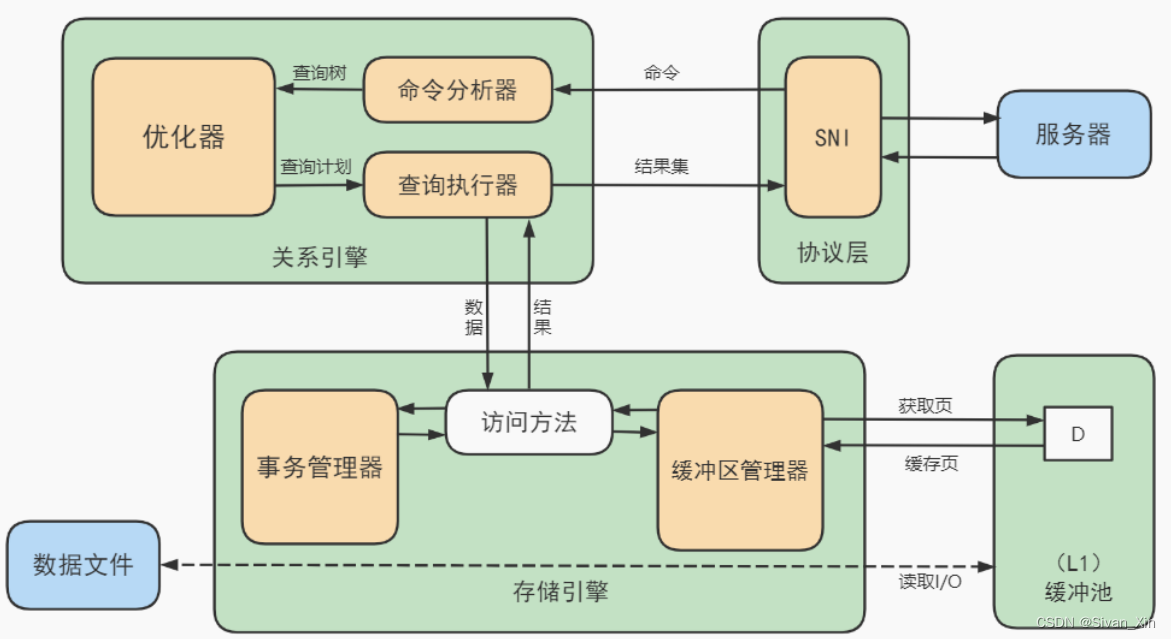
作者:CuteXiaoKe
微信公众号:CuteXiaoKe | 原文
最近收到大家很多的私信提问,也是大家比较关心的问题:如果我有一个PDF,我该如何使用iText获取PDF里面的内容呢,比如文本、图片、表格等。iText官方给出了相关的整体解决思路,在这我给大家翻译并总结一下。在这里主要是抛砖引玉,后续会结合具体例子来解决我们实际过程中的出现的问题。
本文章的主要关注内容如下:
- 为什么需要数据提取?
- 不同类型的PDF文档
- 什么是结构化、半结构化和非结构化的文档?
- 自动化数据提取、智能文档处理等
- 基于模板的提取的好处
1. PDF和数据提取
自1993年推出PDF以来,它已成为正式文档和图形丰富内容的事实标准。不难看出原因;在PDF之前,无论收件人的软件、硬件或操作系统如何,都无法可靠地共享文档,包括任何文本格式、图像等。PDF著名并受大家信赖的原因就是:无论是在屏幕上还是在打印中,都能确保一致的输出。
作为一种通用且可靠的数字文档格式,它是发送和接收商业文档(如发票和采购订单)的常用方式,目的是交换可移植和安全的内容。在现代商业世界中,越来越需要高效地捕获和提取此类文档中包含的数据,理想情况下使用自动化流程。
然而,由于多种原因,提取数据并转换为可用的格式可能具有挑战性。让我们探讨PDF数据提取的挑战和解决方案。
2. 什么时候一个PDF文件并不是PDF?
