Attention 机制
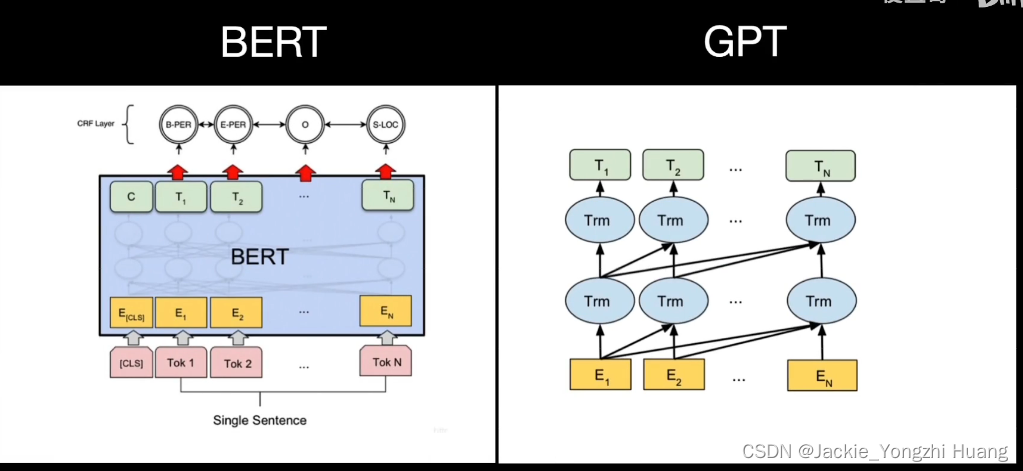
Attention应用在了很多最流行的模型中,Transformer、BERT、GPT等等。
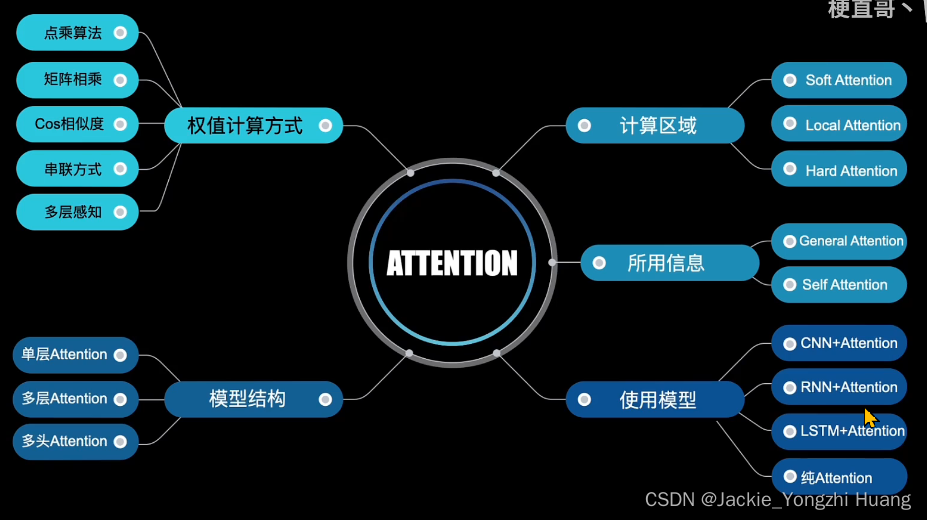
Attention就是计算一个加权平均;通过加权平均的权值来自计算每个隐藏层之间的相关度;
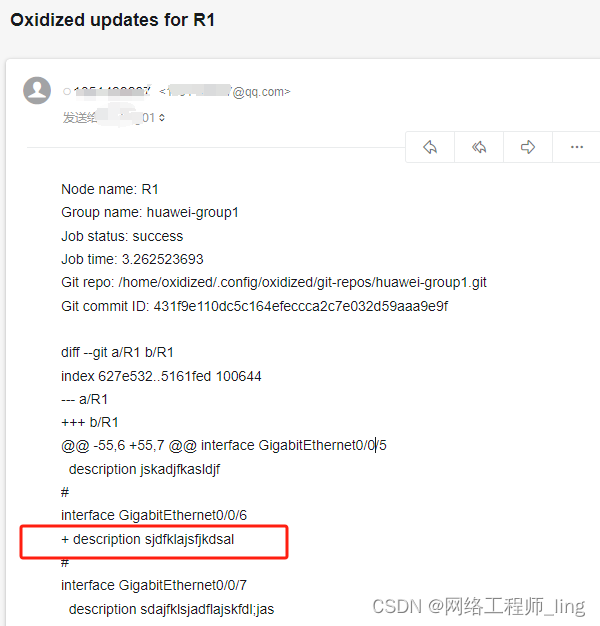
示例
Attention 机制
Attention应用在了很多最流行的模型中,Transformer、BERT、GPT等等。
