文章目录
- Ⅰ 概念及结构
- 1. 静态顺序表
- 2. 动态顺序表
- Ⅱ 基本操作实现
- 1. 定义顺序表
- 2. 初始化顺序表
- 3. 销毁顺序表
- 4. 输出顺序表
- 5. 扩容顺序表
- 6. 尾插法插入数据
- 7. 头插法插入数据
- 8. 尾删法删除数据
- 9. 头删法删除数据
- 10. 顺序表查找
- 11. 在指定位置 pos 插入数据
- 12. 删除指定位置 pos 的元素
Ⅰ 概念及结构
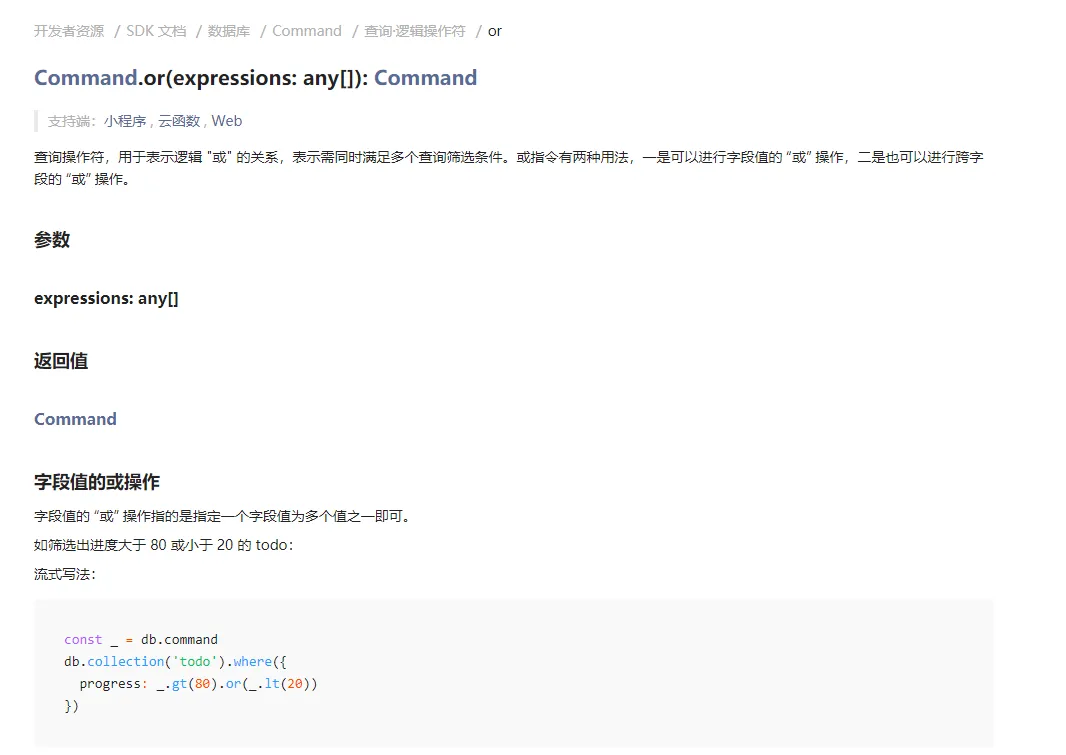
- 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,顺序表的本质就是数组存储。在数组上完成数据的增删查改。
顺序表的分类
- 静态顺序表:使用固定长度的数组来存储元素。
- 动态顺序表:使用动态开辟的数组来存储元素。
1. 静态顺序表
- 顺序表的长度固定,一次性开辟一块连续的数组空间。
- 开辟的空间多了就浪费空间,开辟的空间少了这块空间就没用了。
定义静态顺序表
#define MAX 10
typedef int SLDataType; //顺序表的每个数据类型
typedef struct SeqList
{
SLDateType data[MAX]; //定长数组(顺序表)
int size; //当前顺序表内有效数据的个数
}SeqList;

定长顺序表的缺点
- 顺序表在实际使用过程中没办法确定数组大小,MAX 给小了不够用,给大了浪费。
- 静态的顺序表在实际使用中实用性低,因此本文后面对于顺序表的操作都是基于动态顺序表来实现的。
静态顺序表的定义
2. 动态顺序表
