标题:EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
论文:https://arxiv.org/abs/2205.14756
中文版:【读点论文】EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation将softmax注意力转变为线性注意力
一、摘要
研究背景:高分辨率密集预测使许多有吸引力的现实世界的应用,如计算摄影,自动驾驶等,然而,巨大的计算成本使得部署最先进的高分辨率密集预测模型的硬件设备上的困难。
主要工作:本文提出了一种新的多尺度线性attention的高分辨率视觉模型——EfficientViT。与之前的高分辨率密集预测模型依赖于大量的softmax关注、硬件低效的大核卷积或复杂的拓扑结构来获得良好的性能不同,多尺度线性attention只需要轻量级和硬件高效的操作就能实现全局接受场和多尺度学习(高分辨率密集预测的两个理想特征)。
研究成果:因此,在各种硬件平台(包括移动CPU、边缘GPU和云GPU)上,EfficientViT比以前的最先进型号提供了显著的性能提升。在Cityscapes(数据集)上没有性能损失的情况下,EfficientViT分别比SegFormer和SegNeXt提供了高达13.9倍和6.2倍的GPU延迟减少。对于超分辨率,EfficientViT比Restormer提供高达6.4倍的加速,同时提供0.11dB的PSNR增益。
二、主要贡献
1. 引入了一个新的多尺度线性注意力模块,用于高效的高分辨率稠密预测。它实现了全局感受野和多尺度学习,同时保持了良好的硬件效率。据我们所知,我们的工作是第一个证明线性注意力对高分辨率密集预测的有效性。