Attention就是计算一个加权平均;通过加权平均的权值来自计算每个隐藏层之间的相关度;
示例
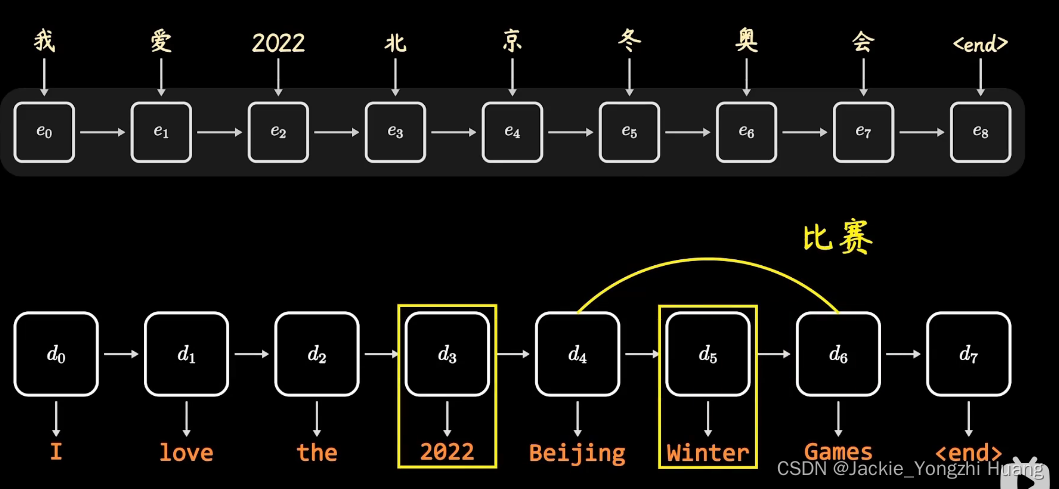
比如翻译:
我爱2022 北京 冬奥会。
I love the 2022 Beijing Winter Games.
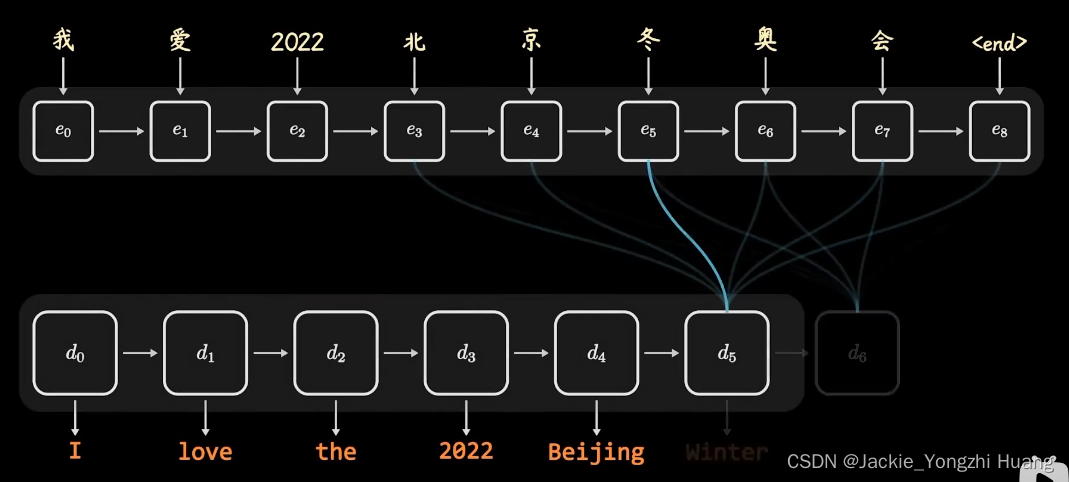
此时,如果我们看到Games这个单词,本意是游戏,
但是,考虑到了北京的权重,那么它的翻译成 比赛;
如果再考虑 2022 和 Winter的权重时候,它就翻译成了 冬奥会。
传统方法的问题
RNN
比如RNN,虽然建立了隐藏层来表示时序的关联,但是,会受到短时节点(前一个节点)的影响,而且不能够关联距离很长距离的内容。

