数据库,计算机网络、操作系统刷题笔记18
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题笔记系列文章:
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
文章目录
- 数据库,计算机网络、操作系统刷题笔记18
- @[TOC](文章目录)
- Oracle知识点复习
- DDL:create,drop,truncate,alter table数据库定义语言
- DML:数据库操纵语言,增删改查insert,delete,update,select【DQL查询是单独可以列出来的】
- DCL:grant,revoke数据库控制语言
- http 2.0新特性
- DNS 服务的常见资源记录类型
- 如果将网络IP段40.15.128.0/17划分成2个子网,则第一个子网IP段为40.15.128.0/18,则第二个子网为:
- HTTP请求的各个参数
- 一个网卡的硬件地址是烧写在其ROM中的。
- 由于局域网的介质访问控制方法比较复杂,所以局域网的标准主要建立在( )上。
- 每个子网要求支持至少 300 个主机,应该选择下面哪个子网掩码( )?
- 集线器不隔离冲突域,隔离广播域。
- PPP协议有两种认证方式,PAP不怎么安全
- I/O重定向,让打印直接输出到屏幕
- 下列操作中,需要执行加锁的操作是()
- 用一位奇偶校验法,能检测出一位存储器错的百分比是()
- 在UNIX 文件系统中,文件的路径名和磁盘索引节点之间并不是一一对应的
- 下面有关文件block的说法错误的是?
- 缺页率主要受以下几个因素影响
- 进程从等待状态进入就绪状态可能是由于()。
- 使用C语言将一个1G字节的字符数组从头到尾全部设置为字’A’,在一台典型的当代PC上,需要花费的CPU时间的数量级最接近()
- 若某文件系统索引结点(inode)中有直接地址项和间接地址项, 则下列选项中, 与单个文件长度无关的因素是( )。
- 下列()进程调度算法会引起进程的饥饿问题。
- 若进程被中断了,那么当中断处理程序执行完成后,进程不是立即获得 CPU 控制权,而是会进入就绪序列排队,
- 批处理可以直接排除,一道批处理执行是直接完成的,中间不会有任何响应。所以不用考虑的。
- 在下面的叙述中正确的是()。
- 要注意概念的理解,进程调度算法使用不当会造成进程长时间等待,与死锁没有关系。造成死锁主要看产生死锁的四个必要条件。
- 8086读写一个以奇数地址开始的双字,最少需几个线周期?()
- 边界网关协议(BGP)是运行于 TCP 上的一种自治系统的路由协议。
- 物理层:电路交换在发送数据前要建立一条端到端的路径
- 拓扑结构指的是()的拓扑结构。
- D.https协议下cookie是明文传递的 https协议下传输的内容都是加密后的,包括cookie也是,
- 网关工作在 OSI 模型的( )
- 总结
文章目录
- 数据库,计算机网络、操作系统刷题笔记18
- @[TOC](文章目录)
- Oracle知识点复习
- DDL:create,drop,truncate,alter table数据库定义语言
- DML:数据库操纵语言,增删改查insert,delete,update,select【DQL查询是单独可以列出来的】
- DCL:grant,revoke数据库控制语言
- http 2.0新特性
- DNS 服务的常见资源记录类型
- 如果将网络IP段40.15.128.0/17划分成2个子网,则第一个子网IP段为40.15.128.0/18,则第二个子网为:
- HTTP请求的各个参数
- 一个网卡的硬件地址是烧写在其ROM中的。
- 由于局域网的介质访问控制方法比较复杂,所以局域网的标准主要建立在( )上。
- 每个子网要求支持至少 300 个主机,应该选择下面哪个子网掩码( )?
- 集线器不隔离冲突域,隔离广播域。
- PPP协议有两种认证方式,PAP不怎么安全
- I/O重定向,让打印直接输出到屏幕
- 下列操作中,需要执行加锁的操作是()
- 用一位奇偶校验法,能检测出一位存储器错的百分比是()
- 在UNIX 文件系统中,文件的路径名和磁盘索引节点之间并不是一一对应的
- 下面有关文件block的说法错误的是?
- 缺页率主要受以下几个因素影响
- 进程从等待状态进入就绪状态可能是由于()。
- 使用C语言将一个1G字节的字符数组从头到尾全部设置为字’A’,在一台典型的当代PC上,需要花费的CPU时间的数量级最接近()
- 若某文件系统索引结点(inode)中有直接地址项和间接地址项, 则下列选项中, 与单个文件长度无关的因素是( )。
- 下列()进程调度算法会引起进程的饥饿问题。
- 若进程被中断了,那么当中断处理程序执行完成后,进程不是立即获得 CPU 控制权,而是会进入就绪序列排队,
- 批处理可以直接排除,一道批处理执行是直接完成的,中间不会有任何响应。所以不用考虑的。
- 在下面的叙述中正确的是()。
- 要注意概念的理解,进程调度算法使用不当会造成进程长时间等待,与死锁没有关系。造成死锁主要看产生死锁的四个必要条件。
- 8086读写一个以奇数地址开始的双字,最少需几个线周期?()
- 边界网关协议(BGP)是运行于 TCP 上的一种自治系统的路由协议。
- 物理层:电路交换在发送数据前要建立一条端到端的路径
- 拓扑结构指的是()的拓扑结构。
- D.https协议下cookie是明文传递的 https协议下传输的内容都是加密后的,包括cookie也是,
- 网关工作在 OSI 模型的( )
- 总结
Oracle知识点复习
SQL语句的类型:
DML:数据库操纵语言,增删改查insert,delete,update,select【DQL查询是单独可以列出来的】
DDL:create,drop,truncate,alter table数据库定义语言
DCL:grant,revoke数据库控制语言
DDL:create,drop,truncate,alter table数据库定义语言
创建表
SQL> set pagesize 200;
SQL> set linesize 150;
SQL> create table test1(id number(7,2),name varchar2(20),deptno number(7,2),sal number(10,5));
表已创建。
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------------------------------------------------- -------- --------------------------------------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL
字段名字 字段类型
用,隔开各个字段
注意事项:
需要主要权限和空间问题
空间满了,放不进去
scott用户默认拥有创建的权限
你要是新用户,可能没有权限,需要授权创建能力
表名字,不能乱写
必须以字母开头哦
SQL> create table 1test(id number);
create table 1test(id number)
*
第 1 行出现错误:
ORA-00903: 表名无效
只能包含大小写字母,数字,_,$,#
长度有限,1-30个字符,太长不行
不能与数据库中的其他对象冲突,比如视图,索引,触发器,存储过程,,,,
也不能与保留的关键字重合
dba账户,可以看保留字
select * from v$reserved_words
修改表
追加新的列
SQL> alter table test1 add class varchar2(20);
表已更改。
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL NUMBER(10,5)
CLASS VARCHAR2(20)
alter table 表名,然后add关键字
add可以替换为modify,修改字段类型
SQL> alter table test1 modify class varchar2(30);
表已更改。
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL NUMBER(10,5)
CLASS VARCHAR2(30)
修改类型啥的都行
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL NUMBER(10,5)
CLASS NUMBER
能否修改字段名字呢?
blob和clob类型不能修改,语法要求的
SQL> alter table test1 add other blob;
表已更改。
SQL> alter table test1 modify blob number;
alter table test1 modify blob number
*
第 1 行出现错误:
ORA-00904: "BLOB": 标识符无效
懂?
