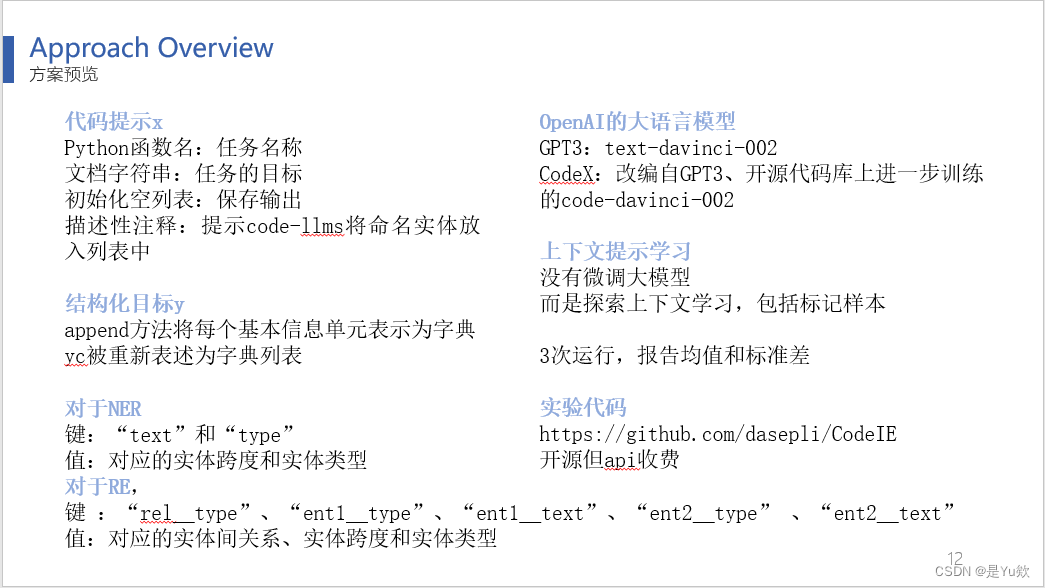
方案预览

论文涵盖了NER和RE两项任务,
首先将原始IE任务转化为代码样式,其中(换PPT)Python函数名称表示任务,文档字符串说明任务目标,初始化空列表用于保存输出,描述性注释提供了提示以将命名实体放入列表中。(换PPT)这些元素被组合为“代码提示x”。
“结构化目标y”,将每个基本信息单元(NER的一对实体和RE的三元组)表示为Python字典,yc为字典列表。
对于NER任务,键包括“text”和“type”,值分别是实体跨度和实体类型。
对于RE任务,键包括实体类型和关系类型。然后,这些输入被传递给代码生成大模型,并得到输出。
左侧显示的文字是对前面图表的简明描述。
此外,GPT-3和CodeX都是OpenAI的模型,而CodeX是在GPT-3的基础上进行改进的,这两者有着相同的起源。
由于大型模型API的黑盒特性,无法对这些大型模型进行微调,因此这篇论文致力于探索上下文学习的方法,包括使用标记样本。
上下文提示学习是如何具体体现的呢?在这篇论文中,任务被转化为代码表示,然后将它们连接在一起,构建了一个上下文演示,其中包括x1y1x2y2直到xnyn,最后有一个准备预测的xc。这个上下文被输入到模型中,生成输出yc,其格式与y1y2yn相似,通常保持了Python语法,容易还原成原始结构。
鉴于少样本训练容易受到高方差的影响,该论文为每个实验采用不同的随机种子运行了三次,并报告了度量指标的均值和标准差。
