一、Apriori原理解析
1. 概述
关联规则分析是数据挖掘中最活跃的研究方法之一,目的是在一个数据集中找到各项之间的关联关系,而这种关系并没有在数据中直接体现出来。以超市的销售数据为例,当存在很多商品时,可能的商品组合数量达到了令人望而却步的程度,这是提取关联规则的最大困难。因此各种关联规则分析算法从不同方面入手减少可能的搜索空间大小以及减少扫描数据的次数。Apriori算法是最经典的挖掘频繁项集的算法,第一次实现了在大数据集上的的关联规则提取,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集。
2. 关键词
关联分析:找出物品中的潜在关系。
频繁项集:频繁一起出现的物品集的集合。
关联规则:两种物品存在的关系(先找频繁项集,再根据关联规则找关联物品)。
支持度(Support):项集A和B的支持度被定义为数据集中同时包含这两项集的记录所占的比例(通俗理解,就是事件A和B同时发生的概率)。公式为Support(A=>B)=P(A∪B)。
置信度(可信度)(Confidence):项集A发生,则项集B发生的概率为关联规则的置信度(通俗理解,在A发生的情况下B发生的概率为多少P(B/A))。公式为Confidence(A=>B)=P(B|A)。
3. Apriori算法
Apriori的作用是根据物品间的支持度找出物品中的频繁项集。通过上面我们知道,支持度越高,说明物品越受欢迎。那么支持度怎么决定呢?这个由我们主观决定,我们会给Apriori提供一个最小支持度参数,然后Apriori会返回比这个最小支持度高的那些频繁项集。
要使用Apriori算法,我们至少需要提供两个参数,数据集和最小支持度。我们从前面已经知道了Apriori会遍历所有的物品组合,遍历的方法就是使用递归。先遍历1个物品组合的情况,剔除掉支持度低于最小支持度的数据项,然后用剩下的物品进行组合。遍历2个物品组合的情况,再剔除不满足条件的组合。不断递归下去,直到不再有物品可以组合。
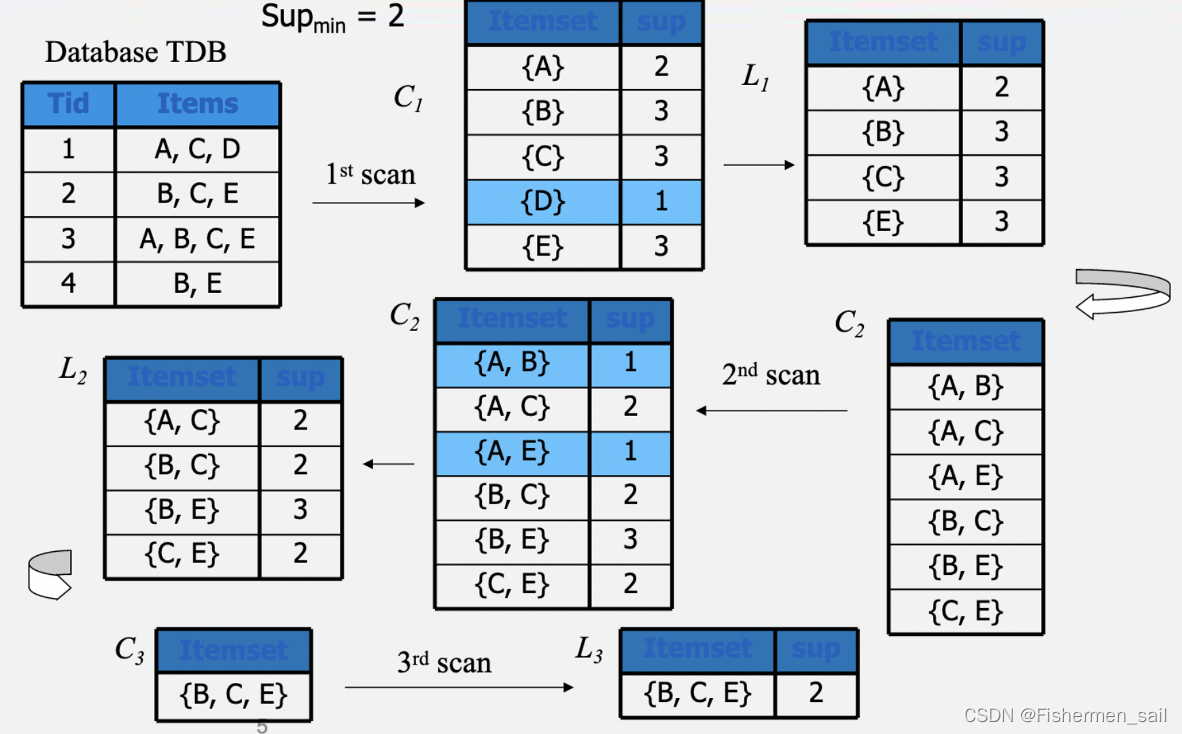
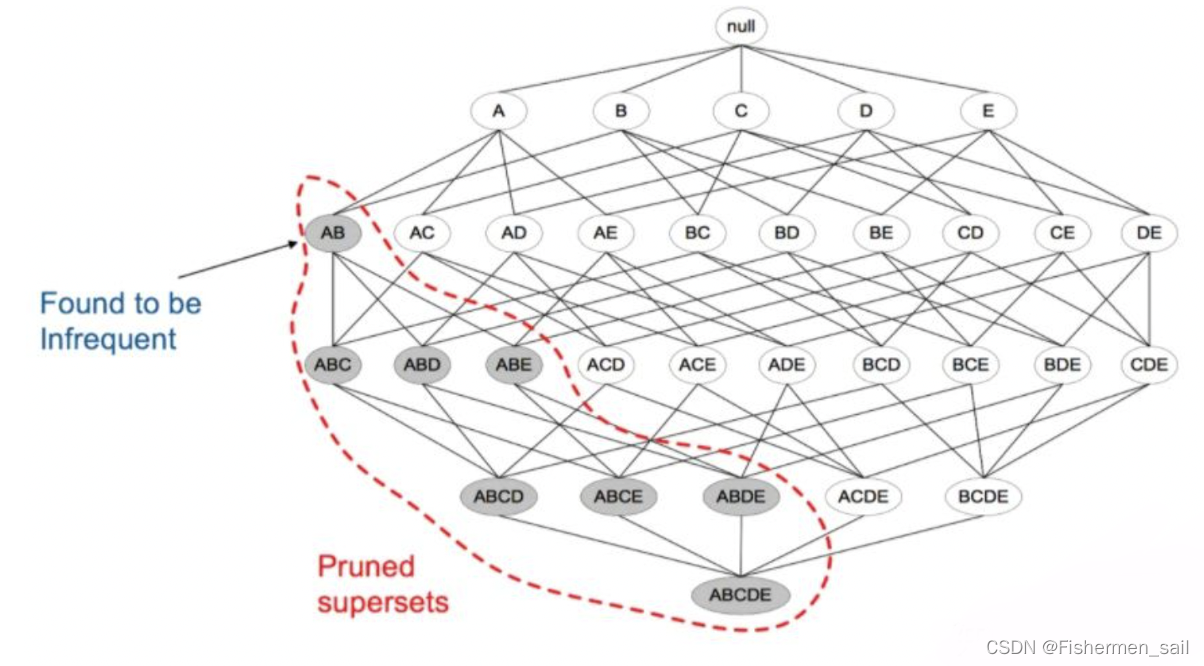
其核心是:如果一个项集是非频繁项集,那么它的所有超集也是非频繁项集。可以发现如果{A,B}这个项集是非频繁的,那么{A,B}这个项集的超集,{A,B,C},{A,B,D}等等也都是非频繁的,这些就都可以忽略不去计算,从而减轻计算,实现剪枝。
二、代码批注
1. Apriori批注
from __future__ import print_function
import pandas as pd