要改,就直接删除这个字段,然后加
SQL> alter table test1 drop column other;
表已更改。
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL NUMBER(10,5)
CLASS NUMBER
删除字段,是drop column关键字
修改字段名字
rename column
SQL> alter table test1 rename column class to other;
表已更改。
SQL> desc test1;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(7,2)
NAME VARCHAR2(20)
DEPTNO NUMBER(7,2)
SAL NUMBER(10,5)
OTHER NUMBER
删除表,直接表结构没了
SQL> drop table test4;
表已删除。
SQL> desc test4;
ERROR:
ORA-04043: 对象 test4 不存在
查看回收站
SQL> show recyclebin;
ORIGINAL NAME RECYCLEBIN NAME OBJECT TYPE DROP TIME
---------------- ------------------------------ ------------ -------------------
TEST4 BIN$hP7CP+XwQr+YiUlB4iKTWA==$0 TABLE 2022-12-25:12:40:25
SQL>
恢复表,闪回技术
purge recyclebin;清空回收站
purge是彻底删除
SQL> purge recyclebin;
回收站已清空。
SQL> select * from tab;
TNAME TABTYPE
------------------------------------------------------------ --------------
CLUSTERID
----------
BONUS TABLE
DEPT TABLE
EMP TABLE
TNAME TABTYPE
------------------------------------------------------------ --------------
CLUSTERID
----------
SALGRADE TABLE
TEST1 TABLE
TEST2 TABLE
TNAME TABTYPE
------------------------------------------------------------ --------------
CLUSTERID
----------
TEST3 TABLE
已选择7行。
SQL>
DML:数据库操纵语言,增删改查insert,delete,update,select【DQL查询是单独可以列出来的】
增
insert into tableName(字段1,2,3,,,) values(字段1值,2值,3值,,,)
字段和值一一对应,数据类型,个数,顺序都得保持一样
给test1插入数据
SQL> insert into test1(id,name,deptno,sal) values(1,'zhangsan',10,10000);
已创建 1 行。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
可以省略字段,直接上values,但是values插入的顺序,必须是完整的字段,顺序不能乱
SQL> insert into test1 values(2,'lisi',20,20000);
已创建 1 行。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
2 lisi 20 20000


还可以动态输入,&占位

SQL> insert into test1 values(&id,&name,&deptno,&sal);
输入 id 的值: 3
输入 name 的值: 'wangwu'
输入 deptno 的值: 20
输入 sal 的值: 30000
原值 1: insert into test1 values(&id,&name,&deptno,&sal)
新值 1: insert into test1 values(3,'wangwu',20,30000)
已创建 1 行。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
2 lisi 20 20000
3 wangwu 20 30000
动态输入感觉是多此一举了
好处在于,字段你是可以自定义的哦
SQL> insert into test1(id,&1,&2,&3) values(4,&1,&2,&3);
输入 1 的值: sal
输入 2 的值: deptno
输入 3 的值: name
输入 1 的值: 15000
输入 2 的值: 30
输入 3 的值: 'kk'
原值 1: insert into test1(id,&1,&2,&3) values(4,&1,&2,&3)
新值 1: insert into test1(id,sal,deptno,name) values(4,15000,30,'kk')
已创建 1 行。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
2 lisi 20 20000
3 wangwu 20 30000
4 kk 30 15000
你看输入的顺序可以不痛了,美滋滋
&可以放很多地方,表名字也行哦
批量插入数据
创建新表时整体导入
把emp整体数据,复制到test2表中
用as,复制
create table test2 as select * from emp;
SQL> create table test2 as (select * from emp);
表已创建。
SQL> select * from test2;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-12月-80 800 20
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30
7566 JONES MANAGER 7839 02-4月 -81 2975 20
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30
7782 CLARK MANAGER 7839 09-6月 -81 2450 10
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20
7839 KING PRESIDENT 17-11月-81 5000 10
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30
7876 ADAMS CLERK 7788 23-5月 -87 1100 20
7900 JAMES CLERK 7698 03-12月-81 950 30
7902 FORD ANALYST 7566 03-12月-81 3000 20
7934 MILLER CLERK 7782 23-1月 -82 1300 10
已选择14行。
as很重要哦,不是from
是as
我们也可以筛选一部分
SQL> create table test3 as (select empno,ename from emp where deptno in(10,20));
表已创建。
SQL> select * from test3;
EMPNO ENAME
---------- --------------------
7369 SMITH
7566 JONES
7782 CLARK
7788 SCOTT
7839 KING
7876 ADAMS
7902 FORD
7934 MILLER
已选择8行。
很容易的
创建一个新表,但是我只要表结构,不要数据,怎么说?
用where 1=0,不满足条件,就不加数据了
骚啊
SQL> create table test4 as (select * from emp where 1=0);
表已创建。
SQL> select * from test4;
未选定行
SQL> desc test4;
名称 是否为空? 类型
----------------------------------------------------------------------------------- -------- --------------------------------------------------------
EMPNO NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
怎么说,看见没
有表结构,但是没用数据
旧表里面整体批量插入
insert into test4 (select * from emp);
没用as?