这篇论文已经开源了这项研究的代码,如果有兴趣的朋友可以前去查看。
实验
接下来,我们对这篇文章的实验部分进行梳理
数据集和基线模型
在实验结果部分,论文涵盖了七个NLP任务的数据集,采用了中等规模的预训练模型作为基线

评价指标
评价指标是常规的NER和RE任务性能度量指标。
实体的偏移量和实体类型与黄金实体匹配,那么实体跨度预测就是正确的。
如果关系类型正确且其实体对应的偏移量和类型正确,则关系预测是正确的。

实验方案对比
结果表明:
1、(表3)LLMs (GPT-3和Codex)在少样本设置下,比中等大小的模型(T5和UIE)实现了优越的性能。
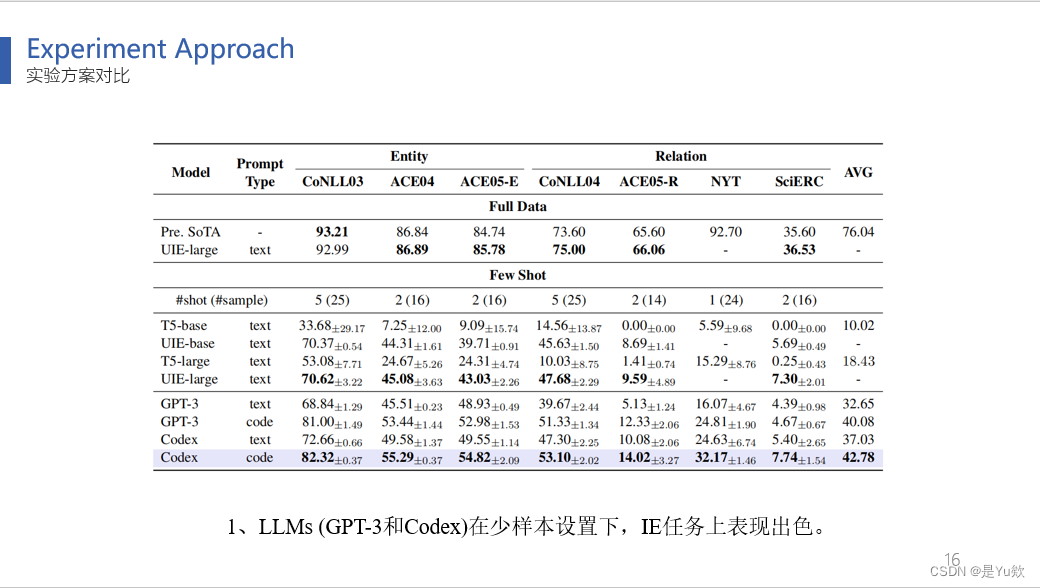
2、比较不同提示设计的效果
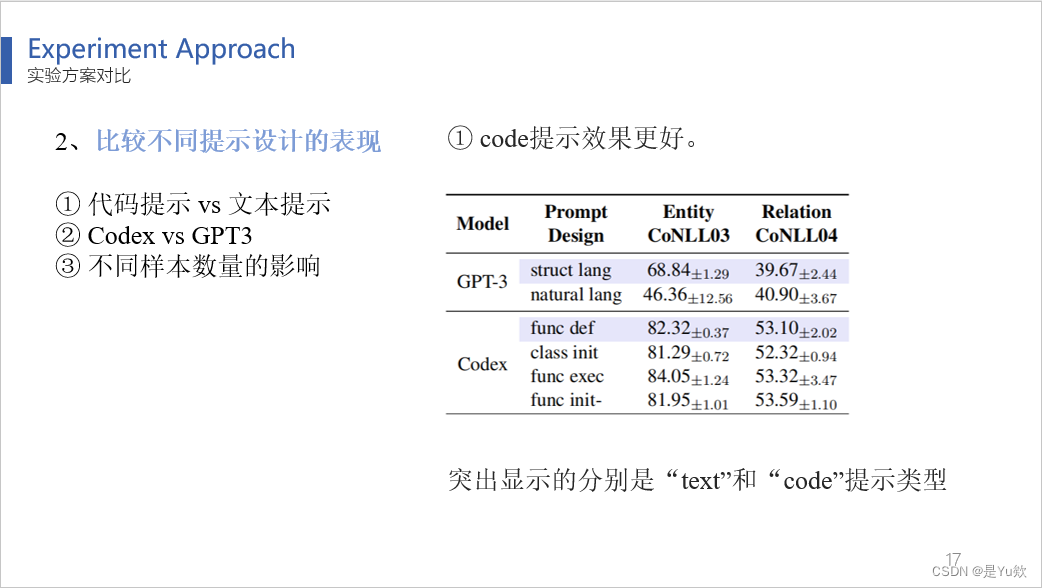
(表4)突出显示的分别是“text”和“code”提示类型,code提示效果更好。
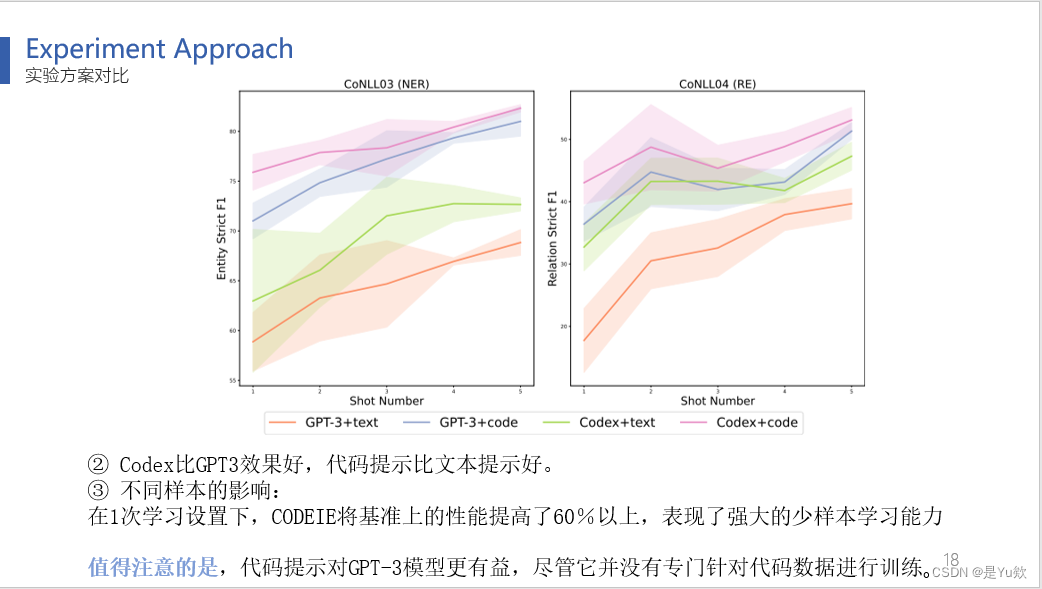
(图3)Codex胜过GPT-3,代码提示优于文本提示。Codex比GPT3效果好,代码提示比文本提示好。
并且在1次学习设置下,CODEIE将基准上的性能提高了60%以上,表现了强大的少样本学习能力
值得注意的是,代码提示对GPT-3更有益,尽管它并没有专门针对代码数据进行训练。
3、控制变量对比实验
作者进行了一些控制变量的对比实验,以探讨导致模型性能优越的因素。
