1.系统下的文件操作:
❓是不是只有C\C++有文件操作呢?💡Python、Java、PHP、go也有,他们的文件操作的方法是不一样的啊
1.1对于文件操作的思考:
我们之前就说过了:文件=内容+属性
针对文件的操作就变成了对内容的操作和对属性的操作
❓当文件没有被操作的时候,文件一般会在什么位置?💡磁盘
❓当我们对文件进行操作的时候,文件需要在哪里?💡内存❓为什么呢?💡因为冯诺依曼体系结构
❓通常我们打开文件、访问文件和关闭文件,是谁在进行相关操作?

运行起来的时候,才会执行对应的代码,然后才是真正的对文件进行相关的操作。
实际上是 进程在对文件进行操作! 在系统角度理解是我们曾经写的代码变成了进程。
进程执行调度对应的代码到了 fopen,write 这样的接口,然后才完成了对文件的操作。
当我执行 fopen 时,对应地就把文件打开了,所以文件操作和进程之间是撇不开关系。
❓当我们对文件进行操作的时候,文件需要提前被load到内存❓load是内容or属性?💡至少得有属性吧
❓当我们对文件进行操作的时候,文件需要被提前lod到内存,是不是只有你一个人在load呢?
💡不是,内存中一定存在大量不同文件的属性、
所以综上,打开文件本质就是将需要的文件属性加载到内存中,OS内部一定一定会同时存在大量的被打开的文件,❓那么操作系统要不要管理这些被打开的文件呢?
💡先描述再组织
先描述,构建在内存中的文件结构体struct file (就可以从磁盘来,struct file*next),被打开的文件
每一个被打开的文件,都要被OS内对应文件对象的struct结构体,可以将所有的struct file结构体用某种数据结构连接起来——在os内部,对被打开的文件进行管理,就被转换成为了对链表的增删查改
结论:文件被打开,OS要为被打开的文件,创建对应的内核数据结构
struct file
{
//各种属性
//各种连接关系
}
文件其实可以被分为两大类:磁盘文件、被打开的文件(内存文件)
❓文件被打开,是谁在打开呢?💡OS,但是是谁让OS打开的呢?用户(进程为代表)
我们之前的所有的文件操作,都是进程和被打开文件的关系
都是进程和被打开文件的关系:struct task_struct和struct_file
快速回忆一下c语言的文件操作(fopen,fwrite等)
#include<stdio.h>
#define LOG "log.txt"
int main()
{
FILE*fp=fopen(LOG,"w");
if(fp==NULL)
{
perror("fopen");
return 1;
}
const char*msg="hello xiaolu,hello 107";
int cnt=5;
while(cnt)
{
fputs(msg,fp);
cnt--;
}
fclose(fp);
return 0;
}
默认如果只是打开,文件内容会自动被清空,同时,每次进行写入的时候,都会从最开始进行写入
1.2文件操作模式:
r:只读模式,打开一个已存在的文本文件,允许读取文件。
r+:读写模式,打开一个已存在的文本文件,允许读写文件。
w:只写模式,打开一个文本文件并清除其内容,如果文件不存在,则创建一个新文件。
w+:读写模式,打开一个文本文件并清除其内容,如果文件不存在,则创建一个新文件。
a:追加模式,打开一个文本文件并将数据追加到文件末尾,如果文件不存在,则创建一个新文件。
a+:读写模式,打开一个文本文件并将数据追加到文件末尾,如果文件不存在,则创建一个新文件。
这些我们 在c语言中已经有了详细的讲解了,就不做解释了
2.文件系统接口
printf 一定封装了系统调用接口。而这个函数就是snprintf函数
所有的语言提供的接口,之所以你没有见到系统调用,因为所有的语言都被系统接口做了 封装。
所以你看不到对应的底层的系统接口的差别。为什么要封装?原生系统接口,使用成本比较高。
系统接口是 OS 提供的,就会带来一个问题:如果使用原生接口,你的代码只能在一个平台上跑。
直接使用原生系统接口,必然导致语言不具备 跨平台性 (Cross-platform) !
