作为多模态人工智能技术领域的翘楚,Jina AI 的愿景是铺平通往多模态 AI 的未来之路。今天,Jina AI 在向着该愿景前进的路上,达成了一个重要里程碑。我们正式发布了自主研发的第二代文本向量模型:jina-embeddings-v2,是全球唯一能支持 8K(8192)输入长度的开源向量模型。
作为多模态人工智能技术领域的翘楚,Jina AI 的愿景是铺平通往多模态 AI 的未来之路。今天,Jina AI 在向着该愿景前进的路上,达成了一个重要里程碑。我们正式发布了自主研发的第二代文本向量模型:jina-embeddings-v2,是全球唯一能支持 8K(8192)输入长度的开源向量模型。
据 MTEB 排行榜显示,jina-embeddings-v2 与 OpenAI 的专有模型 text-embedding-ada-002 在性能方面不相上下。目前,仅 Open AI 与 Jina AI 两家人工智能技术公司推出了 8k 长度的 Embedding 模型。
自该模型发布,迅速登上 HackerNews 榜首,并长时间霸榜,在全球范围内引发了业内人士的广泛讨论。
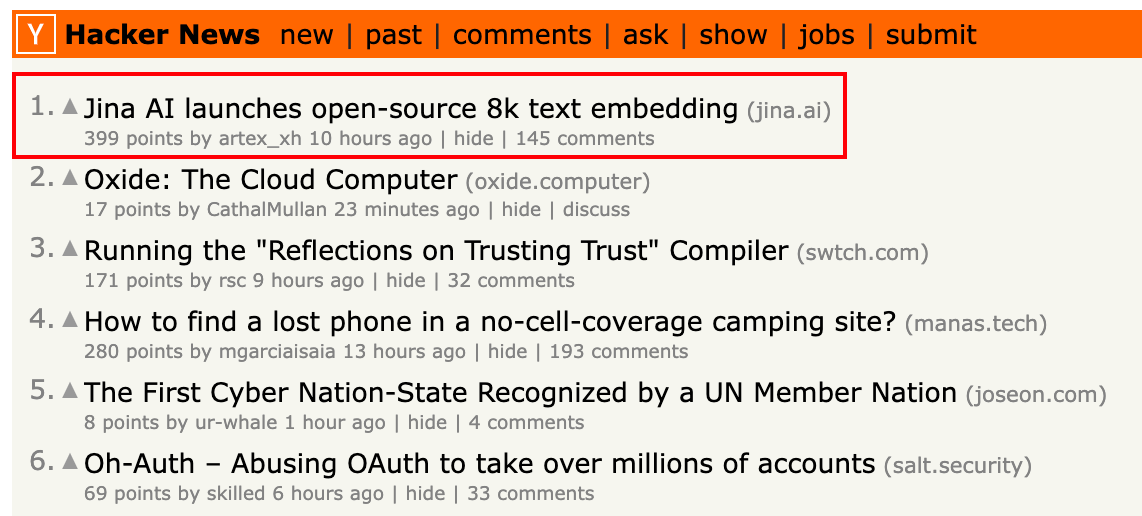

其中,“8K 长度”和“开源”这两点特别受到业界的瞩目,正如 HackerNews 上读者的评论所言,支持 8k 输入长度在表达能力和计算效率之间取得了可喜的平衡,而其中的关键,就在于 jina-embeddings-v2 独特的优势 —— 用更小的维度来实现高效地表征。

虽然 text-embedding-ada-002 已经广泛应用于各种不同场景,但其维度为 1536 维度的输出对于数据量巨大和价格敏感的开发者来说并不友好。 jina-embeddings-v2 通过提供 768(base)和 512(small)两种输出维度的选择,赋予了开发者更大的灵活性。这更意味着可以开发者可以实现更低的计算和存储成本,适用于更多的实际落地的场景。
 在 Jina AI,我们坚信开源技术之于创新、合作与社区力量的催化作用,所以 我们第一时间将模型开源,期待和社区一起共同打造开源 AI 生态。 我们的模型一经发布就迅速登上了 Huggingface Trending 榜单,更多详细信息请访问:https://huggingface.co/jinaai/jina-embeddings-v2-base-en。
在 Jina AI,我们坚信开源技术之于创新、合作与社区力量的催化作用,所以 我们第一时间将模型开源,期待和社区一起共同打造开源 AI 生态。 我们的模型一经发布就迅速登上了 Huggingface Trending 榜单,更多详细信息请访问:https://huggingface.co/jinaai/jina-embeddings-v2-base-en。

