GC(Garbage Collector)垃圾回收机制及调优
简单理解GC机制
其实gc机制特别容易理解,就是物理内存的自动清理工。我们可以把内存想象成一个房间,程序运行时会在这个房间里存放各种东西,但有时候我们会忘记把不再需要的东西拿出去,这就会导致房间变得杂乱不堪。甚至会出现房间的空间不够用的情况,对应到计算机,就是OOM(out of memory, 内存再多用一点,就会爆炸)。
Go语言的GC机制会定期巡视这个房间,找出那些被遗忘的东西,并将它们清理出去,释放内存。这样,程序就能继续运行,不会因为内存不足而崩溃。
那么我们为什么要看gc机制呢,让gc自己在后台运行不好吗?其实看gc机制的主要目的就是为了内存或CPU占用率的优化,体现在两点:
- 我需要知道房间里哪些东西最占地方,看看是不能能在代码上有所优化
- 我要想要更加频繁的清理房间(减小内存占用)或更少频次的清理房间(减少CPU开销)
GC机制的原理
当然如果不想知道原理的话,直接转到第三节就好。(咳咳,其实我对细节也不是那么清楚,知道怎么用的感觉已经很不容易了>.<)
什么时候需要用到GC
其实并不是所有内存都需要GC来清理的,比如说有固定作用域的指针、地址等就无需gc,等这些对象的生命周期结束后,数据自动就会被销毁。换句人话说就是,在栈上开辟的空间会随自动释放,在堆上开辟的空间就需要gc机制来释放。如果学过C或C++就会很好理解,用make、new等操作创建的对象,都需要手动free掉,这些就是堆上开辟的内存空间。在Go语言中,就不用手动free了,这就是gc机制的作用,定期free这些手动创建(堆上)的动态内存分配的对象。
当然,专业点的话,gc是一个专门识别和清理动态内存分配的系统。如果分不清的话,可以看这个例子:
package main
import "fmt"
// 一个简单的结构体类型
type Person struct {
Name string
Age int
}
func main() {
// 栈上的对象分配
// 创建一个名为 "Alice" 年龄为 25 的 Person 对象,分配在栈上
alice := Person{Name: "Alice", Age: 25}
// 动态内存分配
// 创建一个名为 "Bob" 年龄为 30 的 Person 对象,使用 new 函数分配在堆上
bob := new(Person)
bob.Name = "Bob"
bob.Age = 30
// 输出栈上和堆上对象的信息
fmt.Printf("Stack Object: Name: %s, Age: %d\n", alice.Name, alice.Age)
fmt.Printf("Heap Object: Name: %s, Age: %d\n", bob.Name, bob.Age)
}
在程序运行结束后,alice会因为生命周期结束自动free掉。但是bob仍然在堆上,等待gc机制的回收。
对于Go语言的堆栈可以仿照C++做一个简单的理解。实际上go语言的堆栈上的内存处理,确实要比上述代码中描述的要复杂很多。go语言的逃逸分析,就是专门负责堆栈上内存空间开辟的。有兴趣的话,可以右转google一下。
回收内存的方法
gc机制通过标记-清除的方式回收内存。很好理解,我想要free这块内存,起码需要知道这块内存是不是没有用了。这就是标记的作用,被标记的,就是正在使用的(in-use),未被标记的都是要被free的。(gc标记了一块地点)
这个逻辑是不是很顺,但有一个问题,为什么不把标记清除放在一起呢,我既然找到了需要free的内存,为什么不直接清除掉,还要分两个环节来做呢?因为标记需要进行全局扫描,当gc扫描到一个内存,没有被使用时,但是此时很有可能存在一个未被扫描到的指针指向了内存,如果直接free掉就会造成“悬空指针”,影响后续运行,所以必须分为两个阶段,先全局扫描,进行标记,然后陆续进行“清除”
稍微细扣一下:
标记阶段
如何确定一个内存已经没有被使用呢?gc好像有不同的方法,举个例子:引用计数(仿佛又回到了当年被八股的日子)。十分的简单,有指针指向,引用计数就加一,如果扫描到引用计数为0,房子就要没咯。这里边也涉及到一些比较专业点尔的词汇,对象、指针、对象图。对象图是由对象和指向其他对象的指针一起构成的。遍历对象图的过程称为扫描。
为了识别实时内存,GC 从程序的根部开始遍历对象图,这些指针标识程序确实正在使用的对象。当然,也不是时时刻刻都要扫描的,毕竟它也不想996。这个就涉及到频率了,后面会讲到。
还有一个很好玩的概念,因为要对“对象图”进行扫描、标记,gc会给它赋一个值,叫做活动值。trace完成后,GC 就会遍历堆中的所有内存,并使所有未标记为可供分配的内存。 这个过程称为扫掠(sweeping)(文明六直呼内行,从水下的从水下第一个生命的萌芽开始…)。
清除阶段
然后就需要扫掠了,逐个free掉,这个阶段没啥好说的,之所以单独拎出来,主要是为了标题的对称…