2. 我们设计了高效vit,一个新的高分辨率系列基于视觉模型,提出了多尺度线性注意模块。
3. EfficientViT在不同硬件平台(移动的CPU,边缘GPU和云GPU)上的语义分割,超分辨率,分割任何东西和ImageNet分类方面都比以前的SOTA模型有显著的加速。
三、方法论
3.1 Multi-Scale Linear Attention(多尺度线性注意力)
多尺度线性注意力仅通过硬件高效的操作同时实现了全局感受野和多尺度学习。基于多尺度线性注意力,作者提出了一种新的用于高分辨率密集预测的Vision transformer模型EfficientVit。

动机:从性能角度来看,全局感受野和多尺度学习是必不可少的。以前的 SOTA 高分辨率密集预测模型通过启用这些特征提供了较强的性能,但不能提供良好的效率。多尺度线性注意力模块通过用轻微的性能损失换取显著的效率提升来解决这个问题。
方法:使用ReLU线性注意力来实现全局感受野,而不是繁重的softmax注意力。
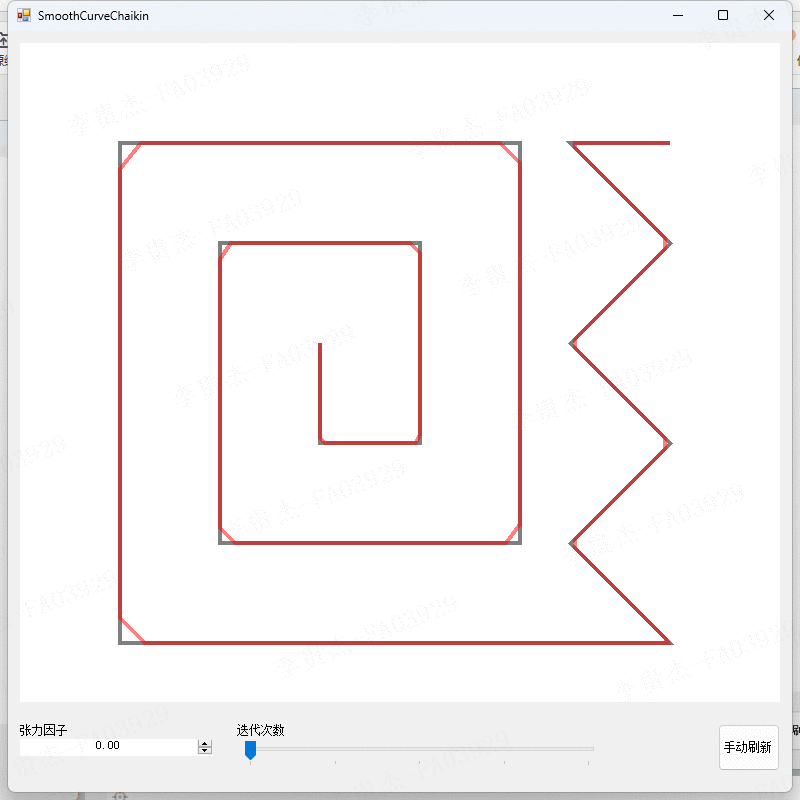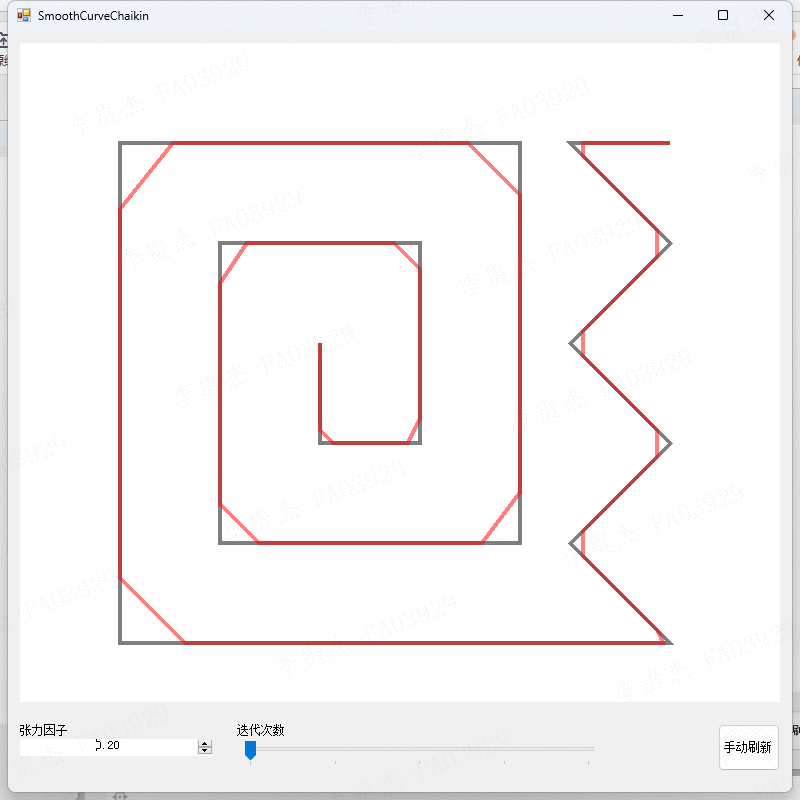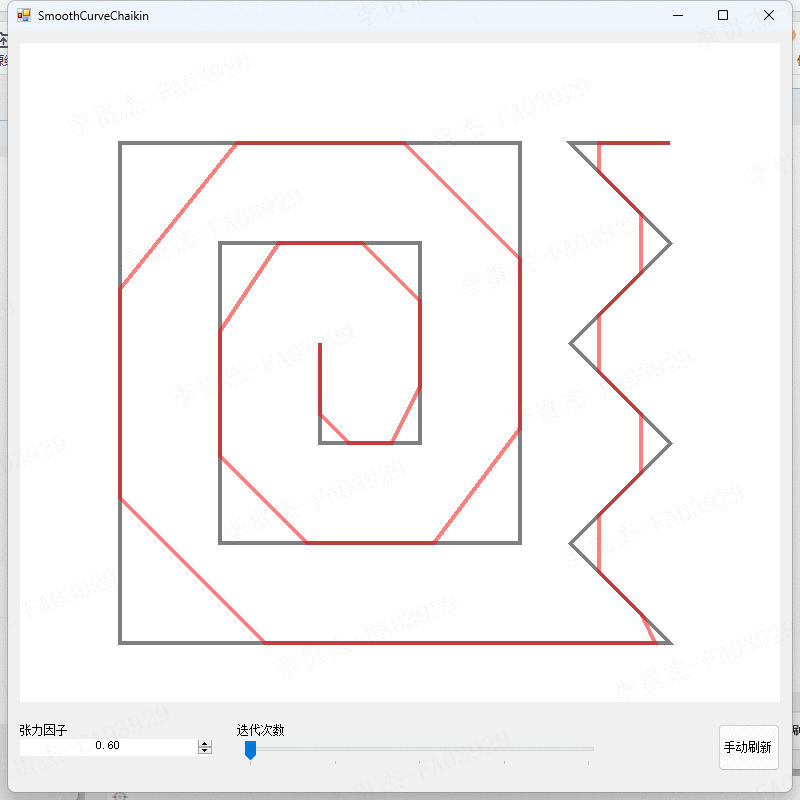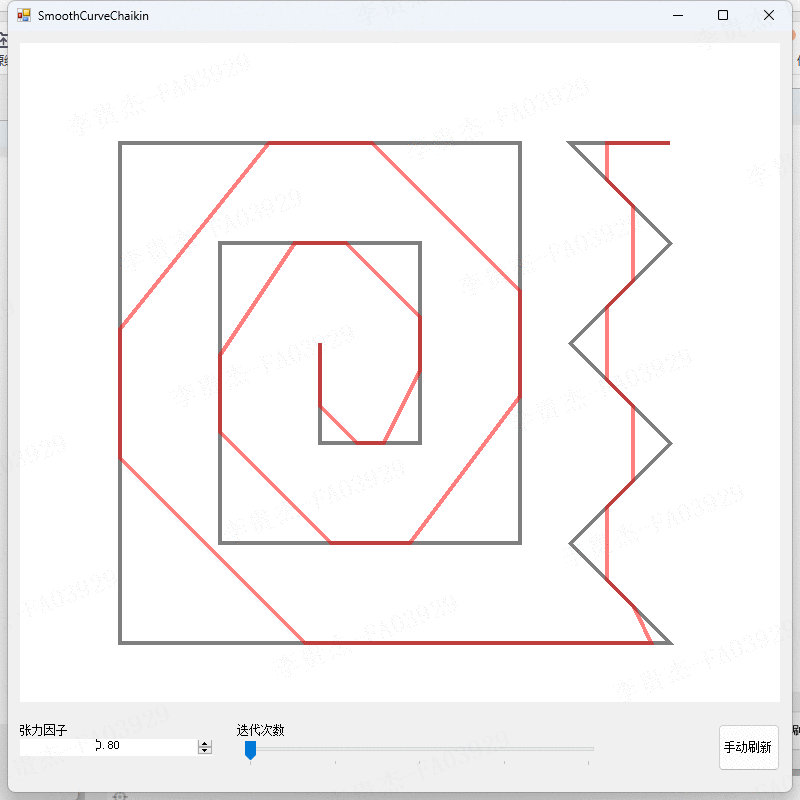
ReLU线性注意力的公式推导:
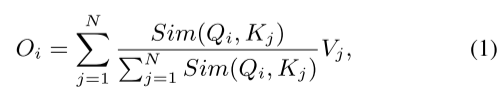
![]()
