文章目录
- 0. 前言
- 1. 数据处理架构的演进
- 2. 传统数据处理架构
- 3. 事务型处理
- 4. 分析型处理
- 用于数据分析的传统数据仓架构
- 状态化流处理
- 5. 事件驱动型应用
- 什么是事件驱动型应用?
- 6. 数据管道
- 什么是数据管道?
- Flink 如何支持数据管道应用?
- 典型的数据管道应用实例
- 7. 流式分析
- 示例
- 参考文档
0. 前言
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
接下来我们将介绍 Flink 常见的几类应用并给出相关实例链接。
事件驱动型应用
数据分析应用
数据管道应用
1. 数据处理架构的演进
数据处理架构已经经历了数十年的演进,在此过程中与硬件的进步、网络的发展、和算法的改进等都有着密切的联系。我们整理了主要的阶段和特点:
-
传统的主机架构:在1980年代之前,大多数据处理都在主机上进行,数据存储在大型磁带或磁盘阵列中。这些系统通常有一个中心化的计算策略,并且是批量处理为主。
-
客户机/服务器架构:在1980s和1990s,随着个人电脑(PC)的普及和网络技术的进步,我们开始从主机迁移到更加去中心化的客户机-服务器架构。在这里,服务器存储数据,而许多客户机可以执行更复杂的数据处理和应用程序任务。
-
三层架构和Web架构:随着互联网的兴起,跨网络的数据处理成为标准。在这类网络架构中,通常有一个数据库服务器层,一个应用服务器层,和一个用户接口层。每一层有其特殊的任务,它们共同处理和服务用户请求。
-
大数据和分布式架构:在21世纪初,随着数据量的爆炸性增长,传统的数据处理架构已不能满足需求。此时出现了Hadoop、Spark等分布式计算框架,来允许在许多机器上并行处理大量的数据。此外,NoSQL数据库也应运而生,以应对非结构化和半结构化数据的增长。
-
云架构:近年来,随着云计算的进步,许多数据处理和存储的任务被迁移到云中。云服务如AWS、Google Cloud和Azure提供了弹性的计算和存储能力,可以根据需求进行扩展,无需用户维护硬件设施。
-
实时/流处理架构:数据的实时处理和分析越来越受到重视,Apache Kafka、Storm、Flink等流处理框架开始流行。
-
AI 和机器学习:近几年,AI和机器学习在数据处理和分析中的作用越来越大。这需要大量的数据,并需要新的计算和存储策略。此外,GPU和TPU等硬件设施的发展也对这个领域产生了重大影响。
上述架构的转变不是独立的阶段,而是逐渐交叠,逐渐取代。比如,虽然有了云架构和分布式处理,但在某些场景下,传统的数据库和客户机/服务器架构仍然具有价值。新的架构并不排斥旧的设计,而是能够满足特定工作负载和业务需求的最佳解决方案。
2. 传统数据处理架构
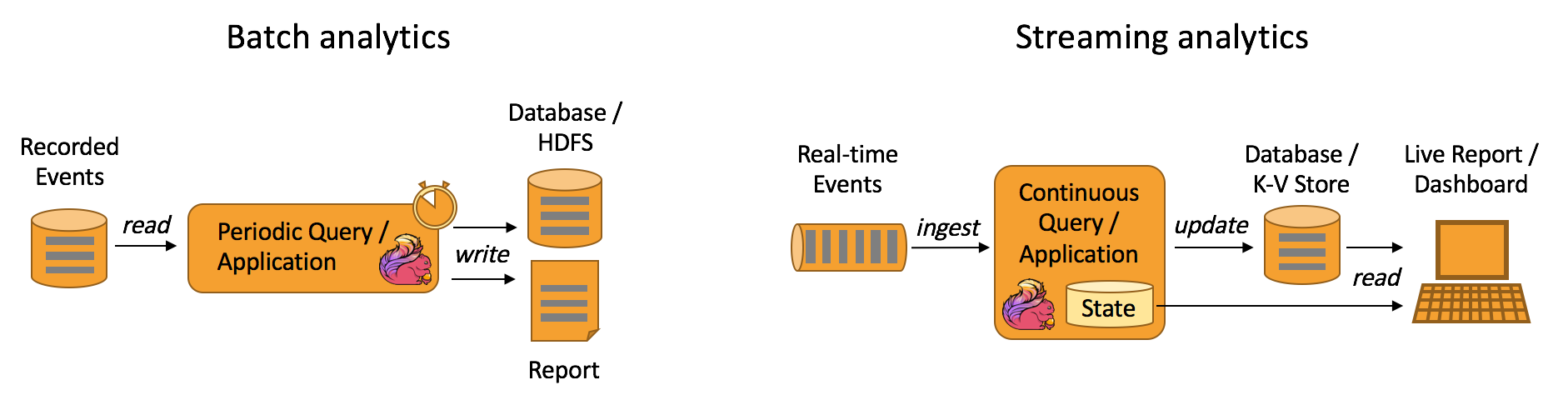
在传统的数据处理架构中,工作流通常分为批处理和流处理两种模式。
-
