1. 预测波士顿房价
1.1 导包
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import itertools
import pandas as pd
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.INFO)最后一行设置了TensorFlow日志的详细程度:
tf.logging.DEBUG:最详细的日志级别,用于记录调试信息。
tf.logging.INFO:用于记录一般的信息性消息,比如训练过程中的指标和进度。
tf.logging.WARN:用于记录警告消息,表示可能存在潜在问题,但不会导致程序终止。
tf.logging.ERROR:仅记录错误消息,表示程序遇到了错误并可能终止执行。
tf.logging.FATAL:记录严重错误消息,并终止程序的执行。
1.2 处理数据集
COLUMNS = ["crim", "zn", "indus", "nox", "rm", "age",
"dis", "tax", "ptratio", "medv"]
FEATURES = ["crim", "zn", "indus", "nox", "rm",
"age", "dis", "tax", "ptratio"]
LABEL = "medv"
training_set = pd.read_csv("boston_train.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
test_set = pd.read_csv("boston_test.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)
prediction_set = pd.read_csv("boston_predict.csv", skipinitialspace=True,
skiprows=1, names=COLUMNS)定义了一些列名和特征,并使用pd.read_csv函数读取了训练集、测试集和预测集的数据。
pd.read_csv函数来读取CSV文件,并将其转换为Pandas数据帧。

1.3 创建DNNRegressor对象
feature_cols = [tf.feature_column.numeric_column(k) for k in FEATURES]
regressor = tf.estimator.DNNRegressor(feature_columns=feature_cols,
hidden_units=[50,50,50],
model_dir="./boston_model")tf.feature_column.numeric_column函数用于创建一个表示数值特征的特征列。在这种情况下,它
会遍历FEATURES列表中的每个特征名称,并为每个特征创建一个数值特征列。
创建DNNRegressor对象的参数:
feature_columns:这是包含特征列的列表,用于定义输入的特征。在这里,您传递了之前创建
的feature_cols,它包含了用于模型训练的数值特征列。
hidden_units:这是一个整数列表,用于定义隐藏层的结构。在这个例子中,您定义了一个具
有3个隐藏层的DNN模型,每个隐藏层都有50个神经元。
model_dir:这是模型保存的目录路径。在这里,您指定了"./boston_model"作为模型保存的目录。

1.4 创建输入函数
def get_input_fn(data_set, num_epochs=None, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
num_epochs=num_epochs,
shuffle=shuffle)该输入函数将Pandas数据帧作为输入,并将其转换为TensorFlow的输入格式。具体而言,它将特
征数据集(由FEATURES列表指定的列)转换为x,将标签数据(由LABEL指定的列)转换为y。
1.5 训练评估预测
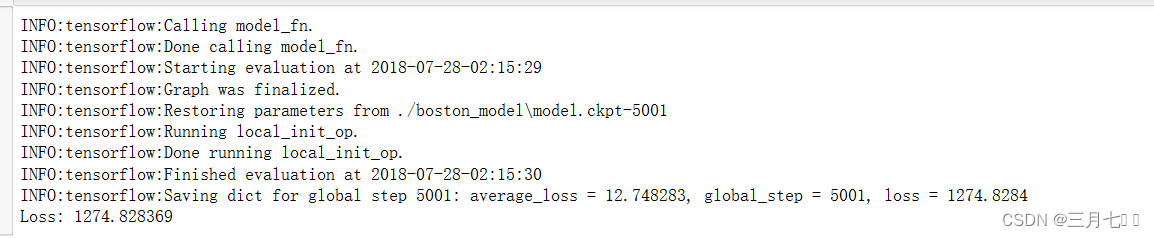
regressor.train(input_fn=get_input_fn(training_set), steps=5000)
ev = regressor.evaluate(
input_fn=get_input_fn(test_set, num_epochs=1, shuffle=False))
loss_score = ev["loss"]
print("Loss: {0:f}".format(loss_score))
y = regressor.predict(
input_fn=get_input_fn(prediction_set, num_epochs=1, shuffle=False))
# .predict() returns an iterator of dicts; convert to a list and print
# predictions
predictions = list(p["predictions"] for p in itertools.islice(y, 6))
print("Predictions: {}".format(str(predictions)))steps参数指定了训练的迭代步数,即模型将对训练数据执行多少次梯度下降更新。
使用get_input_fn获取输入函数,该函数将测试集(test_set)作为输入数据。num_epochs参数设
置为1,表示测试集只会被迭代一次,shuffle参数被设置为False,表示测试集不需要进行洗牌。
然后提取评估结果中的损失值(loss),并将其赋值给loss_score变量。
通过迭代预测结果的字典形式,将预测值提取出来,并将其存储在predictions列表中。


