以下代码是一个基于K-means聚类算法进行图像分割的实现。通过读取一个彩色图像,将其转化为二维数组形式。然后使用K-means算法对像素点进行聚类,聚类个数为7。根据聚类后的标签值对像素点进行着色,并创建掩膜图像。接着使用形态学开运算和闭运算去掉周围的绿色点和填充区域内部空隙,找到最大的轮廓并计算其面积。最后再将最大轮廓绘制在原始图像上并显示出来。
import cv2
import numpy as np
# 读取彩色图像
img = cv2.imread(r'C:\Users\Pictures\rm.png')
# 将图像数据转换为二维数组形式
values = img.reshape((-1, 3))
values = np.float32(values)
# K-Means聚类
K = 7
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret, label, center = cv2.kmeans(values, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# 创建新图像并根据聚类标签对像素点着色
segmented_img = np.zeros_like(values)
# segmented_img[np.where(label==0)[0], :] = [255, 0, 0] # 给第0类像素点赋值蓝色
segmented_img[np.where(label==1)[0], :] = [0, 255, 0] # 给第1类像素点赋值绿色
# segmented_img[np.where(label==2)[0], :] = [0, 0, 255] # 给第2类像素点赋值红色
# segmented_img[np.where(label==3)[0], :] = [0, 0, 0] # 给第3类像素点赋值黑色
# segmented_img[np.where(label==4)[0], :] = [255, 255, 255] # 给第3类像素点赋值白色
# 将分割后图像重新转化成与原图像相同的维度
segmented_img = segmented_img.reshape(img.shape)
# 创建掩膜图像
mask = np.zeros(segmented_img.shape[:2], dtype=np.uint8)
mask[np.where(np.all(segmented_img == [0, 255, 0], axis=-1))] = 255
# 进行形态学开运算,去掉周围的绿色点
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
# 进行形态学闭运算,填充区域内部空隙
closing = cv2.morphologyEx(opening, cv2.MORPH_CLOSE, kernel)
# 找到轮廓并获取最大轮廓及其面积
contours, _ = cv2.findContours(closing, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# max_contour = max(contours, key=cv2.contourArea)
total_area = 0
for i, contour in enumerate(contours):
# 计算轮廓面积
area = cv2.contourArea(contour)
total_area += area
# 绘制最大轮廓并显示在原图上
output = img.copy()
cv2.drawContours(output, contours, -1, (0, 255, 0), 2)
cv2.imshow('Contour', output)
# 显示聚类结果
cv2.imshow('Image', img)
cv2.imshow('Segmented Image', segmented_img)
cv2.imshow('Mask', closing)
# 等待关闭窗口
cv2.waitKey(0)
cv2.destroyAllWindows()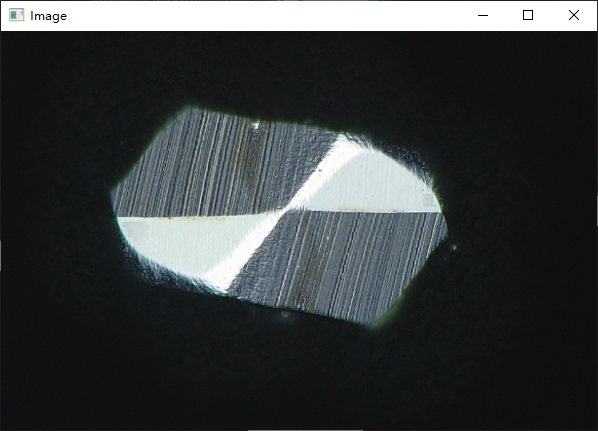
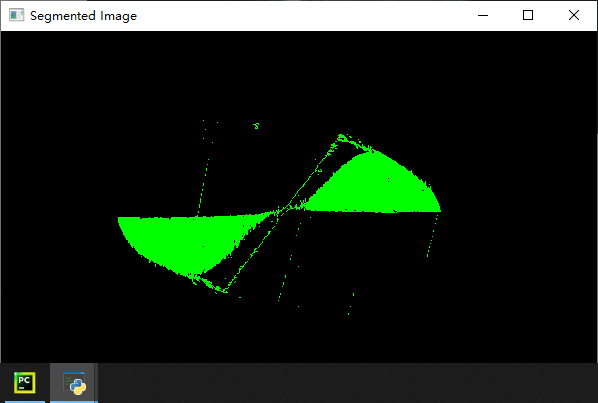

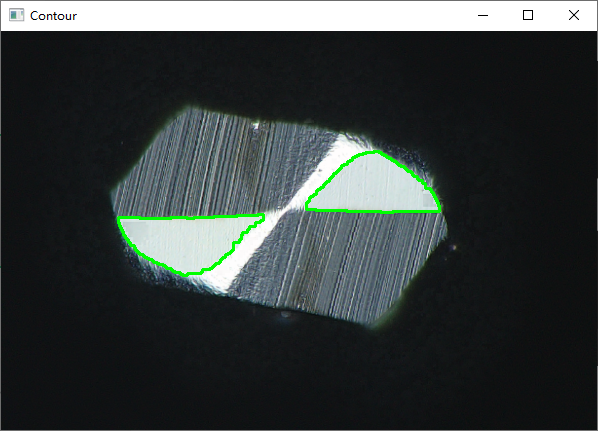
几个问题,供读者思考:
-
为什么选择K-means聚类算法?
-
为什么是聚7类?
-
这种方法具有通用性吗,换其他类似图片也提取准确吗?
-
还有更好的方法吗,如果目标的轮廓更加复杂,该怎么处理?
-
已经算出了图上面积,怎么计算实际面积?





![[红蓝攻防]MDOG(全新UI重制版)为Xss跨站而生,数据共享,表单劫持,URL重定向](https://img-blog.csdnimg.cn/img_convert/45cc431e7fe803aa19a203a4ac5bf7fb.jpeg)