def connect_string(x, ms):
"""
:param x: column
:param ms: 连接符
:return: # 返回与1项频繁集连接生成新的项集
"""
# 这里的map是映射map,与series.map不一样,下面是利用series的写法
# column = pd.Series(column)
# x = list(column.map(lambda i: sorted(i.split('--'))))
x = list(map(lambda i: sorted(i.split(ms)), x))
# 获得目前的频繁集内的项数
l = len(x[0])
# 存放新生成的频繁集
r = []
# 所有的频繁集两两比较,生成新的组合(比原来多一项)
for i in range(len(x)):
for j in range(i, len(x)):
# 这里的意思就是{a,b,c} VS {a,b,d} -> {a,b,c,d}(a和b相同,c与d不同,最后向r里添加a,b与c,d)
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][l - 1]:
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
def find_rule(d, support, confidence, ms=u'--'):
"""
:param d: 数据集
:param support: 支持度
:param confidence: 置信度
:param ms: 连接符
:return: 符合支持度与置信度的关联规则集
"""
# 结果集合,最后to_excel保存
result = pd.DataFrame(index=['support', 'confidence'])
# 支持度序列:就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。
# 1项集的支持度序列(sum():进行列求值;len():数据量)
support_series = 1.0 * d.sum() / len(d) # 默认index就是column
# 初步根据支持度筛选
# 𝑆𝑢𝑝𝑝𝑜𝑟𝑡(𝑋,𝑌)=𝑃(𝑋𝑌)=𝑛𝑢𝑚𝑏𝑒𝑟(𝑋𝑌)/𝑛𝑢𝑚(𝐴𝑙𝑙𝑆𝑎𝑚𝑝𝑙𝑒𝑠)
column = list(support_series[support_series > support].index)
k = 0
while len(column) > 1:
k = k + 1