我们首先要明确一个概念,C语言接口和操作系统接口是上下级的关系,任何一个语言,不管是C、C++、java、Python都有自己打开文件关闭文件读写文件的库函数,但是这些库函数的使用都是在Linux和Windows系统下进行的,所以任何语言的接口和系统接口是一种上下级的关系。
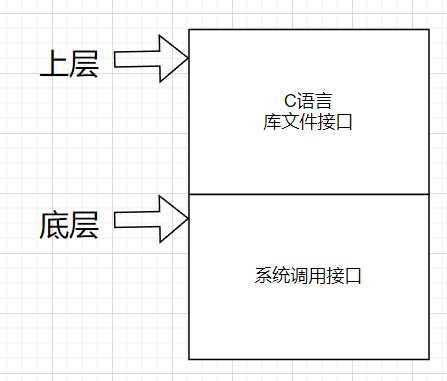
在系统调用接口中,我们打开文件使用open、关闭文件close、写入write、读取read。那这些接口和C中库函数接口有什么联系呢?我们可以这样理解:C中调用得这些库函数底层一定封装了系统调用接口,可以认为fopen底层调用open,fclose底层调用close,fread底层调用read,fwrite底层调用write。我们在windows中打开文件,windows底层也有一套自己的windows相关的api系统接口,当我们在windows使用C的库函数时,C调用的就是windows下的系统接口。这样在语言层面上就实现了跨平台性。
2.1文件打开:open()
打开文件,在 C 语言上是 fopen,在系统层面上是 open。
open 接口是我们要学习的系统接口中最重要的一个,没有之一!所以我们放到前面来讲。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
这里的参数有点抽象,我来给大家解释一下
-
pathname: 要打开或创建的目标文件
-
flags: 打开文件时,可以传个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
其中flags为标志位,并且它是个整数类型(C99 标准之前没有 bool 类型)
标记位实际上我们造就用过了,比如定义 flag 变量,设 flag=0,设 flag=1,传的都是单个的。
❓ 思考:但如果我想一次传递多个标志位呢?定义多个标记位?flag1, flag2, flag3…
那我要传 20 个呢,定义 20 个标记位不成?遇到不确定传几个标志位的情况下,该怎么办?
我们看看写底层的大佬是如何解决的:
👑 方案:系统传递标记位是通过 位图 来进行传递的。
如果你要创建这个文件,该文件是要受到 权限的约束的!
创建一个文件,你需要告诉操作系统默认权限是什么。
当我们要打开一个曾经不存在的文件,不能使用两个参数的 open,而要使用三个参数的 open!
也就是带 mode_t mode 的 open,这里的 mode 代表创建文件的权限:
int open(const char* pathname, int flags, mode_t mode);
文件描述符(open对应的返回值)本质就是数组下标
2.2文件关闭:close()
#include <unistd.h>
int close(int fd);
该接口相对 open 相对来说比较简单,只有一个 fd 参数,我们直接看代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h> // 需引入头文件
int main(void)
{
umask(0);
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd); // 关闭文件
return 0;
}

2.3文件写入:write()
#include <unistd.h>
ssize_t write(int fd, const void* buf, size_t count);
write 接口有三个参数:
- fd:文件描述符
- buf:要写入的缓冲区的起始地址(如果是字符串,那么就是字符串的起始地址)
- count:要写入的缓冲区的大小
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h> // 需引入头文件
int main(void)
{
umask(0);
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
int cnt = 0;
const char* str = "hello xiaolu!\n";
while (cnt < 5) {
write(fd, str, strlen(str));
cnt++;
}
close(fd);
return 0;
}
这里strlen(str)不可以+1,+1就会把\0写出来,但是vim是没有\0的,因此会出现乱码
顺便教一个清空文件的小技巧: > 文件名 ,前面什么都不写,直接重定向 + 文件名:
$ > log.txt

3.系统传递标记位
通过上文的讲解,想必大家已对文件系统基本的接口有一个简单的了解,接下来我们将继续深入讲解,继续学习系统传递标志位,介绍 O_WRONLY, O_TRUNC, O_APPEND 和 O_RDONLY。
3.1.O_WRONLY 没有像 w 那样完全覆盖?
C语言在 w模式打开文件时,文件内容是会被清空的,但是 O_WRONLY 好像并非如此?
当前我们的 log.txt 内有 5 行数据,现在我们执行下面的代码:
int main(void)
{
umask(0);
// 当我们只有 O_WRONLY 和 O_CREAT 时
int fd = open("log.txt", O_WRONLY | O_CREAT, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
// 修改:向文件写入 2 行信息
int cnt = 0;
const char* str = "666\n"; // 修改:内容改成666(方便辨识)
while (cnt < 2) {
write(fd, str, strlen(str));
cnt++;
}
close(fd);
return 0;
}

❓O_WRONLY 怎么没有像 w 那样完全覆盖???
我们以前在 C语言中,w 会覆盖把全部数据覆盖,每次执行代码可都是会清空文件内容的。
而我们的 O_WRONLY 似乎没有全部覆盖,曾经的数据被保留了下来,并没有清空!
其实,没有清空根本就不是读写的问题,而是取决于有没有加 O_TRUNC 选项!
因此,只有 O_WRONLY 和 O_CREAT 选项是不够的:
如果想要达到 w 的效果还需要增添 O_TRUNC
如果想到达到 a 的效果还需要 O_APPEND
下面我们就来介绍一下这两个选项!