由传统的softmax注意力公式和Relu注意力相似度计算函数(相似度计算函数替换为Relu版的),可得:

由矩阵乘法的结合律,可得:

推导最终结论:由公式(3)所示,只需要计算![]() 和
和![]()
一次,就可以对每个Query重用它们(多头attention机制查询无关问题的最终解???),从而只需要O(N)的计算代价和O(N)的内存。
ReLU线性注意力的局限性:如下图所示,softmax 注意和 ReLU 线性注意的注意图。由于缺乏非线性相似函数,ReLU 线性注意不能生成集中的注意图,捕获局部信息的能力较弱。(ReLU线性注意缺点暴露)

解决方案:
1. 为了减轻其局限性,我们提出用卷积增强 ReLU 线性注意力。具体来说,在每个 FFN 层中插入深度卷积。如下图所示,其中 ReLU 线性注意力捕获上下文信息,FFN+DWConv 捕获局部信息。
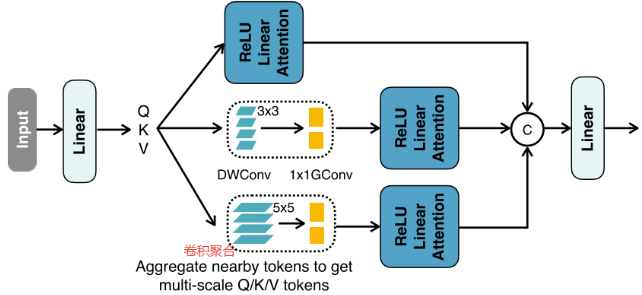
2. 将邻近的 Q/K/V token信息聚合(拼接)成多尺度token,以增强 ReLU 线性注意的多尺度学习能力(这里多尺度是指通道方向上的不同尺度,所以聚合能多尺度学习能力)。
具体来说,将所有DWConv融合成单个DWConv组,将所有 1x1 Convs合并成单个1x1的卷积组,组数为3 × #head,每组通道数为d。得到多尺度token后,对其进行ReLU线性注意力,提取多尺度全局特征。最后,将特征沿头部维度进行连接,并将其提供给最终的线性层以融合特征。
(本质上是使用nn.Conv2d()函数中的groups参数,将输入和输出通道分成几组进行卷积操作,学习通道方向上的不同尺度的信息。)
Q:感受野和注意力机制有什么关系?
