文章目录
- 数据查询
- 1. 单表查询
- 1. 简单查询
- 2. 条件查询
- 总结
- 举例
- 3. 函数查询
- 常用多行函数
- 常用单行函数
- 1. 字符函数
- 2. 数值函数
- 3. 日期时间函数
- 常用日期型函数
- 举例
- 4. 转换函数
- 4. 查询结果排序(order by)
- 参数说明:
- 注意事项:
- 2. 连接查询
- 1. 交叉连接(cross join)
- 2. 内连接(inner join...on)
- 3. 外连接(outer join...on)
- 3. 分组查询(group by、having、top)
- group by
- having
- top
- 4. 子查询
- 1. 标量子查询
- 2. 表子查询(in、and/some|any/all、exists)
- in
- and、some|any、all
- all
- some | any
- exists
- 3. 多列表子查询
- 4. 派生表子查询
- 5. 伪列使用
- 1. ROWNUM
- 2. ROWID
- 3. 其他
- 4. 查询结果的合并(union)
数据查询
1. 单表查询
仅从一个表/视图中检索数据
select <选择列表> from [<模式名>.]<基表名>|<视图名>[<相关名>]
[<where子句>]
[<connect by子句>]
[<group by子句>][<having子句>]
[order by子句];
1. 简单查询
在查询结果列中:
-
as:更改结果列名;
-
*:来表示数据表中的所有列;
-
distinct :去掉查询结果中的重复行。
举例:
查询employee表中job_id列的信息,结果列名为员工编号。
select distinct job_id as 工作编号 from dmhr.employee;
2. 条件查询
总结
在指定表中查询出满足条件的数据。
SELECT <选择列表> FROM [<模式名>.]<基表名>|<视图名> [<相关名>] [<where 查询条件>]
where子句中的常用的查询条件由谓词和逻辑运算符组成。
-
谓词:
-
比较谓词(=、>、<、>=、<=、<、>)
-
between
-
where <表达式1> [not]between <表达式2> and <表达式3>
-
-
in
-
where <表达式1> [not]in (<表达式2>,<表达式3>……)
-
-
like
-
where <列名> [not]like 匹配字符串 -
通配符:
%:任意长度(可以为零)字符串;_:表示任意一个字符。(例:a%b,a_b) -
注意:如果用户要查询的字符串本身就含有%或者是_,则需要用ESCAPE进行换码
-
<列名>[NOT]like 匹配字符串 ESCAPE 换码字符 如:where KCM LIKE 'DB\_%g_' ESCAPE '\' 表示KCM列中以DB开头且倒数第二个字符为g的信息满足条件。
-
-
NULL
-
where <列名> is[NOT] NULL // 注意:is不能用等号(=)代替
-
-
exists
-
-
逻辑运算符
-
and
-
or
-
not
-
举例
- and使用:查询工资高于20000元且雇佣日期晚于2008年1月1日的员工信息。
select employee_name, email, phone_num, hire_date, salary
from dmhr.employee
where salary > 20000 and hire_date > '2008-01-01';
- between使用:查询雇佣日期在2008年1月的员工信息。
select employee_name, email, phone_num, hire_date, salary
from dmhr.employee
where hire_date between ('2007-12-31') and ('2008-02-01')
- in使用:查询11和21部门员工的员工编号、姓名、工作部门编号。
select employee_id, employee_name, email, job_id
from dmhr.employee
where job_id in ('11', '21')
- like使用:查询姓刘的员工信息。
select employee_name, email, phone_num, hire_date, salary
from dmhr.employee
where employee_name like '刘%';
- null使用:查询电话号码为空的员工信息。
select employee_name, email, phone_num, hire_date, salary
from dmhr.employee
where phone_num is null;

3. 函数查询
函数查询是在select的查询过程中,使用函数检索列和条件中的数据集合.