并非所有PDF都是一样的。如果使用软件应用程序将发票等PDF文档打印为PDF格式,并以数字方式创建,则其内容将直接嵌入文档中。可以使用iText 7 Core等库或iText pdf2Data等更友好的解决方案以编程方式直接提取。您可能会看到类似这样的PDF被称为真(true)、原生(natice)PDF或数字生成(digitally-born)等。
然而,如果您想要获得可用(和可重用)的输出,则需要对PDF进行标签话处理,以识别和提供有关文档结构元素的元信息。在发票的示例中,此类标签将标识发票日期、供应商地址等。
带标签PDF(详见学习笔记第张)是PDF/A标准(用于长期存档)和PDF/UA标准(用于通用可访问性)的主要要求之一。这些可以被认为是PDF的“黄金标准”,因为它们使文档中的数据和内容更易于访问,具有清晰和逻辑的结构。当然,这些标准不仅仅是标签,你可以在上面链接的iText的专用解决方案页面上找到更多关于它们和创建此类文档的解决方案的信息。
问题是,虽然可以创建结构良好的PDF文档,但在处理发票或采购订单时不太可能遇到它们。PDF发票通常只是纸质发票的数字版本,您需要处理的大多数商业文档都是没有任何标签内容的PDF。一个明显的例外是电子发票格式,如ZUGPerd,它使用PDF/A-3容器功能将发票数据以机器可读的XML格式嵌入原始发票中。
最坏的情况是,如果原始文档是扫描的纸质副本,那么PDF可能只是扫描图像的容器。在这种情况下,需要依靠OCR来识别嵌入到PDF中的文本,甚至需要在考虑处理或重用之前采用某种手段重新生成内容。不过,我们稍后将讨论OCR预处理。
3. 结构化、半结构化和非结构化文档
通常,文档可以分为三类:结构化、半结构化和非结构化。了解它们之间的差异是选择正确选项以自动从文档中提取数据的关键。
| 文档分类 | 格式 | 样例 |
|---|---|---|
| 结构化 | 固定且可预测 | 政府/组织表格、身份证/护照等。 |
| 半结构化 | 可预测的格式,尽管不同组织的格式有所不同 | 发票、采购订单、银行对账单等。 |
| 非结构化 | 没有预定义的格式或结构 | 电子邮件、法律合同、文章等。 |
需要注意的是,我们并没有像上一节所讨论的那样引用PDF结构树中的标签。相反,它只是对不同类型文档的格式和布局的描述。
因此,这些是自动PDF数据提取的挑战。解决方案呢?
4. 自动化数据提取
从业务文档中提取数据的传统方法需要有人手动从文档中传输数据。当然,这需要大量的时间和资源,需要考虑输入错误或安全问题的风险。如果您能够以可靠和安全的方式自动化此过程,该怎么办?
近年来,业务流程自动化变得越来越重要。智能文档处理(IDP)是一组智能处理文档的技术,帮助企业尽可能简单高效地提取和存储数据。
许多IDP解决方案使用机器学习(ML)和自然语言处理(NLP)等人工智能(AI)技术来分类和提取数据。这样的解决方案可以产生很好的结果,尤其是在处理非结构化文档时。
人工智能并不是一颗神奇的子弹——它需要广泛的训练才能产生准确的结果和人类的监督。除此之外,对文档格式的任何更改都需要重新训练检测模型。
对于更结构化的文档,更有效的方法是利用其布局的可预测性。
5. 基于模板的提取
虽然人工智能和相关技术对于处理结构化程度较低的文档(如电子邮件)特别有用,但结构化(正式表格、护照、身份证等)和半结构化文档(发票、银行对账单等)可以使用更基于规则的方法更有效地处理。
