文章目录
- kafka 副本的基本信息
- Leader选举过程
- Kafka Controller
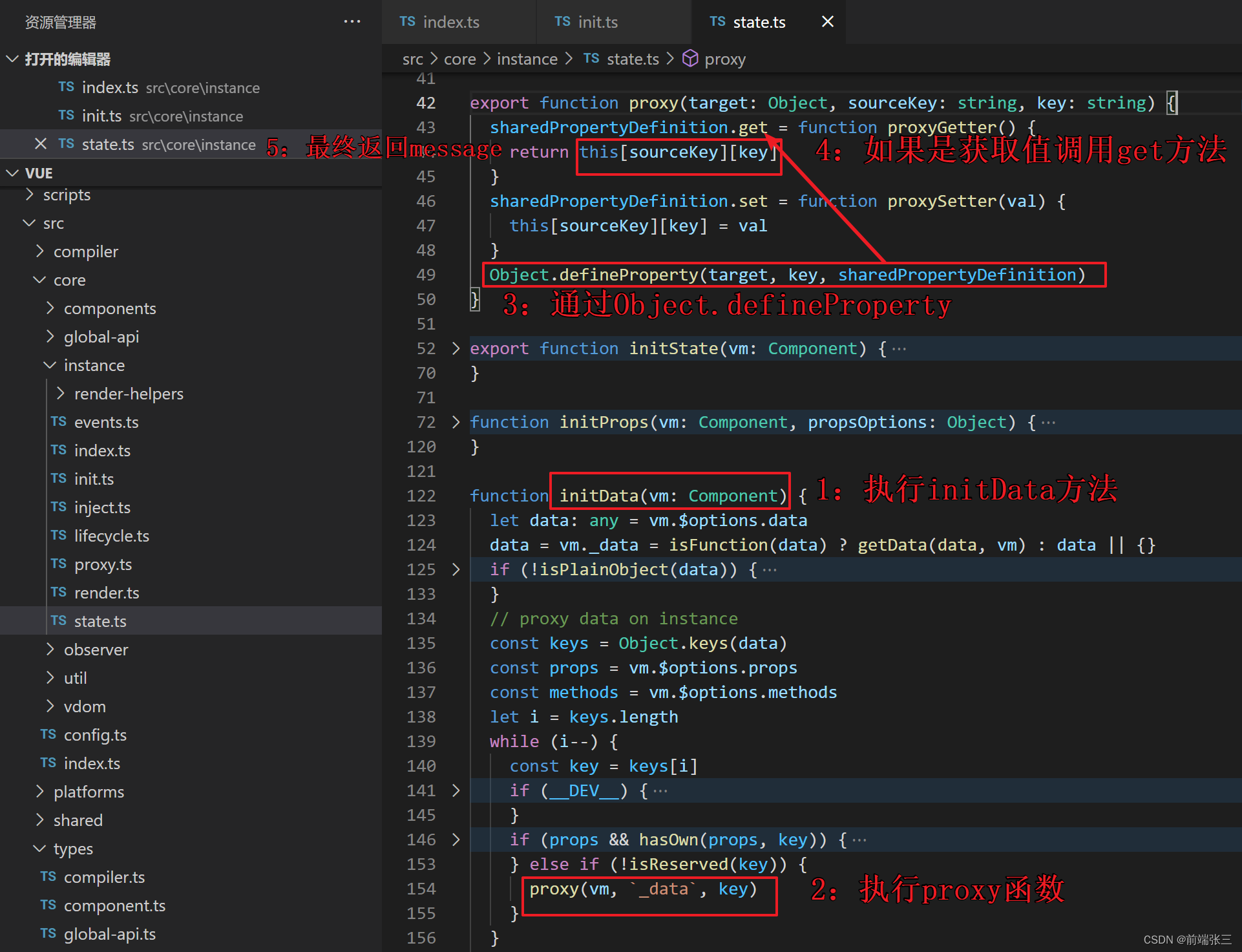
- kafka 分区副本Leader的选举流程
- 实际演示
- ① 查看first的详细信息,注意观察副本分布情况
- ② 停掉hadoop103上的kafka进程
- ③ 再次查看first的相信信息,观察副本分布
- ④ 处理分区leader分布不均匀问题
- leader和 follower故障处理细节
- follower故障处理细节(被踢-重连-追上Hw-连接成功)
- leader故障处理细节(从ISR队列选取ar中靠前的节点选为leader,新leader短则follower“剪”,反之则向leader同步)

kafka 副本的基本信息
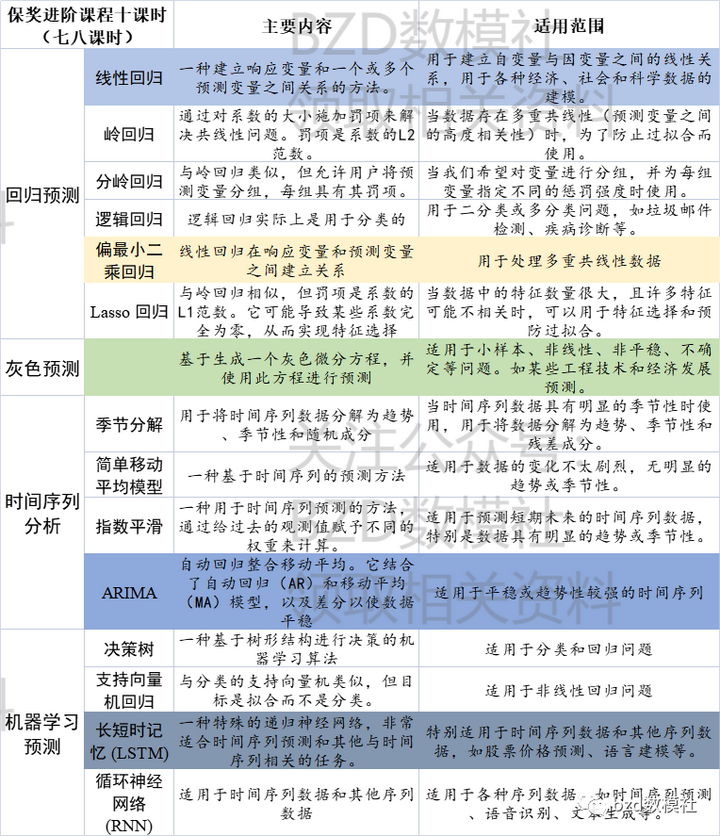
| 参数名称 | 描述 |