A:注意力机制可以通过计算不同位置之间的关系,来捕捉长距离依赖关系,从而扩大感受野,提高网络的感知能力。
代码如下:
# 轻量权重多尺度注意力
class LiteMLA(nn.Module):
r"""Lightweight multi-scale linear attention"""
def __init__(
self,
in_channels: int,
out_channels: int,
heads: int or None = None,
heads_ratio: float = 1.0,
dim=8,
use_bias=False,
norm=(None, "bn2d"),
act_func=(None, None),
kernel_func="relu",
scales: tuple[int, ...] = (5,),
eps=1.0e-15,
):
super(LiteMLA, self).__init__()
self.eps = eps
heads = heads or int(in_channels // dim * heads_ratio)
total_dim = heads * dim
use_bias = val2tuple(use_bias, 2)
norm = val2tuple(norm, 2)
act_func = val2tuple(act_func, 2)
self.dim = dim
self.qkv = ConvLayer(
in_channels,
3 * total_dim,
1,
use_bias=use_bias[0],
norm=norm[0],
act_func=act_func[0],
)
self.aggreg = nn.ModuleList(
[
nn.Sequential(
nn.Conv2d(
3 * total_dim,
3 * total_dim,
scale,
padding=get_same_padding(scale),
groups=3 * total_dim,
bias=use_bias[0],
),
nn.Conv2d(3 * total_dim, 3 * total_dim, 1, groups=3 * heads, bias=use_bias[0]),
)
for scale in scales
]
) # nn.Conv2d()函数中的groups参数是指将输入和输出通道分成几组进行卷积操作
self.kernel_func = build_act(kernel_func, inplace=False) # Relu激活函数
self.proj = ConvLayer(
total_dim * (1 + len(scales)),
out_channels,
1,
use_bias=use_bias[1],
norm=norm[1],
act_func=act_func[1],
)
@autocast(enabled=False)
def relu_linear_att(self, qkv: torch.Tensor) -> torch.Tensor:
B, _, H, W = list(qkv.size())
if qkv.dtype == torch.float16:
qkv = qkv.float()
qkv = torch.reshape(
qkv,
(
B,
-1,
3 * self.dim,
H * W,
),
)
qkv = torch.transpose(qkv, -1, -2)
q, k, v = (
qkv[..., 0 : self.dim],
qkv[..., self.dim : 2 * self.dim],
qkv[..., 2 * self.dim :],
)
# lightweight linear attention
q = self.kernel_func(q) # 进行relu激活
k = self.kernel_func(k) # 进行relu激活