- 动态顺序表可以根据需求申请数组空间,动态顺序表的空间没有不够这种说法。因此在实际使用中使用的更多的还是动态顺序表。
定义动态顺序表
typedef int SLDataType; //顺序表的每个数据类型
typedef struct SeqList //sequence list
{
SLDataType* data; //指向动态开辟的数组空间
int size; //有效数据的个数
int capacity; //数组所能容纳的数据个数
}SeqList;
Ⅱ 基本操作实现
- 在定义各个操作顺序表的函数时,使用的是址传递,否则形参无法改变实参。
1. 定义顺序表
- 本文使用的都是动态顺序表。
typedef int SLDataType; //顺序表的每个数据类型
typedef struct SeqList //sequence list
{
SLDataType* data; //指向动态开辟的数组空间
int size; //有效数据的个数
int capacity; //数组所能容纳的数据个数
}SeqList;
2. 初始化顺序表
void SeqListInit(SeqList* ps)
{
assert(ps);
ps->data = NULL;
ps->size = 0; //初始化有效数据个数为 0
ps->capacity = 0; //初始化最大容纳数量为 0
}
3. 销毁顺序表
- 释放开辟好的连续的空间,将有效数据个数和空间容量都置为 0.
void SeqListDestroy(SeqList* ps)
{
assert(ps);
if (ps->data != NULL) //顺序表不为空
{
free(ps->data);
ps->data = NULL;