3.2.O_TRUNC 截断清空(对标 w)
在我们打开文件时,如果带上 O_TRUNC 选项,那么它将会清空原始文件。
如果文件存在,并且打开是为了写入,O_TRUNC 会将该文件长度缩短 (truncated) 为 0。
也就是所谓的 截断清空 (Truncate Empty) ,我们默认情况下文件系统调用接口不会清空文件的,
但如果你想清空,就需要给 open() 接口 带上 O_TRUNC 选项:
int main(void)
{
umask(0);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
// 向文件写入 2 行信息
int cnt = 0;
const char* str = "666\n";
while (cnt < 2) {
write(fd, str, strlen(str));
cnt++;
}
close(fd);
return 0;
}
3.3.O_APPEND 追加(对标 a)
现在我们用 open,追加是不清空原始内容的,所以我们不能加 O_TRUNC,得加 O_APPEND:
int fd = open("log.txt", O_WRONLY | O_CREATE | O_APPEND, 0666);
3.4.O_REONLY 读取
如果我们想读取一个文件,那么这个文件肯定是存在的,我们传 O_RDONLY 选项:
4.文件描述符:
在认识返回值之前,先来认识一下两个概念: 系统调用 和 库函数
- 上面的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
- 而, open close read write lseek 都属于系统提供的接口,称之为系统调用接口
- 回忆一下我们讲操作系统概念时,画的一张图
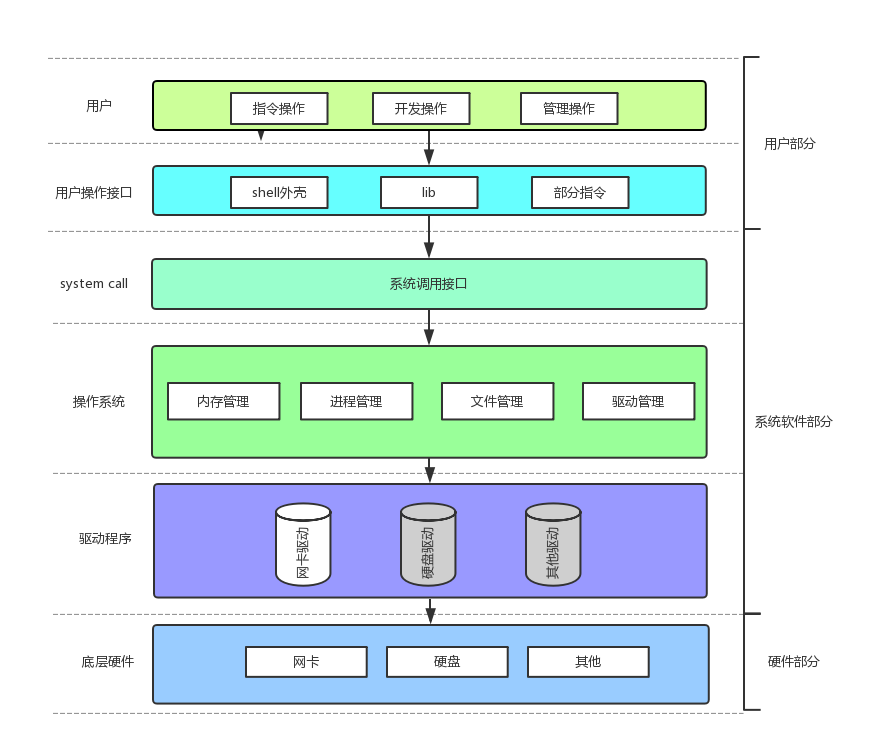
系统调用接口和库函数的关系,一目了然。
所以,可以认为,f#系列的函数,都是对系统调用的封装,方便二次开发。
任何一个进程,在启动的时候,默认会打开当前进程的三个文件:
标准输入 标准输出 标准错误
stdin stdout stderr C
cin cout cerr C++
输出和错误的区别:
#include<iostream>
#include<cstdio>
int main()
{
//C
printf("hello printf->stdout\n");
fprintf(stdout,"hello fprintf->stdout\n");
fprintf(stderr,"hello fprintf->stderr\n");
//C++
std::cout<<"hello cout->cout"<<std::endl;
std::cerr<<"hello cerr ->cout"<<std::endl;
return 0;
}

标准输入——设备文件->键盘文件
标准输出——设备文件->显示器文件
标准错误——设备文件->显示器文件
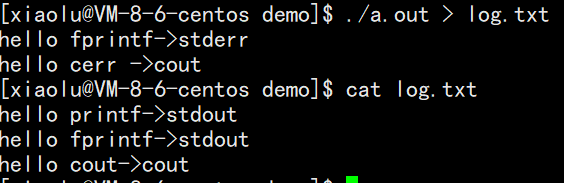
所谓的输出重定向是把输入和输出重定向到文件中,错误留在了显示器
标准输出和标准错误都会向显示器打印,但是其实是不一样的
0默认是标准输入
1默认是标准输出
2默认是标准错误
❓因为Linux下一切皆文件, 所以向显示器打印,本质上就是向文件中写入,如何理解?
