文章目录
- Topic数据的存储机制
- 演示
- 基本信息
- 使用kafka-run-class.sh查看index内容
- 使用kafka-run-class.sh查看log内容
- index文件和log文件详解
- 日志存储参数配置
- 文件清理策略
- 综述
- 清理策略
- 1)delete策略
- 2)compact日志策略
- 高效读写的原因

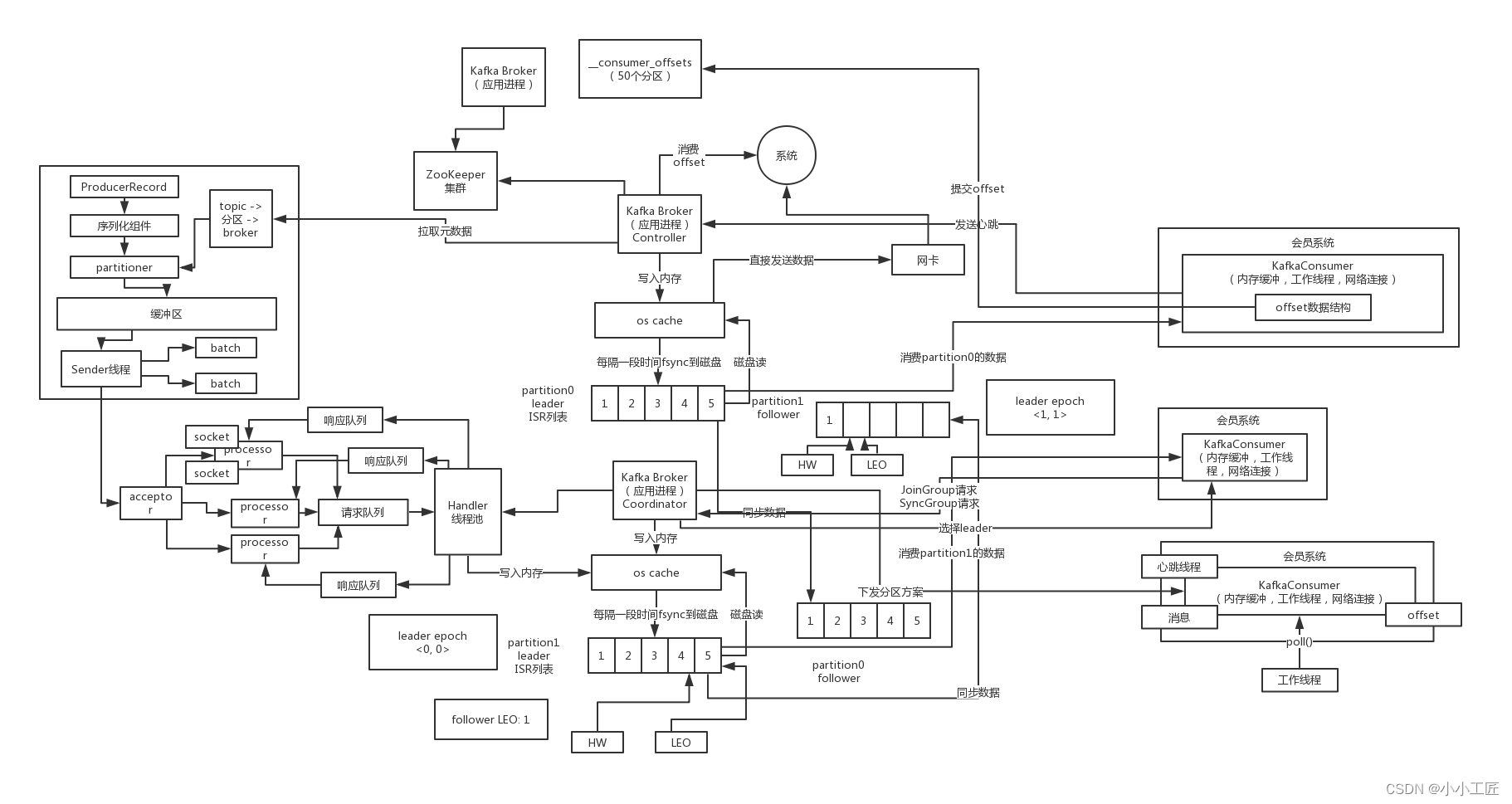
Topic数据的存储机制
Kafka是一个分布式流处理平台,它使用发布-订阅模型来处理消息流。Kafka的数据存储机制主要涉及到以下几个关键组件:Topics(主题)、Partitions(分区)和Segments(段)。
-
Topic(主题):
- Topic是Kafka中数据流的逻辑通道,用于组织和分类消息。消息发布者将消息发送到特定的主题,而消息订阅者则可以订阅感兴趣的主题以接收消息。
- 每个主题可以有零个或多个分区,这取决于配置和性能需求。
-
Partitions(分区):
- 每个主题可以被划分成一个或多个分区,分区是Kafka中的基本存储单元。
- 分区允许水平扩展,提高并行性和吞吐量。消息在分区内是有序的,但不保证全局有序。
- 每个分区在物理上保存在不同的服务器上,以支持数据的分布式存储和处理。
-
Segments(段):
- 每个分区的数据实际上被分成多个段,每个段都是一个日志文件,用于持久存储消息。
- 每个段都有一个固定的大小,一旦达到该大小,就会创建一个新的段。