ps->capacity = 0;
ps->size = 0;
}
}
4. 输出顺序表
//打印顺序表
void SeqListPrint(SeqList* ps)
{
assert(ps);
for (int i = 0; i < ps->size; i++)
{
printf("%d ", ps->data[i]);
}
printf("\n");
}
5. 扩容顺序表
对顺序表进行扩容时有两种情况
- 顺序表不为空:直接将顺序表的容量使用 realloc 扩容两倍即可。
- 顺序表为空:此时 capacity 为 0 不能按两倍来扩容,直接给一个固定值即可。
//检查顺序表是否需要扩容
void SLCheckCapacity(SeqList* ps)
{
assert(ps);
//有效数据 = 容纳数量 时就要扩容了
if (ps->size == ps->capacity)
{
//顺序表容量为 0 时直接开辟 4 个元素的空间,反之按照 2 倍扩容
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* tmp =
(SLDataType*)realloc(ps->data, sizeof(SLDataType) * newcapacity);
if (NULL == tmp)//用 tmp 而不是用 ps->data 是防止开辟空间失败时将原地址覆盖
{
perror("realloc");
return;
}
ps->data = tmp; //让 data 指向扩容后的空间
ps->capacity = newcapacity; //顺序表容量扩大成新的容量
}
}
6. 尾插法插入数据
- 将元素插入到当前顺序表的末尾。