达梦数据库的库函数可以划分为两大类:
-
多行函数:该函数输入多行,处理的对象多属于集合,故又称集合函数
-
单行函数:该函数输入一行,输出一行,通常分为5种类型(字符函数,数值函数,日期函数,转换函数和通用函数)。
常用多行函数
| 函数名 | 功能 |
|---|---|
| distinct 列名称 | 在指定的列上查询表中不同的值 |
| count(*) | 统计记录个数 |
| count(列名称) | 统计一列中值的个数 |
| sum(列名称) | 计算一列值的总和(此列必须是数值型) |
| avg(列名称) | 计算一列值的平均值(此列必须是数值型) |
| max(列名称) | 求一列值中的最大值 |
| min(列名称) | 求一列值中的最小值 |
注意:参数中可使用distinct过滤掉重复记录,默认或用ALL表示取全部记录。
举例:
-
查询employee表中的部门数信息。
select count(distinct job_id) as 部门数 from dmhr.employee; -
从 employee表中查询员工工资在3000 ~ 5000之间的最大值。
select area_max(salary,3000,5000) 最高工资 from dmhr.employee;
常用单行函数
单行函数通常分为五种类型:字符函数﹑数值函数﹑日期函数﹑转换函数和通用函数。
单行函数的主要特征有:
- 单行函数对单行操作;
- 每行返回一个结果;
- 有可能返回值与原参数数据类型不一致(转换函数);
- 单行函数可以写在SELECT、WHERE、ORDERBY子句中;
- 有些函数没有参数,有些函数包括一个或多个参数;
- 函数可以嵌套。
1. 字符函数
函数的参数为字符类型的列,并且返回字符或数字类型的值,主要是完成对字符串的查找、替换、定位、转换和处理等功能。

例1:查询员工信息,将姓名与电子邮箱合并为一列。
SELECT CONCAT (employee_name, email), phone_num, hire_date, salary
FROM employee;
// 等价于
SELECT employee_name||email, phone_num, hire_date, salary
FROM employee;
例2:查询员工信息,并显示每名员工电话号码的前三位。
SELECT employee_name, email , phone_num, hire_date, salary, SUBSTR(phone_num,1,3)
FROM employee;
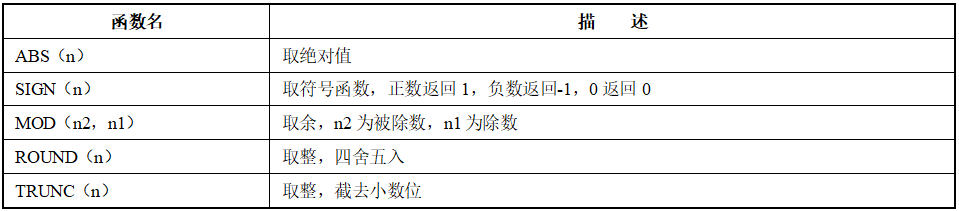
2. 数值函数
数值型函数可以输入数字(如果是字符串,DM自动转换为数字),返回一个数值。其精度由DM的数据类型决定。
3. 日期时间函数
日期类型的函数主要处理日期、时间类型的数据,返回日期或数字类型的数据。
日期运算比较特殊,这里先做个说明:
①在date和timestamp(会被转化为DATE类型值)类型上加、减number类型常量,该常量单位为天数;
②如果需要加减相应年、月、小时或分钟,可以使用n365、n30、n/24或n/1440来实现,利用这一特点,可以顺利实现对日期进行年、月、日、时、分、秒的加减;
③日期类型的列或表达式之间可以进行减操作,功能是计算两个日期之间间隔了多少天。
常用日期型函数


举例
-
查询员工入职日期的年、月、日信息
SELECT employee_name, EXTRACT(YEAR FROM hire_date), EXTRACT(MONTH FROM hire_date), EXTRACT(DAY FROM hire_date) FROM employee; -
获取服务器当前的时间
SELECT SYSDATE(); -
获取2020年2月份最后一天的日期
SELECT LAST_DAY('2020-02-01');
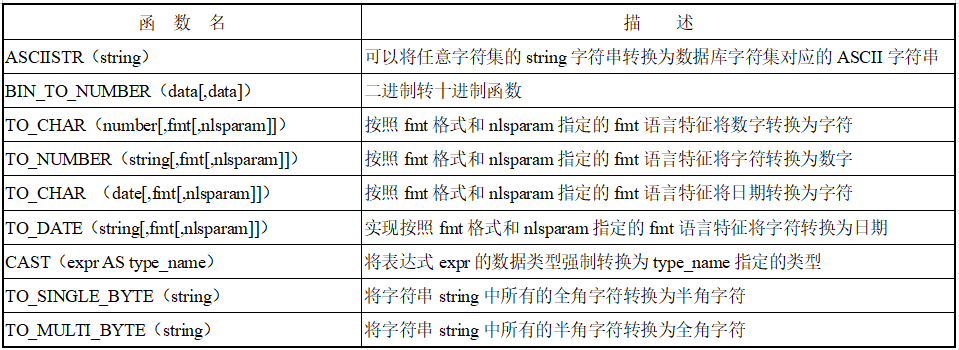
4. 转换函数
转换函数可以完成不同数据类型之间的转换功能.
