文|李大元 (花名:达远)
Kusion 项目负责人

来自蚂蚁集团 PaaS 核心团队,PaaS IaC 基础平台负责人。
本文 4331 字 阅读 11 分钟
PART. 1 后云原生时代
距离 Kubernetes 第一个 commit 已经过去八年多了,以其为代表的云原生技术早已不再是什么新技术,而是现代化应用的“标配”。现代化应用依赖的基础服务远不止 Kubernetes 一种,稍微复杂点的应用往往会同时使用到 Kubernetes 生态云原生技术、IaaS 云服务、企业内部自建系统等各种异构基础设施,可能还会有多云、混合云的部署需求,我们已经进入到了 ”后云原生时代”,只针对 Kubernetes 的运维工具早已不能满足我们的诉求。
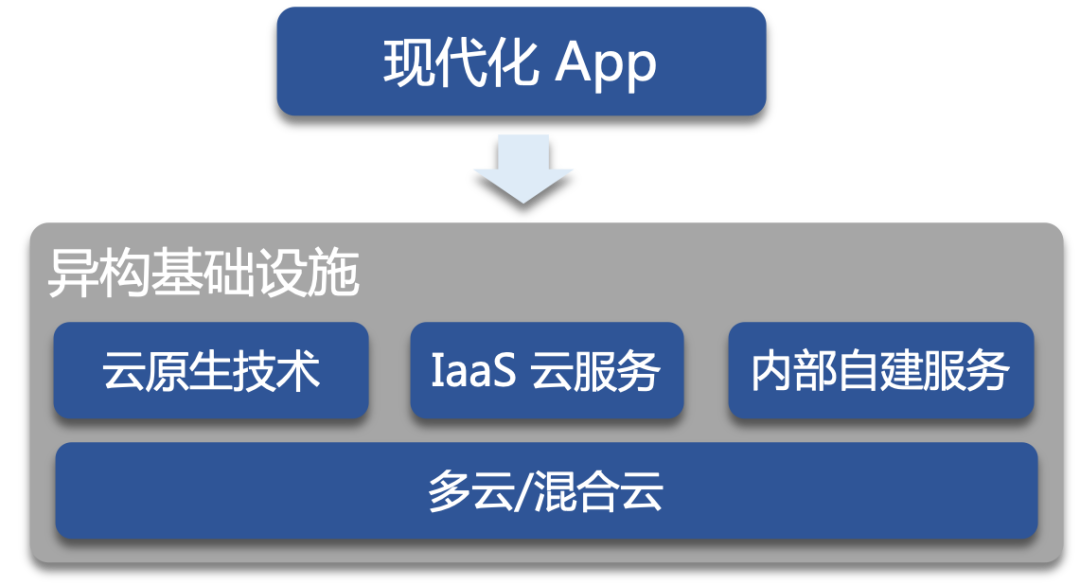
更复杂的是,在企业内部,这些服务一般是由不同团队维护的,一次规模化运维需要多个团队的成员互相配合才能完成,但是 App Dev、Platform Dev、SRE 各个团队之间缺少高效的协作方式。技术自身的复杂性加上低效的团队协作,使得 “后云原生时代” 的规模化运维难度有了指数级的提高。
PART. 2 规模化运维的问题一直都在
复杂异构基础设施的规模化运维,这并不是后云原生时代特有的问题,自分布式系统诞生以来,一直都是一个难题,只是在后云原生时代,这个问题变得更加困难。十多年前业界提出了 DevOps 理念,无数企业基于此理念构建了自己的 DevOps 平台,希望解决此问题,但在实际落地的过程中往往不尽人意,Dev 团队和 Ops 团队之间如何合作?职责如何划分?几十人的平台团队,如何支持几万工程师的运维诉求?底层基础设施复杂多样,能力日新月异,如何快速让一线 Dev 享受到技术红利?这些问题一直没有得到很好的解决,最近又有人提出了 DevOps 已死,Platform Engineering 才是未来的说法。抛开概念定义,无论是 DevOps 还是 Platform Engineering,本质上都是企业规模化运维这同一命题下的不同理念,我们更需要的是一个符合技术发展趋势,能解决当前问题的解决方案。
PART. 3 传统架构不再适用
在传统的运维思路中,解决上述问题的方法一般是构建一个 PaaS 平台,例如我们早期的蚂蚁 PaaS 平台,他是一个 Web 控制台,有 UI 界面,用户(通常是 App Dev 或 SRE)通过 UI 交互可以完成诸如发布、重启、扩缩容等操作。在技术实现上大体可以分为三部分,一个前端系统,提供用户交互的能力,作为系统入口;中间是一个后端系统,对接各个基础设施;底层是各个基础设的 API。这种架构运行了近十年,一直运行的很好,既有用户友好的交互界面,又可以屏蔽基础设施复杂性,而且各个团队之间还职责分明,但是到了如今后云原生时代,这种架构不再适用,暴露出有两个致命缺点, “费人” 、 “费时” 。