相信各位读者应该都听过一个概念,C语言程序会默认打开3个输入输出流,其中这三个输入输出流对应的名为stdin,stdout,stderr,文件类型为FILE*,而FILE*是C语言的概念,底层对应的文件描述符,其中stdin对应0,stdout对应1,stderr对应2,换言之012被默认已经打开了,再打开时就是从3开始打开了,所谓的文件描述符,本质其实就是数组下标。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
char buf[1024];
ssize_t s = read(0, buf, sizeof(buf));
if(s > 0){
buf[s] = 0;
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
}
return 0;
}
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
4.1文件描述符底层原理
一个进程是可以可以打开多个文件的,无非就是多调用几次open,而我们的计算机中是同时存在大量进程的,而这些进程可能会打开各种各样的文件,所以系统中在任何时刻都可能存在大量已经打开的文件,操作系统的功能之一就是文件管理,就是要对这些打开的文件进行管理。
而我们都知道,所谓管理就是先描述再管理,底层中描述文件的数据结构叫做struce file,一个文件对应一个struct file,大量的文件就有大量的struct file,我们只需将这些数据结构用双链表连接起来,所以对文件的管理就变成了对双链表的增删改查。而我们现在要做的,这些已经被打开的文件那些文件属于某个特定的进程,就需要建立进程和文件的对应关系。
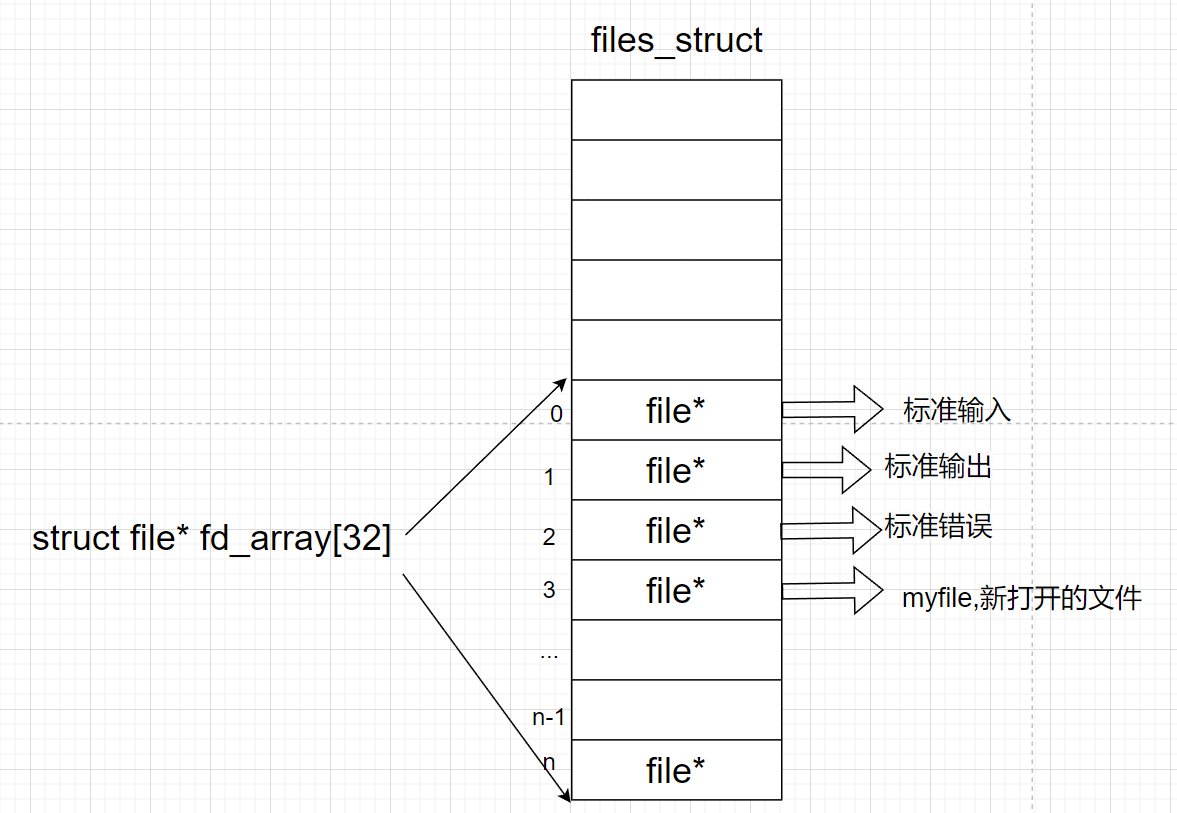
❓进程如何和打开的文件建立映射关系?打开的文件哪一个属于我的进程呢?
