文章目录
- 手写体识别
- iris数据集分类
手写体识别
首先使用load_digits将数据加载,这里的数据集有1797个样本,前1384个训练数据而后面的413个样本作为测试集,每个数据集中的样本是8*8像素的图像和一个[0, 9]整数的标签。紧接着输出64个样本的图像,每个图像输出在matplotlib上,标题title为每个图像的标签

首先将数据标准化,然后使用KNeighborsClassifier来使用K近邻算法,接着进行训练,然后输出训练之后分类模型的性能的指标。
k = 7
clf = KNeighborsClassifier(n_neighbors=k, metric='minkowski')
clf.fit(x_train, y_train) # 训练完毕
predictions = clf.predict(x_test)
当K=3时,分类模型的性能的结果如图
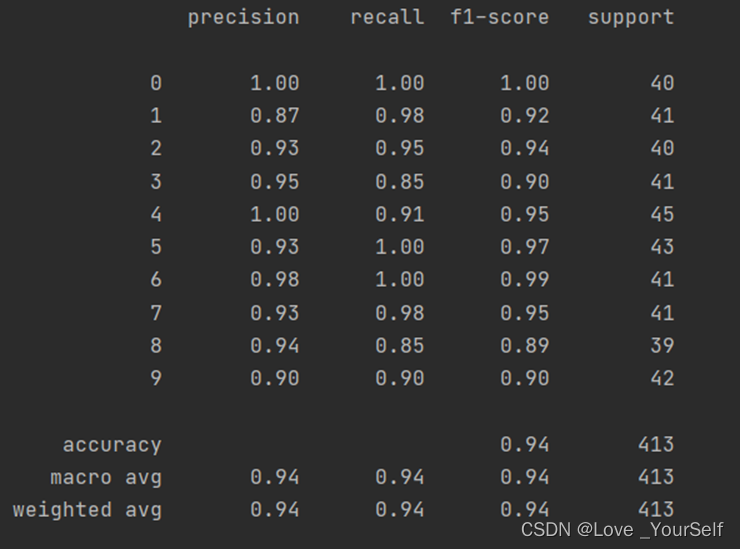
