视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
打开百度翻译网址,我们输入需要翻译的英文,谷歌 F12 打开开发者工具,network可以看到网络请求,我们需要找到请求的API,我们可以选择 Fetch/XHR,来缩小寻找范围。
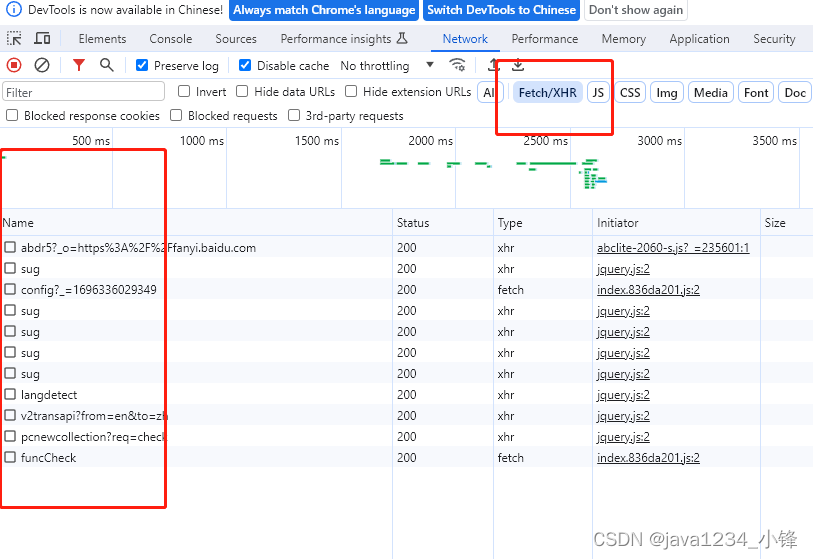
经过排查,有两个接口设计到翻译
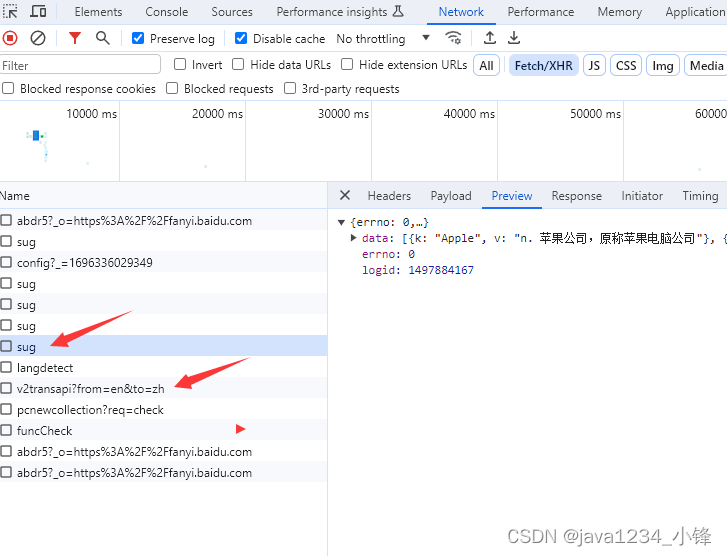
sug请求是用户界面的左侧的一些翻译结果,v2transapi是用户界面右侧的精准结果。
所以我们根据需求,都可以做。
我们就以左侧的用户界面sug接口为例,用requests的post方式模拟下。
https://fanyi.baidu.com/sug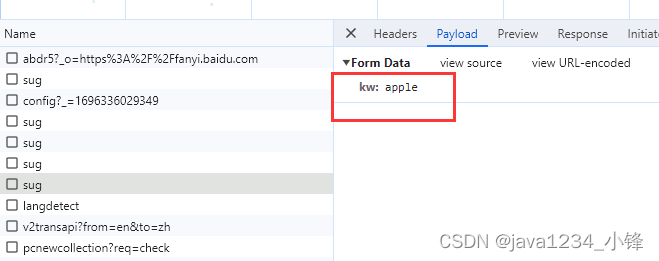
就一个参数
import requests
import json
url = "https://fanyi.baidu.com/sug"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
data = {
'kw': 'white'
}
r = requests.post(url=url, data=data, headers=headers)
print(r.text)
# json.loads方法自动把unicode编码转成中文
result = json.loads(r.text)
print(result)这里用post方法实现,返回结果是unicode编码,因为也是json格式,所以我们用json.loads方法,直接获取Json对象,以及实现unicode编码转成中文。