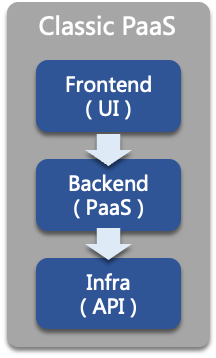
举一个常见的例子,网络团队为其负责的 Loadbalancer(负载均衡器)开发了一种新的负载算法,需要提供给用户使用。
在上述架构下,整个工作流程是这个样子:
1.网络团队开发好能力,提供出 API;
2.PaaS 后端通过编码对接底层 API,进行互联互通,屏蔽复杂性,提供面向用户的更高级别 API;
3.PaaS 前端根据新功能修改 UI,利用后端 API 把能力透出给最终用户。
这里存在一个问题,即使一个再小的功能,也需要 PaaS 后端和前端修改代码,整个流程下来最快也要一周才能上线,而且涉及的基础设施团队越多,效率越低。这个问题在十年前并不算是一个问题,但是在今天就是一个很大的问题,一个后云原生时代的现代化应用,使用三个云原生技术(Kubernetes + Istio + Prometheus),两个云服务(Loadbalancer + Database),一个内部自建服务,已经是一个很常见的形态了,复杂应用只会依赖的更多。如果每个基础设施都由 PaaS 团队硬编码对接一遍,PaaS 团队的人再扩大十倍也不够用。
“费人”讲完了,我们再看看“费时”的问题。上面例子里的一个小功能,需要进行两次跨团队的协作,一次基础设施和 PaaS 后端,另一次是 PaaS 后端与 PaaS 前端。团队协作是一个很难的问题,有时候比技术本身还要难。应用的架构已经很复杂了,如果要做一次规模化运维,一次运维 100 个应用,这要和多少个团队沟通协作?要花费多少时间?没有好的协作机制,这就变成了一个不可能完成的任务。
PART. 4 探索与实践
我们在蚂蚁集团内部进行了近两年的探索,kustomize、helm、argoCD、Terraform 这些常见的工具我们都实践过,甚至还为一些工具自研了一些辅助系统,但结果并不尽人意。这些工具要么太局限于 Kubernetes 生态,运维不了其他类型的基础设施,要么就是支持了异构基础设施,但对于 Kubernetes 生态支持的不友好,无法发挥出云原生技术的优势,而且只是运维工具的升级对于团队协作效率几乎没有提升,我们需要一套更加体系化的方案。
回到问题本身,针对“费人”、“费时”的问题,我们提出两个思路:
1.能否不让 PaaS 做中转,而是由 App Dev 通过一种高效自助的方式,使用到互联互通的各种基础设施能力?
2.能否构建一个中心化的协作平台,用技术的手段规范大家的行为,标准化的进行沟通?
从技术的角度来看,PaaS 平台需要提供灵活的工具链和工作流,基础设施所有能力都通过模块化的方式暴露出来,App Dev 利用这些平台的基本能力,自己组合、编排来解决自己的问题,过程中不需要平台层的参与。并且整个过程中涉及的所有团队,都使用统一的语言和接口进行交流,全程无需人工参与。
PART. 5 我们的实践