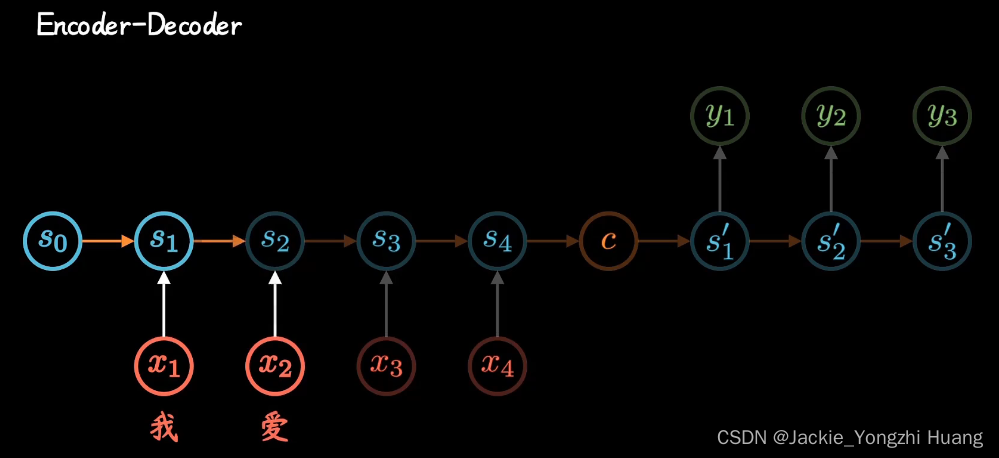
Encoder-Decoder
Encoder-Decoder模型可以看出两个RNN的组合。先编码,通过C把编码传过去,再解码。但是因为不管多长都是由一个C 来表示编码,就导致精度下降。
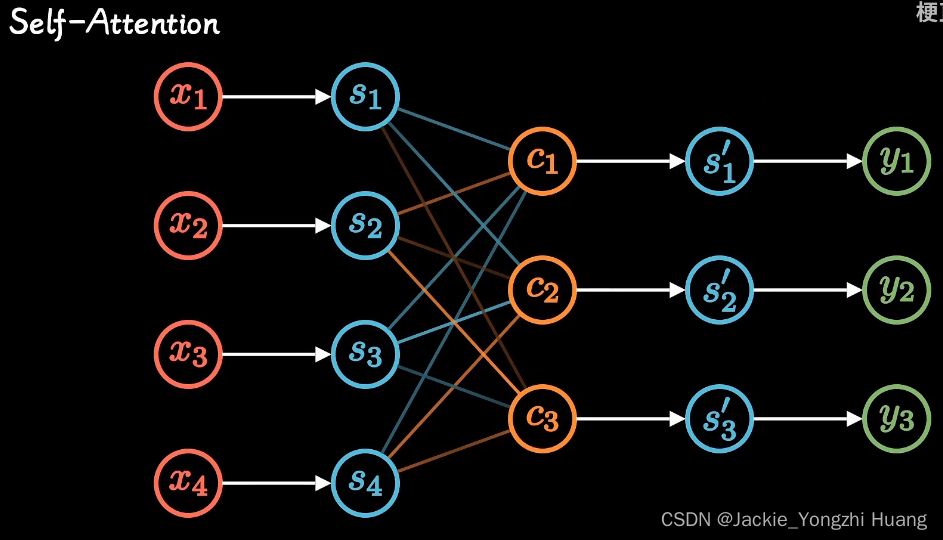
Attention的改进
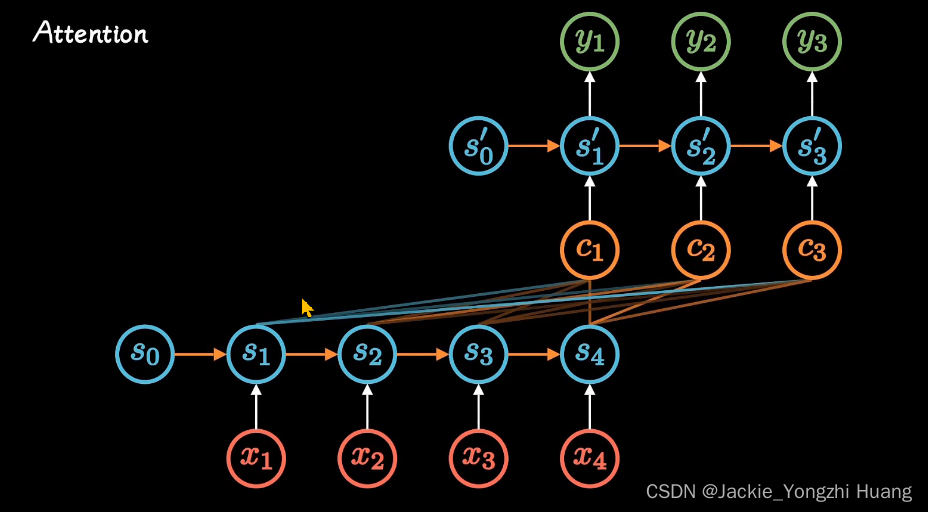
通过不同时刻,建立了不同的C,来表示。所以,每个C就是不同时刻的注意力。
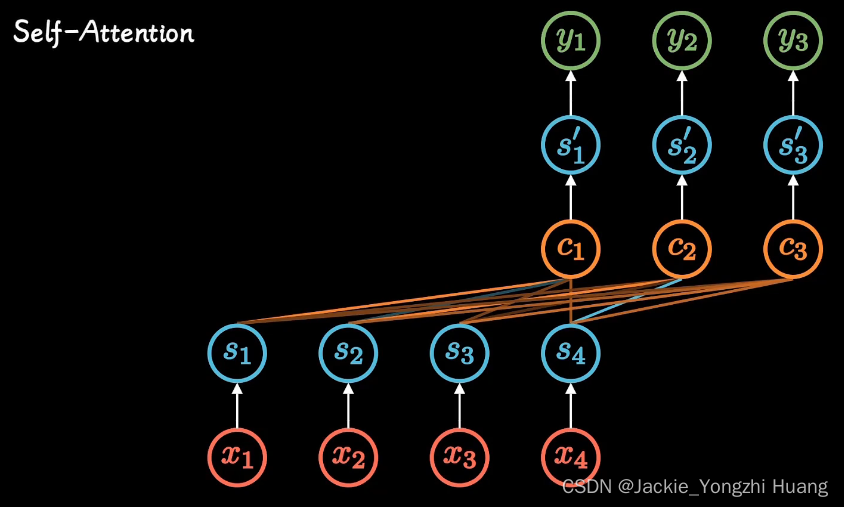
但是,这种方式不方便并行计算。所以,就去掉了顺序结构,变成了 Self-attention。

参考资料:
【【Attention 注意力机制】激情告白transformer、Bert、GNN的精髓】
https://www.bilibili.com/video/BV1xS4y1k7tn/?share_source=copy_web&vd_source=91d02e058149c97e25d239fb93ebef76







![关键路径及关键路径算法[C/C++]](https://img-blog.csdnimg.cn/ccc0ab435e5c449593be9e907ca96d90.png)