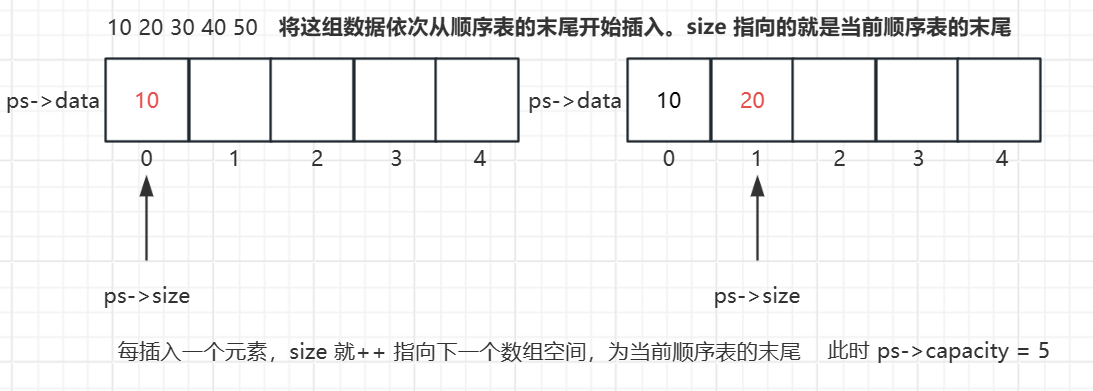
//尾插法插入数据
void SeqListPushBack(SeqList* ps, SLDataType x)
{
assert(ps);
SLCheckCapacity(ps); //插入元素前看看是否要先扩容
ps->data[ps->size] = x; //将 x 插入到顺序表当前的末尾
ps->size++; //继续指向下一个末尾
}
7. 头插法插入数据
头插概念
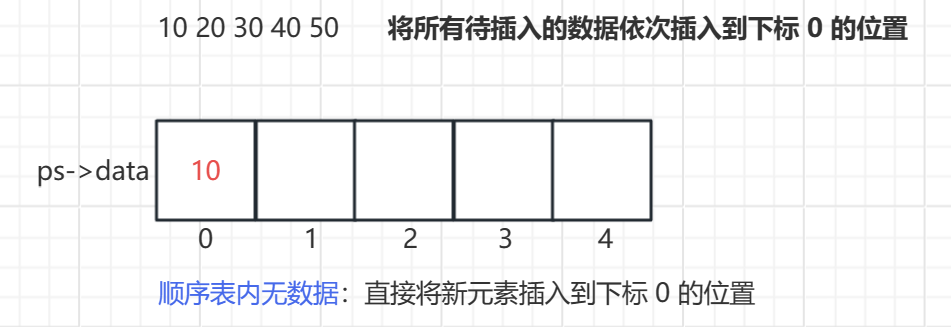
将每个要插入的数据都插入在 下标为 0 的位置上。头插时有两种情况
- 顺序表内无数据:直接将要插入的数据放在下标为 0 的位置。
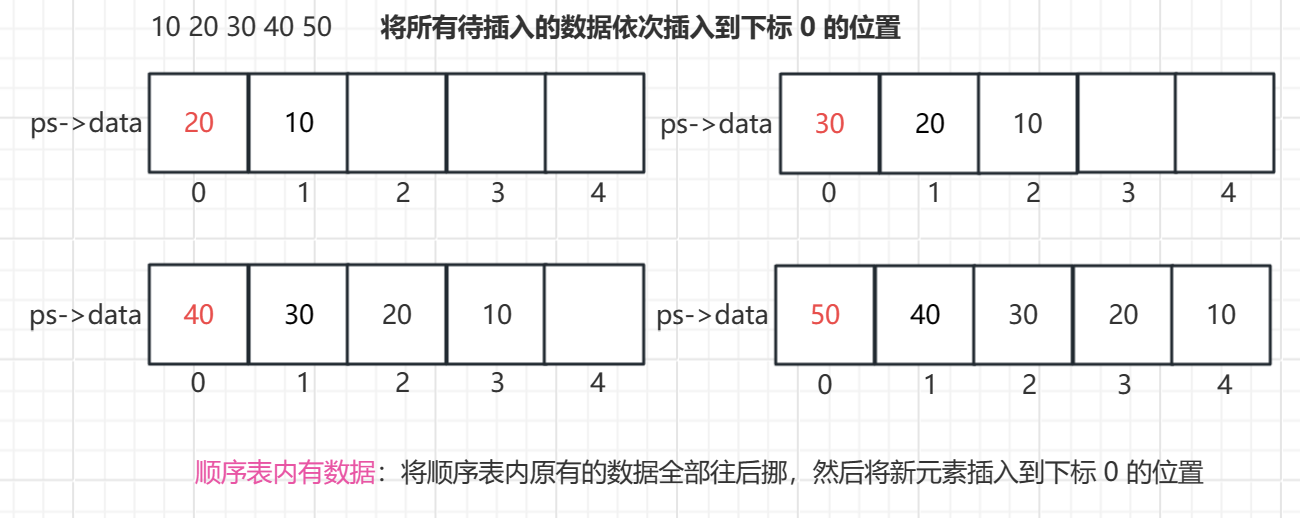
- 顺序表内有数据:将顺序表内原来的所有元素都后移一位,然后将新元素插入到下标 0 的位置。
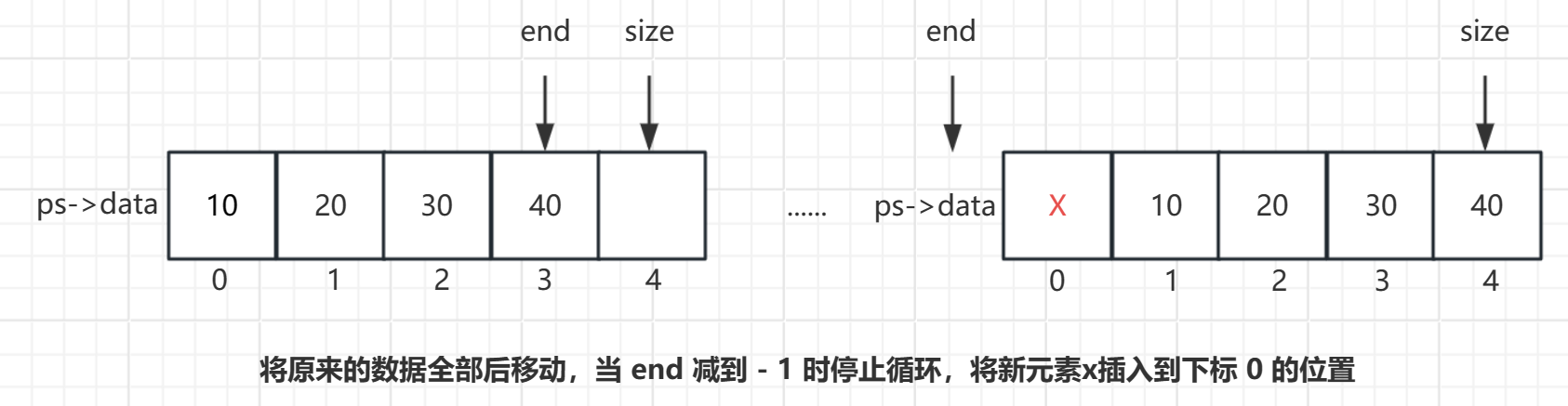
实现思路
- 使用一个变量 end 指向顺序表的最后一个元素,当 end 不小于 0 的时候将 end 指向的数据依次往后挪。
- 因为 end 是下标,顺序表最后一个元素的下标应该为顺序标的有效个数 - 1。
实现代码
//头插法插入数据
void SeqListPushFront(SeqList* ps, SLDataType x)
{
assert(ps);
SLCheckCapacity(ps); //插入前看看是否需要扩容
int end = ps->size - 1; //顺序表最后一个元素的下标
while (end >= 0) //end 不越界就一直将元素往后挪