举例:查询员工信息,使入职日期的显示格式为“yyyy.mm.dd”
SELECT employee_name, email , phone_num, TO_CHAR(hire_date,'yyyy.mm.dd'),salary
FROM employee;

4. 查询结果排序(order by)
select <选择列表>
from [<模式名>.]<基表名>|<视图名>[<相关名>]
[<where子句>]
[order by 列名称 [ASC|DESC][NULLFIRST|LAST],……];
参数说明:
-
[ASC|DESC]:ASC为升序(默认),DESC为降序;
-
[NULLFIRST|LAST]:为null的放在最前面(FIRST)或最后面(LAST,默认)。
注意事项:
-
order by子句为DBMS提供了要排序的项目清单和它们的排序顺序︰
递增顺序(ASC,默认)或是递减顺序(DESC)。它必须跟随<查询表达式>,因为它是在查询计算得出的最终结果上进行操作的。 -
排序键可以是任何在查询清单中的列的名称,或者是对最终结果表的列计算的表达式(即使这一列不在选择清单中),也可以是子查询。
- 对于
union查询语句,排序键必须在第一个查询子句中出现;对于group by分组的排序,排序键可以使用集函数,但group by分组中必须包含查询列中所有列。
- 对于
-
<无符号整数>对应select后结果列的序号。
-
当用<无符号整数>代替列名时,<无符号整数>不应大于select后结果列的个数。
-
若采用其他常量表达式(如-1,3×6)作为排序列,将不影响最终结果表的行输出顺序。
-
-
无论采用何种方式标识想要排序的结果列,它们都不应为多媒体数据类型。(如image、text、blob和clob)。
-
当排序列值包含NULL时,根据指定的“NULLS FIRST|LAST”决定包含空值的行是排在最前还是最后,默认为NULLS FIRST。
-
当排序列包含多个列名时,系统则按列名从左到右排列的顺序,先按左边列将查询结果排序,
当左边排序列值相等时,再按右边排序列排序…以此类推,逐个检查调整,最后得到排序结果。 -
由于order by只能在最终结果上操作,不能将其放在查询中。
-
如果order by后面使用集函数,则必须使用group by分组,且group by分组中必须包含查询列中所有列。
-
order by子句中最多可包含64个排序列。
举例:
将员工表中部门编号为1001的员工按聘用日期先后顺序排列。
select employee_name, hire_date
from dmhr.employee
where department_id='1001'
order by hire_date;

2. 连接查询
如果一个查询包含多个表( >=2 ),则称这种方式的查询为连接查询。
select <结果列表> <FROM子句> [<WHERE子句>][<CONNECTBY子句>]
[<GROUPBY子句>][<HAVING子句>][ORDERBY子句];
其中<FROM子句>::=FROM<表项>,具体如下:
-
<表项>::=<单表>|<连接表项>
-
<连接表项>::=<交叉连接>|<限定连接>|(<连接表>)
-
<交叉连接>::=<表引用>cross join<表引用>
-
<限定连接>::=<表引用>[natural][<连接类型>][<强制连接类型>][join]<表引用>[<连接条件>]
-
<连接类型>::=inner|<外连接类型>[outer]
-
<外连接类型>::=left|right|full
-
<强制连接类型>::=hash
-
<连接条件>::=on<搜索条件>|using(<连接列列名>[{<连接列列名>}])
1. 交叉连接(cross join)
结果集仅包含全部笛卡尔积记录。
例:部门表和职务表通过交叉连接查询部门名称和职务。
select department_name, job_title from dmhr.department
cross join dmhr.job;
等价于:
select department_name, job_title
from dmhr.department, dmhr.job;
2. 内连接(inner join…on)
根据连接条件,结果集仅包含满足连接条件的记录,把这样的连接称为内连接。
若有歧义性字段名应写明所在数据表。
例如:1. 查询员工的部门号、姓名、部门和工资。(两张表)
select employee.department_id as 部门号, employee_name as 姓名,
department_name as 部门, salary as 工资
from employee inner join department
on employee.department_id = department.department_id;
等价于:
select employee.department_id as 部门号, employee_name as 姓名,
department_name as 部门, salary as 工资
from employee, department
where employee.department_id=department.department_id;
-
查询’101’部门员工的姓名、部门和职务。
select employee.department_id as 部门号, employee_name as 姓名, department_name as 部门,job_title as 职务 from employee,department, job where employee.department_id=department.department_id, AND employee.job_id=job.job_id AND department.department_id='101';