直接干进去
SQL> insert into test4 (select * from emp);
已创建14行。
SQL> select * from test4;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-12月-80 800 20
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30
7566 JONES MANAGER 7839 02-4月 -81 2975 20
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30
7782 CLARK MANAGER 7839 09-6月 -81 2450 10
7788 SCOTT ANALYST 7566 19-4月 -87 3000 20
7839 KING PRESIDENT 17-11月-81 5000 10
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30
7876 ADAMS CLERK 7788 23-5月 -87 1100 20
7900 JAMES CLERK 7698 03-12月-81 950 30
7902 FORD ANALYST 7566 03-12月-81 3000 20
7934 MILLER CLERK 7782 23-1月 -82 1300 10
已选择14行。
确实,没用as
直接干进去
还有begin … end

这种算是一个事务,不过这好麻烦呀
begin
2 insert into test1 values(5,'xx',10,10000);
3 insert into test1 values(6,'tt',20,10000);
4 end;
SQL> begin
2 insert into test1 values(5,'xx',10,10000);
3 insert into test1 values(6,'tt',20,10000);
4 end;
5 /
PL/SQL 过程已成功完成。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
5 xx 10 10000
6 tt 20 10000
1 zhangsan 10 10000
2 lisi 20 20000
3 wangwu 20 30000
4 kk 30 15000
已选择6行。
回车不顶用的话,直接/
确认
确实批量插入
要是海量数据,gg
上亿条
得需要数据泵 sql loader,外部表
删
删除关键字delete from可以写,可不写
需要where控制,否则全部数据gg
SQL> delete from test3;
已删除8行。
你要是想撤销,DML是可以通过rollback搞定的
因为没有隐式提交commit
SQL> rollback;
回退已完成。
SQL> select * from test3;
EMPNO ENAME
---------- --------------------
7369 SMITH
7566 JONES
7782 CLARK
7788 SCOTT
7839 KING
7876 ADAMS
7902 FORD
7934 MILLER
已选择8行。
我们可以限定来删除
SQL> delete from test3 where empno>7700;
已删除6行。
SQL> select * from test3;
EMPNO ENAME
---------- --------------------
7369 SMITH
7566 JONES
还可以通过DDL删除表中的所有数据
truncate table 表名,不可以回退
SQL> select * from test3;
EMPNO ENAME
---------- --------------------
7369 SMITH
7566 JONES
SQL> truncate table test3;
表被截断。
SQL> rollback;
回退已完成。
SQL> select * from test3;
未选定行
因为truncate是DDL语句,直接commit了,没法回退rollback
DML的增删改,是可以rollback的
DDL,DCL是不行的哦
打开执行时间
set timing on;

俩删除的方法,步骤,还不通呢
骚啊
很骚
SQL> delete from test2;
已删除14行。
已用时间: 00: 00: 00.00
SQL> rollback;
回退已完成。
已用时间: 00: 00: 00.00
SQL> truncate table test2;
表被截断。
已用时间: 00: 00: 00.00
delete支持闪回,truncate不支持闪回
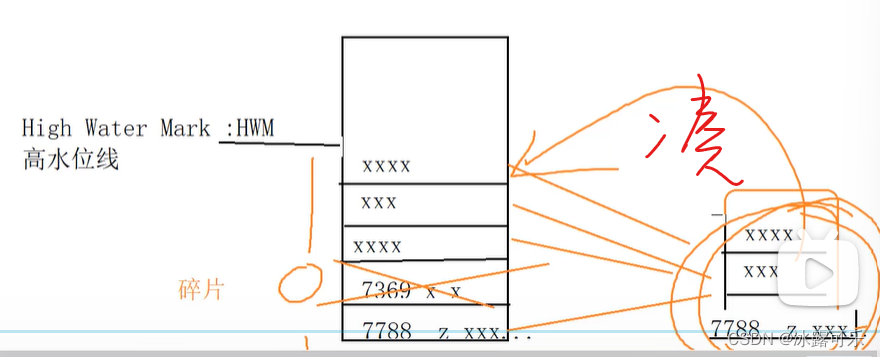
delete不会释放空间,换一个地方存储数据,undo空间里面回收站,并没真的释放,但是truncate确实直接清空了
delete会产生内存碎片,而truncate不会产生内存碎片

删除7369
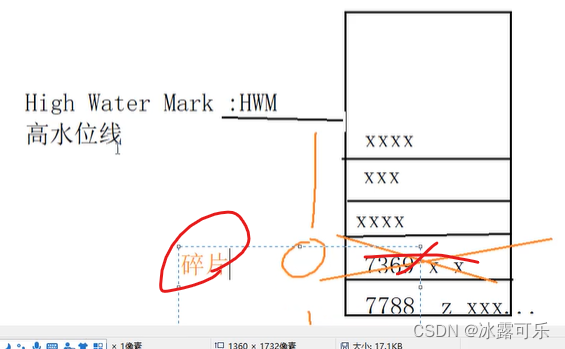
碎片太多的话,需要紧凑技术解决
alter table 表名 move;
将表格导出导入
改
update
update 表名字 set 字段1=值1,字段2=值2,,,,where 控制特定的行,否则整个表格都被你修改了
SQL> update test1 set id=7;
已更新4行。
已用时间: 00: 00: 00.00
SQL> set timing off;
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
7 zhangsan 10 10000
7 lisi 20 20000
7 wangwu 20 30000
7 kk 30 15000
所以不能整个表格都update,得用where限制一下
SQL> rollback;
回退已完成。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
2 lisi 20 20000
3 wangwu 20 30000
4 kk 30 15000
SQL> update test1 set sal=20000 where id = 3;
已更新 1 行。
SQL> select * from test1;
ID NAME DEPTNO SAL
---------- ---------------------------------------- ---------- ----------
1 zhangsan 10 10000
2 lisi 20 20000
3 wangwu 20 20000
4 kk 30 15000
懂?