批处理:批处理是大数据处理的经典模式,它依赖于存储系统(例如HDFS)来存储大量数据,然后通过MapReduce等计算模型对数据进行批量处理。批处理通常在非实时需求的情况下使用,其优点是能够处理大量历史数据,适用于离线分析,但是其延迟较高,不适合实时数据处理场景。
-
流处理:与批处理不同,流处理是基于事件驱动的处理方式,能够实时处理数据。它不需要等待所有数据都被存储再进行处理,而是持续接收和处理数据。流处理的优点是具有低延迟,适用于实时数据处理和快速响应需求。但是,由于其连续处理数据,对窗口操作和时间管理提出了较高要求。
然而,这种工作流的架构带来了开发和管理上的挑战,因为必须将批处理和流处理统一到一个处理流程中。Apache Flink作为一个流处理和批处理一体化的框架,能够解决这类问题,将批处理视作流处理的一种特殊情况,使得开发和管理过程大为简化。
3. 事务型处理
在电子银行系统、在线购物商城、航空订票系统等场景中,这种事务型处理是非常常见的。例如在一个购物车结账操作中,可能包含减少商品的库存数量、将商品添加到购买历史记录、更新客户支付信息等步骤,这些步骤需要构成一个完整的事务,以保证数据的完整性和一致性。
事务型处理(Transaction Processing)是特定于应用和特定于业务的一种任务执行和数据管理方式,通常在数据库管理系统(DBMS)中进行。这种处理类型侧重于完成一系列操作,以产生一组一致、原子性、隔离性和持久性(ACID)的结果。
4. 分析型处理
分析型处理(Analytical Processing)是用于分析和管理业务数据的技术。它发生在数据库中,并侧重于制定业务策略和决策的数据驱动分析。这通常包括收集和检查历史数据以发现趋势、行为模式和洞见,帮助组织利用这些信息改善其业务流程。
分析型处理通常与在线分析处理(OLAP)和数据仓库(Data Warehousing)相关。OLAP 是一种多维的分析方法,它允许用户从不同的视角和维度(如时间、地点、产品类型等)进行数据分析。
以下是几种常见的分析处理:
-
描述性分析(Descriptive Analysis):对历史数据进行分析,以了解过去发生了什么。例如,过去一年中的销售数据分析。
-
预测性分析(Predictive Analysis):通过使用数据挖掘、机器学习和预测模型来预测未来可能发生的情况。
-
诊断性分析(Diagnostic Analysis):对数据进行深入研究,以了解特定结果发生的原因。
-
预防性分析(Prescriptive Analysis):利用优化和模拟算法,根据预测然后决定应采取什么行动。
在许多行业,如零售、金融、医疗、市场研究等,分析型处理往往扮演着关键角色,它帮助决策者理解业务现状,预测未来趋势,从而做出更明智的决策。
-
零售:零售商可能利用描述性分析来确定特定时间段内的最佳销售产品,或在地理位置上的销售差异。预测性分析可能用于预测下一个季度或者节日购物季的销售趋势。预防性分析则可以辅助决策,例如基于预期的销售对库存进行调整。
-
金融:在金融行业中,描述性分析可用于分析过去的股票市场趋势或客户的往来交易行为。预测性分析可以用于预测未来的股市趋势,或评估借款人违约的可能性。此外,预防性分析常用于根据预测结果优化投资组合。