3. 外连接(outer join…on)
外连接除了返回满足连接条件的数据以外,还返回左,右或两表中不满足条件的数据,又分为左连接,右连接和全连接三种。
select <结果列表> <from><表名>[left|right|full] outer join
<连接表名> on [连接条件]……
说明:**
-
left outer join:左外连接,除了返回符合条件的行,还要从左表里选出不匹配的行;
-
right outer join:右外连接,是除了返回符合条件的行,还要右表里选出不匹配的行;
-
full outer join:全外连接,是除了返回符合条件的行,还要从两表中选出不匹配的行;
-
outer可省略。
举例:
-
使用
左连接查询所有岗位的员工信息。select T2.job_id, T2.job_title, T1.employee_name, T1.email,T1.phone_num, T1.hire_date,T1.salary from job T2 left outer join employee T1 ON T1.job_id=T2.job_id; // 等价于: select T2.job_id, T2.job_title, T1.employee_name, T1.email, T1.phone_num, T1.hire_date, T1.salary from job T2, employee T1 where T2.job_id=T1.job_id(+); -
使用
右连接查询所有岗位的员工信息。(左表没有的用NULL表示)select T2.job_id, T2.job_title, T1.employee_name, T1.email,T1.phone_num, T1.hire_date,T1.salary from job T2 right outer join employee T1 ON T1.job_id=T2.job_id; -
使用
全连接查询所有岗位、所有员工的信息。select T2.job_id, T2.job_title, T1.employee_name, T1.email, T1.phone_num, T1.hire_date,T1.salary from job T2 full outer join employee T1 on T1.job_id=T2.job_id; // 此语句使用了全连接,既包含没有岗位的员工信息,又包含没有员工的岗位信息。

3. 分组查询(group by、having、top)
select <结果列表><FROM><表名>[GROUPBY子句]
group by
分组子句 GROUP BY 对查询进行分组。
说明:
<group by子句>::=group by<分组项>|<rollup项>|<cube项>|<grouping sets项>
<分组项>::=<列名>|<值表达式>{<列名>|<值表达式>}
<rollup项>::=rollup(<分组项>)
<cube项>::=cube(<分组项>)
<grouping sets项>::=grouping sets(<分组项>|(<分组项>){<分组项>|(<分组项>)})
group by定义了行组的分组集合:每一个组由其中所有分组列的值都相等的行构成。
注意:
-
在group by子句中的每一列必须明确地命名属于在from子句中命名的表的一列。
-
分组列不能为集函数表达式或在select子句中定义的别名。
-
当分组列值包含空值时,则空值作为一个独立组。
-
当分组列包含多个列名时,则按照group by子句中列出现的顺序进行分组。
-
分组列的数据类型不能是多媒体数据类型。
-
group by子句中最多可包含128个分组列。
例1:统计每个部门的员工数。
select department_id 部门,count(*) 员工数
from employee group by department_id;
例2:求1001号部门中各职务员工的数量,并按数量多少升序排列。
select job_id 职务编号, count(*) 数量
from employee
where department_id='1001'
group by job_id
order by 数量;
having
使用 having 子句对group by分组进行筛选。
例:从员工表中,查询员工数量小于100 的部门。
select b.department_name as 部门, count(a.employee_name) as 人数
from employee a, department b
where a.department_id=b.department_id
group by department_name
having count(a.employee_name)<100;
top
规定要返回的结果记录的数目。
例1:查询员工表中前 10条记录。
select top 10 * from employee;
例2:查询员 工表中前1%条记录。
select top 1 percent * from employee;

4. 子查询
当一个查询的结果是另一个查询的条件时,该查询称为子查询,又称嵌套查询。
子查询常出现在:
- from中:
select 结果列表 from (select语句)
- where、having中:
select 结果列表 from 表名称
where [having] <列名称> <运算符> (select语句)