DCL:grant,revoke数据库控制语言
后续笔记,我继续说
http 2.0新特性
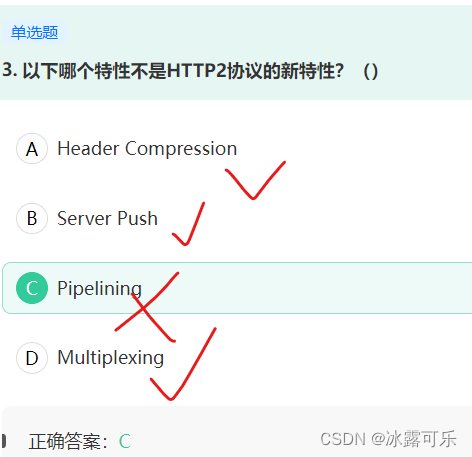
1:增加二进制分帧
2:压缩头部
3:多路复用
4:请求优先级
5:服务器提示
DNS 服务的常见资源记录类型
链接:https://www.nowcoder.com/questionTerminal/8179f561410b47729bee6808afae494c
来源:牛客网
DNS 服务的常见资源记录类型:
A记录(主机地址)、
CNAME记录(别名)、
MX记录(邮件主机)、
NS记录(名称服务器)、
SOA记录(起始授权机构)、
PTR记录(IP反向解析)、
SRV记录(MS DNS服务器的活动目录)。
故选项 ABC 正确。
如果将网络IP段40.15.128.0/17划分成2个子网,则第一个子网IP段为40.15.128.0/18,则第二个子网为:
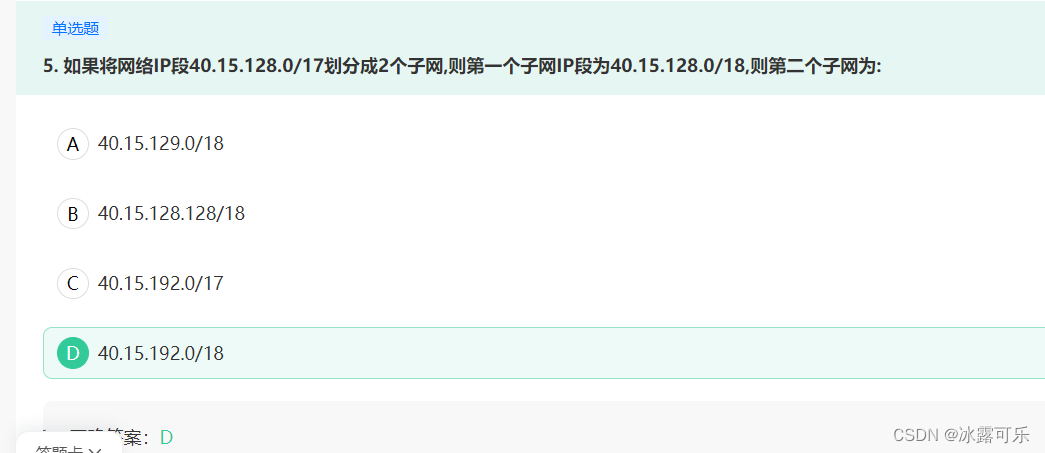

18位,上,第一个子网是0
第二个子网1
就是192
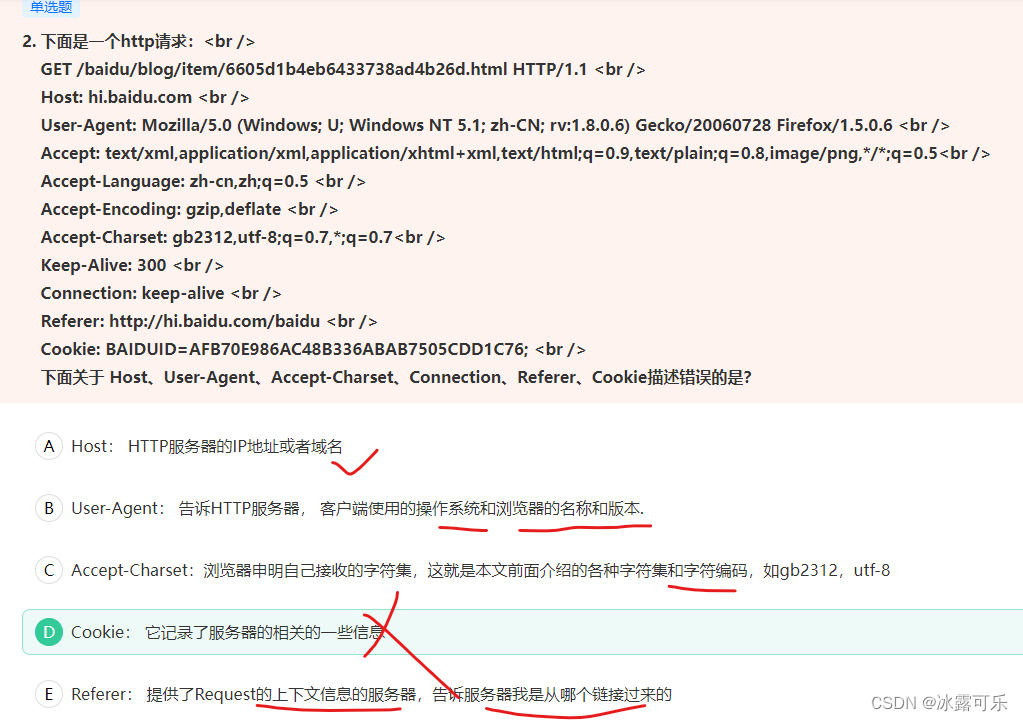
HTTP请求的各个参数


cookie是用来记录用户信息,表明用户身份的。
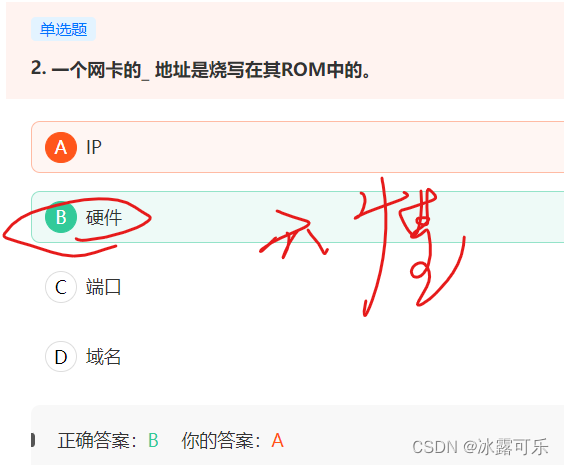
一个网卡的硬件地址是烧写在其ROM中的。
链接:https://www.nowcoder.com/questionTerminal/d321ebe1a98c4b3f82fd0b1444b074df
来源:牛客网
由于局域网的介质访问控制方法比较复杂,所以局域网的标准主要建立在( )上。
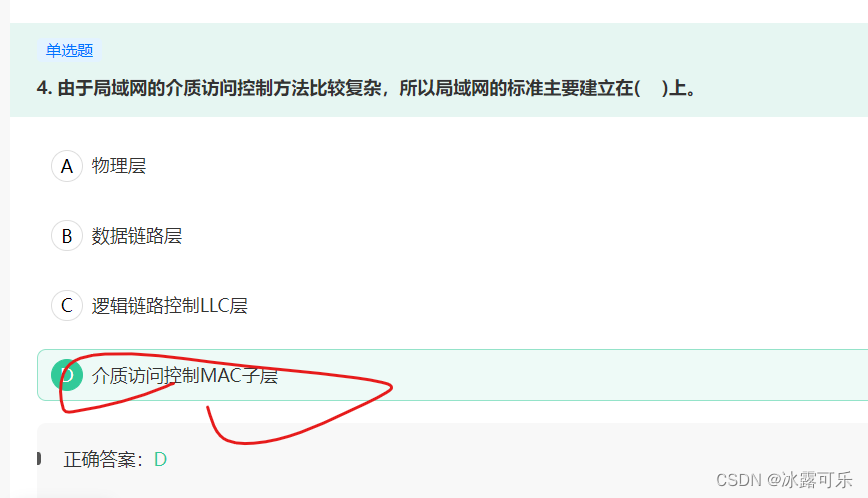
局域网体系结构分为3层:物理层、媒体访问控制(MAC)子层和逻辑链路控制(LLC)子层(实际上仍是两层,即:物理层和数据链路层)。
1.物理层 局域网体系结构中的物理层和计算机网络OSI参考模型中物理层的功能一样,主要处理物理链路上传输的比特流,
实现比特流的传输与接收、同步前序的产生和删除;建立、维护、撤销物理连接,处理机械、电气和过程的特性。
2.媒体访问控制MAC子层:MAC子层负责介质访问控制机制的实现,即处理局域网中各站点对共享通信介质的争用问题,不同类型的局域网*通常使用不同的介质访问控制协议,另外MAC 子层还涉及局域网中的物理寻址。
3.逻辑链路控制LLC子层:LLC子层负责屏蔽掉MAC子层的不同实现,将其变成统一的LLC界面,从而向网络层提供一致的服务。
局域网体系结构中的LLC子层和MAC子层共同完成类似于OSI参考模型中数据链路层的功能,将数据组成帧进行传输,并对数据帧进行顺序控制、差错控制和流量控制,使不可靠的链路变为可靠的链路。
每个子网要求支持至少 300 个主机,应该选择下面哪个子网掩码( )?