-
医疗:在医疗领域,描述性分析可能被用来研究特定疾病在某地区的发病率。预测性分析可能用于预测未来在特定情况下(例如大型活动或旅游旺季)的疾病爆发风险。而预防性分析则可用于制定有效的公共健康政策和疾病预防计划。
-
市场研究:市场研究人员可能会利用描述性分析来理解消费者的购买行为和态度。预测性分析可以帮助他们预测未来的市场趋势或消费者行为。预防性分析可以帮助他们在研究的基础上制定市场营销策略。
分析型处理的基本流程是一种处理海量数据、并从中获取有用信息以进行决策和策略制定的方法。以下是一个常见的分析处理流程:
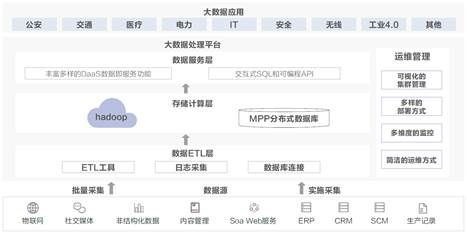
-
数据收集: 这一步需要确定需要收集的数据类型和来源。例如,您可能需要收集客户交易数据、公司内部数据、公开可用的数据,等等。为了提高效率,数据收集应当尽可能自动化。
-
数据清洗: 数据清洗是一个重要步骤,用于移除无关数据、修正数据错误或完善缺失数据。这一步保证了后续分析的准确性。
-
数据整理: 在此步骤中,原始数据被转换为可以用于分析的格式。可能需要进行的任务包括分类、排序、合并和划分数据。
-
数据分析: 数据分析师会运用一系列统计和机器学习技术来挖掘数据中的信息。分析的目标可能包括找出数据趋势、建立预测模型、检查变量之间的关系等。
-
数据呈现: 分析结果常被整理为报告或数据可视化形式,这样决策者可以很容易地理解和利用分析结果。
-
决策和行动: 最后,基于分析结果,决策者会制定和执行相应的策略或行动计划。
用于数据分析的传统数据仓架构
在处理数据分析任务时,通常会应用到的一种方法是使用传统的数据仓库架构。这一架构通常包括以下几个关键组成部分:
-
源系统:这是数据仓库获取数据的原始位置。这些系统可以是各种类型的应用程序数据,如企业资源规划(ERP)系统,客户关系管理(CRM)系统,金融系统,日志文件等。
-
ETL过程:即提取,转换,加载(Extract, Transform, Load)。数据从源系统提取出来,然后转换以满足数据仓库的规定格式和质量,最后加载到数据仓库中。
-
数据仓库:这是针对分析和报告的整合数据的中央存储库。它通常以一种可以提供优化查询性能和数据分类的模式(比如星型模式或雪花模式)来组织数据。
-
数据集市:这是针对特定业务部门或报表需求的数据仓库分区。数据集市存储的信息比数据仓库中的信息更加精细和细致,直接面向具体的业务用户。
-
报表和分析工具:这是在数据仓库中执行查询以查看和理解数据的工具。它们可以是商业智能(BI)工具,数据可视化工具,或者更高级的数据科学和机器学习工具。
这种架构对于大量历史数据的存储和分析是非常有用的,并且它提供了一种方式来实现跨多个源系统的数据一致性和整合。然而,它通常不适合处理实时或近实时的数据分析需求,或者处理非结构化的大数据。对于这些需求,你可能需要查看更现代和灵活的数据架构方法,如数据湖、流处理等。
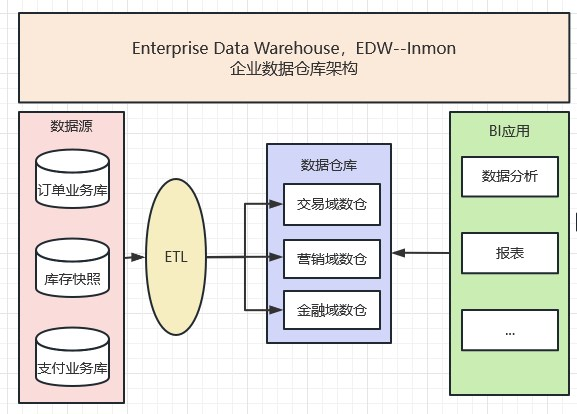
状态化流处理
5. 事件驱动型应用
什么是事件驱动型应用?