经过在蚂蚁内部 PaaS 平台近两年的探索与实践,沉淀出一套端到端的完整方案, 取名为 KusionStack,目前已经开源。试图从统一异构基础设施运维与团队协作两个角度解决传统 PaaS “费人”、“费时”的问题。
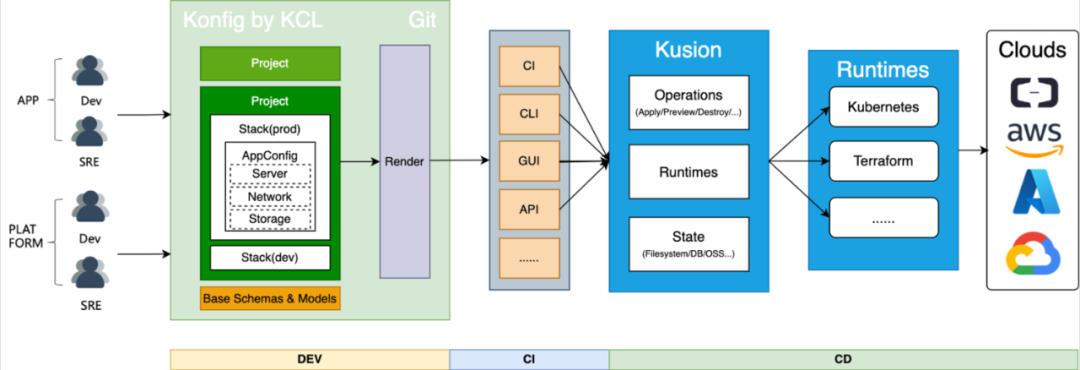
整个体系主要分为三个部分:
1.Konfig:Git 大库,是多团队协作的中心化平台,存放着各个团队的运维意图;
2.KCL:蚂蚁自研的配置策略 DSL,所有团队间交流的工具;
3.Kusion:KusionStack 引擎,负责所有的运维操作。
Platform Dev 通过 KCL 定义好基础能力模型,App Dev 通过 import、mixin 等语言特性在应用配置模型(AppConfig)里复用这些预定义好的能力,快速在 Konfig 里描述运维意图。AppConfig 是一个精心设计过的模型,只暴露 App Dev 需要关心的属性,屏蔽基础设施的复杂性。
永远不要低估基础设施的专业性与复杂性,即使已经成为云原生技术标准的 Kubernetes,对普通用户来说依然有很高的门槛,一个 Deployment 就有几十个字段,再加上自定义的 labels、annotations 就更多了,普通用户根本无法全部理解。或者说普通 AppDev 不应该去了解 Kubernetes,他们需要的只是发布,甚至不需要关心底层是不是 Kubernetes。
AppConfig 经过编译后会生成多个异构基础设施的资源,通过 CI、CLI、GUI 等方式把数据传输给 KusionStack 引擎。引擎是整个体系的核心,负责所有运维操作,是运维意图真正生效到基础设施的地方。他通过统一的方式对接异构基础设施,并对这些资源进行校验、编排、预览、生效、观测、健康检查等一系列操作。
值得一提的是,整个过程对运维 Kubernetes 资源非常友好。使用过 Kubernetes 的同学都知道,由于其面向终态、自调和的特点,apply 成功并不代表资源已经可以用,需要等资源调和成功后才能提供服务,如果调和失败了,还需要登陆到集群中,通过 get、describe、log 等命令查看具体报错,整个过程十分繁琐。
我们通过技术的手段对这些操作进行了简化,把调和过程中的重要信息以用户友好的方式透露出来。下面的动图是一个简单的示例,当命令下发后,可以清晰的看到所有资源及其关联资源调和过程,直到资源真正的可用。
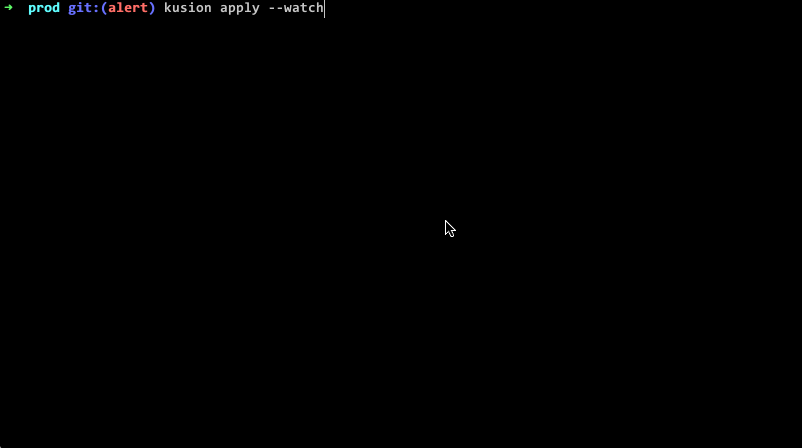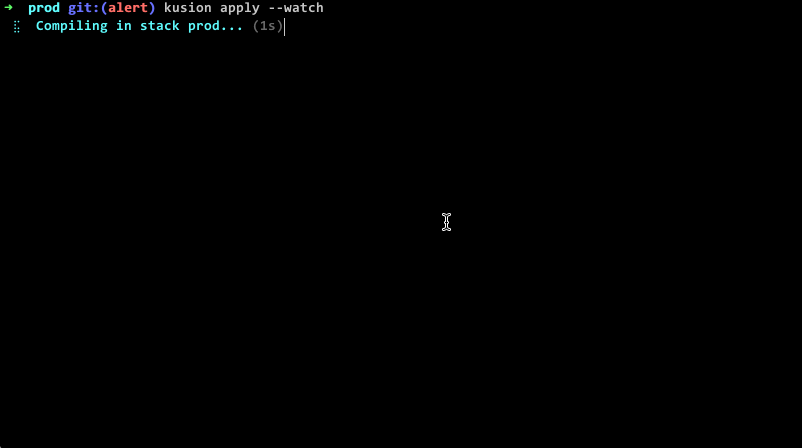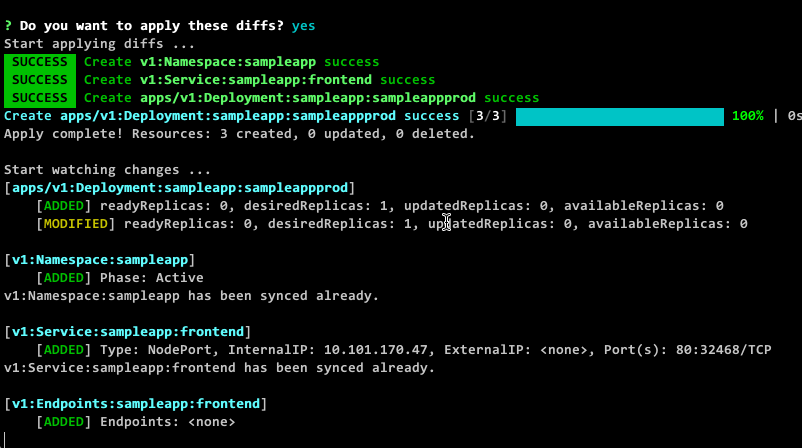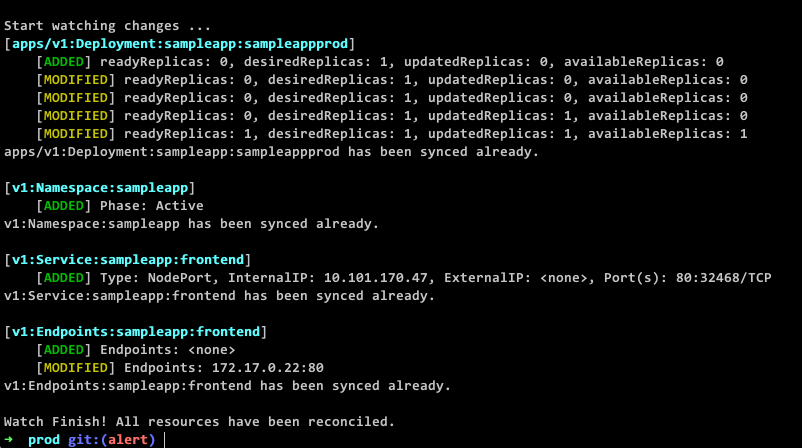
整个体系有如下几个特点:
1.以应用为中心
-
应用全方位配置管理,包括计算、网络、存储等所有与应用有关配置;
-