{
ps->data[end + 1] = ps->data[end]; //将元素后挪一位
end--; //让 end 指向更前一个元素
}
ps->data[0] = x; //将要插入的元素插入到下标 0 的位置
ps->size++; //顺序表有效个数 + 1
}
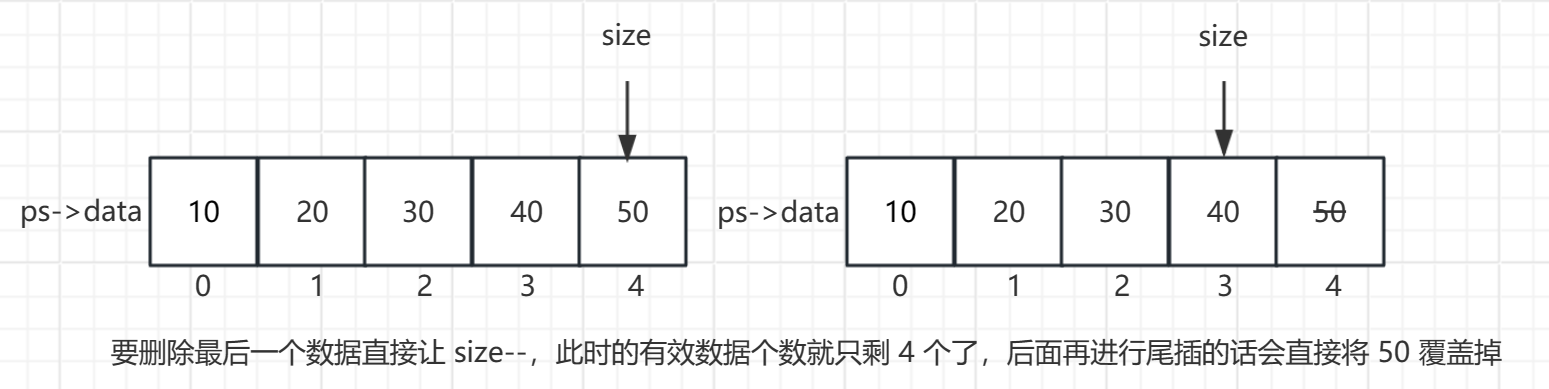
8. 尾删法删除数据
- 删掉顺序表的最后一个元素。
- 直接将顺序表的有效个数 - 1即可,在删除之前还应该先判断顺序表内是否有有效元素。如果有效个数 size 为 0 还继续 - 1 的话直接就越界了。
//尾删法删除数据
void SeqListPopBack(SeqList* ps)
{
assert(ps && ps->size > 0);
ps->size--; //这样原来的第 size 个数据就不再是有效数据了
}
9. 头删法删除数据
- 每次删除数据都是将下标为 0 的数据给删除掉。
- 只需要将下标 0 后面的数据依次往前覆盖上来,就可以直接将头元素删除掉了。
实现思路
- 定义一个 begin 变量初始值为 1,将 begin 指向的值往前挪到 begin - 1 的位置。
- 然后讲 begin++ 指向下一个元素,再继续重复第一步。
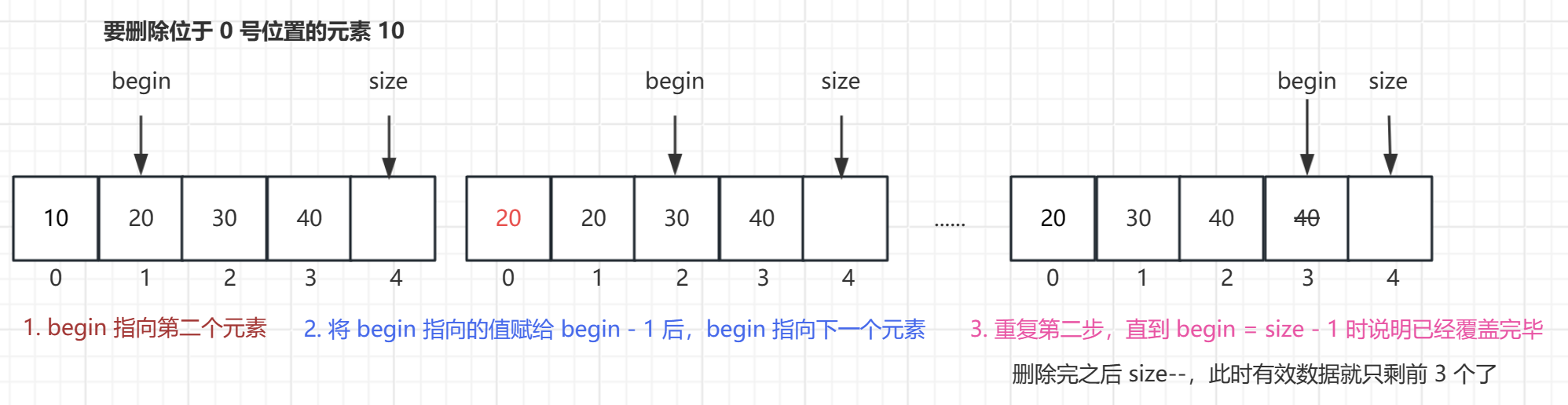
实现代码
//头删法删除数据
void SeqListPopFront(SeqList* ps)
{
assert(ps && ps->size > 0);
int begin = 1;
while (begin < ps->size)
{