说明:
-
执行时先执行内层的子查询,再执行外层查询;
-
使用子查询需要圆括号()括起来;
-
子查询可以嵌套,但内部子查询不能使用order by子句;
-
子查询参与条件比较运算时,只能放在比较条件的右侧;
-
根据返回结果的行数又可分为单行(标量)子查询与多行(表)子查询。
1. 标量子查询
子查询结果只返回一行一列。
例:查询比2001号员工工资高的员工信息。
select * from dmhr.employee
where salary > (select salary from dmhr.employee where employee_id='2001');
// 等价于
select * from dmhr.employee where salary>10000;
2. 表子查询(in、and/some|any/all、exists)
表子查询结果可以返回多行多列。
in
in运算符可以测试表达式的值是否与子查询返回的某一个值相等。
例:查询有员工工资超过20000元的部门。
select * from dmhr.department
where department_id in (select department_id from dmhr.employee where salary>20000);
// 等价于
select * from dmhr.department
where department_id in ('101', '301', '701')
and、some|any、all
量化符ALL、SOME、ANY可以用于将一个<数据类型>的值和一个由表子查询返回的值的集合进行比较。
all
<标量表达式> <比较算符> all <表子查询>
说明:
<标量表达式>可以是对任意单值计算的表达式。
<比较算符>包括=、>、<、>=、<=或<>。
若表子查询返回0行或比较算符对表子查询返回的每一行都为TRUE,则返回TRUE。
若比较算符对于表子查询返回的至少一行是FALSE,则ALL返回FALSE。
例1:查询工作经历表中没有数据的员工的编号、姓名和电话号码。
select employee_id,employee_name,phone_num
from dmhr.employee
where employee_id <> all (select employee_id from dmhr.job_history);
例2:查询总经理岗位(岗位ID为“11”)中工资比项目经理岗位(岗位ID为“32")工资都要高的员工信息。
select * from dmhr.employee
where job_id='11' and salary > all (select salary from dmhr.employee where job_id='32');
some | any
SOME、ANY定量比较语法如下︰
<标量表达式> <比较算符> any | some <表子查询>
SOME和ANY是同义词,如果它们对于表子查询返回的至少一行为TRUE,则返回为TRUE。
若表子查询返回0行或比较算符对表子查询返回的每一行都为FALSE,则返回FALSE。
例:查询总经理岗位(岗位ID为“11”)中任意一个人的工资都比项目经理岗位(岗位ID为“32")工资要高的员工信息。
select * from dmhr.employee
where job_id='11' and salary > (select salary from dmhr.employee where job_id='32');
exists
exists判断是对非空集合的测试并返回TRUE或FALSE。
[not]exists<表子查询>
功能︰若表子查询返回至少一行,则exists返回true,否则返回false。
exists关键字比in关键字的运算效率高,所以,在实际开发中,特别是数据量大时,推荐使用exists关键字。
对于由exists引起的子查询,其目标列表达式通常都用*,因为带exists的子查询只返回真值或假值,给出列名无实际意义。
例1:查询职务为总经理的员工的姓名和入职时间。
select t1.employee_name, t1.hire_date
from employee t1
where exists (select * from job t2 where t2.job_id=t1.job_id and t2.job_title='总经理');
例2:查询有员工工资超过20000元的部门。
select * from department t1
where exists (select * from employee t2 where t2.salary > 20000 and t1.department_id=t2.department_id);

3. 多列表子查询
为了满足应用需求,DM数据库扩展了子查询功能,目前支持多列in / not in查询。子查询可以是值列表或查询块。
例:查询部门号为1001且职务号为11的员工姓名及聘用日期。
select employee_name, hire_date
from employee
where (job_id,department_id) in (('11','1001'));
// 等价于
select employee_name, hire_date
from employee where job_id='11' and department_id='1001';
4. 派生表子查询
派生表子查询是一种特殊的表子查询。
派生表是指from子句中的select语句,并以别名引用这些派生表。在select语句的from子句中可以包含一个或多个派生表。