2. 鸢尾花数据集分类
import tensorflow as tf
import pandas as pd
COLUMN_NAMES = [
'SepalLength',
'SepalWidth',
'PetalLength',
'PetalWidth',
'Species'
]
# Import training dataset
training_dataset = pd.read_csv('iris_training.csv', names=COLUMN_NAMES, header=0)
train_x = training_dataset.iloc[:, 0:4]
train_y = training_dataset.iloc[:, 4]
# Import testing dataset
test_dataset = pd.read_csv('iris_test.csv', names=COLUMN_NAMES, header=0)
test_x = test_dataset.iloc[:, 0:4]
test_y = test_dataset.iloc[:, 4]
# Setup feature columns
columns_feat = [
tf.feature_column.numeric_column(key='SepalLength'),
tf.feature_column.numeric_column(key='SepalWidth'),
tf.feature_column.numeric_column(key='PetalLength'),
tf.feature_column.numeric_column(key='PetalWidth')
]
# Build Neural Network - Classifier
classifier = tf.estimator.DNNClassifier(
feature_columns=columns_feat,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model is classifying 3 classes
n_classes=3)
# Define train function
def train_function(inputs, outputs, batch_size):
dataset = tf.data.Dataset.from_tensor_slices((dict(inputs), outputs))
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
return dataset.make_one_shot_iterator().get_next()
# Train the Model.
classifier.train(
input_fn=lambda:train_function(train_x, train_y, 100),
steps=1000)
# Define evaluation function
def evaluation_function(attributes, classes, batch_size):
attributes=dict(attributes)
if classes is None:
inputs = attributes
else:
inputs = (attributes, classes)
dataset = tf.data.Dataset.from_tensor_slices(inputs)
assert batch_size is not None, "batch_size must not be None"
dataset = dataset.batch(batch_size)
return dataset.make_one_shot_iterator().get_next()
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:evaluation_function(test_x, test_y, 100))
print('\nAccuracy: {accuracy:0.3f}\n'.format(**eval_result))首先导入所需的库,包括 TensorFlow 和 Pandas。然后,定义了一个包含特征列的列
表 columns_feat,用于描述输入数据的特征。接下来,通过 Pandas 读取训练集和测试集的数
据,并将其分为输入特征和输出类别。
然后,使用 tf.estimator.DNNClassifier 类构建了一个多层感知机神经网络分类器。该分类器具
有两个隐藏层,每个隐藏层包含10个节点,输出层用于分类3个类别的鸢尾花。
然后,定义了一个训练函数 train_function 和一个评估函数 evaluation_function,用于转换输
入数据并创建 TensorFlow 数据集。训练函数将训练数据转换为 Dataset 对象,并进行随机化、重
复和分批处理。评估函数将测试数据转换为 Dataset 对象,并进行分批处理。
最后,通过调用 classifier.train 方法来训练模型,使用训练函数作为输入函数,并指定训练步
数。然后,通过调用 classifier.evaluate 方法来评估模型的性能,使用评估函数作为输入函数,
并指定评估时的批大小。评估结果包括准确率,并通过 print 函数进行输出。






![[Leetcode] 0108. 将有序数组转换为二叉搜索树](https://img-blog.csdnimg.cn/img_convert/9c970c6c3847ede3a76b5d6faa682f47.png)