随着科技的进步和数字化转型的加速,全球数据量正以惊人的速度增长。根据IDC的最新报告,2020年全球数据总量已经达到了约53 ZB(Zettabyte,万亿亿GB),而这个数字在2025年预计会达到175 ZB。这种指数级增长不仅体现了大数据时代的来临,也对数据处理和分析能力提出了更高的要求。
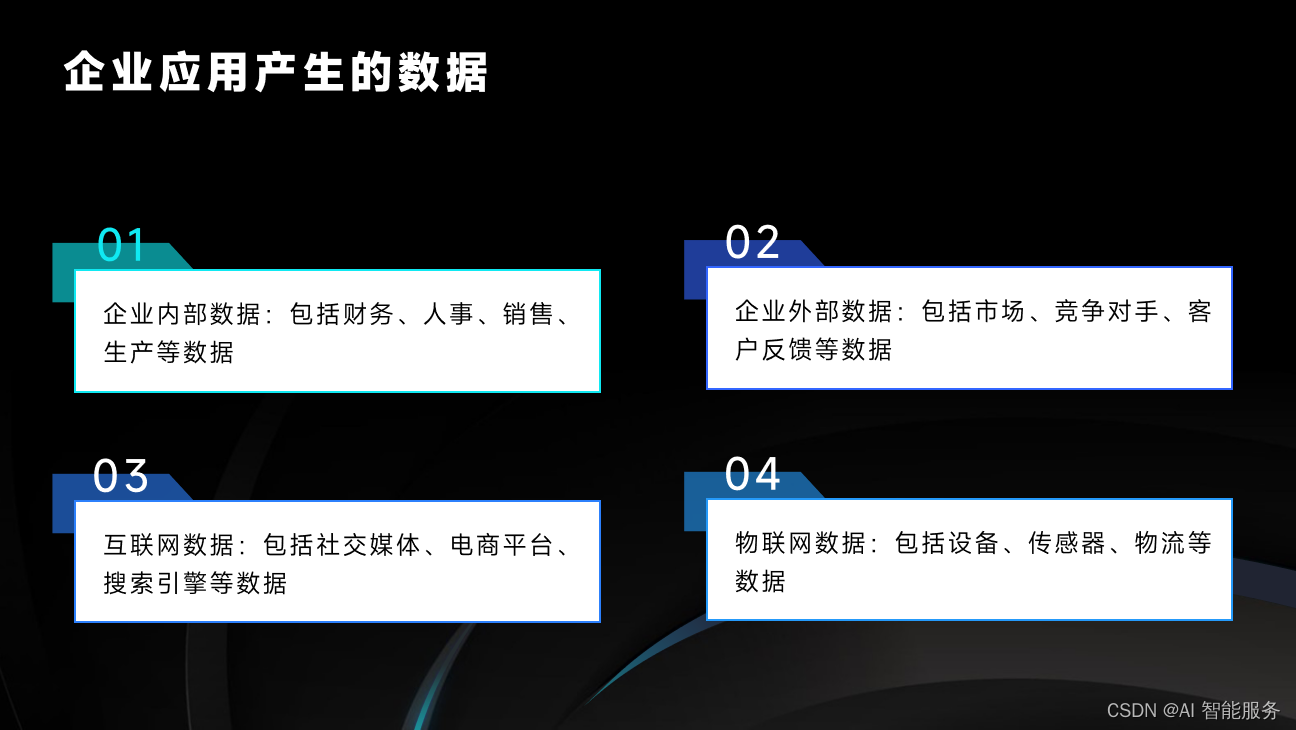
如此庞大的数据量并不是凭空产生的,它有着各种各样的来源。首先,随着互联网、物联网、移动设备和社交媒体的普及,人们在日常生活中产生的数据量不断增加。每一次在线购物、搜索、社交互动,甚至每一次点击都会生成数据。这些数据不仅包括个人用户的隐私信息,也包括企业的大量交易数据和市场数据。其次,各种企业和机构也是数据的主要来源。在生产过程中,机器设备会产生大量的传感器数据;在销售过程中,交易数据和客户行为数据不断积累;在服务过程中,用户的反馈和投诉也会形成大量的文本数据。
这些来源不同的数据在大数据技术的支持下,被整合、分析和挖掘,为各行各业提供了深入的洞察和决策支持。从商业决策、风险管理到科技创新,大数据都在发挥着越来越重要的作用。而随着数据量的持续增长,我们也需要不断提升数据处理和分析的技术和能力,以应对未来的挑战。
1.数据来源


2.数据用途
数据的用途非常广泛,可以应用于各个领域,包括但不限于以下几个方面:
- 商业决策:数据可以提供对市场、消费者行为的深入洞察,帮助企业做出更明智的商业决策。
- 风险管理:通过数据分析和预测,企业可以更好地识别和预防潜在的风险,并制定相应的应对措施。
- 科技创新:数据可以提供对科技趋势、新兴技术的深入了解,推动科技创新和进步。
- 医疗健康:数据可以用于诊断、治疗和预防疾病等方面,帮助医生制定更准确的诊断方案,提高治疗效果。
- 城市规划:数据可以提供对城市交通、人口、环境等各方面的深入了解,帮助城市规划者制定更合理的城市规划方案。
- 社交媒体分析:通过分析社交媒体数据,可以了解公众对某个话题、事件的态度和情绪,帮助企业或组织制定相应的公关策略。
下面详细介绍几个应用案例:
2.1出行行业

2.2金融行业

2.3医疗行业

3.数据标注
数据标注是为机器学习提供基础数据的过程。这个过程涉及到对图片、语音、文本等各类数据进行分类、画框、标注、注释等处理,以供机器学习算法使用。数据标注的质量和精度对机器学习算法的训练和表现有着重要影响。
在数据标注的过程中,一般会遵循以下步骤:
- 数据采集:从各种来源获取原始数据。
- 数据清洗:去除无效、错误和重复的数据,提高数据的质量。
- 数据标注:对数据进行标注处理,例如对图片中的物体进行标注,对语音数据进行转写,对文本数据进行分类等。
- 数据质检:对标注后的数据进行质量检查,确保标注的准确性和完整性。
数据标注的类型有很多,主要包括图像标注、语音标注、文本标注等。
图像标注是对图片数据进行处理,将图片中物体边缘、颜色、形状等特征提取出来,转换为机器可识别的数据格式;
语音标注是对语音数据进行转写,将其转换为文本格式;
文本标注则是对文本数据进行分类、关键词提取等处理,以便机器学习算法使用。
下面具体介绍几种标注:






数据标注在人工智能领域中扮演着重要的角色,它是许多机器学习算法得以有效运行的关键环节。未经标注处理的原始数据往往是非结构化的,难以被机器识别和学习。只有经过标注处理后的结构化数据才能被算法模型训练使用。随着人工智能技术的不断发展,数据标注的需求和应用也越来越广泛。