当然,说的有些简单了,大体上分为这两个阶段。如果细分的话,还可以分:SweepTermination、Mark、MarkTermination,还有一些标记算法比如三色标记法等等,感兴趣的可以自行查一查~
gc调优的原理和开销
GOGC 决定了 GC CPU 和内存之间的权衡。所谓的优化,也不过是在内存和CPU开销之间反复横跳,看更需要哪种资源了。gc的一些官方文档上提到:“GOGC 加倍会使堆内存开销加倍,并使 GC CPU 成本减半”。现在用数学公式来看一下二者的tradeoff
内存开销
首先,堆目标设置总堆大小的目标。超过堆目标或目标的百分比,就要执行gc了。这就是确定gc执行的时间的方案。堆目标就两部分构成:新开辟的内存和正在使用的内存(活动堆)。
# 这个是gc计算目标堆内存大小的公式,不用太纠结它的物理含义,超过这个值就需要进行gc了
Target heap memory = Live heap + (Live heap + GC roots) * GOGC / 100
Total heap memory = Live heap + New heap memory
# 前两者推出:
New heap memory = (Live heap + GC roots) * GOGC / 100
-
Target heap memory(目标堆内存):这是垃圾回收器的目标,它表示希望控制整个堆的大小。这个值由Go运行时系统设置,并可以通过环境变量 GOGC 来调整。它主要影响新分配的堆内存的大小,而不是已经存在的堆内存。
-
Live heap(活动堆内存):这是当前正在使用的堆内存的大小。这包括程序中正在使用的对象和数据结构。
-
GC roots(垃圾回收根节点):这表示垃圾回收器需要考虑的根节点的数量。根节点是程序中的全局变量、栈上的对象等。它们是指向堆内存的引用,这是刚才提到的对象图的根结点。
-
GOGC(Go语言的垃圾回收阈值):GOGC 是一个环境变量,表示垃圾回收器的触发阈值。当已分配的内存达到 Target heap memory 的一定百分比时,垃圾回收将被触发,默认值是100。也就是100%、
可能公式有一些绕,大概意思就是,我规定了一个目标堆内存大小的计算公式,然后,推出了新开辟的堆内存大小,只要新开辟的堆内存大小达到了New heap memory,就执行一次gc。这个新开辟的内存大小是受gc调控的。
CPU开销
来个简化版公式:
Total GC CPU cost = (Allocation rate) / (GOGC / 100) * (Cost per byte) * T
详细公式可以看:A Guide to the Go Garbage Collector
从这个简化版公式可以看出,cpu的开销适合GOGC的大小成反比的
CPU vs 内存图例
依然是上面的网站,有一个好玩的例子,应用程序总共分配 200 MiB,每次 1s分配20 MiB。它假设唯一要完成的相关 GC 工作来自活动堆,并且(不切实际地)应用程序不使用额外的内存。
- GC=100(默认情况)时
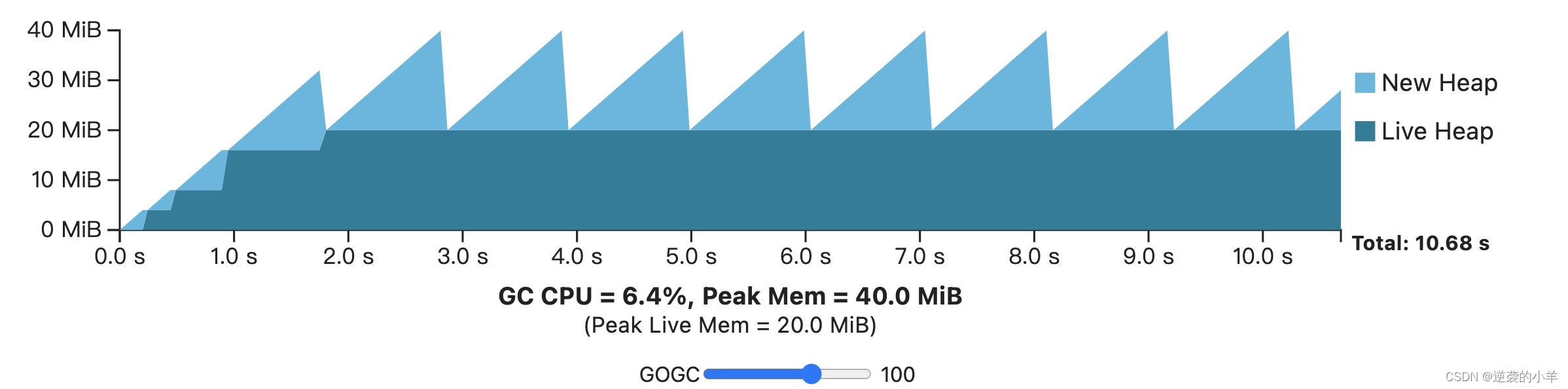
- GC=50时

- GC=-1(关闭gc)时

GC调优
同第一节所说,我们的目的有两个:
- 需要知道什么东西最占内存
- 修改gc机制的频次或阈值
查看内存,手动调优
举个例子,代码来自:go pprof
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"sync"
"time"
)
func main() {
// we need a webserver to get the pprof webserver
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
fmt.Println("hello world")
var wg sync.WaitGroup
wg.Add(1)
go leakyFunction(wg)
wg.Wait()
}
func leakyFunction(wg sync.WaitGroup) {
defer wg.Done()
s := make([]string, 3)
for i := 0; i < 10000000; i++ {
s = append(s, "magical pandas")
if (i % 100000) == 0 {
time.Sleep(500 * time.Millisecond)
}
}
}
leakyFunction基本上,这只是启动一个分配一堆内存的goroutine ,然后最终退出。在程序运行期间,通过以下命令查看内存的分配情况:
go tool pprof http://localhost:6060/debug/pprof/heap
然后使用top查看内存用量的前几名,如下
# go tool pprof http://localhost:6060/debug/pprof/heap
Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap
