文章目录
- 一、爬取目标
- 二、实现效果
- 三、准备工作
- 四、代理IP
- 4.1 代理IP是什么?
- 4.2 代理IP的好处?
- 4.3 获取代理IP
- 4.4 Python获取代理IP
- 五、代理实战
- 5.1 导入模块
- 5.2 设置翻页
- 5.3 获取图片链接
- 5.4 下载图片
- 5.5 调用主函数
- 5.6 完整源码
- 5.7 免费代理不够用怎么办?
- 六、总结
一、爬取目标
本次爬取的目标是某网站4K高清小姐姐图片:

二、实现效果
实现批量下载指定关键词的图片,存放到指定文件夹中:

三、准备工作
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
pip install requests # 网页数据爬取
pip install lxml # 提取网页数据
四、代理IP
4.1 代理IP是什么?
代理IP是一种安全功能,可以充当网络中间平台,使得用户电脑可以先访问代理IP,然后由代理IP访问目标网站页面,从而起到防火墙的作用。代理IP具有多种类型,包括HTTP代理、HTTPS代理、SOCKS代理等,分别适用于不同的网络通信需求。使用代理IP可以提高访问速度、保护隐私信息、突破下载限制以及作为防火墙保护网络安全。
4.2 代理IP的好处?
使用代理IP的好处有以下几个方面:
-
隐藏真实IP地址:使用代理IP可以将您的真实IP地址隐藏起来,确保您的在线活动更加匿名和隐私保护。这对于保护个人隐私和防止追踪非常重要。
-
绕过网络限制:有些地区或网络环境可能存在访问限制,如某些网站、社交媒体平台或在线服务被屏蔽。通过使用代理IP,可以绕过这些限制,访问被封锁的内容或服务。
-
提高访问速度:代理IP可以缓存和压缩网络数据,从而提高网页加载速度和下载速度。这对于访问速度较慢的网站或在网络拥堵时特别有用。
-
数据采集和爬虫应用:代理IP可以用于数据采集和爬虫应用,通过使用不同的代理IP地址,可以避免被目标网站识别和封禁,从而更好地进行数据采集和爬虫操作。
-
地理位置伪装:有时候需要在网站或应用中模拟不同的地理位置,以获取特定的服务或信息。使用代理IP可以实现地理位置的伪装,使网站或应用认为您位于不同的地理位置。
4.3 获取代理IP
博主最近写爬虫,发现了一款不错的代理IP,响度速度快,代理质量高,有免费试用也有超值套餐:云立方代理IP

1、打开云立方的官网,点击代理IP:http://www.yunlifang.cn/dailiIP.asp
2、我们这里免费试用,测试一下效果:
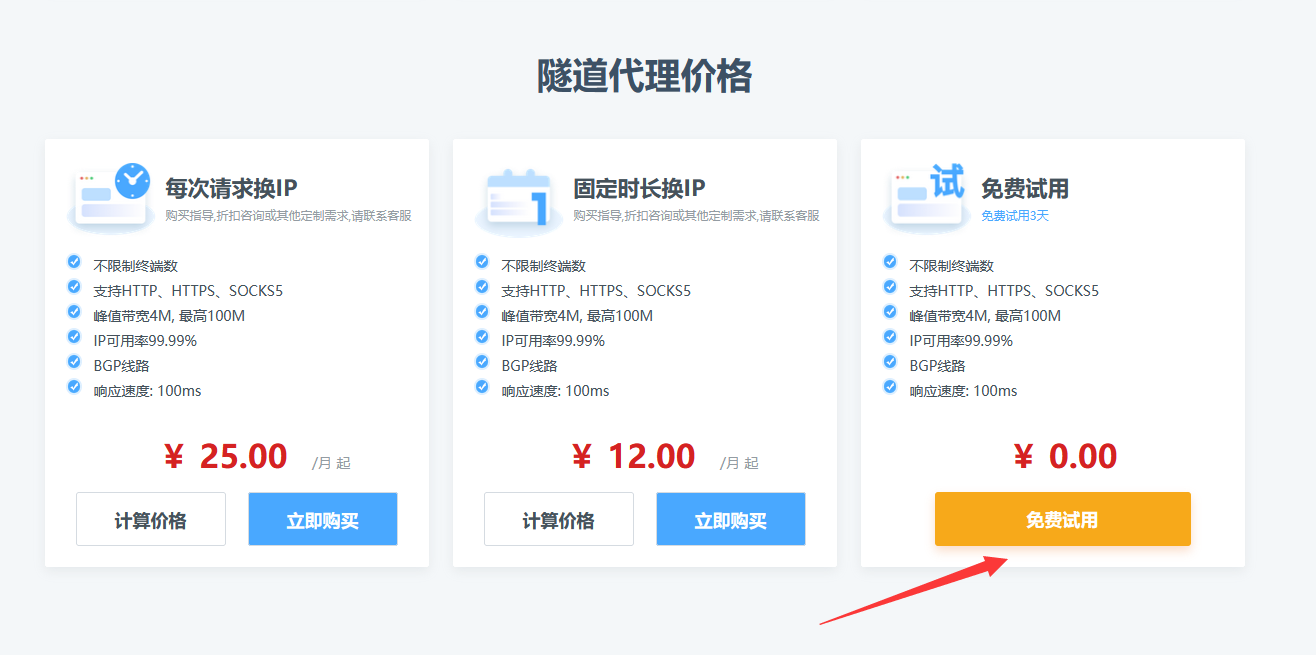
3、然后找客服说明免费试用一下,说明需要代理IP的时长、数量等信息:

然后客服给我们账号密码,请求地址和端口号:
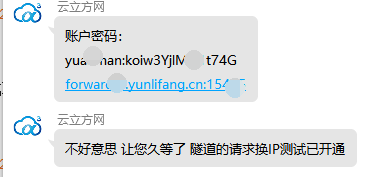
接下来就是使用Python去获取代理IP。
4.4 Python获取代理IP
我们用Python获取代理IP,注意将代码中的账号、密码、地址、端口替换为刚才客服给的账号信息:
def get_ip():
"""获取代理IP"""
# 这里替换为刚才客服给的账号信息
proxyUser = "你的账号" # 账户
proxyPass = "你的密码" # 密码
proxyHost = "你的地址" # 地址
proxyPort = "你的端口号" # 端口
proxyMeta = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
print(proxies)
return proxies
get_ip()
这里我用的隧道代理IP(隧道代理IP:是指下面那个账号链接每次去访问网页就会自动切换IP):

五、代理实战
5.1 导入模块
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import os # 创建文件
5.2 设置翻页
首先我们来分析一下网站的翻页,一共有62页:

第一页链接:
https://pic.netbian.com/4kmeinv/index.html
第二页链接:
https://pic.netbian.com/4kmeinv/index_2.html
第三页链接:
https://pic.netbian.com/4kmeinv/index_3.html
可以看出每页只有index后面从第二页开始依次加上_页码,所以用循环来构造所有网页链接:
if __name__ == '__main__':
# 页码
page_number = 1
# 循环构建每页的链接
for i in range(1,page_number+1):
# 第一页固定,后面页数拼接
if i ==1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'
5.3 获取图片链接
可以看到所有图片url都在 ul标签 > a标签 > img标签下:

我们创建一个get_imgurl_list(url)函数传入网页链接获取 网页源码,用xpath定位到每个图片的链接:
def get_imgurl_list(url,imgurl_list):
"""获取图片链接"""
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 发送请求
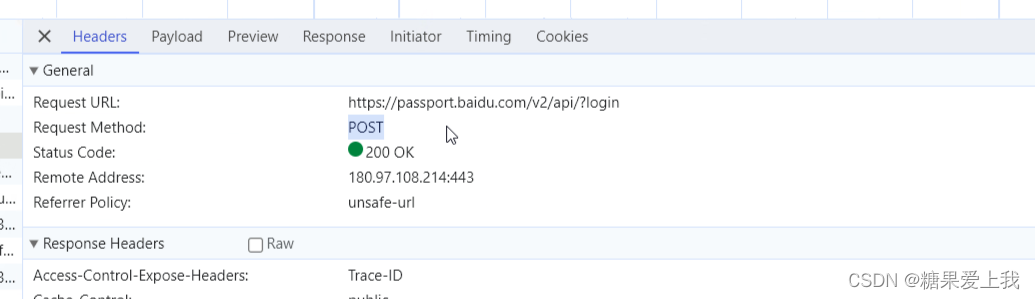
response = requests.get(url=url, headers=headers)
# 获取网页源码
html_str = response.text
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ul[@class='clearfix']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出20,没有问题
for li in li_list:
imgurl = li.xpath(".//a/img/@src")[0]
# 拼接url
imgurl = 'https://pic.netbian.com' +imgurl
print(imgurl)
# 写入列表
imgurl_list.append(imgurl)
运行结果:

点开一个图片链接看看:

OK没问题!!!
5.4 下载图片
图片链接有了,代理IP也有了,下面我们就可以下载图片。定义一个get_down_img(img_url_list)函数,传入图片链接列表,然后遍历列表,每下载一个图片切换一次代理,将所有图片下载到指定文件夹:
def get_down_img(imgurl_list):
# 在当前路径下生成存储图片的文件夹
os.mkdir("小姐姐")
# 定义图片编号
n = 0
for img_url in imgurl_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 调用get_ip函数,获取代理IP
proxies = get_ip()
# 每次发送请求换代理IP,获取图片,防止被封
img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content
# 拼接图片存放地址和名字
img_path = './小姐姐/' + str(n) + '.jpg'
# 将图片写入指定位置
with open(img_path, 'wb') as f:
f.write(img_data)
# 图片编号递增
n = n + 1
5.5 调用主函数
这里我们可以设置需要爬取的页码:
if __name__ == '__main__':
# 1. 设置获取的页数
page_number = 63
imgurl_list = [] # 用于存储所有的图片链接
# 2. 循环构建每页的链接
for i in range(1,page_number+1):
# 第一页固定,后面页数拼接
if i ==1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'
# 3. 获取图片链接
get_imgurl_list(url,imgurl_list)
# 4. 下载图片
get_down_img(imgurl_list)
5.6 完整源码
注意将get_ip()函数代码中的账号、密码、地址、端口替换为刚才客服给的账号信息
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import time # 防止爬取过快可以睡眠一秒
import os
def get_ip():
"""获取代理IP"""
# 这里替换为刚才客服给的信息代理服务器
proxyUser = "你的账号" # 账户
proxyPass = "你的密码" # 密码
proxyHost = "你的地址" # 地址
proxyPort = "你的端口号" # 端口
proxyMeta = f"http://{proxyUser}:{proxyPass}@{proxyHost}:{proxyPort}"
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
print(proxies)
return proxies
def get_imgurl_list(url,imgurl_list):
"""获取图片链接"""
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 发送请求
response = requests.get(url=url, headers=headers)
# 获取网页源码
html_str = response.text
# 将html字符串转换为etree对象方便后面使用xpath进行解析
html_data = etree.HTML(html_str)
# 利用xpath取到所有的li标签
li_list = html_data.xpath("//ul[@class='clearfix']/li")
# 打印一下li标签个数看是否和一页的电影个数对得上
print(len(li_list)) # 输出20,没有问题
for li in li_list:
imgurl = li.xpath(".//a/img/@src")[0]
# 拼接url
imgurl = 'https://pic.netbian.com' +imgurl
print(imgurl)
# 写入列表
imgurl_list.append(imgurl)
def get_down_img(imgurl_list):
# 在当前路径下生成存储图片的文件夹
os.mkdir("小姐姐")
# 定义图片编号
n = 0
for img_url in imgurl_list:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
# 调用get_ip函数,获取代理IP
proxies = get_ip()
# 每次发送请求换代理IP,获取图片,防止被封
img_data = requests.get(url=img_url, headers=headers, proxies=proxies).content
# 拼接图片存放地址和名字
img_path = './小姐姐/' + str(n) + '.jpg'
# 将图片写入指定位置
with open(img_path, 'wb') as f:
f.write(img_data)
# 图片编号递增
n = n + 1
if __name__ == '__main__':
# 1. 设置获取的页数
page_number = 50
imgurl_list = [] # 用于存储所有的图片链接
# 2. 循环构建每页的链接
for i in range(1,page_number+1):
# 第一页固定,后面页数拼接
if i ==1:
url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
url = f'https://pic.netbian.com/4kmeinv/index_{i}.html'
# 3. 获取图片链接
get_imgurl_list(url,imgurl_list)
# 4. 下载图片
get_down_img(imgurl_list)
运行结果:

下载成功了没有报错,代理IP的质量还是不错的!!!
5.7 免费代理不够用怎么办?
免费的代理不够用可以看看云立方家的套餐还是蛮便宜的:http://www.yunlifang.cn/dailiIP.asp

六、总结
代理IP对于爬虫是密不可分的,代理IP可以帮助爬虫隐藏真实IP地址,有需要代理IP的小伙伴可以试试云立方家的代理IP:云立方代理IP