- 段的持久性和不断追加新消息的特性使Kafka适合于高吞吐量的数据流处理。
Kafka的数据存储机制的关键优点包括:
- 高吞吐量:Kafka能够处理大量的消息,因为数据分布在多个分区和段中,允许并行处理。
- 数据持久性:消息在Kafka中是持久存储的,因此即使消费者没有立即处理它们,数据也不会丢失。
- 水平扩展:通过增加分区和服务器,可以轻松扩展Kafka的容量和性能。
总之,Kafka的数据存储机制通过主题、分区和段的组织,支持高吞吐量的消息流处理,使其成为一种强大的数据流平台。
演示
基本信息
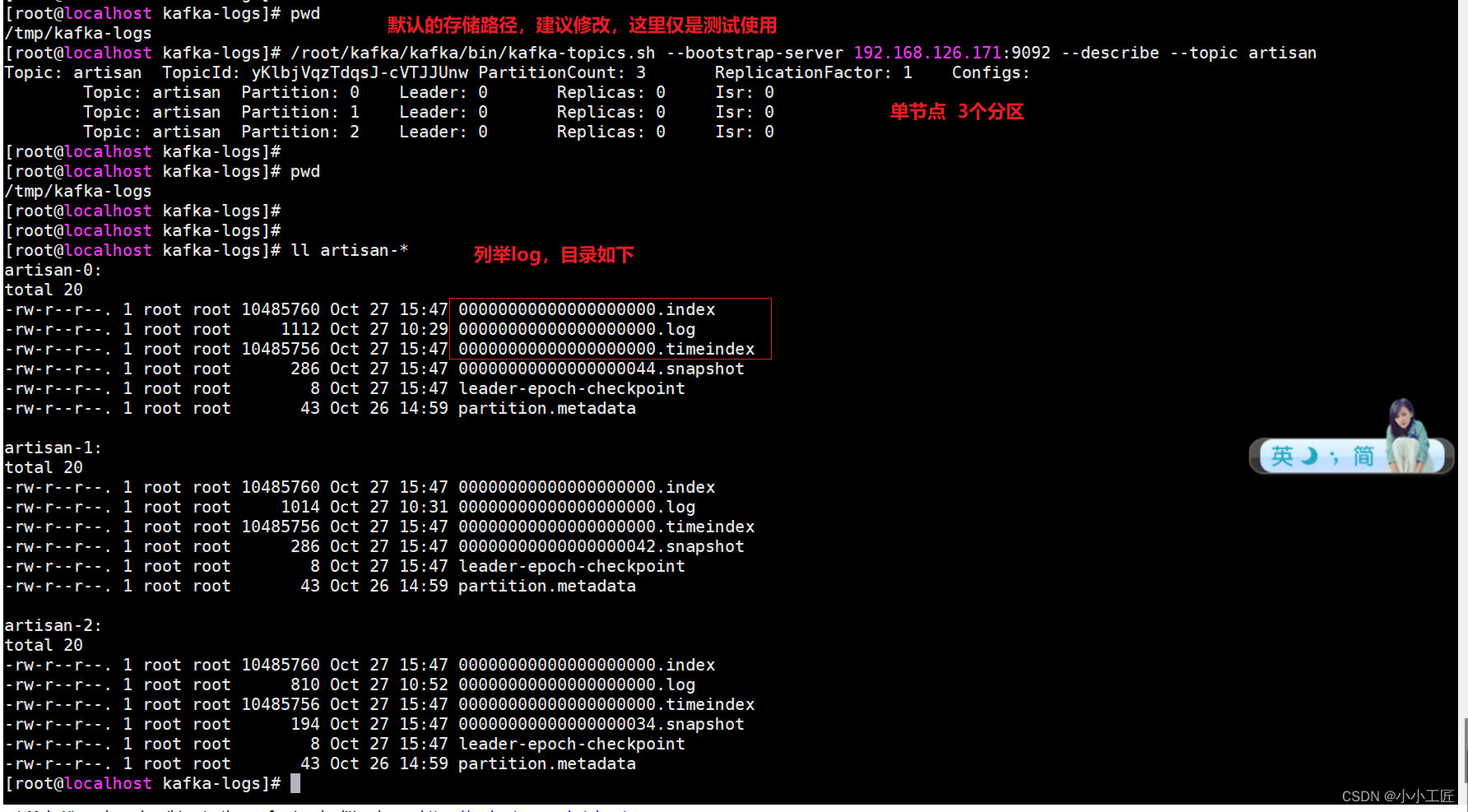
使用kafka-run-class.sh查看index内容
[root@localhost artisan-0]# /root/kafka/kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 0 position: 0
Mismatches in :/tmp/kafka-logs/artisan-0/./00000000000000000000.index
Index offset: 0, log offset: 3
使用kafka-run-class.sh查看log内容
[root@localhost artisan-0]# /root/kafka/kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