当一个程序加载了就是一个进程,进程就会有task_struct
当磁盘有一个文件,其实这个被打开的文件就会被os加载到内存,会在内存中创建一个files_struct包含了文件的大部分属性
我们进程的task_struct结构体中也会有一个struct files_struct*files指针指向下面这个结构体
在内核中,task_struct 在自己的数据结构中包含了一个 struct files_struct *files (结构体指针):
struct files_struct *files;
而我们刚才提到的 “数组” 就在这个 file_struct 里面,该数组是在该结构体内部的一个数组。
struct file* fd_array[32];
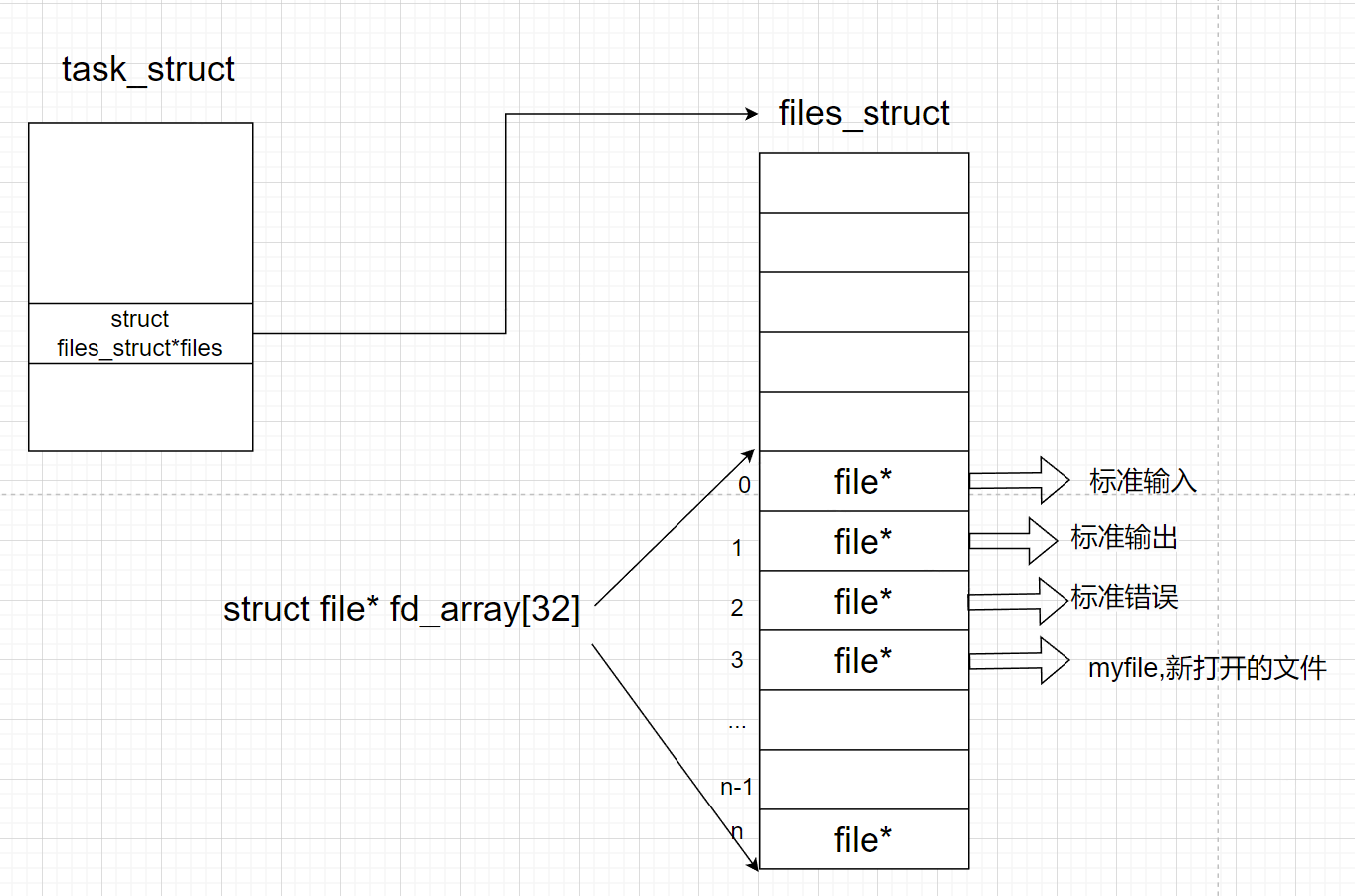
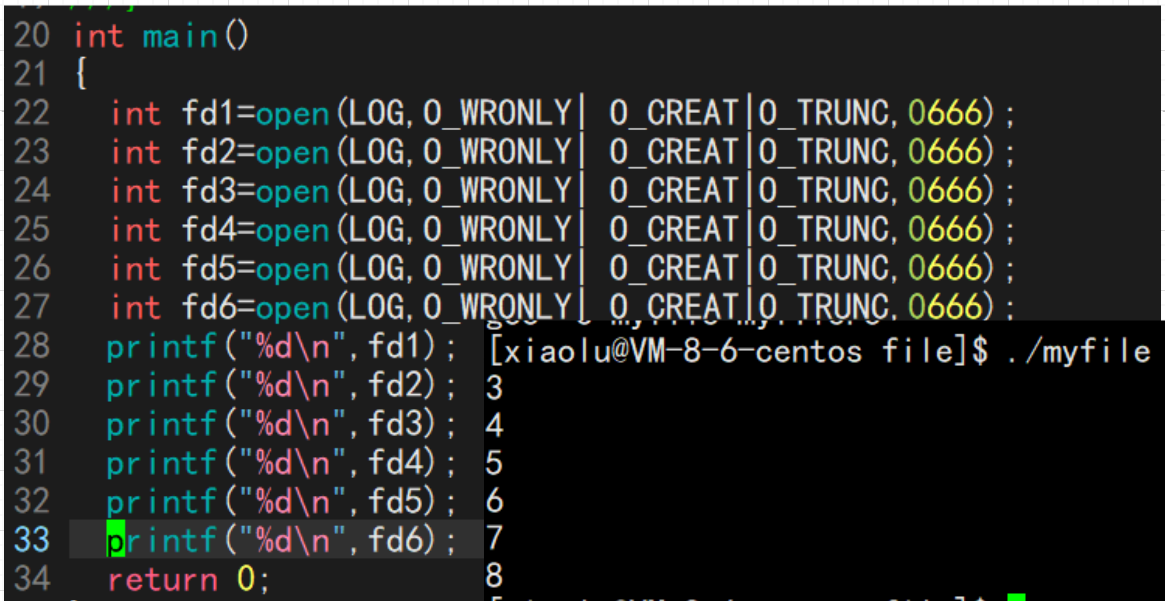
4.2文件描述符的分配规则
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}

关闭0或者2,在看
