大数据技能大赛平台搭建(容器环境)
- 一、Hadoop3.X 完成分布式安装部署
- 1、 JDK安装
- 1、解压jdk
- 2、修改配置文件
- 3、免密登录
- 2、hadoop集群环境搭建
- 1、配置文件
- 2、配置环境变量
- 3、给slave1和slave2分发配置文件
- 4、启动Hadoop集群
- 3、配置完成!
- 二、Zookeeper安装部署
- 1、解压
- 1. 将Master节点Zookeeper安装包解压到/opt/module目录下
- 2. 改名(可不做)
- 2、配置
- 1. 复制zoo.cfg.dynamic.next 改名为 zoo.cfg
- 2. 修改zoo.cfg文件
- 3. 新建目录
- 4. 配置环境变量
- 3、分发
- 1,将环境变量文件分发给slave1和slave2
- 2,将zookeeper安装包分发给slave1和2
- 3,需要修改slave1和slave2上的myid文件
- 4,使slave1和2的环境变量生效
- 4、启动
- 5、完成!
- 三、Kafka安装配置
- 1、解压/
- 1. 将kafka安装包解压到/opt/module目录下
- 2. 改名(可不做)
- 2、配置
- 1. 配置环境变量
- 2. 修改文件 server.properties
- 3、分发
- 1,给slave1和2 分发环境变量文件
- 2,分发安装包
- 3,修改slave1和2的配置文件
- 4,验证
- 5,任务
- 6,配置完成
- 四、HBase2.x分布式安装配置
- 1、解压
- 1. 将Master节点Hbase安装包解压到/opt/module目录下
- 2、配置
- 1. 配置环境变量
- 2. 修改 hbase-site.xml 文件
- 3、分发
- 1. 将解压包以及环境变量配置文件分发至slave1、slave2中
- 2. 启动hbase
- 4、任务
- 五、ClickHouse单机安装配置
- 1、解压
- 1. 将Master节点ClickHouse相关安装包解压到/opt/module/clickhouse目录下
- 2. 执行启动各个相关脚本
- 3. 设置远程访问并移除默认监听文件(listen.xml),同时由于9000端口被hadoop占用,需要将clickhouse的端口更改为9001
- 4. 启动clickhouse,启动后查看clickhouse运行状态
一、Hadoop3.X 完成分布式安装部署
需要三台虚拟机
所有相关安装包在Master节点的/opt/software目录下
解压到 /opt/module目录下
命令中要求使用绝对路径
1、 JDK安装
- 在master操作
1、解压jdk
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
2、修改配置文件
- 修改 etc下的profile文件:vi /etv/profile
添加配置文件(里面原本的内容不可以删除,在最后一行按 o 输入,修改完成先按 Esc 再输入 :wq ( :wq : 退出并保存)):
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 使文件生效:source /etc/profile ,使用 java -version命令验证

3、免密登录
- 修改/etc/hosts 文件(三台虚拟机都需要):vi /etc/hosts ,将slave1和slave2的ip添加到里面(查看IP的命令:ip addr):
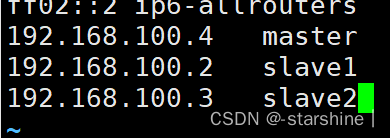
-
在master上输入:
ssh-keygen -t rsa 然后连续按下三次回车然后输入命令(若遇到需要输入yes或者no 输入yes)
ssh-copy-id master 按下回车后输入master所对应的虚拟机密码
ssh-copy-id slave1 按下回车后输入slave1所对应的虚拟机密码
ssh-copy-id slave2 按下回车后输入slave2所对应的虚拟机密码验证方式:输入 ssh slave1 不需要输入密码即可