链接:https://www.nowcoder.com/questionTerminal/844829c0c3e1462a8eb2d475de0f29f3
来源:牛客网
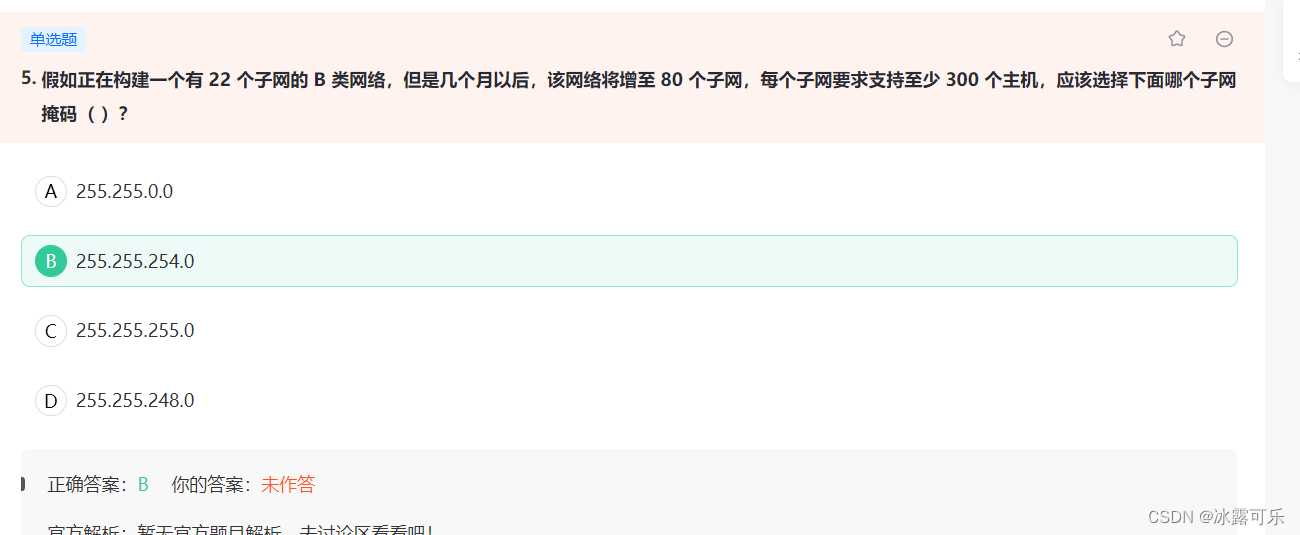
题目中每个子网至少要支持300个主机,(28-2)<300<(29-2),所以主机号至少应该占据9位,
即至少为11111111 11111111 11111110 00000000
这么看B,D都可以。
又因为是B类网络,默认的子网掩码是255.255.0.0,要支持80个子网的话,子网号至少占据7位,所以D不行,选择B
254最合适
但是D不行
COK
这题不容易啊,需要学会计算
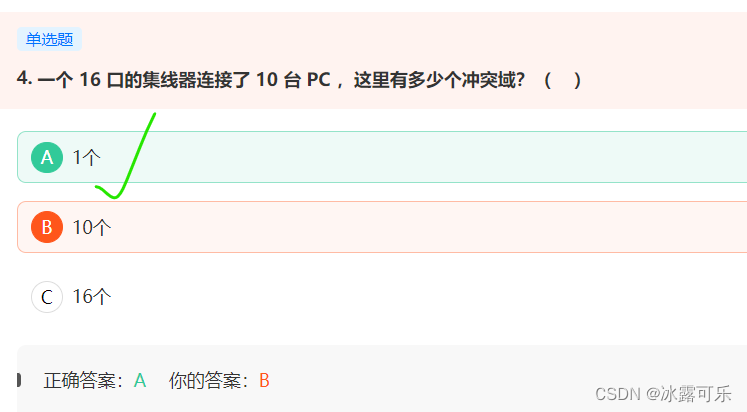
集线器不隔离冲突域,隔离广播域。

集线器的所有端口都是一个冲突域
网桥隔离冲突域,不隔离广播域
交换机隔离冲突域,可以隔离广播域。
这些别搞混了
PPP协议有两种认证方式,PAP不怎么安全
链接:https://www.nowcoder.com/questionTerminal/4bf9e912481548f597050fbd49911e35
来源:牛客网
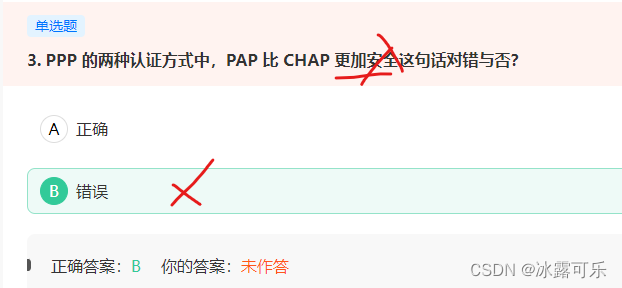
