用于记录chatglm3的过程,防止忘记
需要注意的
可以使用xtuner -h查看有哪些功能可以使用。
[2023-10-31 11:40:18,643] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
10/31 11:40:22 - mmengine - INFO -
Arguments received: ['xtuner', '-h']. xtuner commands use the following syntax:
xtuner MODE MODE_ARGS ARGS
Where MODE (required) is one of ('list-cfg', 'copy-cfg', 'log-dataset', 'check-custom-dataset', 'train', 'test', 'chat', 'convert', 'preprocess')
MODE_ARG (optional) is the argument for specific mode
ARGS (optional) are the arguments for specific command
Some usages for xtuner commands: (See more by using -h for specific command!)
1. List all predefined configs:
xtuner list-cfg
2. Copy a predefined config to a given path:
xtuner copy-cfg $CONFIG $SAVE_FILE
3-1. Fine-tune LLMs by a single GPU:
xtuner train $CONFIG
3-2. Fine-tune LLMs by multiple GPUs:
NPROC_PER_NODE=$NGPUS NNODES=$NNODES NODE_RANK=$NODE_RANK PORT=$PORT ADDR=$ADDR xtuner dist_train $CONFIG $GPUS
4-1. Convert the pth model to HuggingFace's model:
xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
4-2. Merge the HuggingFace's adapter to the pretrained LLM:
xtuner convert merge $NAME_OR_PATH_TO_LLM $NAME_OR_PATH_TO_ADAPTER $SAVE_PATH
4-3. Split HuggingFace's LLM to the smallest sharded one:
xtuner convert split $NAME_OR_PATH_TO_LLM $SAVE_PATH
5. Chat with LLMs with HuggingFace's model and adapter:
xtuner chat $NAME_OR_PATH_TO_LLM --adapter $NAME_OR_PATH_TO_ADAPTER --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
6-1. Preprocess arxiv dataset:
xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
7-1. Log processed dataset:
xtuner log-dataset $CONFIG
7-2. Verify the correctness of the config file for the custom dataset.
xtuner check-custom-dataset
Run special commands:
xtuner help
xtuner version
GitHub: https://github.com/InternLM/xtuner
xtuner命令都有对应的python文件,可以在源码的xtuner/tools下找到,方便了解我们在运行命令时可以选择哪些参数
下载模型
这是我下载模型的地址。
上传到网盘上了
环境
主要是安装xtuner,使用xtuner工具继续微调。
pip install 'xtuner[deepspeed]'
也可以git上下载源码安装,就是使用命令方便一点
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]'
数据处理
之前微调Atom模型的时候使用自己收集的数据做了一个问答的csv文件,格式如下
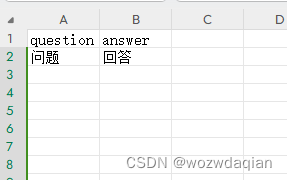
需要把数据转为json格式,格式如下:
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]
转换的代码如下:
import csv
import json
csv_file = 'data.csv'
json_file = 'output.json'
data = [] # 存储转换后的数据
# 读取CSV文件
with open(csv_file, 'r', encoding="utf-8") as file:
reader = csv.DictReader(file)
for row in reader:
instruction = row['question']
output = row['answer']
item = {"conversation":[{
# system需要填入你认为合适的语句
'system': '你是一个***专家。请回答我下面的问题。',
'input': instruction,
'output': output
}]}
data.append(item)
# 将转换后的数据写入JSON文件
with open(json_file, 'w', encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False)
print("转换完成!")
微调
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
xtuner list-cfg
通过xtuner copy-cfg 下载chatglm3的配置文件
xtuner copy-cfg chatglm3_6b_base_qlora_alpaca_zh_e3 .
这行命令会下载一个chatglm3_6b_base_qlora_alpaca_zh_e3_copy.py,接下来我们需要更改这个文件。
- pretrained_model_name_or_path:改为chatglm3模型路径
- alpaca_zh_path:改为json文件路径
- max_epochs:改为你需要的训练轮数
- evaluation_inputs:(可选)改成自己的问题
微调启动!!
NPROC_PER_NODE=2 xtuner train chatglm3_6b_base_qlora_alpaca_zh_e3_copy.py --work-dir 保存路径
pt转hf
xtuner convert pth_to_hf chatglm3_6b_base_qlora_alpaca_zh_e3_copy.py 训练保存的pth模型路径 hf模型保存路径
合并模型
xtuner convert merge chatglm3模型路径 上面的hf模型保存路径 合并模型保存路径
测试
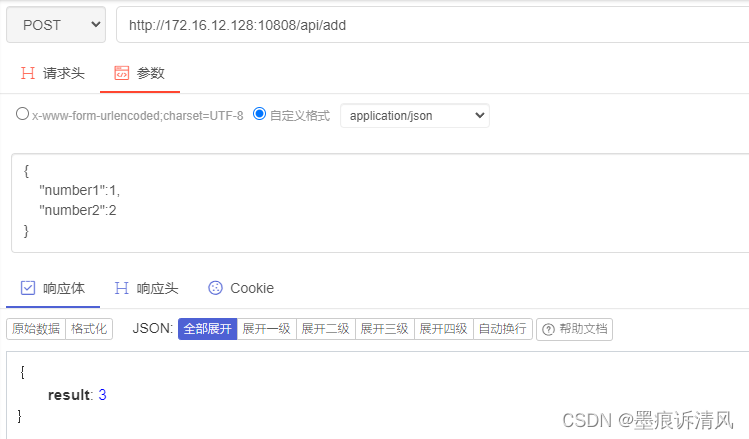
使用xtuner的chat进行测试,注意一定要填–prompt-template,不然他默认选择的是PROMPT_TEMPLATE的default的值,会报错,原因如下:
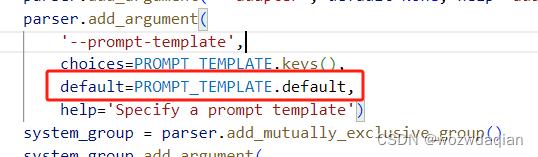
如果你是源码运行的话也可以把default的值改为’default’。
运行chat代码测试模型
xtuner chat 合并模型路径 --prompt-template default

参考
https://github.com/InternLM/xtuner/blob/151917720c7d57d02b78d9972e4b6ff755de93a0/README_zh-CN.md