2、hadoop集群环境搭建
- 将hadoop解压到/opt/module下
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
- 修改配置文件
修改文件位于:/opt/module/hadoop-3.1.3/etc/hadoop
可以直接:cd /opt/module/hadoop-3.1.3/etc/hadoop
需要修改的配置文件有5个:
1,core-site.xml(核心配置文件)
2,hdfs-site.xml(HDFS配置文件)
3,mapred-site.xml(MapReduce配置文件)
4,yarn-site.xml(YARN配置文件)
5,hadoop-env.sh
6,yarn-env.sh
7,workers (该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
1、配置文件
1,core-site.xml(核心配置文件)
vi core-site.xml
<property>
<!-- 指定NameNode的地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<!-- 指定hadoop数据的存储目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
2,hdfs-site.xml(HDFS配置文件)
vi hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
3,mapred-site.xml
vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4,yarn-site.xml
vi yarn-site.xml(YARN配置文件)
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
5,hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
6,yarn-env.sh
vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
7,workers
vi workers
master
slave1
slave2
2、配置环境变量
vi /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3、给slave1和slave2分发配置文件
- 分发jdk
scp -r /opt/module/jdk1.8.0_212/ root@slave1:/opt/module/
scp -r /opt/module/jdk1.8.0_212/ root@slave2:/opt/module/
- 分发环境变量配置文件
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
- 分发hadoop
scp -r /opt/module/hadoop-3.1.3/ root@slave1:/opt/module/
scp -r /opt/module/hadoop-3.1.3/ root@slave2:/opt/module/
- 使slave1和slave2的配置文件生效
切换到slave1和slave2 输入命令 source /etc/profile
输入java -version 查看是否成功

4、启动Hadoop集群
- 初始化NameNode(在master)
hdfs namenode -format
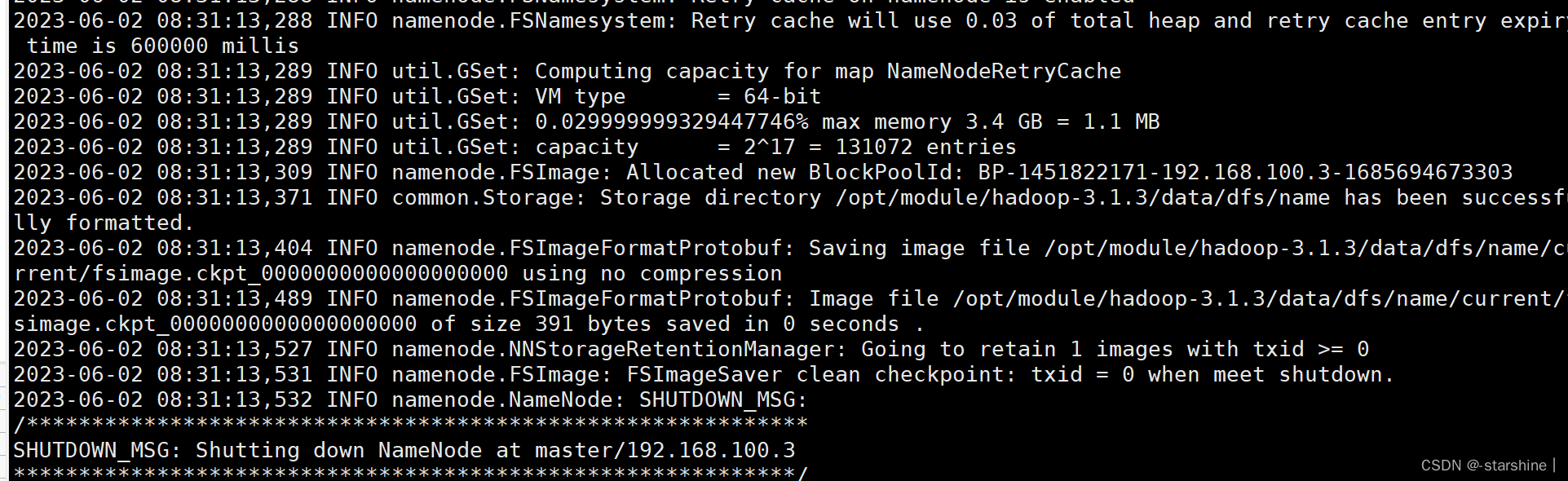
- 启动hdfs和yarn
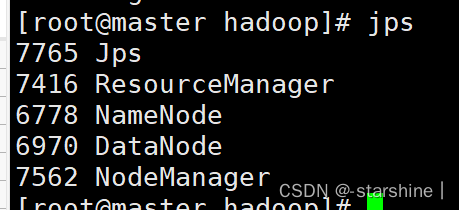
start-all.sh
master 节点下输入 jps 显示以下内容
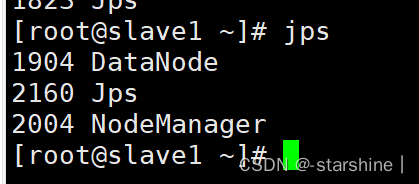
slave1节点下输入jps显示以下内容
3、配置完成!
