Redis 只有 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
zset 结构体里有两个数据结构:一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
typedef struct zset{
dict *dict;
zskiplist *zsl;
} zset;
Zset 对象在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致。
Zset 对象能支持范围查询(如 ZRANGEBYSCORE 操作),这是因为它的数据结构设计采用了跳表,而又能以常数复杂度获取元素权重(如 ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
可能很多人会奇怪,为什么我开头说 Zset 对象的底层数据结构是「压缩列表」或者「跳表」,而没有说哈希表呢?
Zset 对象在使用跳表作为数据结构的时候,是使用由「哈希表+跳表」组成的 struct zset,但是我们讨论的时候,都会说跳表是 Zset 对象的底层数据结构,而不会提及哈希表,是因为 struct zset 中的哈希表只是用于以常数复杂度获取元素权重,大部分操作都是跳表实现的。
接下来,详细的说下跳表。
跳表结构设计
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表,这样的好处是能快读定位数据。
那跳表长什么样呢?我这里举个例子,下图展示了一个层级为 3 的跳表。
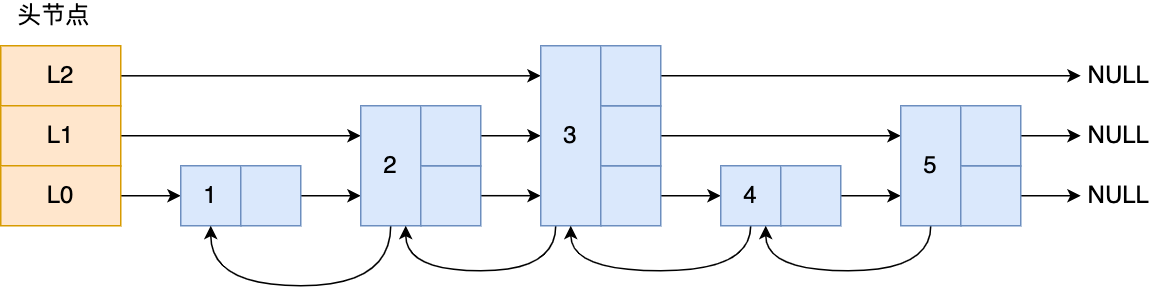
图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
● L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
● L1 层级共有 3 个节点,分别是节点 2、3、5;
● L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 O(logN)。
那跳表节点是怎么实现多层级的呢?这就需要看「跳表节点」的数据结构了,如下:
typedef struct zskiplistNode{
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
structzskiplistNode*backward;
//节点的level数组,保存每层上的前向指针和跨度
structzskiplistLevel{
structzskiplistNode*forward;
unsignedlong span;
} level[];
} zskiplistNode;
Zset 对象要同时保存「元素」和「元素的权重」,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针(struct zskiplistNode *backward),指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表是一个带有层级关系的链表,而且每一层级可以包含多个节点,每一个节点通过指针连接起来,实现这一特性就是靠跳表节点结构体中的zskiplistLevel 结构体类型的 level 数组。
level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。zskiplistLevel 结构体里定义了「指向下一个跳表节点的指针」和「跨度」,跨度时用来记录两个节点之间的距离。
比如,下面这张图,展示了各个节点的跨度。

第一眼看到跨度的时候,以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针(struct zskiplistNode *forward)就可以完成了。
跨度实际上是为了计算这个节点在跳表中的排位。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L2),并且层的跨度是 3,所以节点 3 在跳表中的排位是 3。
另外,图中的头节点其实也是 zskiplistNode 跳表节点,只不过头节点的后向指针、权重、元素值都没有用到,所以图中省略了这部分。
问题来了,由谁定义哪个跳表节点是头节点呢?这就介绍「跳表」结构体了,如下所示:
typedef struct zskiplist{
structzskiplistNode*header,*tail;
unsignedlong length;
int level;
} zskiplist;
跳表结构里包含了:
- 跳表的头尾节点,便于在O(1)时间复杂度内访问跳表的头节点和尾节点;
- 跳表的长度,便于在O(1)时间复杂度获取跳表节点的数量;
- 跳表的最大层数,便于在O(1)时间复杂度获取跳表中层高最大的那个节点的层数量;
跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
- 如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。

如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
跳表节点层数设置
跳表的相邻两层的节点数量的比例会影响跳表的查询性能。
举个例子,下图的跳表,第二层的节点数量只有 1 个,而第一层的节点数量有 6 个。

这时,如果想要查询节点 6,那基本就跟链表的查询复杂度一样,就需要在第一层的节点中依次顺序查找,复杂度就是 O(N) 了。所以,为了降低查询复杂度,我们就需要维持相邻层结点数间的关系。
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
下图的跳表就是,相邻两层的节点数量的比例是 2 : 1。

那怎样才能维持相邻两层的节点数量的比例为 2 : 1 呢?
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
虽然我前面讲解跳表的时候,图中的跳表的「头节点」都是 3 层高,但是其实如果层高最大限制是 64,那么在创建跳表「头节点」的时候,就会直接创建 64 层高的头节点。
如下代码,创建跳表时,头节点的 level 数组有 ZSKIPLIST_MAXLEVEL个元素(层),节点不存储任何 member 和 score 值,level 数组元素的 forward 都指向NULL, span值都为0。
/* Create a new skiplist. */
zskiplist *zslCreate(void){
int j;
zskiplist *zsl;
zsl =zmalloc(sizeof(*zsl));
zsl->level =1;
zsl->length =0;
zsl->header =zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for(j =0; j < ZSKIPLIST_MAXLEVEL; j++){
zsl->header->level[j].forward =NULL;
zsl->header->level[j].span =0;
}
zsl->header->backward =NULL;
zsl->tail =NULL;
return zsl;
}
其中,ZSKIPLIST_MAXLEVEL 定义的是最高的层数,Redis 7.0 定义为 32,Redis 5.0 定义为 64,Redis 3.0 定义为 32。
为什么用跳表而不用平衡树?
这里插一个常见的面试题:为什么 Zset 的实现用跳表而不用平衡树(如 AVL树、红黑树等)?
Redis的作者 @antirez 是怎么说的:
主要是从内存占用、对范围查找的支持、实现难易程度这三方面总结的原因:
- 它们不是非常内存密集型的。基本上由你决定。改变关于节点具有给定级别数的概率的参数将使其比 btree 占用更少的内存。
- Zset 经常需要执行 ZRANGE 或 ZREVRANGE 的命令,即作为链表遍历跳表。通过此操作,跳表的缓存局部性至少与其他类型的平衡树一样好。
- 它们更易于实现、调试等。例如,由于跳表的简单性,我收到了一个补丁(已经在Redis master中),其中扩展了跳表,在 O(log(N) 中实现了 ZRANK。它只需要对代码进行少量修改。
我再详细补充点: - 从内存占用上来比较,跳表比平衡树更灵活一些。平衡树每个节点包含 2 个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
- 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。