PPP协议有两种认证方式,PAP(口令鉴别协议)方式和CHAP(口令握手鉴别协议)方式。PAP只需进行一次认证,并且只在链路初始状态时执行。而且用户名与密码的传送方式是明文的。CHAP采用周期性的验证,并且认证内容经过MD5加密后再传送,安全性要比PAP高。
I/O重定向,让打印直接输出到屏幕
链接:https://www.nowcoder.com/questionTerminal/822a991ef2f5426798cb8efe5db6ab87
来源:牛客网
I/O重定向,是指用于I/O操作的设备可以更换(重定向),而不必改变应用程序。
比如调试程序,可将所有输出送屏幕显示,而程序调试完后,如需正式打印出来,需将I/O重定向中的数据结构—逻辑设备表中的显示终端改为打印机。
下列操作中,需要执行加锁的操作是()
ABC都可以划分成几个原子操作组合起来的(从内存中读变量的的值到寄存器中,对寄存器执行加或者减操作,再把新值写回变量所处的内存地址),
只有D是一个单独的原子操作
用一位奇偶校验法,能检测出一位存储器错的百分比是()
在UNIX 文件系统中,文件的路径名和磁盘索引节点之间并不是一一对应的
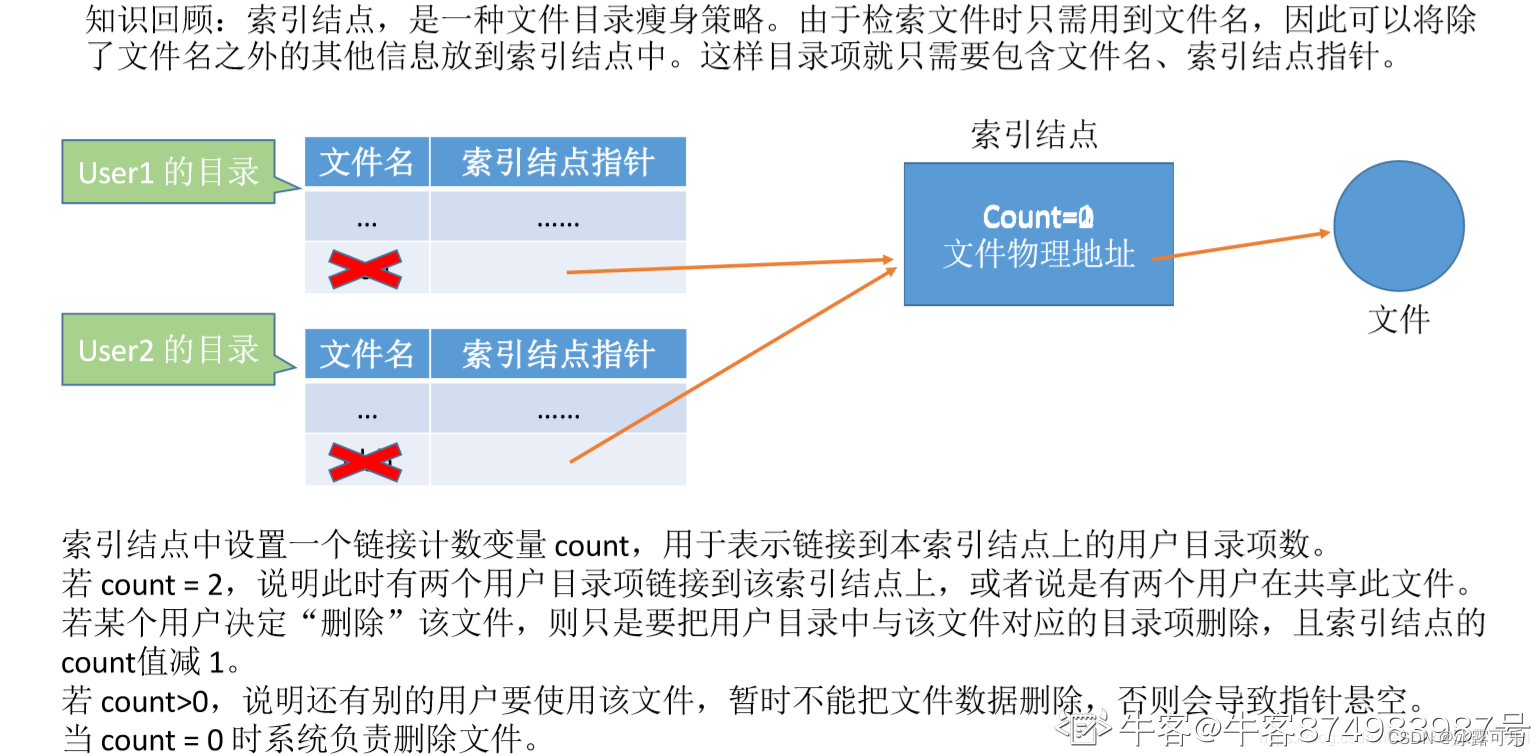
下面有关文件block的说法错误的是?