当K=4时,分类模型的性能的结果如图
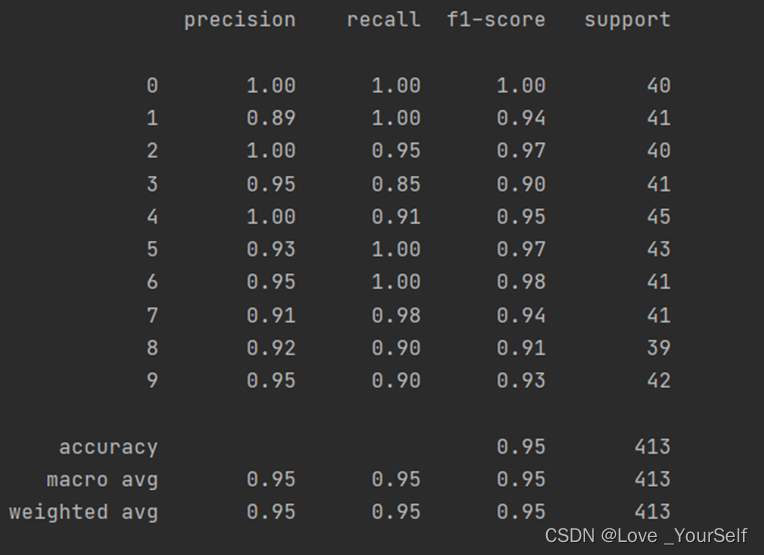
当K=5时,分类模型的性能的结果如图
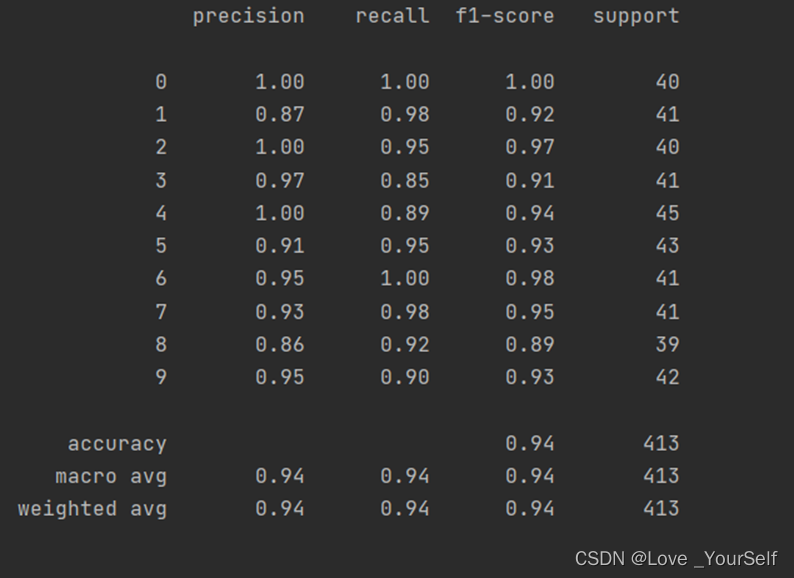
当K=6时,分类模型的性能的结果如图
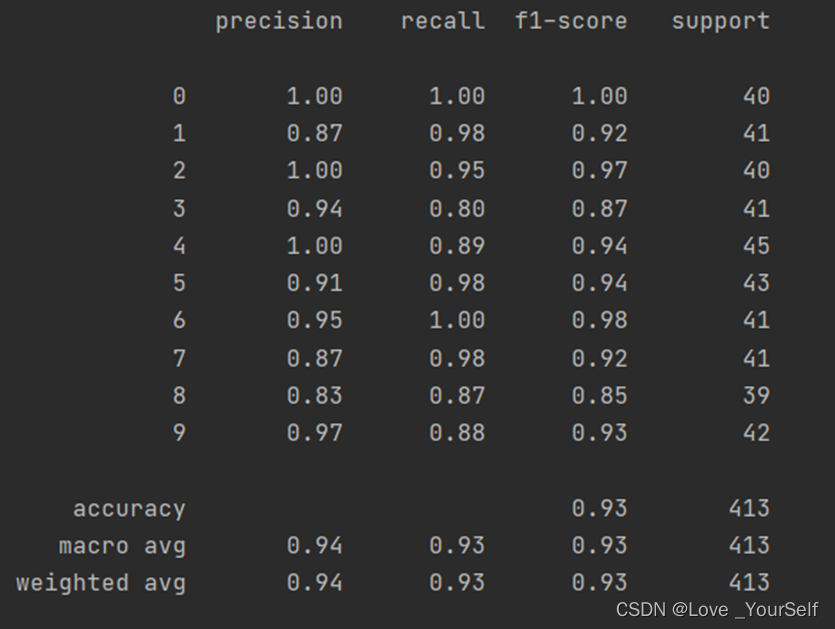
结果显示当K=4时效果较好,性能指标相较K=3、5和6时相对较好
iris数据集分类
接着使用sklearn自带的iris数据集,使用datasets.load_iris()导入数据,数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。获得数据集之后将数据集分为训练集和测试集,这里我分的是30个测试集和120个训练集,然后训练数据,之后输出分类模型的性能指标。
# 加载数据集
iris = datasets.load_iris()
data_size = iris.data.shape[0]