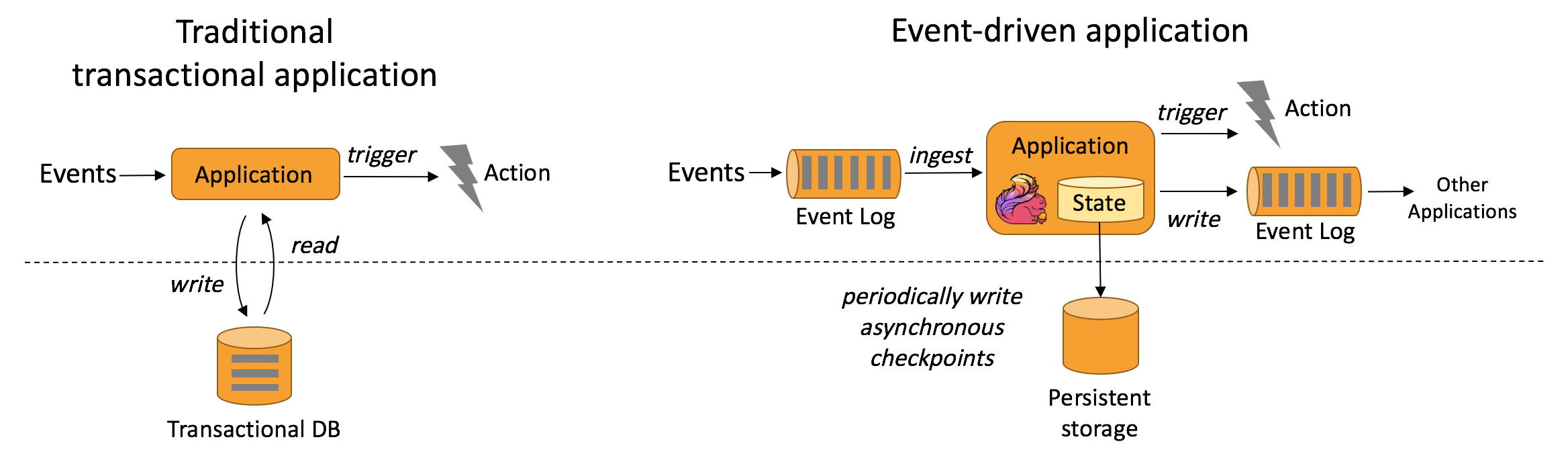
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
- 实时推荐 例如在客户浏览商家页面的同时进行产品推荐
- 模式识别或复杂事件处理 例如根据信用卡交易记录进行欺诈识别
- 异常检测 例如计算机网络入侵检测
事件驱动型应用架构
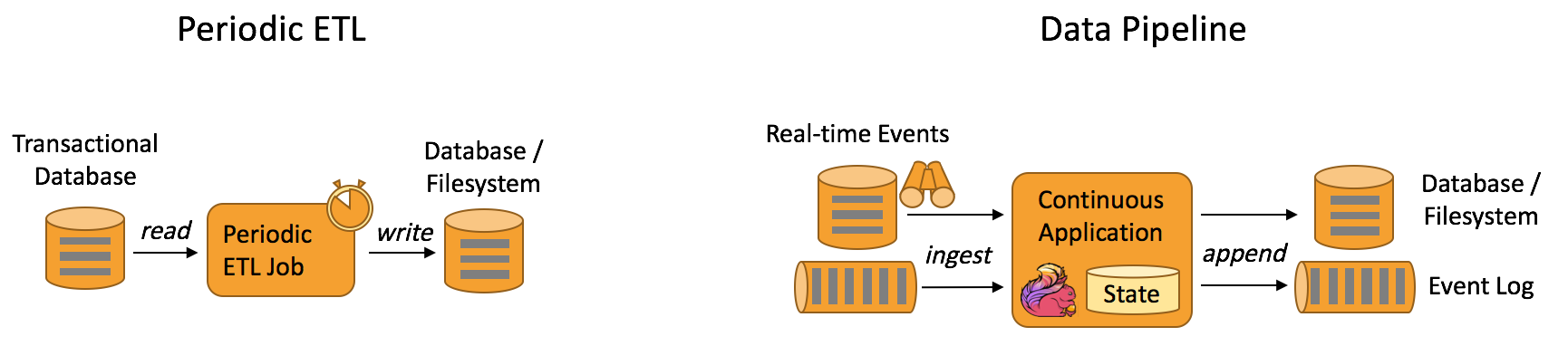
6. 数据管道
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
Flink 如何支持数据管道应用?