第一个是格式一致性Format Consistency
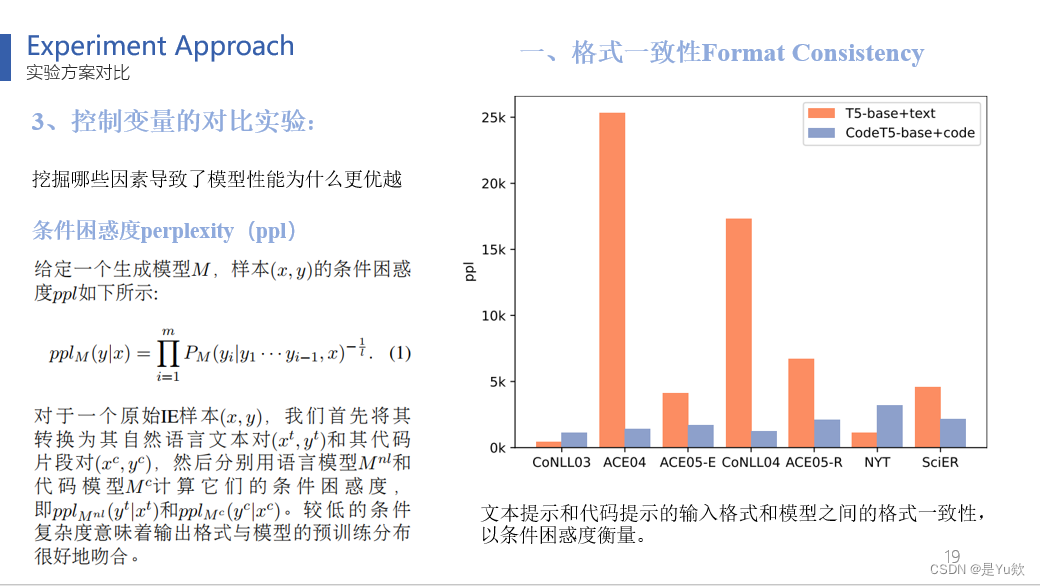
介绍下条件困惑度,这是一种衡量生成的文本在给定条件下生成文本的可预测性,也就是在给定上下文前缀的条件下,模型生成下一个字符的概率的准确性的度量。
较低的条件困惑度值表示生成的文本更符合所期望的条件。
图4,在7个数据集上,文本提示和代码提示的输入格式和模型之间的条件困惑度。
第二个是模型忠实度
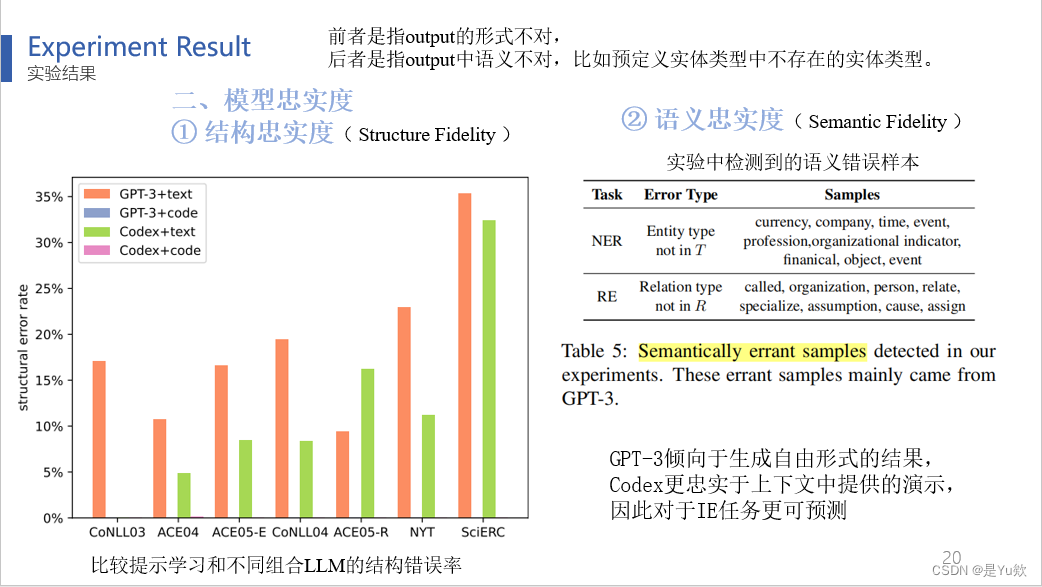
分为两个指标:
1、一个是结构忠实度Structure Fidelity,顾名思义是生成文本的结构
图5:比较提示学习和不同组合LLM的结构错误率,output的形式不对
2、一个是语义忠实度Semantic Fidelity,生成文本的语义忠诚度
表5:实验中检测到的语义错误样本,output中语义不对,比如预定义实体类型中不存在的实体类型。
结果表明,GPT-3倾向于生成自由形式的结果,Codex更忠实于上下文中提供的演示,因此对于IE任务更可预测
第三个,细粒度性能Fine-grained Performance
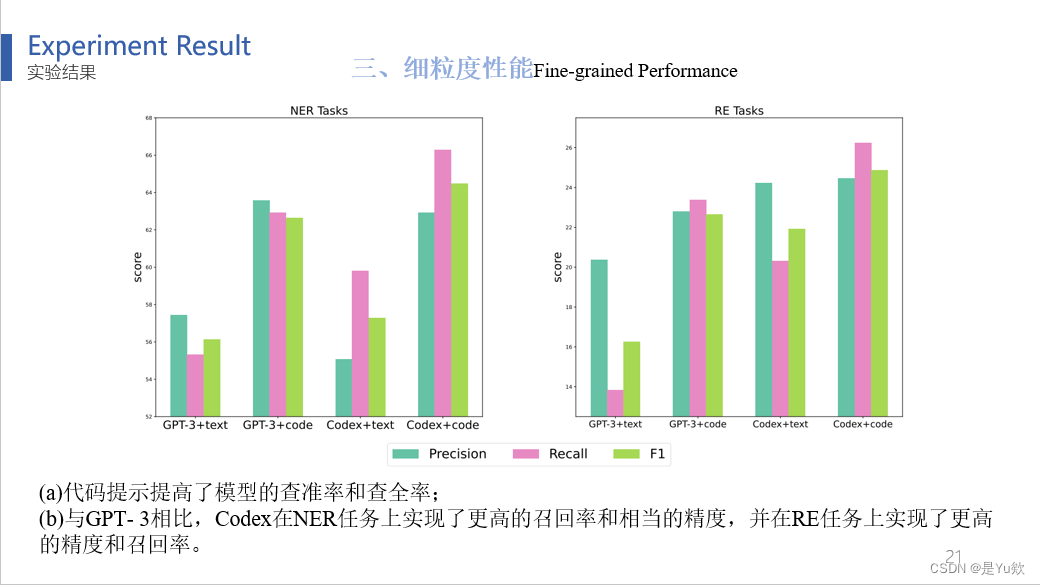
结果表明(a)代码提示提高了模型的查准率和查全率;
(b)与GPT- 3相比,Codex在NER任务上实现了更高的召回率和相当的精度,并在RE任务上实现了更高的精度和召回率。