Saved profile in /Users/yang/pprof/pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz
Type: inuse_space
Time: Oct 28, 2023 at 11:31pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 11715.14kB, 100% of 11715.14kB total
Showing top 10 nodes out of 24
flat flat% sum% cum cum%
7104.01kB 60.64% 60.64% 7104.01kB 60.64% main.leakyFunction
2562.81kB 21.88% 82.52% 2562.81kB 21.88% runtime.allocm
1024.01kB 8.74% 91.26% 1024.01kB 8.74% runtime.doaddtimer
512.20kB 4.37% 95.63% 512.20kB 4.37% runtime.malg
512.11kB 4.37% 100% 512.11kB 4.37% net/http.ListenAndServe (inline)
0 0% 100% 512.11kB 4.37% main.main.func1
0 0% 100% 1024.01kB 8.74% runtime.bgscavenge
0 0% 100% 1025.12kB 8.75% runtime.mcall
0 0% 100% 1024.01kB 8.74% runtime.modtimer
0 0% 100% 1537.69kB 13.13% runtime.mstart
(pprof)
当然也可以用图片:比如这样:不过需要Graphviz包,没有的话会报错,安装也很简单
apt install graphviz ## debian/ubuntu
brew install graphviz ## mac
## 然后
go tool pprof -png http://localhost:6060/debug/pprof/heap > out.png
然后就可以看到内存的分布图了

这样你就可以清晰的看到内存使用最多的函数,leakyFunction。线越粗,代表内存用量越大,不过需要注意的是,这里的信息只是你执行代码时采的点,没有办法实时反应内存用量。
找到内存耗量最大的部分,然后就可以手动对代码的做一些修改。这就极大的考验代码能力了。如果不想整,可以移步下一小节,修改gc参数,自动搞定~
当然除了看内存,还可以看cpu开销等等(这些命令我忘记从哪里粘的了,侵删),虽然官网上也有: https://pkg.go.dev/net/http/pprof。(但实在是懒,就直接粘过来了)
#所有过去内存分配的采样
go tool pprof http://127.0.0.1:6060/debug/pprof/allocs
#对活动对象的内存分配进行采样
go tool pprof http://127.0.0.1:6060/debug/pprof/heap
# 下载 cpu profile,默认从当前开始收集 30s 的 cpu 使用情况,需要等待 30s
go tool pprof http://127.0.0.1:6060/debug/pprof/profile
# wait 120s
go tool pprof http://127.0.0.1:6060/debug/pprof/profile?seconds=120
#导致同步原语阻塞的堆栈跟踪
go tool pprof http://127.0.0.1:8080/debug/pprof/block
#所有当前goroutine的堆栈跟踪
go tool pprof http://127.0.0.1:8080/debug/pprof/goroutine
#争用互斥锁持有者的堆栈跟踪
go tool pprof http://127.0.0.1:8080/debug/pprof/mutex
#当前程序的执行轨迹。
go tool pprof http://127.0.0.1:8080/debug/pprof/trace
当然本地开发的话这些都是有http窗口的,但貌似对linux上开发帮助不大。感兴趣大家可以右拐google一下,有很多帖子都是。
修改gc参数,自动调优
gc值暴露了一个接口,让我们修改gc的值,那就是:debug.SetGCPercent(),需要import runtime/debug。
ps:gc真好哇!知道我乱七八槽的不会用,只给了我一个接口。
比如:
package main
import (
"runtime/debug"
)
func main() {
debug.SetGCPercent(30)
//......