print(u'\n正在进行第%s次搜索...' % k)
# 获得新的频繁集
column = connect_string(column, ms)
2. main_apr.py
"""
使用Apriori算法挖掘菜品订单关联规则
"""
from __future__ import print_function
from apriori import * # 导入自行编写的apriori函数
from timeit import default_timer as timer
inputFile = '../data/Income.csv'
# 结果文件
outputFile = '../tmp/apriori_rules.xls'
# 读取数据
data1 = pd.read_csv(inputFile)
data2 = data1.drop('Unnamed: 0', 1) # 这个1是省略了axis,来区分行与列
# 最小支持度
support = 0.1
# 最小置信度
confidence = 0.9
# 连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
ms = '---'
# 保存结果
tic = timer()
# 保存结果
find_rule(data2, support, confidence, ms).to_excel(outputFile)
toc = timer()
# 计算耗时
print(toc - tic)
三、运行结果
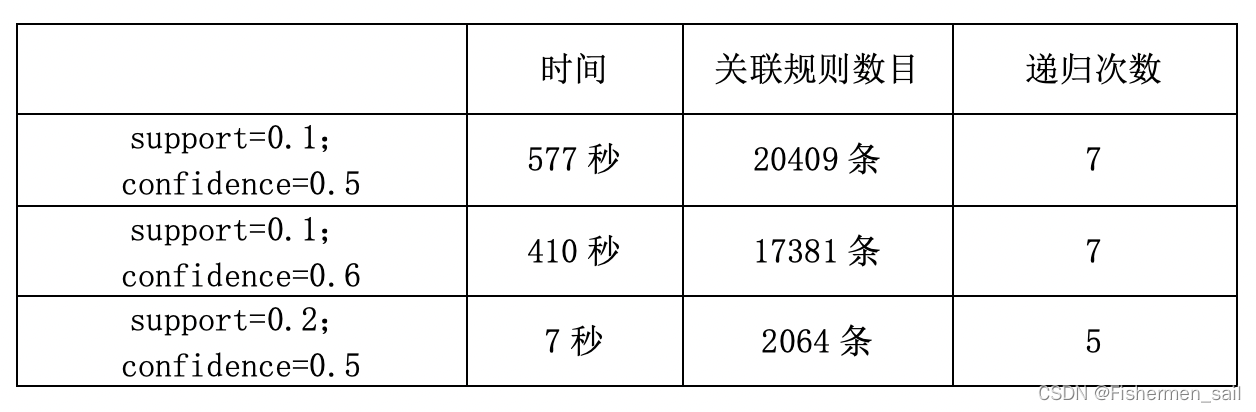
根据上述结果,可以观察到,支持度和置信度越高符合条件的频繁集会越少,所花时间、递归次数就越少;递归次数根据源码可得主要取决于支持度(代码中的support_series列表),支持度越大递归的次数也就会越少。对于该组数据,如果支持度为0.1的化符合条件的数据量太大,把置信度调整到0.9也有四千多条,感觉没有太大的意义,后期也比较难分析。所以在支持度为0.2的情况下效果更好一些。
四、优缺点
- 优点
1)Apriori算法采用逐层搜索的迭代方法,算法简单明了,没有复杂的理 论推导,也易于实现。
2)适合事务数据库的关联规则挖掘。
3)适合稀疏数据集。根据以往的研究,该算法只能适合稀疏数据集的关 联规则挖掘,也就是频繁项目集的长度稍小的数据集。 - 缺点
1)对数据库的扫描次数过多。
2)Apriori算法可能产生大量的候选项集。
3)在频繁项目集长度变大的情况下,运算时间显著增加。
4)采用唯一支持度,没有考虑各个属性重要程度的不同。
5)算法的适应面窄。