|---|---|
| kafka副本作用 | 提高数据可靠性 |
| kafka副本个数 | 默认1个,生产环境中一般配置为2个,保证数据可靠性;但是过多的副本会增加磁盘存储空间、增加网络数据传输、降低kafka效率。 |
| kafka副本角色 | 副本角色分为Leader和Follower。kafka生产者只会把数据发送到Leader,follower会主动从Leader上同步数据。 |
| kafka中的AR | 是所有副本的统称(Assigned Repllicas),AR = ISR + OSR |
| ISR | 表示和Leader保持同步(默认30s)的follower集合。 |
| OSR | 表示Follower与Leader副本同步时,延迟过多的副本。 |
Leader选举过程
Kafka Controller
kafka集群中有一个broker的Controller会被选举为Controller Leader,负责管理集群broker的上下线、所有的topic的分区副本分配和Leader选举等工作。
Controller的信息同步工作是依赖于Zookeeper的。
kafka 分区副本Leader的选举流程
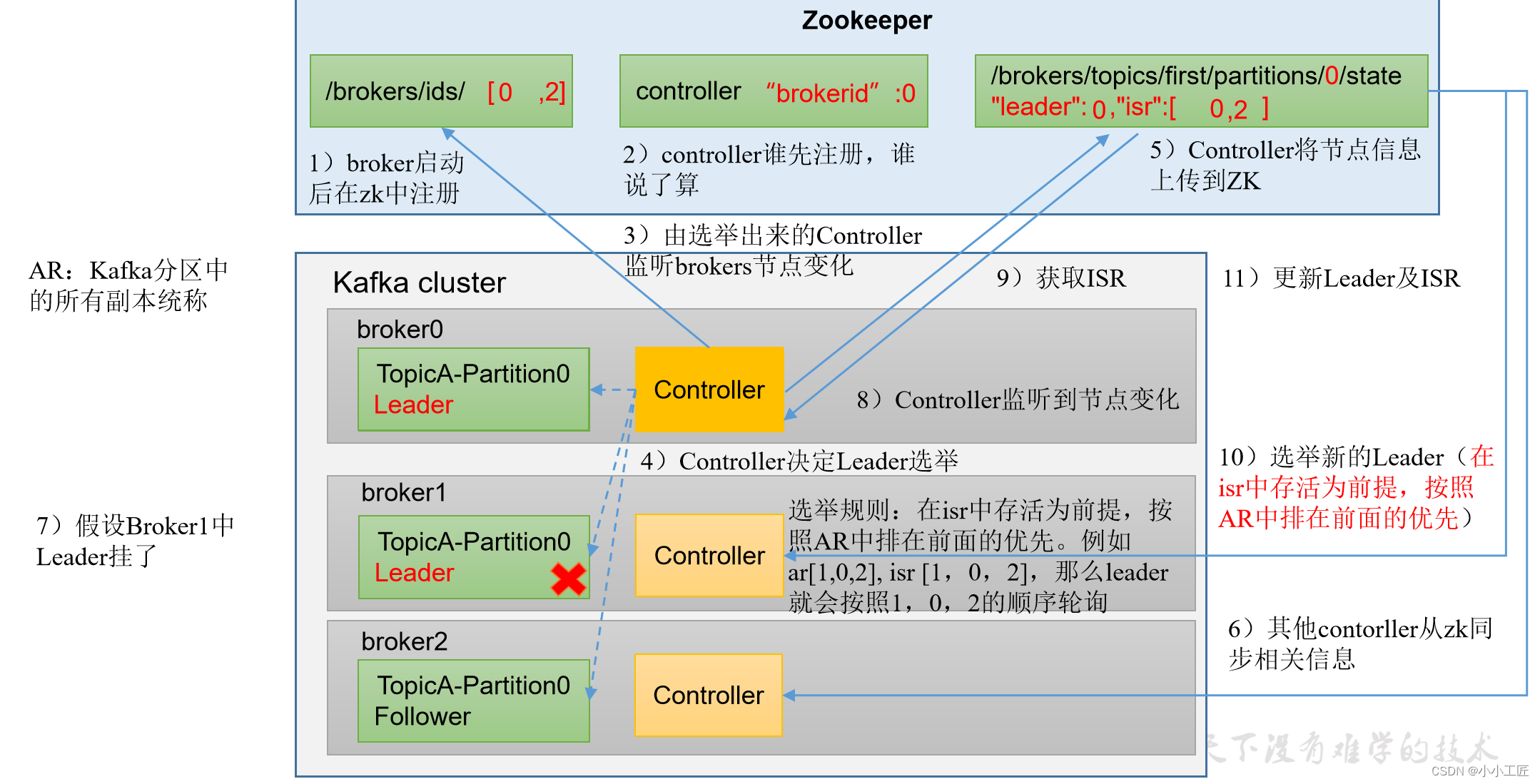
Kafka是一个分布式消息系统,具有分区和副本的概念,以确保高可用性和容错性。在Kafka中,每个分区都有一个领导者(Leader)和零个或多个副本(Replicas)。当分区的领导者(Leader)失败时,会触发新的领导者选举过程,确保分区的可用性。
以下是Kafka分区领导者选举的一般流程:
-
原始领导者故障:当Kafka集群中分区的当前领导者故障,或者由于某种原因无法提供服务时,领导者选举会被触发。
-
副本提名:每个分区的副本都有可能成为新的领导者。首先,副本需要“提名”自己作为新的领导者。这个提名会通过ZooKeeper或最新的KRaft元数据管理器(在Kafka 2.8.0及更高版本中引入)来完成。