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
发现是结果是: fd: 0 或者 fd 2 可见
4.3理解:Linux 下一切皆文件
我之前一直说Linux下一切皆文件,我们一直不理解为什么,我们在这里来好好理解一下这个话题
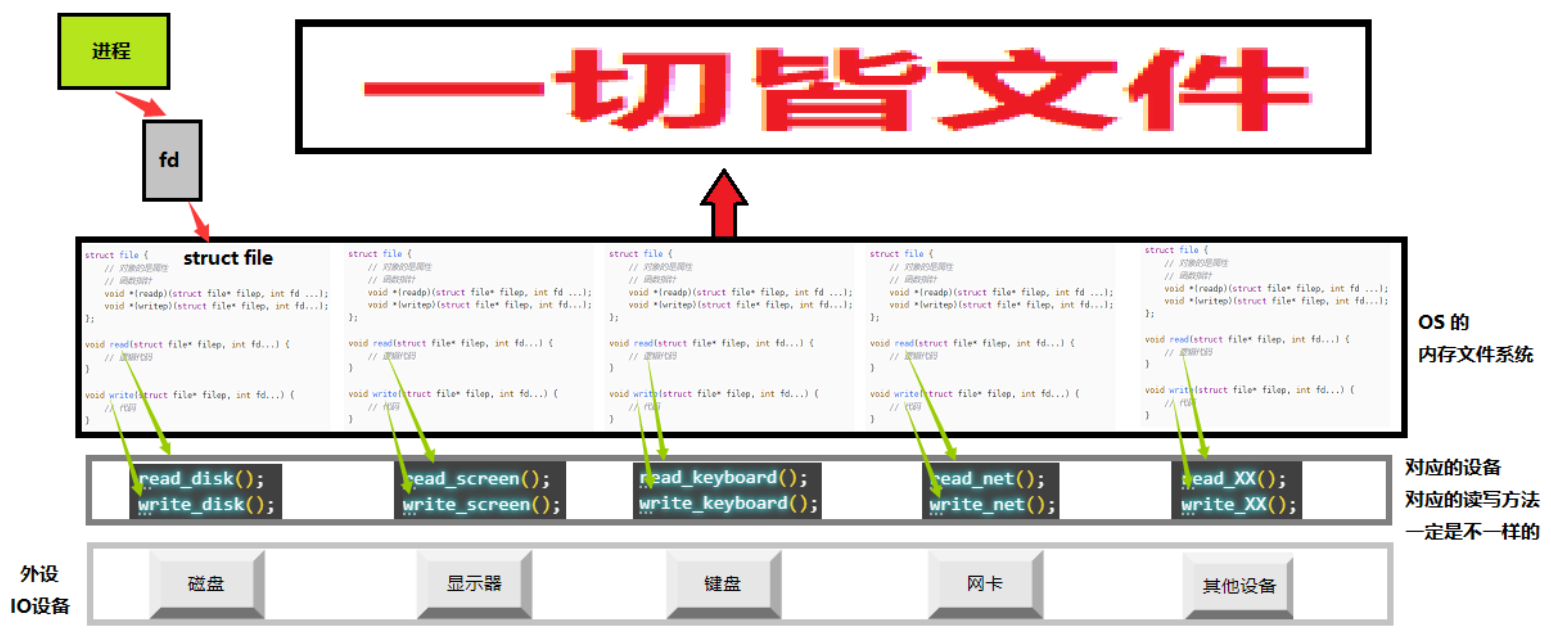
深灰色层:对应的设备和对应的读写方法一定是不一样的。
黑色层:看见的都是 struct file 文件(包含文件属性, 文件方法),OS 内的内存文件系统。
红色箭头:再往上就是进程,如果想指向磁盘,通过 找到对应的 struct file,根据对应的 file 结构调用读写方法,就可以对磁盘进行操作了。如果想指向对应的显示器,通过 fd 找到 struct file……最后调用读写,就可以对显示器操作了…… 以此类推。
我们会发现os将这些外设抽象成结构体,因此os在操作的时候就变成了对struct file_struct的操作了,也就是变成了对文件的操作
我们使用os的本质:
都是通过进程的方式进行os的访问!