二、Zookeeper安装部署
1、解压
1. 将Master节点Zookeeper安装包解压到/opt/module目录下
tar -zxvf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
2. 改名(可不做)
mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
2、配置
配置文件在 /opt/module/zookeeper-3.5.7/conf
1. 复制zoo.cfg.dynamic.next 改名为 zoo.cfg
cp zoo_sample.cfg zoo.cfg
2. 修改zoo.cfg文件
vi zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData(原来配置文件中有,只需要修改目录)
# 下面三个需要新增
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
3. 新建目录
在/opt/module/zookeeper-3.5.7 新建 zkData 文件夹
mkdir zkData
在zkData文件夹新建文件myid,里面输入1
vi myid
4. 配置环境变量
vi /etc.profile
添加如下内容:
#ZOOKEPPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export PATH=$PATH:$ZOOKEEPER_HOME/bin
使环境变量生效
source /etc/profile
3、分发
1,将环境变量文件分发给slave1和slave2
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
2,将zookeeper安装包分发给slave1和2
scp -r /opt/module/zookeeper-3.5.7/ root@slave1:/opt/module/
scp -r /opt/module/zookeeper-3.5.7/ root@slave2:/opt/module/
3,需要修改slave1和slave2上的myid文件
slave1:myid修改为2
vi /opt/module/zookeeper-3.5.7/zkData/myid
slave2:myid修改为3
vi /opt/module/zookeeper-3.5.7/zkData/myid
4,使slave1和2的环境变量生效
source /etc/profile
4、启动
三台机器都执行:
cd /opt/module/zookeeper-3.5.7/
./bin/zkServer.sh start
三台机器都启动成功之后,使用jps查看是否有QuorumPeerMain进程
./bin/zkServer.sh status
查看当前zookeeper的mode,有一台机器是leader,另外两台是follower
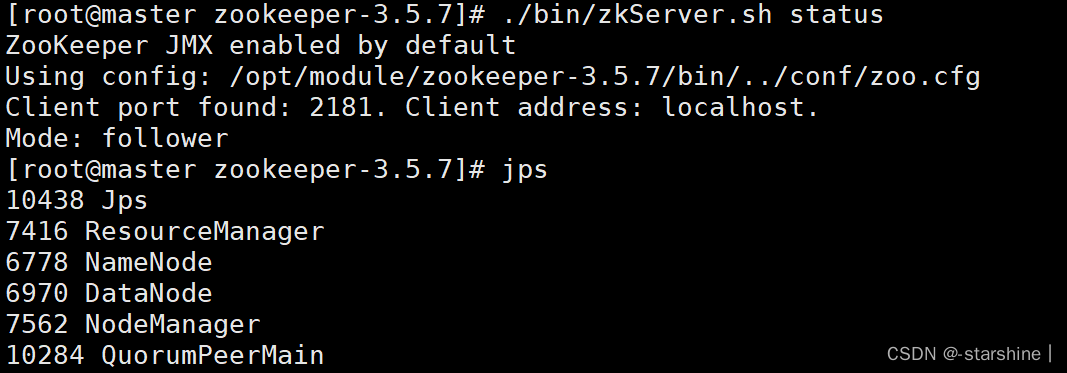
5、完成!