很多常见的数据转换和增强操作可以利用 Flink 的 SQL 接口(或 Table API)及用户自定义函数解决。如果数据管道有更高级的需求,可以选择更通用的 DataStream API 来实现。Flink 为多种数据存储系统(如:Kafka、Kinesis、Elasticsearch、JDBC数据库系统等)内置了连接器。同时它还提供了文件系统的连续型数据源及数据汇,可用来监控目录变化和以时间分区的方式写入文件。
假设我们是一个在线购物网站,需要对实时的用户购物行为数据(例如浏览、点击、购买等行为)进行处理分析,以便于实时推荐产品或者进行其他营销活动。这个场景下,我们就可以使用 Flink 构建实时数据处理管道。
-
数据采集:首先,用户的行为数据会被实时地打到 Kafka 这样的消息中间件。这时,Flink 可以利用自带的 Kafka connector 从 Kafka 中读取数据。
-
数据处理:Flink 支持实时流处理以及复杂事件处理。在读取到 Kafka 中的数据之后,Flink 可以实时处理这些数据,例如过滤出购买行为,或者对浏览行为进行计数等等。这里可以利用 Flink 的窗口操作进行时间窗口内的数据聚合。
-
数据存储和推荐系统的反馈:处理完的数据可以存储到例如 HDFS 或者 Elasticsearch 这样的系统中以便后续的离线分析。同时,处理结果也可以实时地发送到推荐系统,推荐系统根据这些信息实时调整推荐策略。这部分可以利用 Flink 的 sink 功能实现。
使用 Apache Flink 进行流处理的简单示例,
假设我们在接收一流的商品交易记录,并将交易额大于某个值的记录筛选出来。
首先连接到 Kafka 作为数据源并消费其中的消息。然后,我们将每条消息转换为 Transaction 对象(该对象是我们自定义的,包含了 product 和 price 信息),然后通过 filter 函数过滤出价格大于 100 的交易记录。
// 创建一个 Flink 执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 假设我们从 Kafka 中读取数据,所以需要定义一个 KafkaSource
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("group.id", "test");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("flink-topic", new SimpleStringSchema(), kafkaProps);