index = [i for i in np.arange(data_size)]
random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
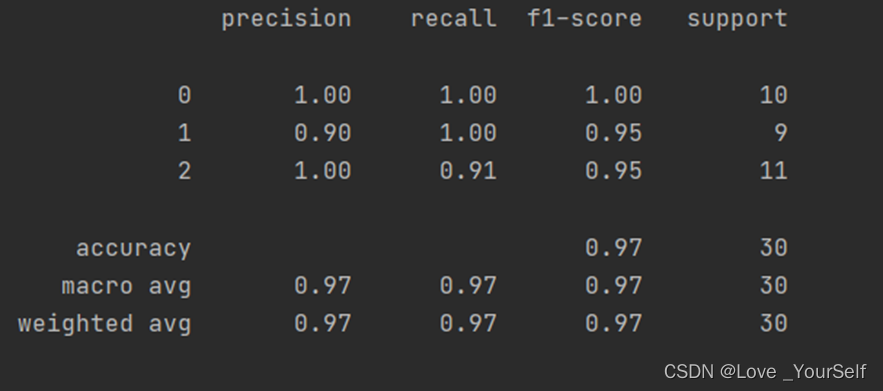
首先将K设置为5,结果如下
K=4的时候结果为下图
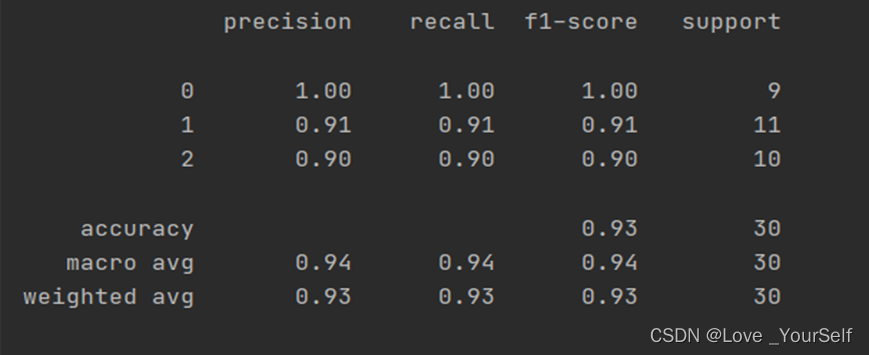
K=6的时候结果为下图
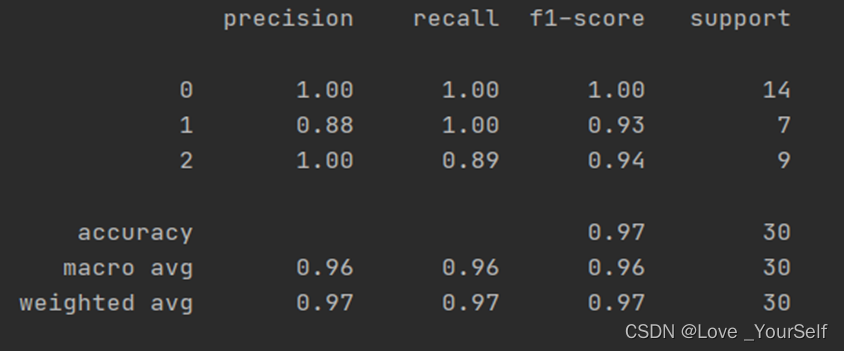
K=7的时候结果为下图
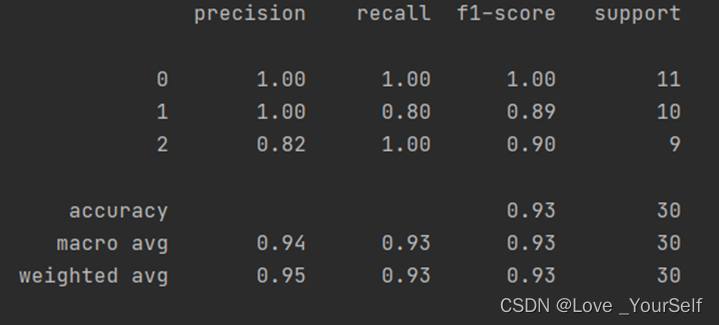
所以将K设置为5时效果较好,性能指标相较K=3、4、6和7时相对较好

![[附源码]java毕业设计教师教学评价系统](https://img-blog.csdnimg.cn/ea5c7d92960b489abb4ecc35b8091f29.png)