三、Kafka安装配置
需要配置好zookeeper,其中zookeeper使用集群模式,分别在master,slave1,slave2作为其节点(若zookpeer已安装配置好,则无需再次配置)
1、解压/
1. 将kafka安装包解压到/opt/module目录下
tar -zxvf /opt/software/kafka_2.12-2.4.1.tgz -C /opt/module/
2. 改名(可不做)
mv kafka_2.12-2.4.1/ kafka-2.4.1
2、配置
1. 配置环境变量
vi /etc/profile
添加内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
2. 修改文件 server.properties
vi /opt/module/kafka-2.4.1/config/server.properties
内容:
broker.id=0 (原本有,不用改)
log.dirs=/opt/module/kafka-2.4.1/logs(原本有,需要改)
zookeeper.connect=master:2181,slave1:2181,slave2:2181/kafka(原本有,需要改)
3、分发
1,给slave1和2 分发环境变量文件
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
2,分发安装包
scp -r /opt/module/kafka-2.4.1/ root@slave1:/opt/module/
scp -r /opt/module/kafka-2.4.1/ root@slave2:/opt/module/
3,修改slave1和2的配置文件
slave1:
vi /opt/module/kafka-2.4.1/config/server.properties
将 broker.id=0 改成 broker.id=1
slave2:
vi /opt/module/kafka-2.4.1/config/server.properties
将 broker.id=0 改成 broker.id=2
4,使环境变量生效
三台机器:
source /etc/profile
4,验证
使用kafka-server-start.sh --version查看kafka的版本内容

5,任务
在每个节点启动Kafka,创建topic,其中toipic名称为installtopic,分区数为2,副本数为2
1,在三个节点的/opt/module/kafka-2.4.1/config目录下,使用命令:kafka-server-start.sh -daemon server.properties
cd /opt/module/kafka-2.4.1/config
kafka-server-start.sh -daemon server.properties
使用jps查看,三个节点都有kafka
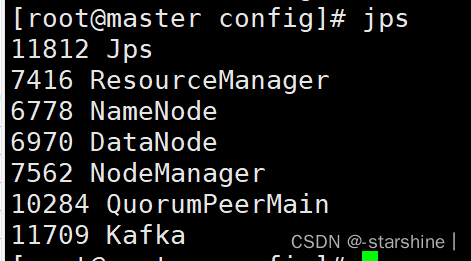
2,创建命令:
kafka-topics.sh --create --bootstrap-server master:9092 --replication-factor 2 --partitions 2 --topic installtopic
3,创建结果
kafka-topics.sh --bootstrap-server master:9092 --list

6,配置完成
四、HBase2.x分布式安装配置
确认是否完成Hadoop和Zookeeper的分布式(Hadoop伪分布式不可以)安装部署,没有的话请进行安装部署并启动。
1、解压
1. 将Master节点Hbase安装包解压到/opt/module目录下
tar -zxvf /opt/software/hbase-2.2.3-bin.tar.gz -C /opt/module/
2、配置
1. 配置环境变量
vi /etc/profile
添加内容:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.2.3
export PATH=$PATH:$HBASE_HOME/bin
2. 修改 hbase-site.xml 文件
位于:/opt/module/hbase-2.2.3/conf