应用全生命周期管理,从第一行配置代码到生产可用。
2.统一运维“后云原生时代”应用的异构基础设施
-
Kubernetes 友好的工作流,为 Kubernetes 资源提供可观测性、健康检查等高阶能力,释放云原生技术红利;
-
复用 Terraform 生态,统一的工作流运维 Kubernetes、Terraform 多运行时资源。
3.规模化协同平台
-
灵活的工作流,用户可利用平台的基本能力,自己组合、编排来解决自己的问题;
-
App Dev 和 Platform Dev 关注点分离,底层能力迭代无需平台介入,直接供 App Dev 使用;
-
纯客户端方案,风险“左移”,尽早发现问题。
PART. 6 一切才刚刚开始
这套体系经过近两年的探索,已广泛应用在蚂蚁多云应用交付运维,计算及数据基础设施交付,建站运维,数据库运维等多个业务领域,目前 400+ 研发者直接参与了 Konfig 大库代码贡献,累计近 800K Commits,其中大部分为机器自动化代码修改,日均 1K pipeline 任务执行和近 10K KCL 编译执行,全量编译后可产生 3M+ 行的 YAML 文本。
不过,这一切才刚刚开始,后云原生时代也才刚刚到来,我们把这套系统开源的目的也是希望邀请业内各方的力量,一起构建一个符合技术发展趋势,能真正解决当下企业规模化运维这个难题的解决方案。蚂蚁 PaaS 团队还有很多经过内部规模化验证的技术沉淀,后续也会开源出来,只有我们远远不够,真诚地邀请大家一起来玩。
| 相关链接 |
Kusion:
https://github.com/KusionStack/kusion
KCL:
https://github.com/KusionStack/KCLVM
Konfig:
https://github.com/KusionStack/konfig
官网:https://kusionstack.io
PPT:KusionStack:“后云原生时代” 应用模化运维解决方案
https://kusionstack.io/blog/2022-kusionstack-application-scale-operation-solution-in-the-post-cloudnative-era/
了解更多…
KusionStack Star 一下✨:
https://github.com/KusionStack/kusion
本周推荐阅读
从规模化平台工程实践,我们学到了什么?
KusionStack 开源有感|历时两年,打破“隔行如隔山”困境
Go 代码城市上云——KusionStack 实践
KusionStack 开源|Kusion 模型库和工具链的探索实践







![[ CTF ] WriteUp-2022年春秋杯网络安全联赛-冬季赛](https://img-blog.csdnimg.cn/11dce9f414814cd6885b3106096842a9.png)