操作系统层面,我们必须要访问fd(文件描述符),我们才能找到文件 ,然后语言层访问外设或者文件必须经历os
FILE是什么呢?谁提供的?和我们刚刚讲的内核的struct file有关系吗?
FILE是结构体,是C语言给你提供的,没有关系,要是硬扯的话就是上下层的关系
5.重定向
5.1fflush 函数
fflush 刷新缓冲区
int main(void)
{
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
fflush(stdout);
close(fd);
}

我们发现它内容不往显示器打印了,而变成在文件当中,这不就是重定向嘛!!!
此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中,fd=1。这种现象叫做输出重定向。常见的重定向有:>, >>, <
那重定向的本质是什么呢?
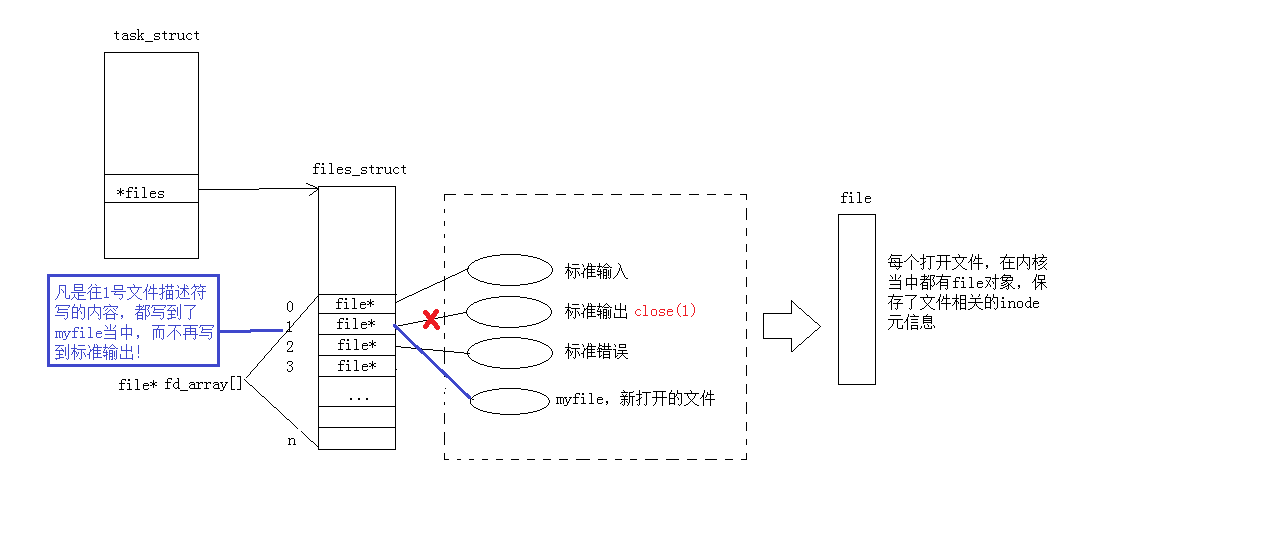
5.2dup函数
函数原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);
dup2 可以让 newfd 拷贝 oldfd,如果需要可以将 newfd 先关闭。
newfd 是 oldfd 的一份拷贝,将后者 (newfd) 的内容写入前者 (oldfd),最后只保留 oldfd。
至于参数的传递,比如我们要输出重定向 (stdout) 到文件中:
我们要重定向时,本质是将里面的内容做改变,所以是要把 fd 的内容拷贝到 1 中的:
oldfd:fd 《—newfd:1
当我们最后进行输出重定向的时候,所有的内容都和 fd 的内容是一样的了。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(void)
{
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
dup2(fd, 1); // fd ← 1
fprintf(stdout, "打开文件成功,fd: %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}

#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd = open("log.txt", O_CREAT | O_RDWR);
if (fd < 0) {
perror("open");
return 1;
}
close(1);
dup2(fd, 1);
for (;;) {
char buf[1024] = {0};
ssize_t read_size = read(0, buf, sizeof(buf) - 1);
if (read_size < 0) {
perror("read");
break;
}
printf("%s", buf);
fflush(stdout);
}
return 0;
}

6.缓冲区的理解
① 什么是缓冲区?缓冲区的本质就是一段内存。
②为什么要有缓冲区?为了 解放使用缓冲区的进程时间。
缓冲区的存在可以集中处理数据刷新,减少 IO 的次数,从而达到提高整机的效率的目的。
6.1语言级缓冲区:
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
// 给它们都带上 \n
printf("Hello printf\n"); // stdout -> 1
fprintf(stdout, "Hello fprintf!\n");
fputs("Hello fputs!\n", stdout);
const char* msg = "Hello write\n";
write(1, msg, strlen(msg));
sleep(5);
return 0;
}
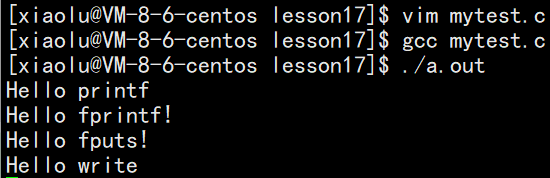
现在我们再把 \0 去掉:
int main(void)
{
printf("Hello printf"); // stdout -> 1
fprintf(stdout, "Hello fprintf!");