}
还是上面的代码,将gc改成30后,我查看了前六次gc的日志和gc为默认值100情况下:
# gc为30
# GODEBUG=gctrace=1 go run pprof.go
gc 1 @0.505s 0%: 0.053+2.3+1.1 ms clock, 0.64+0/0.94/1.2+14 ms cpu, 3->4->2 MB, 4 MB goal, 12 P
gc 2 @0.509s 0%: 0.034+3.6+0.002 ms clock, 0.41+0/1.3/2.7+0.033 ms cpu, 4->4->2 MB, 5 MB goal, 12 P
gc 3 @0.513s 0%: 0.031+5.0+0.002 ms clock, 0.37+0.95/0.63/3.9+0.028 ms cpu, 3->3->2 MB, 4 MB goal, 12 P
gc 4 @0.519s 0%: 0.057+3.2+0.002 ms clock, 0.68+0/4.1/0.72+0.027 ms cpu, 4->4->3 MB, 5 MB goal, 12 P
gc 5 @1.024s 0%: 0.060+6.0+0.003 ms clock, 0.72+0/3.3/4.6+0.041 ms cpu, 5->5->4 MB, 6 MB goal, 12 P
gc 6 @1.031s 0%: 0.029+11+0.074 ms clock, 0.35+0.87/6.6/0.42+0.88 ms cpu, 7->10->10 MB, 8 MB goal, 12 P
# gc为100
# GODEBUG=gctrace=1 go run pprof.go
gc 1 @0.505s 0%: 0.062+2.4+0.002 ms clock, 0.74+0/1.1/1.6+0.033 ms cpu, 4->4->1 MB, 5 MB goal, 12 P
gc 2 @0.510s 0%: 0.027+6.0+0.002 ms clock, 0.33+0.18/3.9/0.55+0.032 ms cpu, 5->6->4 MB, 6 MB goal, 12 P
gc 3 @1.018s 0%: 0.12+11+0.002 ms clock, 1.5+0/11/0.29+0.030 ms cpu, 9->9->7 MB, 10 MB goal, 12 P
gc 4 @1.534s 0%: 0.044+12+0.002 ms clock, 0.53+0/13/2.4+0.030 ms cpu, 15->15->8 MB, 16 MB goal, 12 P
gc 5 @2.050s 0%: 0.046+16+0.002 ms clock, 0.55+0/3.6/13+0.032 ms cpu, 20->20->7 MB, 21 MB goal, 12 P
gc 6 @2.567s 0%: 0.075+16+0.002 ms clock, 0.90+0/6.2/15+0.034 ms cpu, 15->15->15 MB, 16 MB goal, 12 P
如何查看分析日志呢,见下一小节。
其实可以明显的看出来,gc为30时,目标堆大小,明显要比gc为100的时候要小得多。这样我们就省下来很多的内存,可以存一些自己想要的学习资料(好好好,拿内存当存储是吧…)
查看gc日志
查看gc日志信息(参考自:GODEBUG-GC):
# GODEBUG=gctrace=1 go run debug.go
gc 1 @0.049s 0%: 0.016+0.26+0.015 ms clock, 0.19+0.13/0.33/0.18+0.19 ms cpu, 4->4->0 MB, 5 MB goal, 12 P
gc 2 @0.816s 0%: 0.11+0.39+0.003 ms clock, 1.3+0.19/0.65/0.62+0.037 ms cpu, 4->4->0 MB, 5 MB goal, 12 P
gc 3 @0.824s 0%: 0.15+0.33+0.002 ms clock, 1.8+0/0.39/0.51+0.024 ms cpu, 4->4->0 MB, 5 MB goal, 12 P
含义如下:
- gc#:GC 执行次数的编号,每次叠加。
- @#s:自程序启动后到当前的具体秒数。
- #%:自程序启动以来在 GC 中花费的时间百分比。
- #+…+#:GC 的标记工作共使用的 CPU 时间占总 CPU 时间的百分比。
- #->#-># MB:分别表示 GC 启动时, GC 结束时, GC 活动时的堆大小.
- #MB goal:下一次触发 GC 的内存占用阈值。
- #P:当前使用的处理器 P 的数量
debug的其他api
有点跑题了,不过确实很有用,关于gc参数调整,goland只提供了一个接口,但是对于debug中还有其他的一些api也很有用比如说
// 强制gc 将尽可能多的内存返回给操作系统
func FreeOSMemory()
// 设置最大堆大小
func SetMaxStack(bytes int) int
// 设置最大线程数
func SetMaxThreads(threads int) int
和SetGCPercent的使用方法一样,更多api详见:https://pkg.go.dev/runtime/debug#FreeOSMemory
参考
A Guide to the Go Garbage Collector
gc问题集
debug.api
GODEBUG-GC
go pprof
ChatGPT[doge]