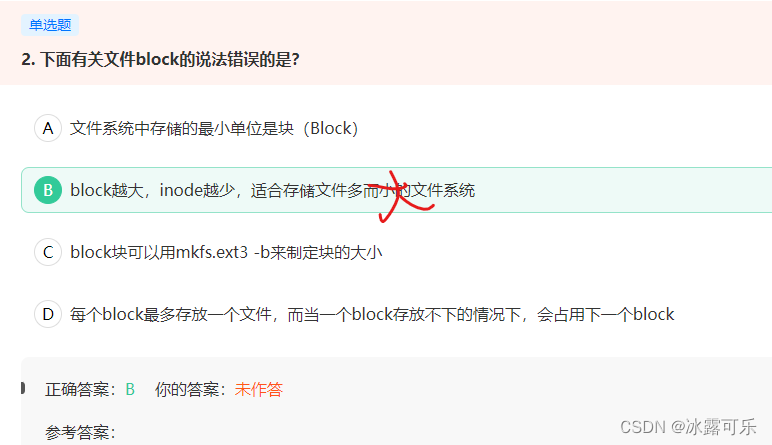
B 文件系统中的最小存储单元是逻辑块,也就是这里所说的Block;
block越大,inode越少,适合存储大文件的文件系统;
block越小,inode越多,适合存储文件多而小的文件系统。
要格式化档案系统为Ext3,亦可以使用命令mkfs.ext3,block块可以用mkfs.ext3 -b来制定快的大小,每个block块最多可存放一个文件;
block存放文件的数据,每个block最多存放一个文件,而当一个block存放不下的情况下,会占用下一个block。
缺页率主要受以下几个因素影响
1、页面大小 ‘’
2、页面置换算法
3、进程所分配的物理块
4、程序的固有特性
进程从等待状态进入就绪状态可能是由于()。
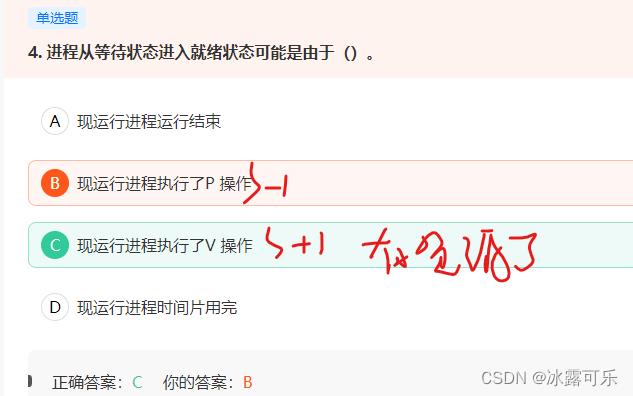
链接:https://www.nowcoder.com/questionTerminal/c68f0820569b4fb2bbb8c0dfd7507630
来源:牛客网
A 运行结束是在V作之后的,不是直接原因
B P作使信号量-1,尝试申请资源,发现为负说明没有申请到,阻塞自己到等待队列
C V***作使信号量+1,加完之后非正说明等待队列里有进程在等待,调用wakeup唤醒一个等待进程
D 时间片用完会从【执行状态】回到【就绪状态】,而不是进到【阻塞状态】
使用C语言将一个1G字节的字符数组从头到尾全部设置为字’A’,在一台典型的当代PC上,需要花费的CPU时间的数量级最接近()
链接:https://www.nowcoder.com/questionTerminal/1ea1fd8dfd9943529d9f3bdfff7f3ed9
来源:牛客网
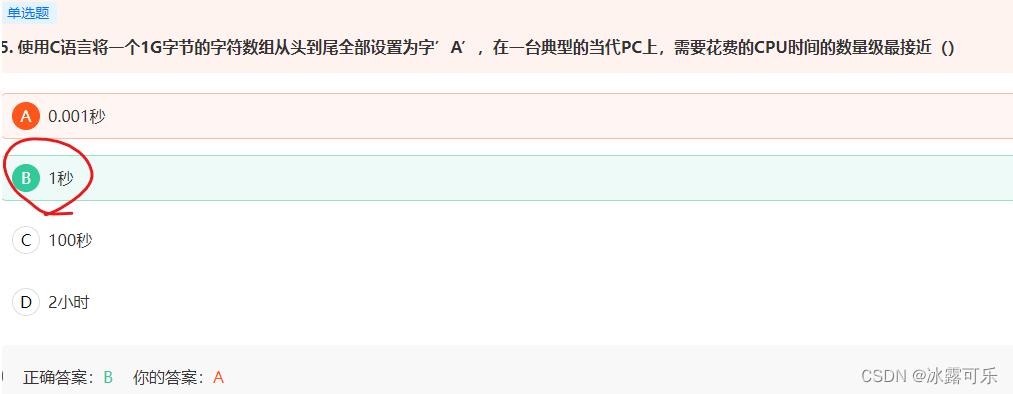
执行1条语句约1ns即10的-9次方秒,
1G=1024M=10241024k=102410241024byte,
每次赋值1byte都要执行一次语句,故至少花费10241024102410^-9=1.073741824s
gg
若某文件系统索引结点(inode)中有直接地址项和间接地址项, 则下列选项中, 与单个文件长度无关的因素是( )。
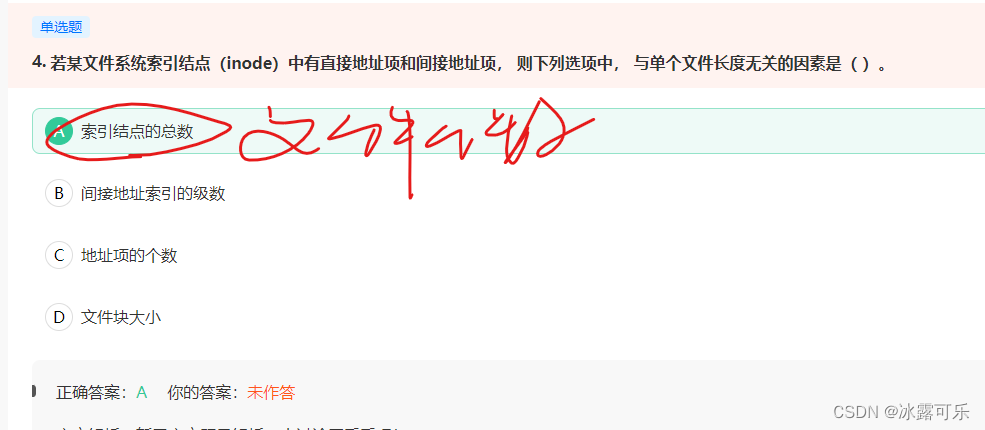
链接:https://www.nowcoder.com/questionTerminal/31bdc543b80940b7b0d7c074e51b094b
来源:牛客网
A:一个**文件索引节点对应一个FCB,对应一个目录项,**对应一个文件,文件索引节点数就是文件数,与单个文件的大小无关
B:索引节点内有直接地址和间接地址,间接地址指向次级索引块,使用间接索引增加了地址项的个数,缺点是多级间接地址访存次数多,延迟高
CD:文件大小=磁盘块总数(地址数)×每块磁盘块的大小.