Dumping ./00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 3 count: 4 baseSequence: 0 lastSequence: 3 producerId: 2012 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1698303603739 size: 137 magic: 2 compresscodec: none crc: 3622782875 isvalid: true
baseOffset: 4 lastOffset: 13 count: 10 baseSequence: 0 lastSequence: 9 producerId: 2013 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 137 CreateTime: 1698304010395 size: 241 magic: 2 compresscodec: none crc: 1795667702 isvalid: true
baseOffset: 14 lastOffset: 23 count: 10 baseSequence: 0 lastSequence: 9 producerId: 2014 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 378 CreateTime: 1698304027258 size: 241 magic: 2 compresscodec: none crc: 2868390514 isvalid: true
baseOffset: 24 lastOffset: 28 count: 5 baseSequence: 0 lastSequence: 4 producerId: 2017 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 619 CreateTime: 1698304616155 size: 156 magic: 2 compresscodec: none crc: 1863625421 isvalid: true
baseOffset: 29 lastOffset: 33 count: 5 baseSequence: 0 lastSequence: 4 producerId: 2018 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 775 CreateTime: 1698304624578 size: 156 magic: 2 compresscodec: none crc: 739158864 isvalid: true
baseOffset: 34 lastOffset: 43 count: 10 baseSequence: 0 lastSequence: 9 producerId: 3000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 931 CreateTime: 1698373784040 size: 181 magic: 2 compresscodec: snappy crc: 3489556255 isvalid: true
[root@localhost artisan-0]#
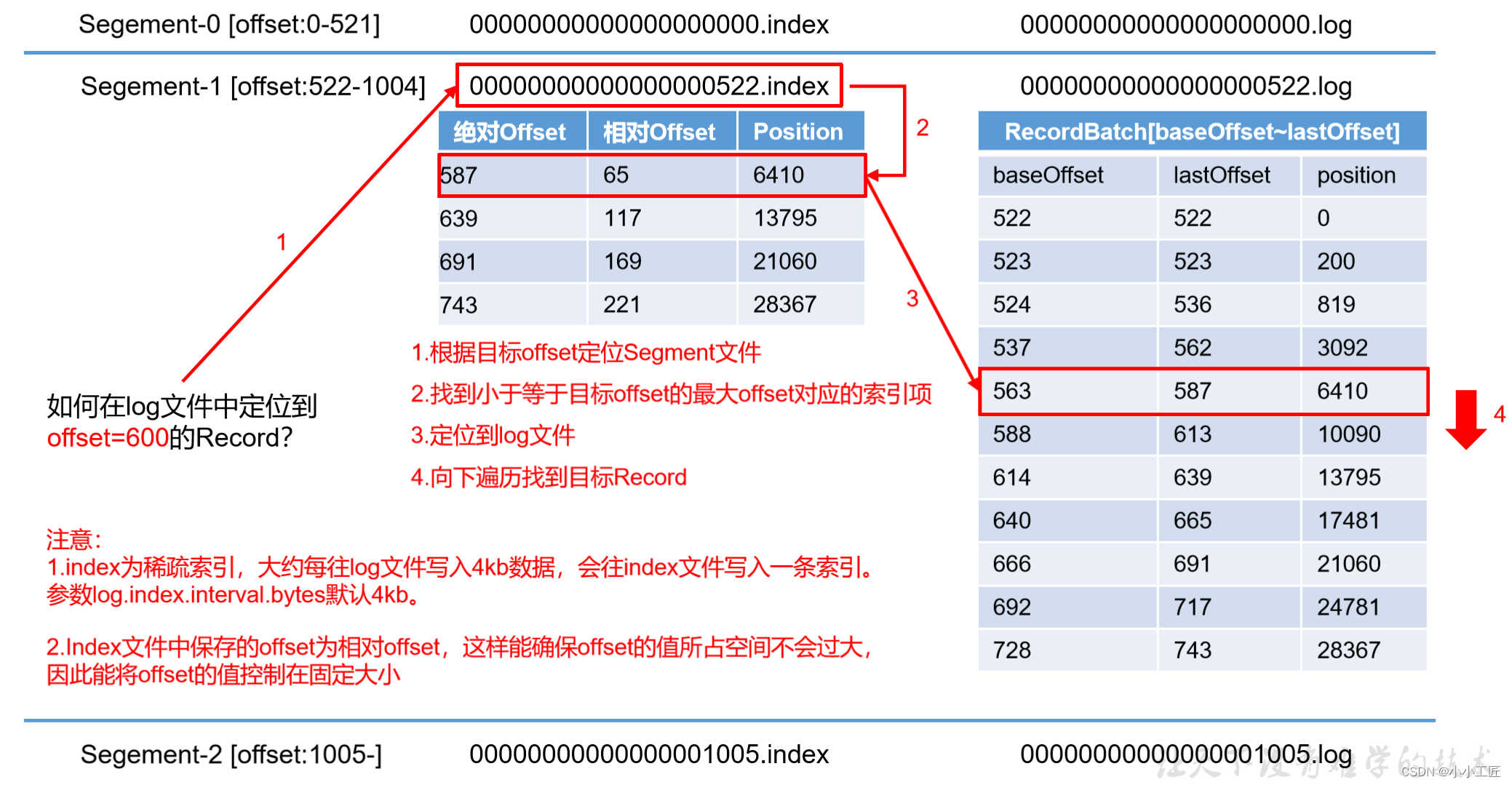
index文件和log文件详解
日志存储参数配置
| 参数 | 描述 |
|---|---|
| log.segment.bytes | Kafka中log日志是分成一块块存储的,此配置是指log日志划分成块的大小,默认值1G。 |
| log.index.interval.bytes | 默认4kb,Kafka里每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。稀疏索引。 |
文件清理策略
综述
Kafka的日志清理策略是为了管理磁盘上的数据,确保系统的性能和可用性。日志清理策略通常与消息日志的保留策略相关。以下是Kafka的日志清理策略的要点:
-
日志保留策略:
- Kafka允许配置保留消息日志的时间(通过
log.retention.ms参数)或消息数量(通过log.retention.bytes参数)。 - 消息日志可以保留一定时间(例如,一周)或一定大小的消息(例如,10 GB),之后将进行清理。