例:查询职务包含工程师的部门编号、部门名称、工程师数量,并按数量递减排列。
select t1.department_id, t1.department_name,t2.num
from department t1,
(
select department_id, count(*) from employee
where job_id in
(select job_id from job where job_title like '%工程师%')
group by department_id
) as t2(department_id,num)
where t1.department_id=t2.department_id
order by t2.num desc;
5. 伪列使用
伪列即物理上不存在的列,可以进行查询,但不能插入、更新和删除它们的值。
在达梦中主要的伪列有:ROWID,USER,UID,TRXID、ROWNUM等。
1. ROWNUM
rownum是一个虚假的列,表示从表中查询的行号,或者连接查询的结果集行数。它将被分配为1,2,3,4,…N,N是行的数量。
通过使用rownum可以限制查询返回的行数。
注意:
-
一个rownum值不是被永久地分配给一行。表中的某一行并没有标号,不可以查询rownum值为5的行。
rownum值只有当被分配之后才会增长,并且初始值为1,即只有满足一行后,rownum值才会加1,否则只会维持原值不变。 -
在查询中,ROWNUM可与任何数字类型表达式进行比较及运算,但不能出现在含OR的布尔表
达式中,否则报错处理。 -
ROWNUM只能在非相关子查询中出现,不能在相关子查询中使用,否则报错处理。
-
在非相关子查询中,ROWNUM只能实现与TOP相同的功能,因此子查询不能含ORDERBY和GROUPBY。
-
ROWNUM所处的子谓词只能为如下形式:rownum op exp
-
exp的类型只能是立即数、参数和变量值,op∈{<,<=,>,>=,=,<>}。
例:对employee表所有数据按salary升序排序后输出前5行。
select * from (select * from employee order by salary) where rownum < 6;
// 等价于
select top 5 * from employee order by salary;
2. ROWID
-
ROWID用来标识数据库基表中每一条记录的唯一键值,标识了数据记录的确切的存储位置。
-
如果用户在选择数据的同时从基表中选取ROWID,在后续的更新语句中,就可以使用ROWID来提高性能。
-
如果在查询时加上for update语句,该数据行就会被锁住,以防其他用户修改数据,保证查询和更新之间的一致性。
例:查看EMPLOYEE表所有员工的ROWID值。
select rowid, * from employee;
3. 其他
| 伪列 | 含义 |
|---|---|
| UID | 当前用户的用户标识 |
| USER | 当前用户的用户名 |
| TRXID | 当前事务的事务标识 |
| SESSID | 当前会话的ID标识 |
| LEVEL | 层次查询中,当前元组在层次数据形成的树结构中的层数。LEVEL的初始值为1,即层次数据的根节点数据的LEVEL值为1,之后其子孙节点的LEVEL依次递增。 |
| CONNECT_BY_ISLEAF | 层次查询中,当前元组在层次数据形成的树结构中是否是叶节点 (即该元组根据连接条件不存在子结点)。是叶节点时为1,否则为0。) |
| CONNECT_BY_ISCYCLE | 层次查询中,当前元组是否会将层次数据形成环,该伪列只有在层次查询子句中表明NOCYCLE关键字时才有意义。 如果元组的存在会导致层次数据形成环,该伪列值为1,否则为0。 |
4. 查询结果的合并(union)
DM提供了一种集合运算符UNION。这种运算符将两个或多个查询块的结果集合并为一个结果集输出。
<查询表达式> union [all][distinct][(]<查询表达式>[)];
使用说明︰
-
每个查询块的查询结果列数目必须相同。
-
每个查询块对应的查询结果列的数据类型必须兼容。
-
不允许查询列含有BLOB、CLOB或IMAGE、TEXT等大字段类型。
-
关键字ALL的意思是保持所有重复,而没有ALL的情况下表示删除所有重复。
-
关键字DISTINCT的意思是删除所有重复。
例1:查询部门101和102的员工姓名,将两者连接,并去掉重复行。
SELECT employee_name FROM employee WHERE department_id IN ('101')
UNION
SELECT employee_name FROM employee WHERE department_id IN ('101','102')
ORDER BY 1;
例2:查询部门101和102的员工姓名,将两者连接。
SELECT employee_name FROM employee WHERE department_id IN ('101')
UNION ALL
SELECT employee_name FROM employee WHERE department_id IN ('101','102')
ORDER BY 1;

![web:[网鼎杯 2020 青龙组]AreUSerialz](https://img-blog.csdnimg.cn/5e1b479f769d41539688f58397020d41.png)







![[云原生1.] Docker镜像的创建](https://img-blog.csdnimg.cn/989921fefb6a4db7a2519f83adc1bd0f.png)