-
提名标准:副本提名自己的标准通常包括以下因素:
- 副本是否具备最新的数据(即最高的日志段offset)。
- 副本的健康状态,例如是否在线、可用性等。
- 副本的副本同步延迟。
-
提名协调:Kafka通过ZooKeeper或KRaft元数据管理器来协调各个副本的提名过程。这些管理器会比较各个提名并选择一个新的领导者。
-
提名通知:一旦新的领导者被选出,Kafka会通知所有副本,将新领导者的ID分发给它们。
-
新领导者选举完成:一旦新领导者被选出并通知其他副本,分区将有一个新的领导者。客户端请求将路由到新领导者,确保消息的读写操作可以继续。
需要注意的是,Kafka的分区领导者选举是一种自愿的过程,只有当当前领导者无法提供服务时,才会触发这一过程。这有助于确保Kafka的高可用性和容错性,因为在任何时刻都有多个副本可用以提供数据服务。
实际演示
① 查看first的详细信息,注意观察副本分布情况
[xxx@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104,103
Topic: first Partition: 1 Leader: 103 Replicas: 103,102,104 Isr: 103,102,104
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,103,102
② 停掉hadoop103上的kafka进程
[xxx@hadoop103 kafka]$ bin/kafka-server-stop.sh
③ 再次查看first的相信信息,观察副本分布
[xxx@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104
Topic: first Partition: 1 Leader: 102 Replicas: 103,102,104 Isr: 102,104