向量模型与 8k 输入长度
在传统的自然语言处理任务中,通常会将文本转化为一组数字进行表示,也就是向量。向量模型用于生成向量表示,被广泛应用于检索、分类、聚类或语义匹配等任务。
在大模型时代,向量模型的重要性进一步增强。尤其是在检索增强生成(RAG)场景中,它成为了一个核心组件,用于解决大模型的上下文长度限制、幻觉问题和知识注入问题。因为大模型通常有上下文长度的限制,我们需要一个有效的方法来压缩、存储和查询大量的信息。这就是向量模型的用武之地。在 RAG 系统中,文档首先被转化为向量。随后,大模型可以快速地查询这些向量,找到与当前上下文相关的文档,再基于这些文档生成回复。
然而,目前的大部分开源向量模型都是仅支持最大 512 长度(大约 500 个汉字)的输入长度,这使得开发者无法表征长文本的语义。jina-embeddings-v2 支持最大 8k 长度的输入,突破了长文本向量表示的瓶颈,让开发者可以更自由的对文本信息进行不同语义颗粒度的完整表示,从而更精准的表示文本语义。 这不仅可以帮助开发者提高 RAG 场景下大模型回复的准确性,而且适用于各种处理长文本的场景,例如处理数十页的报告综述、长篇故事推荐等。
与 text-embedding-ada-002 模型对比测试
与 OpenAI 的 text-embedding-ada-002 相比,jina-embeddings-v2 展现出不俗的实力。下表为两模型的性能对比。

值得注意的是,jina-embeddings-v2 在文本分类任务、检索任务、检索重排任务、和文本摘要任务上的得分都超过了 text-embedding-ada-002。
拥抱开源
OpenAI 已经为我们展示了 8K 上下文长度模型的潜力,但 jina-embeddings-v2 不仅与其齐头并进,还做出了更大胆的决策:完全开源!这意味着任何人都可以使用、修改和进一步优化这款模型。
不仅如此,当我们与 OpenAI 的模型进行直接比较时,jina-embeddings-v2 在多个关键指标上展现出了优越的性能。考虑到 jina-embeddings-v2 是开源的,我们坚信通过社区的集体智慧和努力,我们将有机会超越目前的标杆。
正是因为我们坚信开放和共享的价值,我们希望与全球的研究者、工程师和 AI 爱好者共同努力,不断完善和推进这款模型。我们也在计划中继续拓展功能,例如提供更多语言的支持,以及开发更为强大的 API 平台。
特点和优势
全新的向量模型发布,再次证明了我们在技术创新上面的决心, jina-embeddings-v2 并非对前代模型的简单修订,而是经过了深入研发和优化后的全新设计,我们团队付出了很多努力,从数据收集、处理再到模型调优,使得 v2 模型在性能表现上有了质的飞跃。
此外,jina-embeddings-v2 支持 8K 输入长度,与其他领先的向量模型相比,在长文本任务中展现出了明显的优势,突显了其扩展上下文长度的实际价值。这一特点也为很多实际应用提供了更多可能性,比如法律文件解读、医学文献研究、深入的文学分析、金融数据洞察和聊天机器人的应答优化等等。
对于想要使用 jina-embeddings-v2 的开发者和研究者,我们在 Huggingface 平台上提供了两种规模的模型,以适应不同场景和需求:
jina-embeddings-v2-base-en
-
大小:0.27G(fp16),0.54G(fp32) -
参数数量:1.37 亿 -
适用场景:适合处理需要高精度的大型任务 -
下载链接:https://huggingface.co/jinaai/jina-embeddings-v2-base-en
jina-embeddings-v2-small-en
-
大小:0.07G -
参数数量:0.33 亿 -
适用场景:特别为轻量级的应用场景设计,如移动端应用或那些计算能力有限的设备上的任务 -
下载链接:https://huggingface.co/jinaai/jina-embeddings-v2-small-en
回顾本次发布历程,Jina AI 创始人兼 CEO 肖涵博士说:
“在 AI 技术快速发展的今天,始终保持前沿并向公众开放最新研究成果是我们的核心追求。有了 jina-embeddings-v2,我们达成了一个重要的里程碑。我们不仅开发了全球首款开源 8K 上下文长度的模型,而且其性能能够与 OpenAI 这样的行业巨头相匹敌。Jina AI 的目标很明确:我们希望推动 AI 民主化,让更多的人能够使用且受益,而不只是那些拥有大量资源的大公司。今天,我可以很自豪地说,我们朝着这一愿景迈出了坚实的一步。”
展望未来
Jina AI 深信开源的魔力,并致力于为 AI 社区构建前沿且易于接入的工具。接下来,我们还会推动以下几项重要工作:
-
分享学术成果:为了让社区更好地了解 jina-embeddings-v2 的性能和特点,团队将很快发布一篇详细的学术文章,深入介绍模型的技术细节,以及和其他模型的比较分析。
-
API 平台:我们正在努力构建一个 Embedding API 平台,其功能和 OpenAI 类似,帮助用户能够根据自己的需求,更轻松地使用我们的向量模型。
-
多语言支持:Jina AI 正着手引入多语种,下一步计划推出德文/英文以及中文/英文的双语模型,并进一步增强我们模型的能力。

本文由 mdnice 多平台发布