骚啊
下列()进程调度算法会引起进程的饥饿问题。
链接:https://www.nowcoder.com/questionTerminal/34b77b85d27242f3b5e91b40bb03d5c0
来源:牛客网
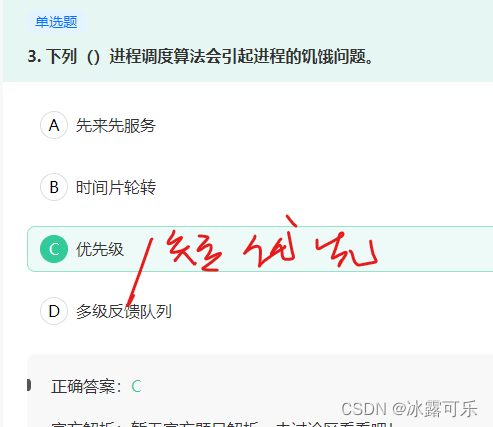
FCFS(先来先服务, 队列实现, 非抢占的):先请求CPU的进程先分配到CPU
SJF(最短作业优先调度算法):平均等待时间最短, 但难以知道下一个CPU区间长度
优先级调度算法(可以是抢占的, 也可以是非抢占的):优先级越高的越先分配到CPU, 相同优先级先到先服务,
存在的主要问题是:低优先级进程无穷等待CPU, 会导致无穷阻塞式饥饿,
解决方案:老化(随着时间的推移, 那些越老的进程优先级反而越高)
时间片轮转调度算法(可抢占的):队列中没有进程被分配超过一个时间片的CPU时间, 除非它是唯一可运行的进程。 如果进程的CPU区间超过了一个时间片, 那么该进程就被抢占并放回就绪队列
**多级队列调度算法:**将就绪队列分成多个独立的队列, 每个队列都有自己的调度算法, 队列之间采用固定优先级抢占调度, 其中, 一个进程根据自身属性被永久地分配到一个队列中
**多级反馈队列调度算法:**与多级队列调度算法相比, 其允许进程在队列之间移动, 若进程使用过多CPU时间, 那么它会被转移到更低的优先级队列, 在较低优先级队列等待时间过长的进程会被转移到更高优先级队列, 以防止饥饿发生
若进程被中断了,那么当中断处理程序执行完成后,进程不是立即获得 CPU 控制权,而是会进入就绪序列排队,
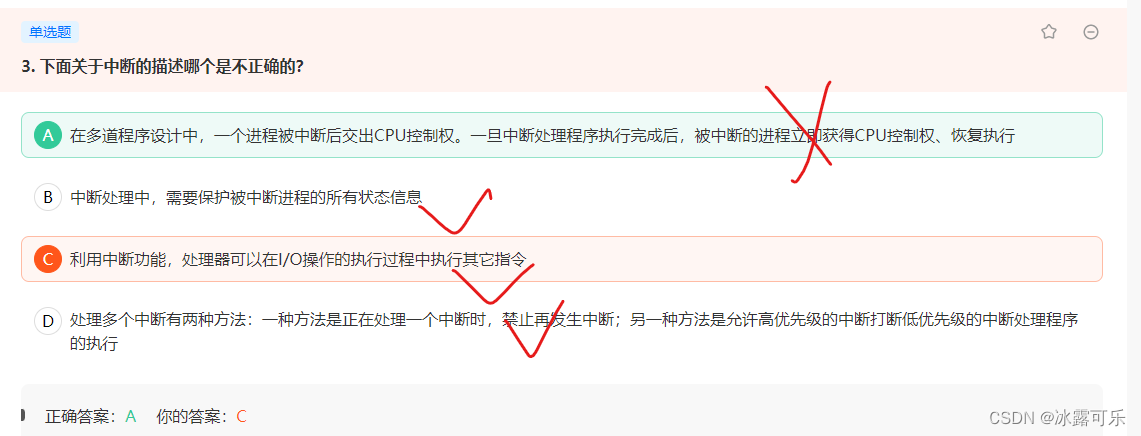
所以 A 选项错误。
这个题已经错过2次了哦
批处理可以直接排除,一道批处理执行是直接完成的,中间不会有任何响应。所以不用考虑的。

在下面的叙述中正确的是()。
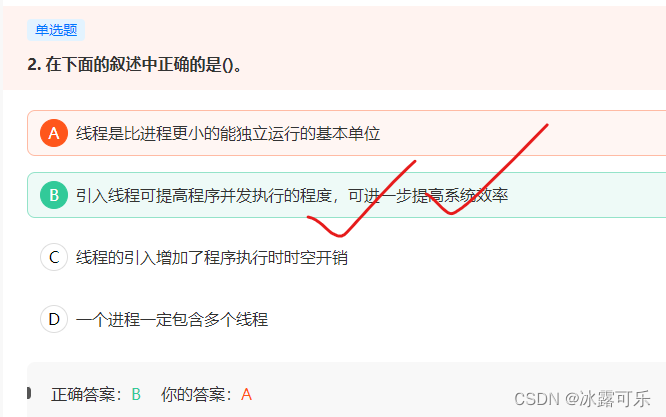
A线程不能独立运行,线程需要进程所获得的资源。
C引入线程机制降低了时空的开销。
D一个进程至少包含一个主线程(线程数量大于等于1)。
要注意概念的理解,进程调度算法使用不当会造成进程长时间等待,与死锁没有关系。造成死锁主要看产生死锁的四个必要条件。
死锁与调度算法无关啊卧槽
8086读写一个以奇数地址开始的双字,最少需几个线周期?()

8086是16位芯片,题目要求读取双字则为32位,即读取4个字节。而从奇数地址开始读,只能读取1个字节,偶数地址开始能读取2个字节。因此4个字节需要3个线周期。1->2->1
边界网关协议(BGP)是运行于 TCP 上的一种自治系统的路由协议。
Bgp是少有的基于TCP协议 端口使用179 基于TCP,所以BGP更新方式是单播更新
物理层:电路交换在发送数据前要建立一条端到端的路径
拓扑结构指的是()的拓扑结构。
算机网络拓扑结构是指网络中各个站点相互连接的形式,各个站点抽象来说都是网络资源。
计算机网络的最主要的拓扑结构有总线型拓扑、环型拓扑、树型拓扑、星型拓扑、混合型拓扑以及网状拓扑。
其中环形拓扑、星形拓扑、总线拓扑是三个最基本的拓扑结构。
在局域网中,使用最多的是星型结构。
D.https协议下cookie是明文传递的 https协议下传输的内容都是加密后的,包括cookie也是,
故D错误
网关工作在 OSI 模型的( )
网间连接器或协议转换器,是一系列组网设备的组合(非单一设备),泛指所有网络互联设备,一般用于广域网和局域网相连的场合。
以下所列设备都可以充当:
路由器:数据转发
防火墙:安全验证
网络服务:VPN服务 其工作通常出现在最高层(应用层),但也有可能是网络层服务。
一般在OSI体系中指传输层以上的协议转换器;TCP/IP体系中指网络层中继设备(路由器)。根据题目OSI模型,所以选D。
过分了
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。

![[Jule CTF 2022] 部分WP](https://img-blog.csdnimg.cn/186abb23f3e348ad8258d965fc97d9bf.png)



![[~/vulhub]/log4j/CVE-2021-44228-20221225](https://img-blog.csdnimg.cn/img_convert/863dd7e2db55cb643e1283a5a8350ec6.png)