ps->data[begin - 1] = ps->data[begin];//让后一个元素往前覆盖
begin++;
}
ps->size--;
}
10. 顺序表查找
- 遍历顺序表内所有的有效数据,如果等于要查找的值,则返回下标值,反之返回 -1。
// 顺序表查找
int SeqListFind(SeqList* ps, SLDataType x)
{
assert(ps && ps->size > 0);
for (int i = 0; i < ps->size; i++)
{
if (ps->data[i] == x)
{
return i; //找到了则返回该元素在顺序表内的下标
}
}
return -1; //找不到则返回 -1
}
11. 在指定位置 pos 插入数据
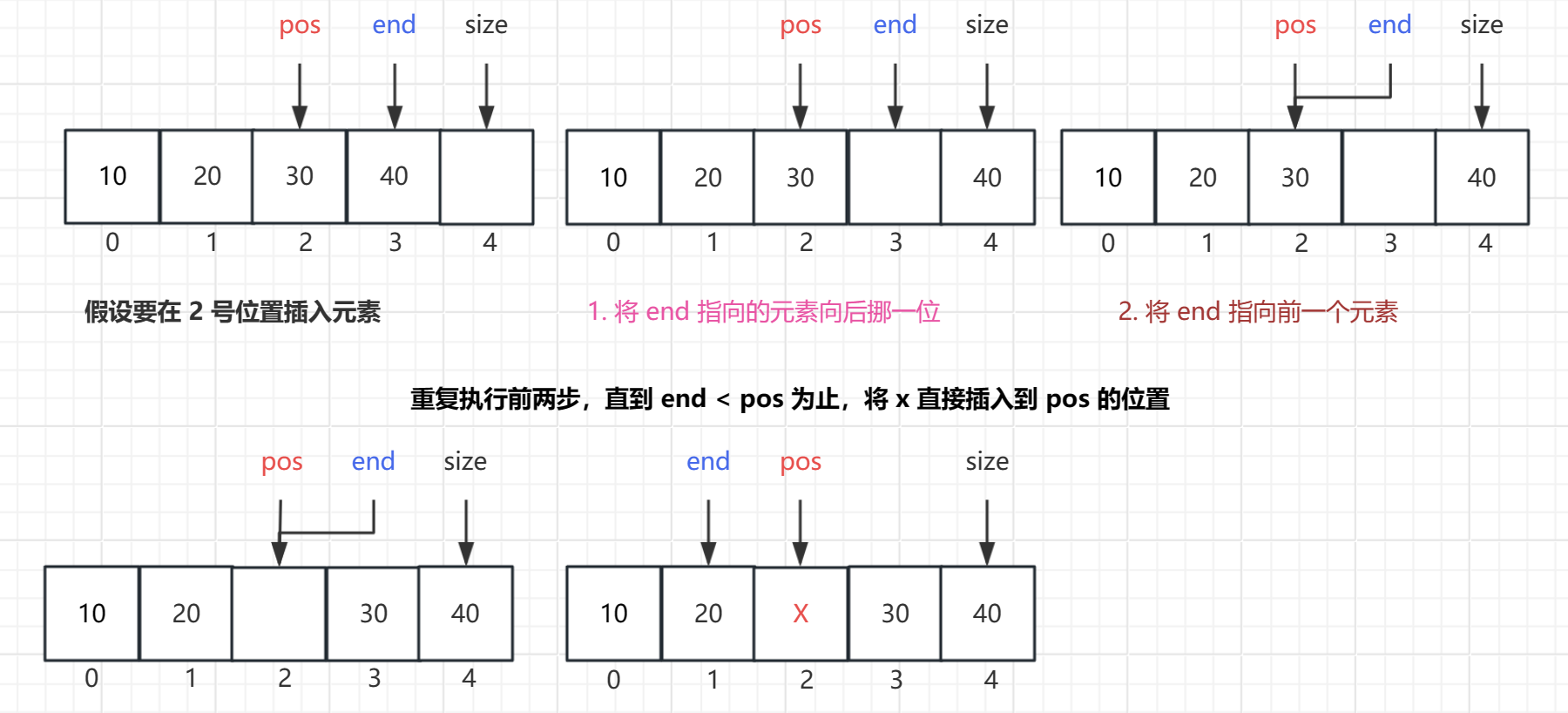
pos 的下标在合法时有两种情况
-
0 <= pos < size:
- 定义一个 end 变量指向顺序表内的最后一个有效数据 (size - 1 的位置),从 end 开始依次将数据往后挪,直到 end 移动到小于 pos 的位置时说明已经全部挪动完毕,此时直接将新数据插入到下标为 pos 的位置即可。
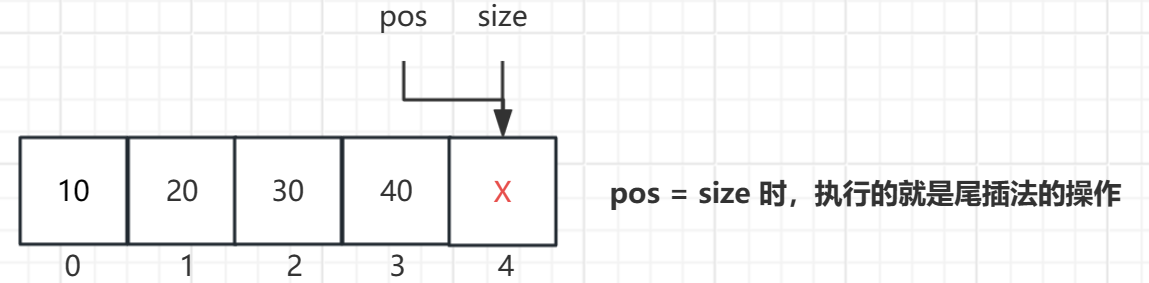
- pos == size:此时要插入的位置在最后一个元素之后,直接将元素插入即可。
// 顺序表在 pos 位置插入 x
void SeqListInsert(SeqList* ps, int pos, SLDataType x)
{
assert(ps);
assert(pos >= 0 && pos <= ps->size); //指定的位置在合法范围内