fputs("Hello fputs!", stdout);
const char* msg = "Hello write";
write(1, msg, strlen(msg));
sleep(5);
return 0;
}

write先打印出来,printf和fprintf fputs是五秒后打印出来的
然而 write 无论带不带 \n 都会立马刷新,也就是说,只要 printf, fprint, fputs 调了 write 数据就一定显示。
我们继续往下深挖,stdout 的返回值是 FILE,FILE 内部有 struct,封装很多的成员属性,其中就包括 fd,还有该 FILE 对应的语言级缓冲区。
C 库函数 printf, fwrite, fputs… 都会自带缓冲区,但是 write 系统调用没有带缓冲区。
我们现在提及的缓冲区都是用户级别的缓冲区,为提高性能,OS 会提供相关的 内核级缓冲区。
库函数在系统调用的上层,是对系统调用做的封装,但是 write 没有缓冲区,这说明了:
该缓冲区是二次加上的,由 C 语言标准库提供,我们来看下 FILE 结构体:
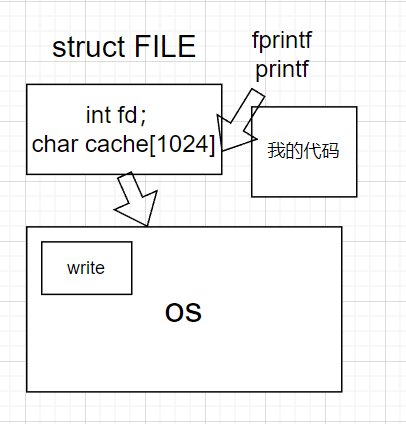
放到缓冲区,当数据积累到一定程度时再刷。
- 每一个文件都有一个 fd 和属于它自己的语言级别缓冲区。
6.2缓冲区的刷新策略
常规策略:
- 无缓冲 (立即刷新)
- 行缓冲 (逐行刷新)
- 全缓冲 (缓冲区打满,再刷新)
特殊情况:
- 进程退出
- 用户强制刷新(即调用 fflush)
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
const char* str1 = "hello printf\n";
const char* str2 = "hello fprintf\n";
const char* str3 = "hello fputs\n";
const char* str4 = "hello write\n";
// C 库函数
printf(str1);
fprintf(stdout, str2);
fputs(str3, stdout);
// 系统接口
write(1, str4, strlen(str4));
// 调用完了上面的代码,才执行的 fork
fork();
return 0;
}
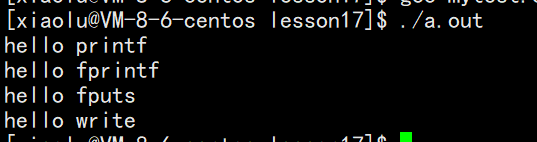
到此为止都很正常
但如果我们此时重定向,比如输入 ./a.out > log.txt,怪事就发生了!log.txt 中居然有 7 条消息:

当我们重定向后,本来要显示到显示器的内容经过重定向显示到了文件里,
如果对应的是显示器文件,刷新策略就是 行刷新
如果是磁盘文件,那就是 全刷新,即写满才刷新
- 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
- printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
- 而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
- 但是进程退出之后,会统一刷新,写入文件当中。
- 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
- write 没有变化,说明没有所谓的缓冲。
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
如果有兴趣,可以看看FILE结构体:
typedef struct _IO_FILE FILE; 在/usr/include/stdio.
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
nters correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */








![[ASP]青辰网络考试管理系统NES X3.5](https://img-blog.csdnimg.cn/96f81143a4454aea8a37adcedd40540a.png)