// 添加 source
DataStream<String> stream = environment.addSource(kafkaConsumer);
// 我们假设从 Kafka 中获得的消息是一个 JSON 字符串,包含 product 和 price,我们需要解析 JSON 字符串并过滤出价值大于 100 的交易。
DataStream<Transaction> transactions = stream.map(new MapFunction<String, Transaction>() {
private static final long serialVersionUID = -6867736771747690202L;
@Override
public Transaction map(String value) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.readValue(value, Transaction.class);
}
});
DataStream<Transaction> filteredTransactions = transactions.filter(new FilterFunction<Transaction>() {
@Override
public boolean filter(Transaction t) throws Exception {
return t.getPrice() > 100;
}
});
// 打印结果
filteredTransactions.print();
// 执行作业
environment.execute("Flink Streaming Java API Skeleton");
进一步完善以上流程可以形成一个闭环,形成一个实时的、动态调整的数据处理与产品推荐体系。这就是一个实际应用中 Flink 如何支持数据管道应用的例子。通过 Flink,我们可以构建出实时反应、高效的、确保数据一致性的数据管道。
典型的数据管道应用实例
电子商务中的实时查询索引构建
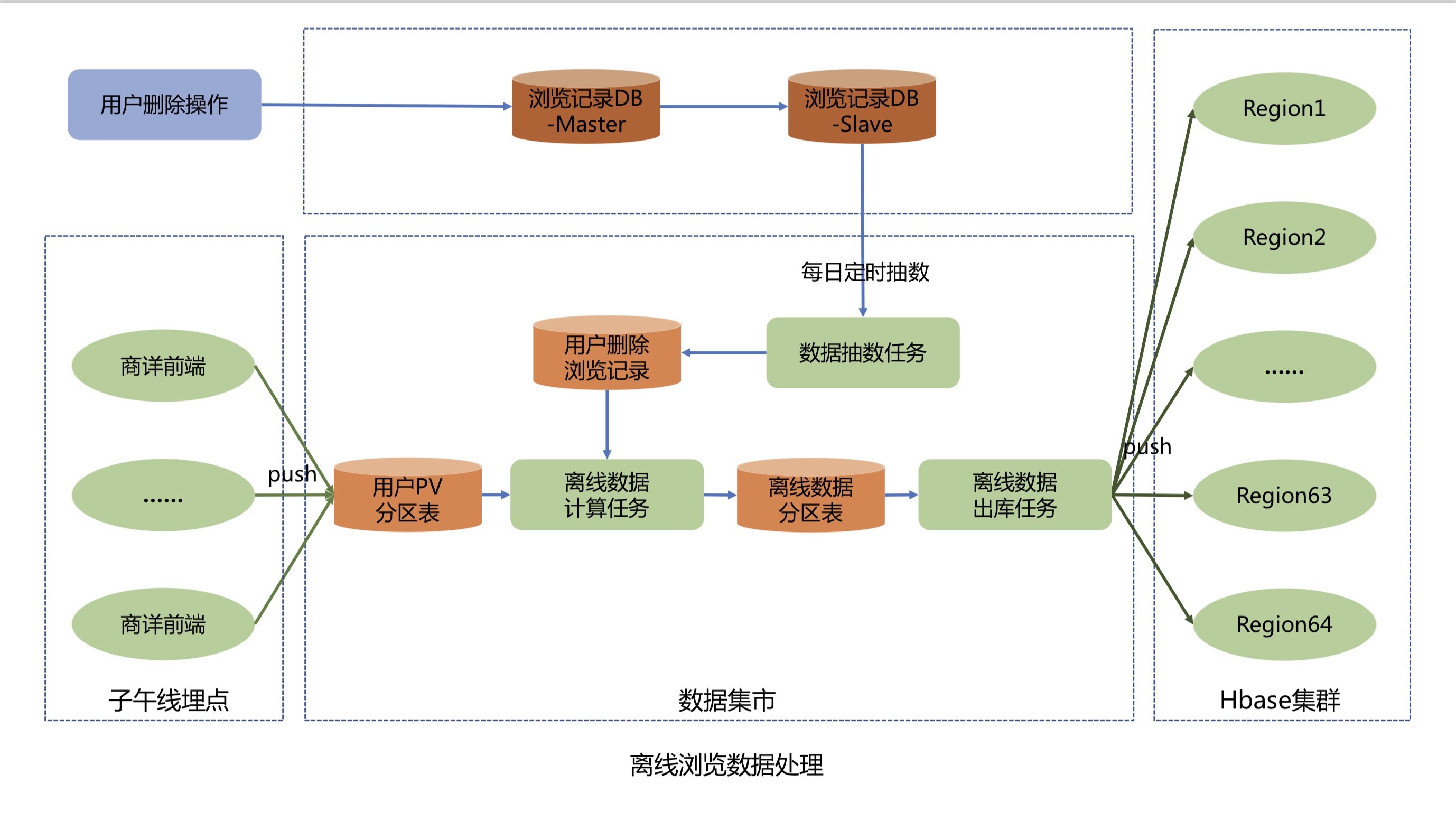
电子商务中的持续 ETL
7. 流式分析
流式分析应用示例
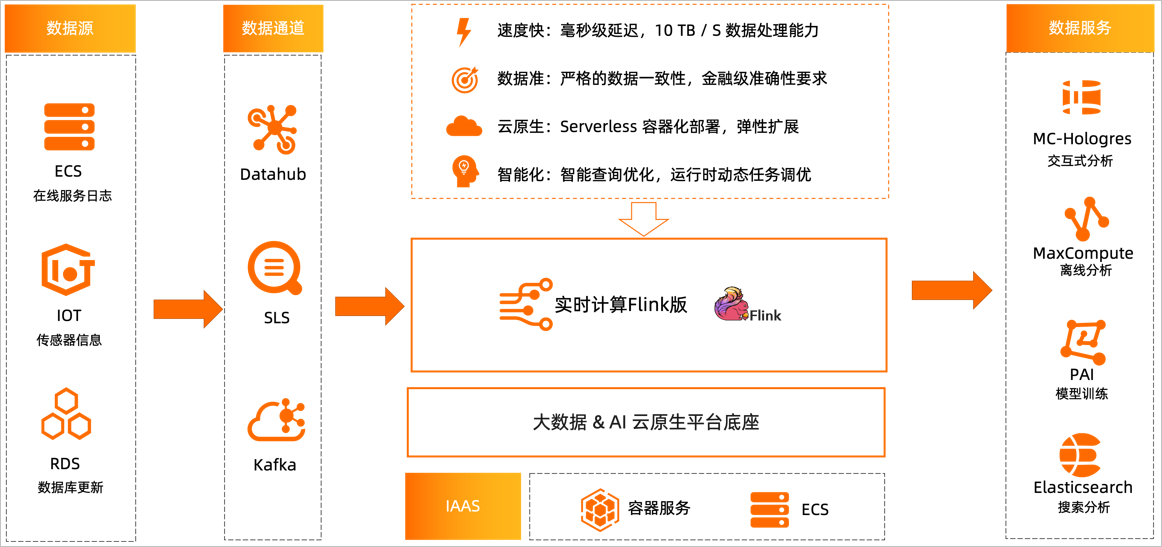
示例