研究总结

最后对这篇论文进行总结。
这篇论文提出的方法相对于其他顶刊论文来说,更加简单有效。它通过领域迁移,将文本生成转化为代码生成,设计上下文提示学习以替代仅提供API的大型模型微调。
未来的工作可考虑:
考虑设计更良好的代码格式提示。
目前是在黑盒模型GPT3和Codex上进行实验,之后可以在开源模型上进一步微调。
以及,在非英文数据集(如中文数据集)上探索本文模型的实用性。

这就是《CODEIE: Large Code Generation Models are Better Few-Shot Information Extractors》的主要内容和关键观点。感谢大家的聆听。
补充
条件困惑度
条件复杂度是一种用于评估模型在给定上下文下生成下一个标记的难度和质量的度量,
模型的目标是尽可能减少条件复杂度,以获得更高质量的生成结果。
语言模型的条件复杂度和代码模型的条件复杂度通常都基于困惑度(Perplexity)来计算,但有一些细微的差异,具体取决于模型的类型和应用领域。
1. 语言模型的条件复杂度:
语言模型的条件复杂度用于评估模型在给定上下文下生成下一个单词的质量。它通常采用以下方式计算:
- 给定一组文本数据(通常是测试集),将每个句子划分为多个标记(例如,单词或字符)。
- 模型接受一个前缀文本(通常是句子的一部分)作为输入,并尝试生成下一个标记。
- 通过将模型生成的标记与实际下一个标记进行比较,计算困惑度。困惑度通常使用交叉熵损失来计算。
数学表达式如下:
P e r p l e x i t y = exp ( − 1 N ∑ i = 1 N log P ( w i ∣ w 1 , w 2 , … , w i − 1 ) ) Perplexity = \exp\left(-\frac{1}{N} \sum_{i=1}^{N} \log P(w_i | w_1, w_2, \ldots, w_{i-1})\right) Perplexity=exp(−N1i=1∑NlogP(wi∣w1,w2,…,wi−1))
其中:
- P ( w i ∣ w 1 , w 2 , … , w i − 1 ) P(w_i | w_1, w_2, \ldots, w_{i-1}) P(wi∣w1,w2,…,wi−1)表示在给定前缀 w 1 , w 2 , … , w i − 1 w_1, w_2, \ldots, w_{i-1} w1,w2,…,wi−1的条件下,模型生成标记 w i w_i wi的概率。
- N N N表示测试集中的标记总数。
2. 代码模型的条件复杂度:
对于代码生成模型,条件复杂度的计算方式与语言模型类似,但有一些不同之处:
- 给定一组源代码或代码片段,将其分解为标记(例如,编程语言中的令牌或代码块)。
- 模型接受前缀代码或上下文,并尝试生成下一个代码标记。
- 使用交叉熵或其他损失函数计算条件复杂度,以评估模型在给定上下文下生成下一个代码标记的质量。
计算方式在代码模型中的具体实施可能因任务和模型架构而异,但基本原理与语言模型相似。