如果我们以发票文档为例,地址、采购订单号和类似的文档元素往往位于一个位置,并且只有项目描述、数量和成本等内容在发票之间发生变化。通过使用示例发票作为模板,可以定义要捕获的数据所在的文档区域并对其进行分类。
这是iText pdf2Data用于数据提取的方法。iText pdf2Data是一种解决方案,它通过在模板中定义与要提取的内容相对应的区域和规则,提供了从此类PDF文档中提取数据的简单方法。然后可以用其他文档对模板进行视觉验证,以确认数据被正确识别。
然后,匹配该模板的所有后续文档都可以自动解析,无需任何用户干预。您只需要一个示例文档即可实现可靠的自动数据提取。
与基于AI的替代方案不同,您不需要数百个样本和密集的监督来训练识别过程。内容识别由您配置的模板控制,这意味着您可以立即开始提取数据。
人工智能识别也有其他缺点。对所需输出的任何更改(如添加新字段)都需要对模型进行重新训练,并且多语言支持充其量是最少的。使用相同布局但包含不同语言内容的文档可能会产生极不一致的结果。
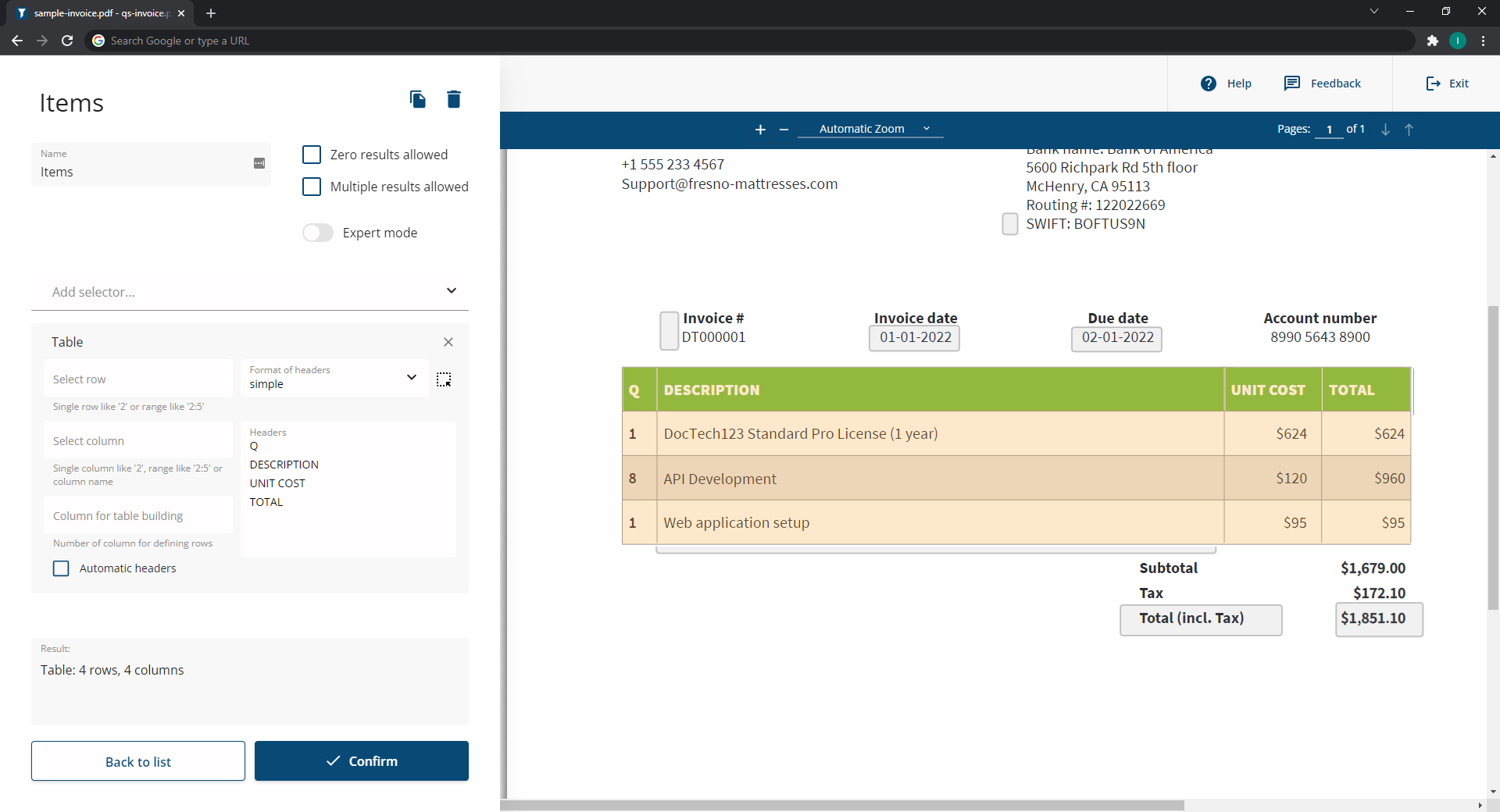
在一方面,iText pdf2Data没有这些缺点。对模板进行修改既快速又简单,而且提供了出色的语言支持。它还提供了强大的表识别功能,这是其他数据提取解决方案的确实的功能之一,如图1.1所示。
6. OCR有用吗
iText pdf2Data包含自动化PDF数据提取工作流所需的全部内容,但如果您需要数字化纸质文档或处理仅为扫描图像的PDF文档,该怎么办?这就是需要OCR解决方案的地方。
我们为iText 7 Core PDF库提供了pdfOCR插件,它可以将扫描的文档和图像转换为PDF(如果您需要长期存档合规性,也可以转换为PDF/A-3u),以便iText pdf2Data处理。根据您的需求,使用iText 7 Core执行其他预处理或后处理任务,或iText 7 Suite中提供的任何其他附加组件,也可能会使您的工作流程受益。
7. iText pdf2Data工作原理
通过使用基于浏览器的直观便捷的pdf2Data Editor,可以轻松创建数据提取模板。通过为感兴趣的区域定义数据字段选择器,只需基于示例文档创建模板PDF。选择器是可配置的规则,用于检测不同类型的内容以进行提取,许多选择器可以组合以微调检测参数。
有大约20个选择器可供选择,使iText pdf2Data能够智能地识别和提取文本以及图像或条形码等其他内容。选择器可配置为检测:
- 页面范围和页面上的位置
- 特定的字体样式、字体颜色和文本模式
- 固定数据旁边的关键字
- 表结构的自动识别
与我们的文档生成解决方案iText DITO类似,iText pdf2Data允许任何人利用iText强大的PDF功能,而不仅仅是开发人员。通过以智能和结构化的方式从文档中智能地提取数据,可以轻松地将数据重新用于分析、报告或任何您需要的用途。
开发人员只需要部署pdf2Data Editor并将pdf2Data SDK集成到文档工作流中。从那时起,您可以配置模板,验证数据,并将iText pdf2Data设置为工作状态。
一旦iText pdf2Data组件被部署并集成到自动化文档工作流中,创建或优化文档模板以识别和自动提取数据就很简单,然后任何需要它的人都可以轻松地重用这些数据。
注意:然而说了这么多,pdf2Data其实是闭源的,只有30天免费试用。iText家族所有插件是否开源请参考链接
后续我会继续尝试其他方法、其他工具提取发票、订单等信息,敬请关注支持