一、前言&闲聊
我们知道,HDFS客户端在写三副本的情况下,会建立一个pipeline,然后client不断地把数据发送到pipeline里的第一个datanode,然后第一个datanode再顺着pipeline往下游datanode传递数据。写pipeline的过程模型图如下所示: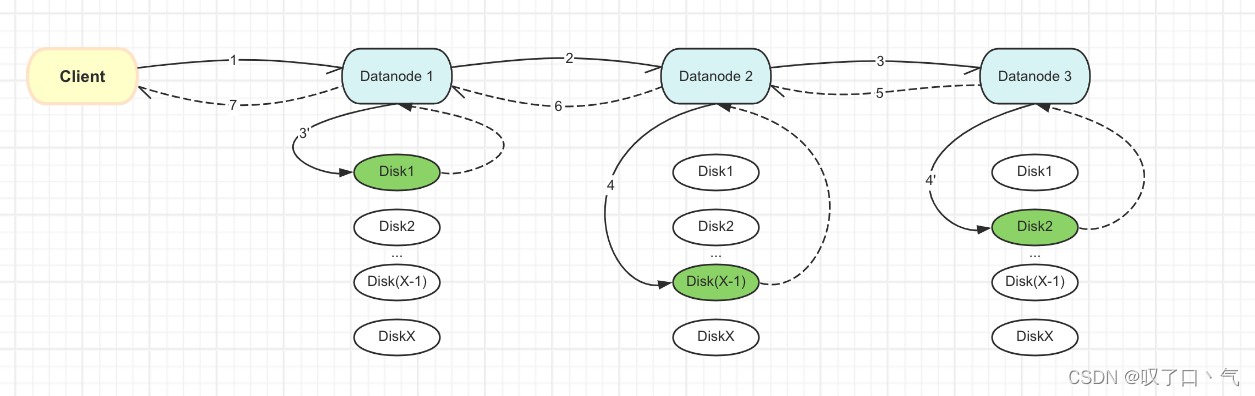
这里HDFS有个优化,如果pipeline里的某个datanode发生错误导致写失败,client会把这个节点给exclude掉,也就是把这个datanode当作bad datanode从pipeline里给踢除掉,这样就避免某个坏datanode把整个写入链路拖的特别慢甚至卡死。
再往下说说,仅仅把bad datanode从pipeline里踢除还不行。为什么这么说呢?想象一下,如果3个datanode都是慢datanode,那岂不是都被踢出去了,那client写数据的链路不就终止了么?所以说,不能仅踢除datanode,还要往pipeline里补充datanode。
当然了,也不是说每次从pipeline里踢除一个datanode就要往pipeline里补充一个新datanode。而是要根据配置的补充datanode的policy来灵活地添加,可以通过配置项去配置使用的policy。
本文我们不关注这些policy,本文我们重点关注:当满足新添加一个datanode到pipeline的条件时,把已经写到pipeline里其他datanode节点的数据给传输到这个新datanode上的这个过程。