# linear matmul
trans_k = k.transpose(-1, -2)
v = F.pad(v, (0, 1), mode="constant", value=1) # 进行维度扩展
kv = torch.matmul(trans_k, v) # 按推导公式计算
out = torch.matmul(q, kv)
out = out[..., :-1] / (out[..., -1:] + self.eps)
out = torch.transpose(out, -1, -2)
out = torch.reshape(out, (B, -1, H, W))
return out
def forward(self, x: torch.Tensor) -> torch.Tensor:
# generate multi-scale q, k, v
qkv = self.qkv(x) # 获取Q、K、V,由1x1卷积得到
multi_scale_qkv = [qkv]
for op in self.aggreg: # 卷积聚合,学习通道上的多尺度信息
multi_scale_qkv.append(op(qkv))
multi_scale_qkv = torch.cat(multi_scale_qkv, dim=1) # Q、K、V拼接
out = self.relu_linear_att(multi_scale_qkv) # 重新等分划分为Q,K,V,馈入ReLU线性注意力
out = self.proj(out) # 1x1卷积输出,模拟线性层
return out
3.2 EfficientViT架构

如上图所示,
Backbone(骨干):由输入层和四个阶段组成,特征图大小逐渐减小,通道数量逐渐增加。在阶段3和4中插入EfficientViT模块。对于下采样,我们使用步幅为2的MBConv。
Head(分割头):P2、P3和P4表示阶段2、3和4的输出,形成特征图的金字塔。为了简单和高效,使用1x 1卷积和标准上采样操作(例如,双线性/双三次上采样)以匹配它们的空间和信道大小并经由加法来融合它们。简单的头部设计,其包括若干MBConv块和输出层(即,预测和上采样)。
四、实验
数据集:Cityscapes 和 ADE20K数据集。
评价指标:mIoU、Params和MAC(乘加累积操作数)。
4.1 消融研究
(1)EfficientViT模块的性能测试

mIoU和MAC在Cityscapes上测量,输入分辨率为1024x2048。重新调整模型的宽度,使它们具有相同的MAC,由上表所示,多尺度学习和全局感受野对于获得良好的语义分割性能至关重要。
(2)ImageNet上的主干性能对比
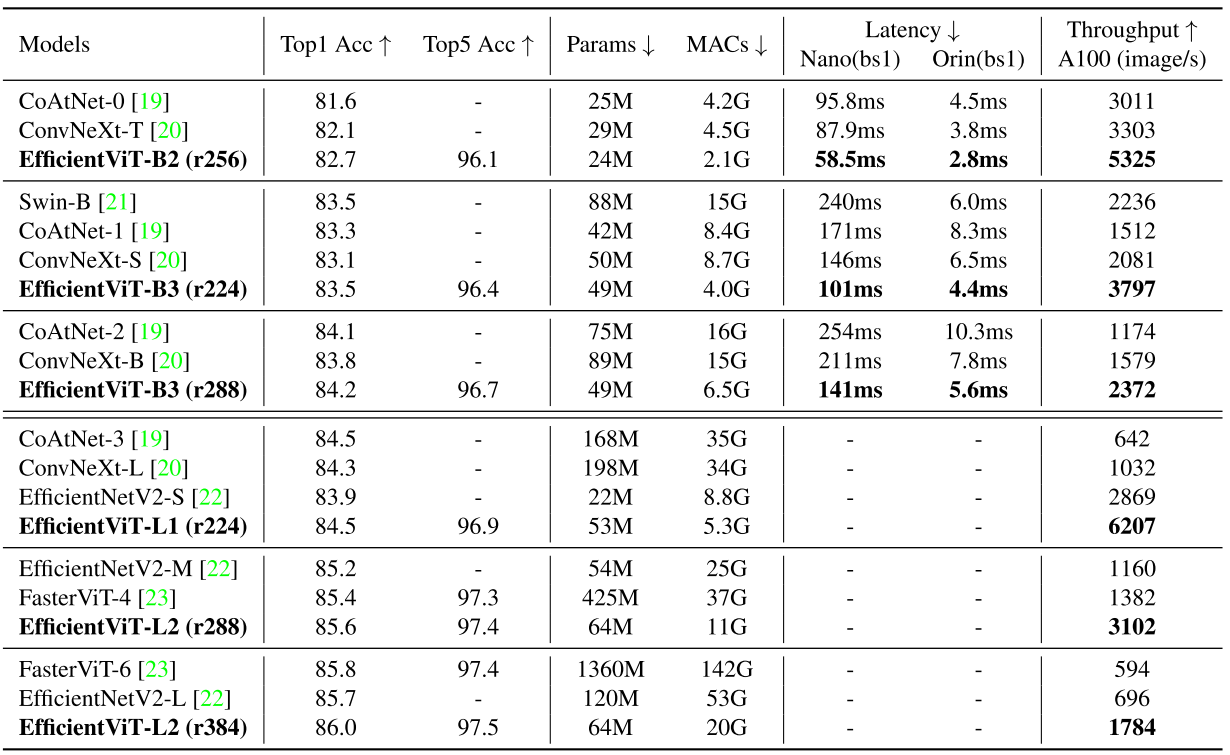
EfficientViT-L2-r384在ImageNet上获得了86.0的top-1精度,比EfficientNetV 2-L提供了+0.3的精度增益,在A100 GPU上提供了2.6倍的加速。
4.2 语义分割实验
与先进语义分割模型在Cityscapes数据集上的对比。

与SegFormer相比,EfficientViT在mIoU更高的边缘GPU(Jetson AGX Orin)上获得了高达13倍的MAC数节省和高达8.8倍的延迟减少。与SegNeXt相比,EfficientViT在边缘GPU上提供高达2.0倍的MAC减少和3.8倍的加速,同时保持更高的mIoU。
五、总结
1. 本文针对高分辨率稠密预测的有效架构设计,引入了一个轻量级的多尺度注意力模块,它同时实现了全局感受野,以及具有轻量级和硬件高效操作的多尺度学习,从而在各种硬件设备上提供了显着的加速,而不会比SOTA高分辨率密集预测模型带来性能损失。
2. 多尺度线性注意力,使用ReLU线性注意力来实现全局感受野,通过FFN+DWConv 捕获局部信息和卷积聚合捕获多尺度信息,以此克服ReLU线性注意力轻量化所带来的缺点。