int end = ps->size - 1; //指向顺序表的最后一个有效数据
while (end >= pos) //如果 pos > end 则直接执行尾插法
{
ps->data[end + 1] = ps->data[end]; //将 pos 后的元素依次往后挪
end--; //指向前一个元素
}
ps->data[pos] = x; //在 pos 下标处插入新元素
ps->size++; //顺序表有效数据个数 + 1
}
12. 删除指定位置 pos 的元素
- 将 pos 位置后的元素依次往前覆盖,和头删法一样。
- pos 的位置此时就不能等于 size 了,最后一个元素下标是 size - 1,不能删除下标为 size 的元素。
pos 的下标在合法时有两种情况
- 0 <= pos < size - 1:直接将 pos 后的元素依次往前覆盖。
- pos == size - 1:要删除的是最后一个元素,直接将顺序表有效数据个数 - 1 即可。
// 顺序表删除pos位置的值
void SeqListErase(SeqList* ps, int pos)
{
assert(ps);
assert(pos >= 0 && pos < ps->size);
int begin = pos + 1; //指向 pos 后的一个数据
//pos 如果等于 size - 1 则 begin = size
while (begin < ps->size) //依次往前覆盖元素,如果要删除最后一个则不进入循环.
{
ps->data[begin - 1] = ps->data[begin];
begin++;
}
ps->size--; //顺序表有效数据个数 - 1
}