- Kafka允许配置保留消息日志的时间(通过
-
Segments(段):
- Kafka的消息日志被分成多个段(log segment),每个段包含一定数量的消息。
- 清理策略针对这些段执行。段的创建和关闭是基于时间和大小的策略。
-
日志清理策略类型:
- Kafka支持两种主要的日志清理策略:删除策略(Delete)和压缩策略(Compact)。
- 删除策略通过删除旧的日志段来释放磁盘空间。这是默认策略。
- 压缩策略通过保留消息键相同的最新消息,删除旧版本的消息。这对于维护有状态应用程序非常有用。
-
消息日志清理的触发:
- 清理策略的触发可以由多个因素决定,包括时间(
log.retention.ms)、日志大小(log.retention.bytes)、活动日志段的数量和特定主题的配置。 - 通常,Kafka会周期性地执行清理任务,确保消息日志不会无限增长。
- 清理策略的触发可以由多个因素决定,包括时间(
-
日志清理的影响:
- 日志清理可能导致消息丢失,特别是对于删除策略。因此,清理策略的配置需要谨慎考虑,以平衡磁盘空间和消息保留需求。
总之,Kafka的日志清理策略是一个关键组成部分,用于管理消息日志的大小和维护磁盘空间。根据业务需求,可以选择不同的保留策略和清理策略,以满足数据保留、性能和可用性方面的要求。
- kafka数据文件保存时间:默认是7天
- kafka数据文件保存可通过如下参数修改
① log.retention.hours:最低优先级小时, 默认7天(168小时)