cd /opt/module/hbase-2.2.3/conf
vi hbase-site.xml
添加内容:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
3、分发
1. 将解压包以及环境变量配置文件分发至slave1、slave2中
scp -r /etc/profile root@slave1:/etc/profile
scp -r /etc/profile root@slave2:/etc/profile
scp -r /opt/module/hbase-2.2.3/ root@slave1:/opt/module/
scp -r /opt/module/hbase-2.2.3/ root@slave2:/opt/module/
# 使环境变量生效
# 在三个节点,都需要执行
source /etc/profile
2. 启动hbase
在master:start-hbase.sh
4、任务
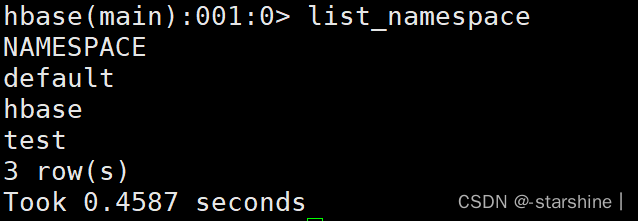
正常启动后在hbase shell中查看命名空间
hbase shell 进入方式:master直接输入 hbase shell
查看命名空间:list_namespace
五、ClickHouse单机安装配置
1、解压
1. 将Master节点ClickHouse相关安装包解压到/opt/module/clickhouse目录下
tar -zxvf clickhouse-client-21.9.4.35.tgz -C /opt/module/clickhouse/
tar -zxvf clickhouse-common-static-21.9.4.35.tgz -C /opt/module/clickhouse/
tar -zxvf clickhouse-common-static-dbg-21.9.4.35.tgz -C /opt/module/clickhouse/
tar -zxvf clickhouse-server-21.9.4.35.tgz -C /opt/module/clickhouse/
2. 执行启动各个相关脚本
cd /opt/module/clickhouse
./clickhouse-client-21.9.4.35/install/doinst.sh
./clickhouse-common-static-21.9.4.35/install/doinst.sh
./clickhouse-common-static-dbg-21.9.4.35/install/doinst.sh
./clickhouse-server-21.9.4.35/install/doinst.sh
####如果让输入密码直接回车,不要输入任何密码
3. 设置远程访问并移除默认监听文件(listen.xml),同时由于9000端口被hadoop占用,需要将clickhouse的端口更改为9001
进入ClickHouse的配置目录:
cd /etc/clickhouse-server
给文件config.xml给权限:chmod 777 config.xml
编辑config.xml文件:
取消掉<!-- <listen_host>0.0.0.0</listen_host> -->的注释变为:<listen_host>0.0.0.0</listen_host>
将里面所有的9000变成9001
4. 启动clickhouse,启动后查看clickhouse运行状态
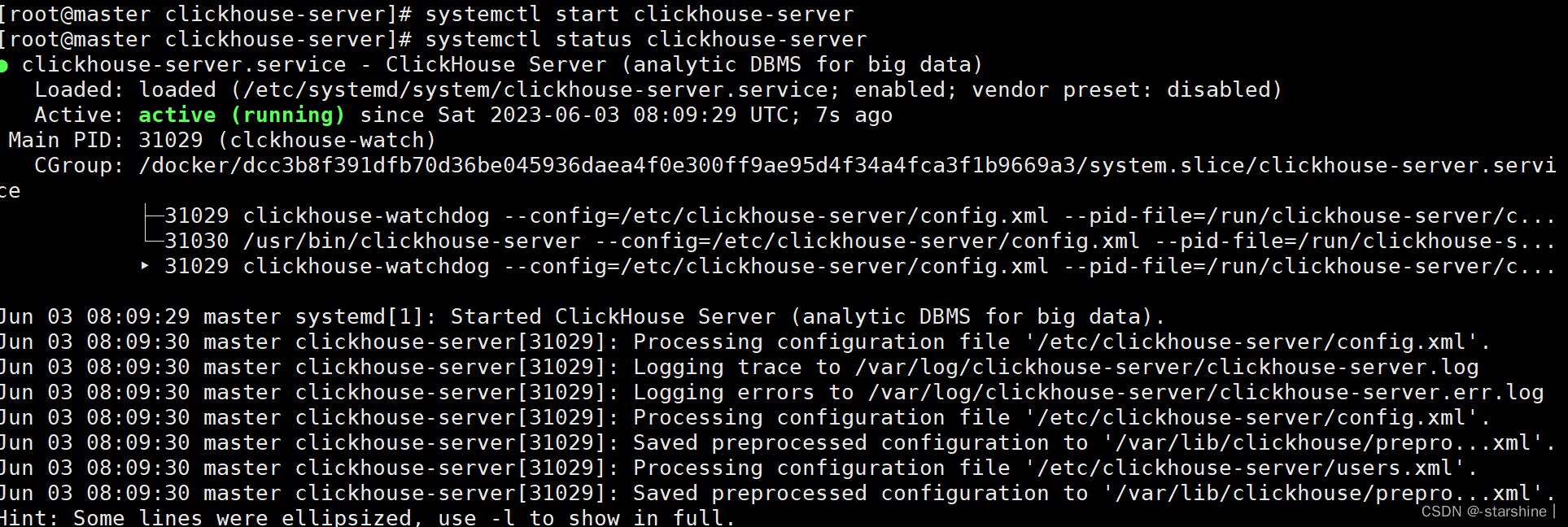
- 启动clickhouse:
systemctl start clickhouse-server - 查看clickhouse运行状态:
systemctl status clickhouse-server

![[推荐]SpringBoot,邮件发送附件含Excel文件(含源码)。](https://img-blog.csdnimg.cn/e042371eadb9418c9f7e3195067cf0dc.png)





![function函数指针和lamada的[]和[=]注意事项](https://img-blog.csdnimg.cn/22f57631de824d378f942b735535e9f8.png)