背景
对于C程序员,尤其是嵌入式C程序员,hashmap使用的相对较少,所以会略显陌生,hashmap其实涉及到2个概念,分别是哈希(hash)、map。
哈希hash:是把任意长度输入通过蓝列算法变换成固定长度的输出,这种转换是一种压缩映射,一般不可逆。这是专业的解释,我们常说的crc16、crc32、lrc、md5、sha256等,本质上都是哈希hash,只不过散列算法不同而已。
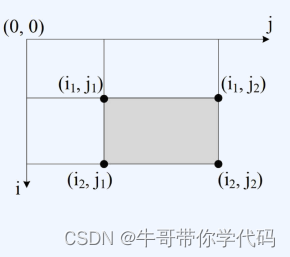
map: 是高级语言(比如java)中的一种数据结构,对于C语言,我们常用的就是数组,而map则是比数组更加高级的数据结构,其内部一般是数组+链表+红黑树的数据结构。如下图所示:

什么时候需要使用hashmap
既然hashmap是一种数据结构,我们不妨从常用的数据结构对比分析:
| 数据结构类型 | 存储形式 | 检索方式 |
|---|---|---|
| 数组 | 空间大小固定,要存的数据有唯一的、递增/连续的索引值 | 通过数组索引值检索 |
| 链表 | 空间动态扩展,要存储的数据有唯一的、不需要联系的索引或key值 | 遍历链表 |
| 数据库 | 空间动态扩展,要存储的数据有唯一的key值 | 通过SQL语句 or key值检索 |
上面的数据结构是我们最常用的集中数据格式,对于C程序员,常用的是数组和链表,而数据库由于相对较重,用的并不会太多。那么数组和链表的特点是什么呢?
- 数组的大小不能够动态扩展, 需要唯一的索引值,而且索引值最好是递增连续,但是数组的查找效率是最高的。
- 链表的大小可以动态扩展,也需要一个唯一的key值,不需要key是连续或递增,但是查找的效率是最低的,因为每次都是需要遍历查找。
那有没有一种数据结构,能够兼顾查找效率和动态扩展呢?答案是有,hashmap就是。hashmap可以存放无序的数据,查找的效率相比链表提升非常多。我们可以简单的认为hashmap是一种轻量级、极其简单的内存数据库(类似redis的实现原理也涉及hashmap),当我们的代码中需要存储大量的动态扩展的数据节点时,并且会频繁查询时,在不引入数据库的前提下,hashmap相比链表是更合适的一种数据结构。
hashmap 和 链表 遍历查询效率比较
完整的测试代码已经上传到gitee,地址如下:
C语言实现hashmap
测试代码 hash_list_cmp_test.c
/*
* A unit test and example of how to use the simple C hashmap
*/
#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
#include <sys/time.h>
#include <stdint.h>
#include <string.h>
#include "hashmap.h"
#include "list.h"
#define KEY_MAX_LENGTH (256)
#define KEY_PREFIX ("somekey")
#define KEY_COUNT (300)
typedef struct data_struct_s
{
char key_string[KEY_MAX_LENGTH];
int number;
} data_struct_t;
typedef struct{
char key_buf[KEY_MAX_LENGTH];
int value;
struct slist_s list;
} data_list_node_t;
struct slist_s g_data_list_head;
int main(char* argv, int argc)
{
int index, i;
int error;
map_t mymap;
char key_string[KEY_MAX_LENGTH];
data_struct_t* value;
data_list_node_t *node = NULL;
struct timeval tv1, tv2;
uint64_t t1, t2;
mymap = hashmap_new();
slist_init(&g_data_list_head);
/* First, populate the hash map with ascending values */
for (index=0; index<KEY_COUNT; index+=1){
/* Store the key string along side the numerical value so we can free it later */
value = malloc(sizeof(data_struct_t));
snprintf(value->key_string, KEY_MAX_LENGTH, "%s%d", KEY_PREFIX, index);
value->number = index;
error = hashmap_put(mymap, value->key_string, value);
assert(error==MAP_OK);
// list node add
node = (data_list_node_t *)malloc(sizeof(data_list_node_t));
memset(node, 0, sizeof(data_list_node_t));
slist_init(&node->list);
snprintf(node->key_buf, KEY_MAX_LENGTH, "%s%d", KEY_PREFIX, index);
node->value = index;
slist_add_tail(&node->list, &g_data_list_head);
}
/* Now, check all of the expected values are there */
gettimeofday(&tv1, NULL);
for (index=0; index<KEY_COUNT; index+=1){
snprintf(key_string, KEY_MAX_LENGTH, "%s%d", KEY_PREFIX, index);
error = hashmap_get(mymap, key_string, (void**)(&value));
/* Make sure the value was both found and the correct number */
assert(error==MAP_OK);
assert(value->number==index);
//printf("get key:%s, value:%d\n", value->key_string, value->number);
}
gettimeofday(&tv2, NULL);
t1 = (uint64_t)tv1.tv_sec * 1000000 + tv1.tv_usec;
t2 = (uint64_t)tv2.tv_sec * 1000000 + tv2.tv_usec;
printf("hash map iterate cost time %ld us\n", t2 - t1);
gettimeofday(&tv1, NULL);
for(i = 0; i < KEY_COUNT; i++){
snprintf(key_string, KEY_MAX_LENGTH, "%s%d", KEY_PREFIX, i);
slist_for_each_entry(&g_data_list_head, node, data_list_node_t, list){
if(0 == strcmp(node->key_buf, key_string)){
// printf("find %s ok, value=%d\n", node->key_buf, node->value);
break;
}
}
}
gettimeofday(&tv2, NULL);
t1 = (uint64_t)tv1.tv_sec * 1000000 + tv1.tv_usec;
t2 = (uint64_t)tv2.tv_sec * 1000000 + tv2.tv_usec;
printf("list iterate cost time %ld us\n", t2 - t1);
/* Now, destroy the map */
hashmap_free(mymap);
return 1;
}
运行结果:
hash map iterate cost time 60 us
list iterate cost time 435 us
从上述结果可知,hashmap的查找效率要比链表的查找效率高7倍以上。
小结
- hashmap是一种数据结构,跟数组、链表同级别的数据结构。
- hashmap有数组和链表的优点,查找效率比链表高,动态可扩展性比数组好。
- hashmap是用空间、算法来实现的一种内部轻量级数据结构,我们在开发程序时,如果涉及频繁查找,可以使用hashmap替换链表。