② log.retention.minutes:分钟
③ log.retention.ms:最高优先级毫秒
④ log.retention.check.interval.ms:负责设置检查周期,默认5分钟。
清理策略
3.那么一旦超过了设置的时间就会采取清理策略,清理策略有两种:delete和compact
1)delete策略
delete日志删除:将过期数据删除。
配置:log.cleanup.policy=delete
基于时间:默认打开,以segment中所有记录中的最大时间戳作为文件时间戳
基于大小:默认关闭,超过设置的所有日志大小,删除最早的segment。
log.retention.bytes,默认等于-1,表示无穷大。
2)compact日志策略
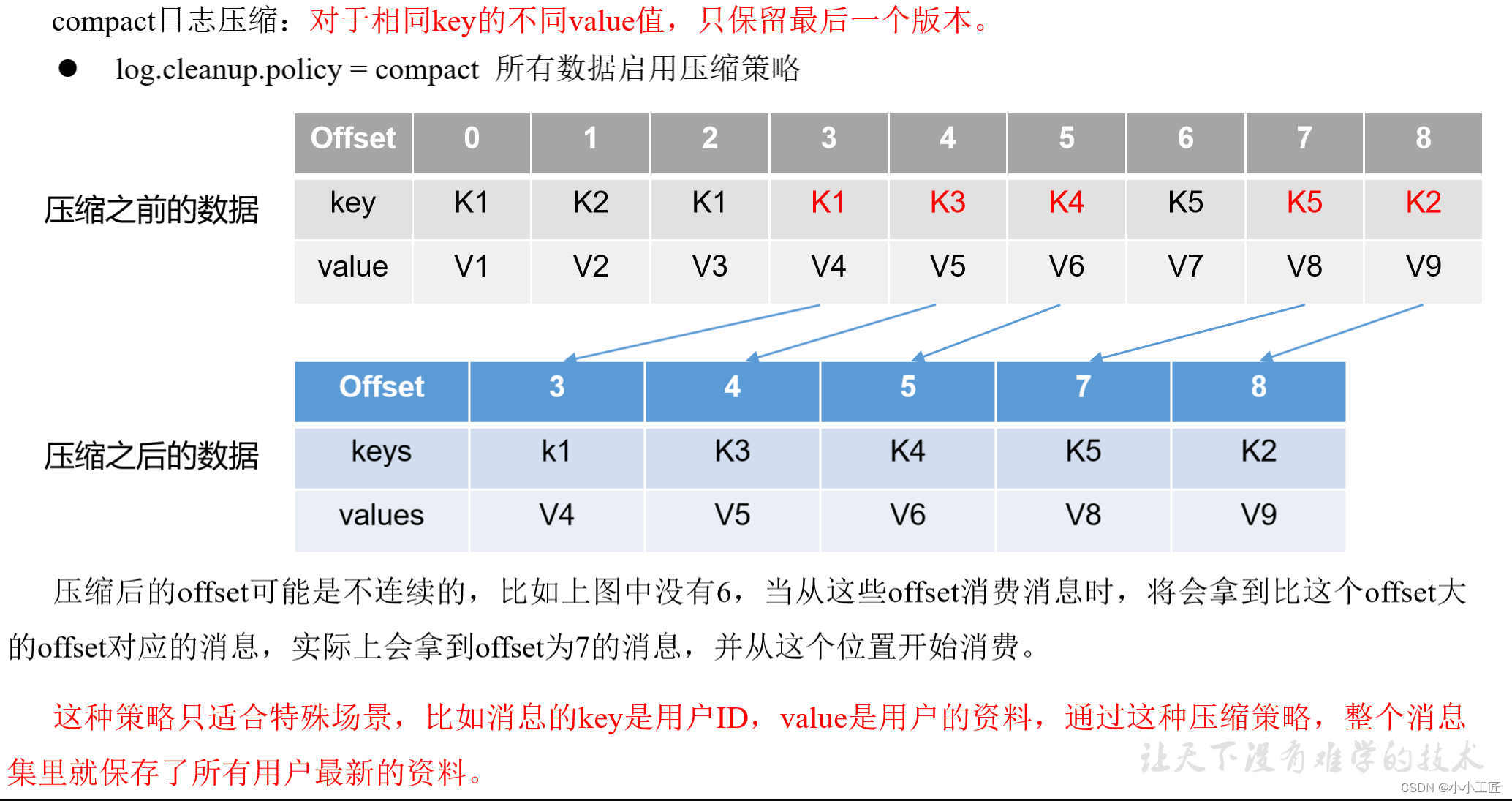
高效读写的原因
-
Kafka本身是分布式集群,可以采用分区技术,并行度高
-
读数据采用稀疏索引,可以快速定位要消费的数据
-
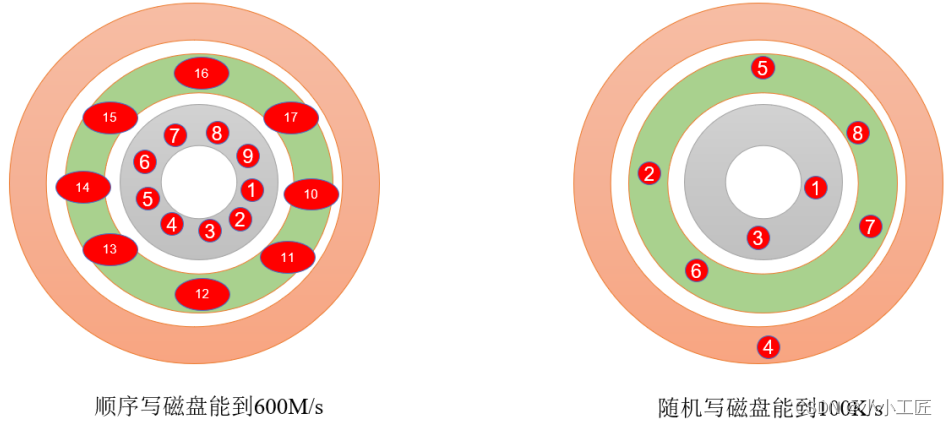
顺序写磁盘
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
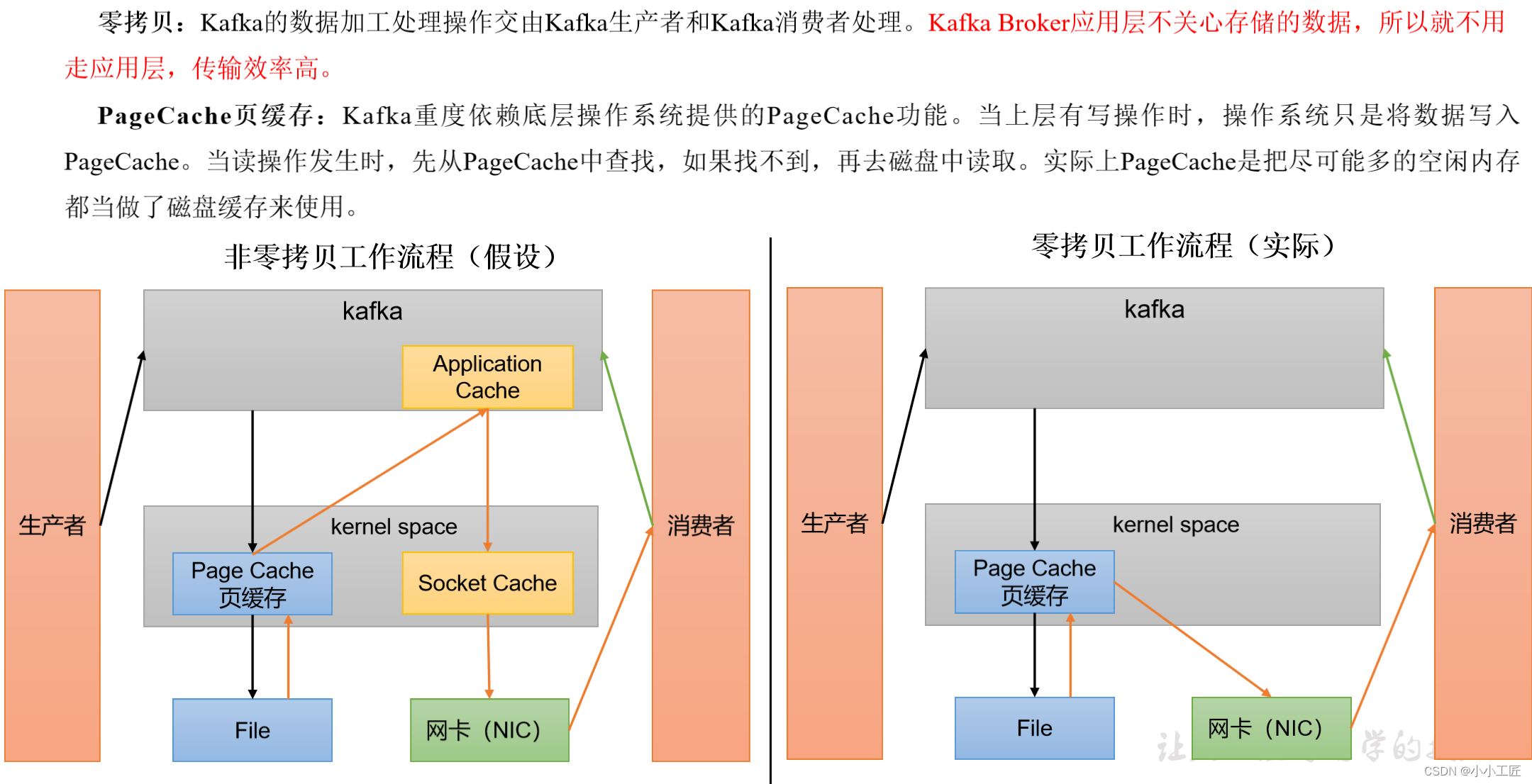
- 页缓存+零拷贝技术
| 参数 | 描述 |
|---|---|
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。 |