1 介绍
对于具有相同形状的张量 ypred 和 ytrue(ypred 是输入,ytrue 是目标),定义逐点KL散度为:
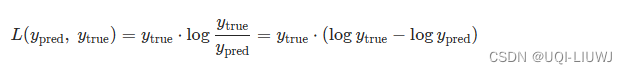
为了在计算时避免下溢问题,此KLDivLoss期望输入在对数空间中。如果log_target=True,则目标也在对数空间。

2 参数
| reduction |
reduction= “mean”不返回真正的KL散度值,reduction= “batchmean”才是 |
| log_target | 指定目标是否在对数空间中 |

3 举例
import torch
import torch.nn as nn
input = torch.tensor([[0.5, -0.5, 0.1], [0.1, -0.2, 0.3]], requires_grad=True)
target = torch.tensor([[0.7, 0.2, 0.1], [0.1, 0.5, 0.4]])
loss_function = nn.KLDivLoss(reduction='batchmean')
loss = loss_function(input, target)
print(loss)
#tensor(-1.0176, grad_fn=<DivBackward0>)等价手动形式:
target*(target.log()-input)
'''
tensor([[-0.5997, -0.2219, -0.2403],
[-0.2403, -0.2466, -0.4865]], grad_fn=<MulBackward0>)
'''
#这里的每个元素计算方式为:
'''
tensor([[-0.5997, -0.2219, -0.2403],
[-0.2403, -0.2466, -0.4865]], grad_fn=<MulBackward0>)
'''
torch.sum(target*(target.log()-input))/2
#tensor(-1.0176, grad_fn=<DivBackward0>)





 Leetcode 283.移动零和1089.复写零](https://img-blog.csdnimg.cn/img_convert/f1eaf0bc09739753935a317dfb2e5ad8.png)