Apache Flink 是专为分布式、高性能、总持续大数据处理而设计的开源流处理框架。它提供了用于常规批处理和流处理的 API 。其核心是一个流处理引擎,专门设计用于执行任意数据流的计算,在内存执行以提供高性能。
以下是一个简单的 Apache Flink 流处理示例,用于读取 Stream 数据、处理后输出。
socket作为数据源,每接收到一行文本数据,就拆分为多个单词,然后通过 keyBy 和 sum 进行类似 MapReduce 的处理,最后将结果打印到标准输出。为运行此程序,您需要在本地主机的9999端口上启动一个套接字服务器。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 创建 stream execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建一个 DataStream,数据来源可以是网络套接字、文件、kafka、数据集等
DataStream<String> textStream = env.socketTextStream("localhost", 9999);
// 使用空格拆分接收到的字符串,然后对结果执行 word count
DataStream<Tuple2<String, Integer>> wordCountStream = textStream
.flatMap(new Tokenizer())
.keyBy(0)
.sum(1);
// 打印结果到 stdout (这也可以写出到文件或网络等)
wordCountStream.print();
// 启动流计算
env.execute("WordCount Stream");
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// 使用非字母字符拆分字符串
String[] words = value.split("\\W+");
// 对单词进行计数
for (String word : words) {
if (word.length() > 0) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}
参考文档
https://flink.apache.org/zh/what-is-flink/use-cases/#%E4%BB%80%E4%B9%88%E6%98%AF%E6%95%B0%E6%8D%AE%E7%AE%A1%E9%81%93