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,102
④ 处理分区leader分布不均匀问题
[xxx@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 0
[xxx@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 1
[xxx@hadoop102 kafka]$ bin/kafka-leader-election.sh --bootstrap-server hadoop102:9092 --topic first --election-type preferred --partition 2
[xxx@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: aUFTM5wES7eSBiuSKT0UpA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 102 Replicas: 102,104,103 Isr: 102,104,103
Topic: first Partition: 1 Leader: 103 Replicas: 103,102,104 Isr: 102,104,103
Topic: first Partition: 2 Leader: 104 Replicas: 104,103,102 Isr: 104,102,103
leader和 follower故障处理细节
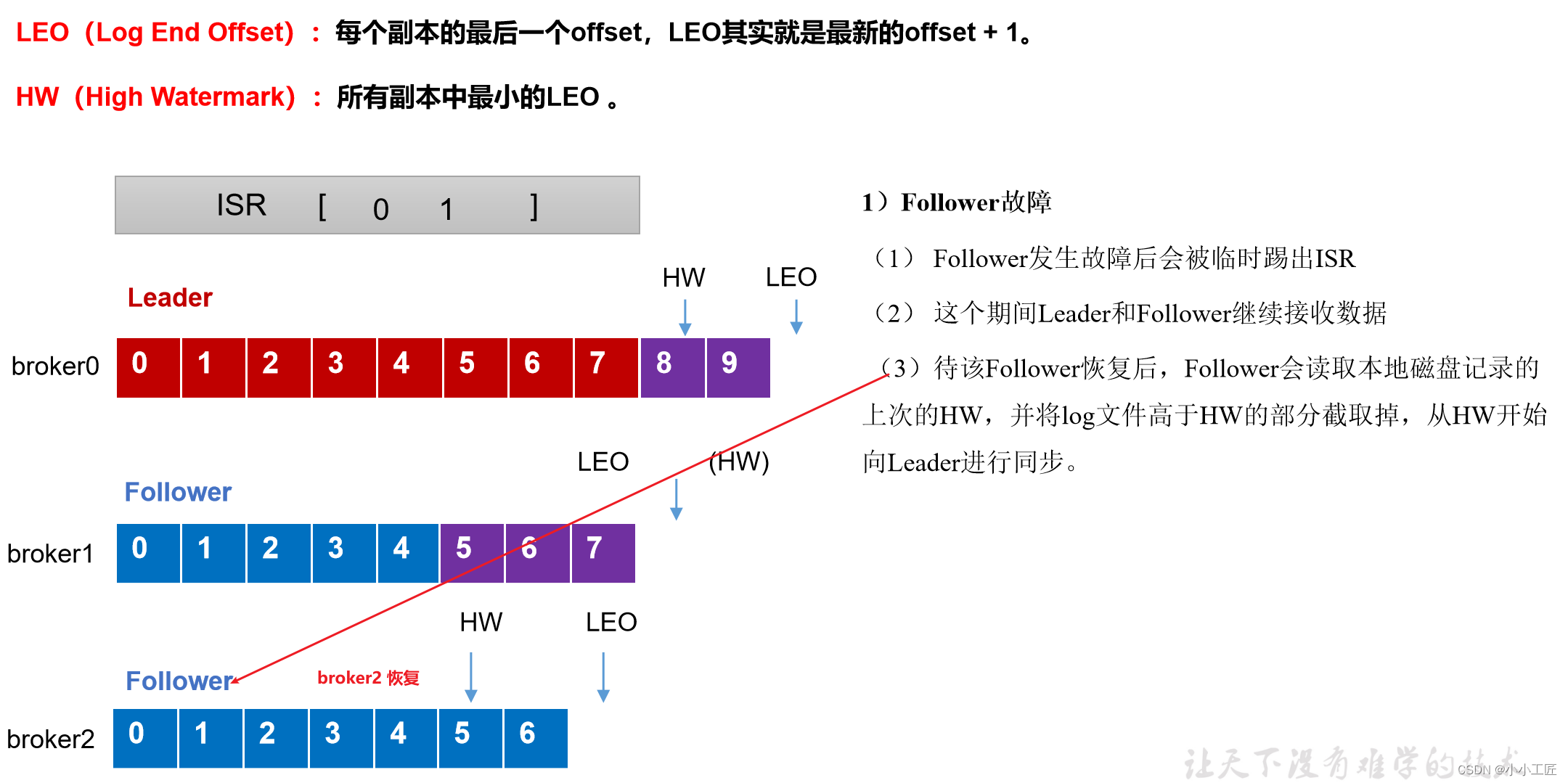
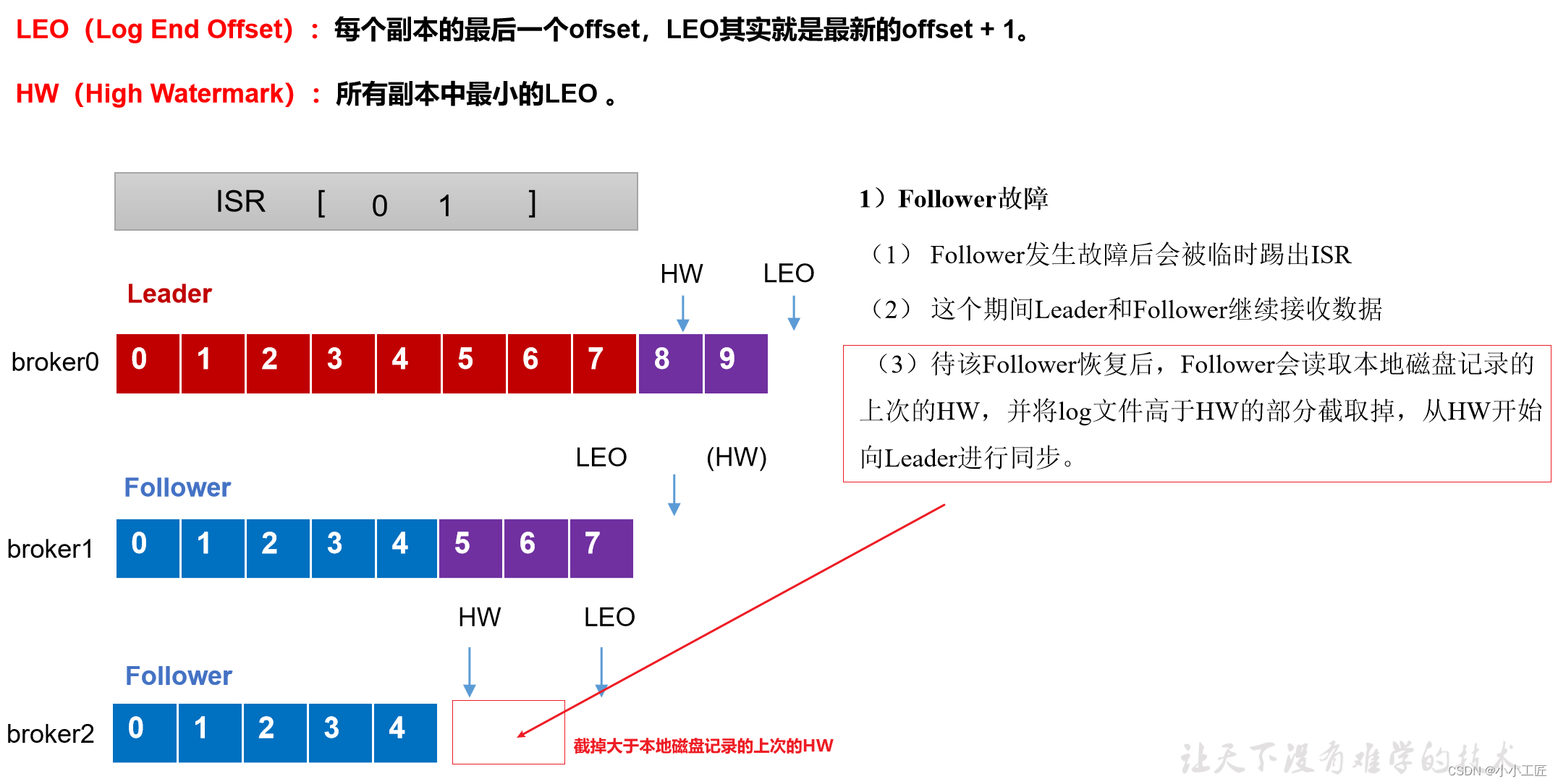
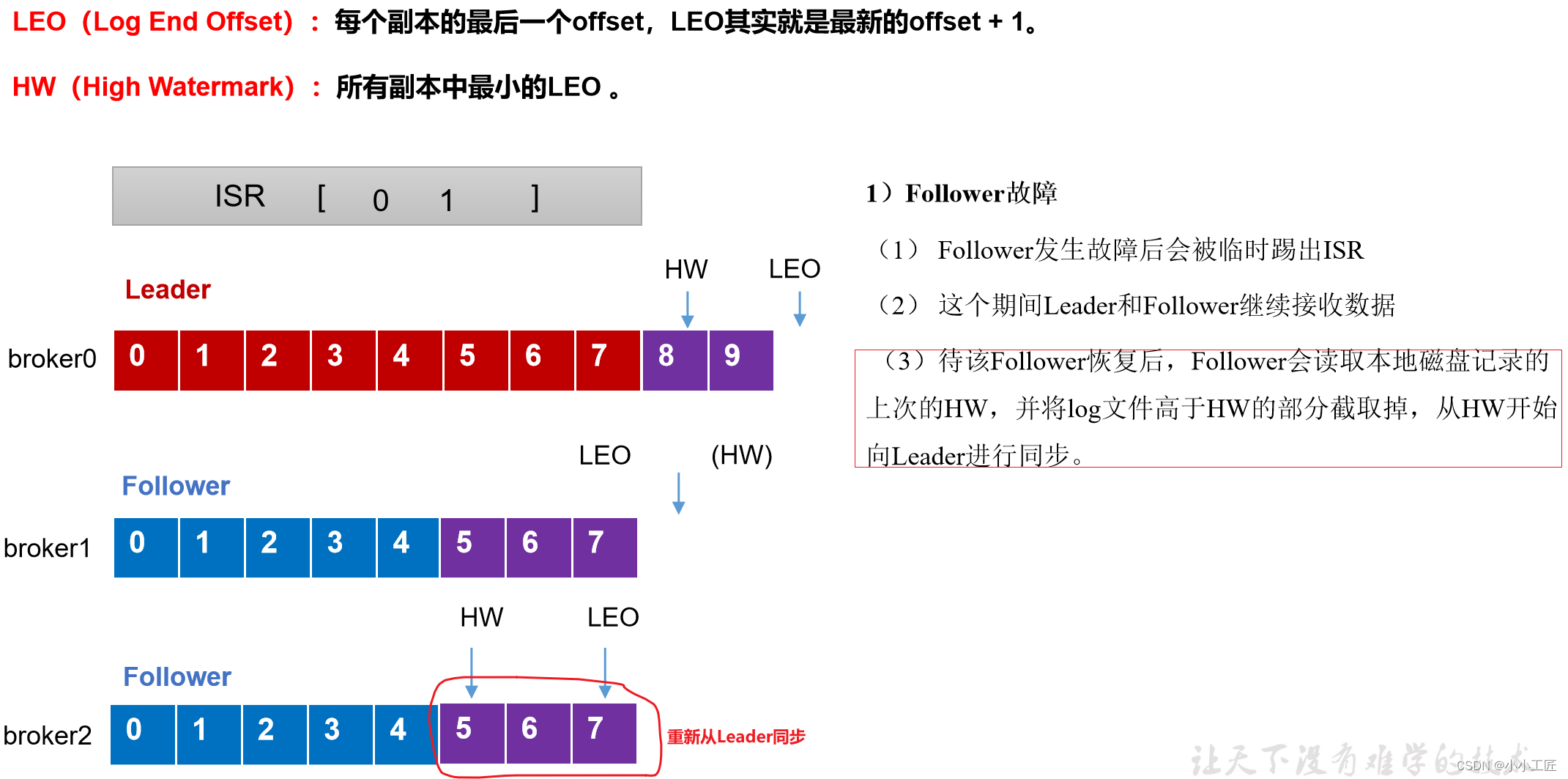
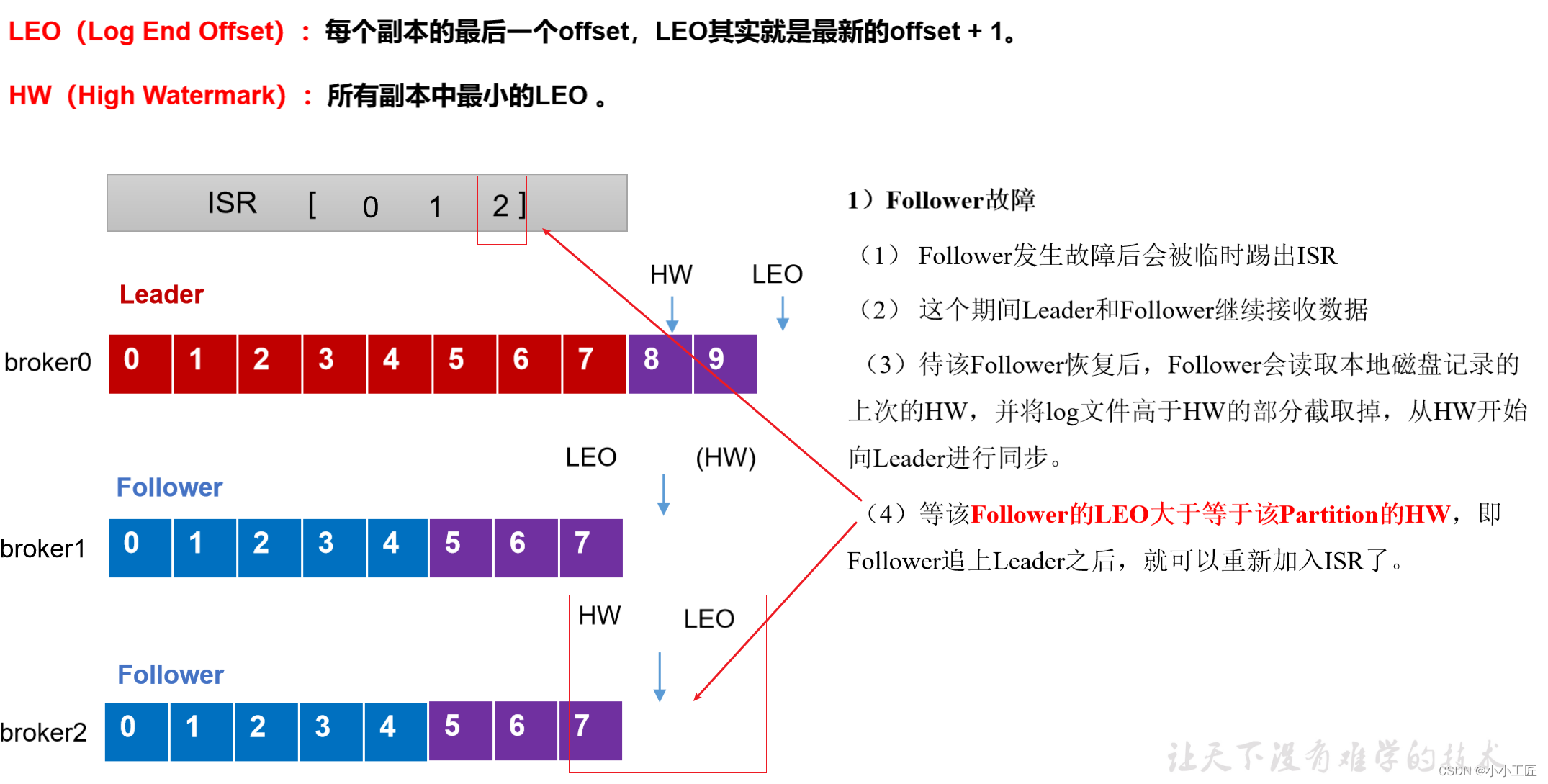
follower故障处理细节(被踢-重连-追上Hw-连接成功)
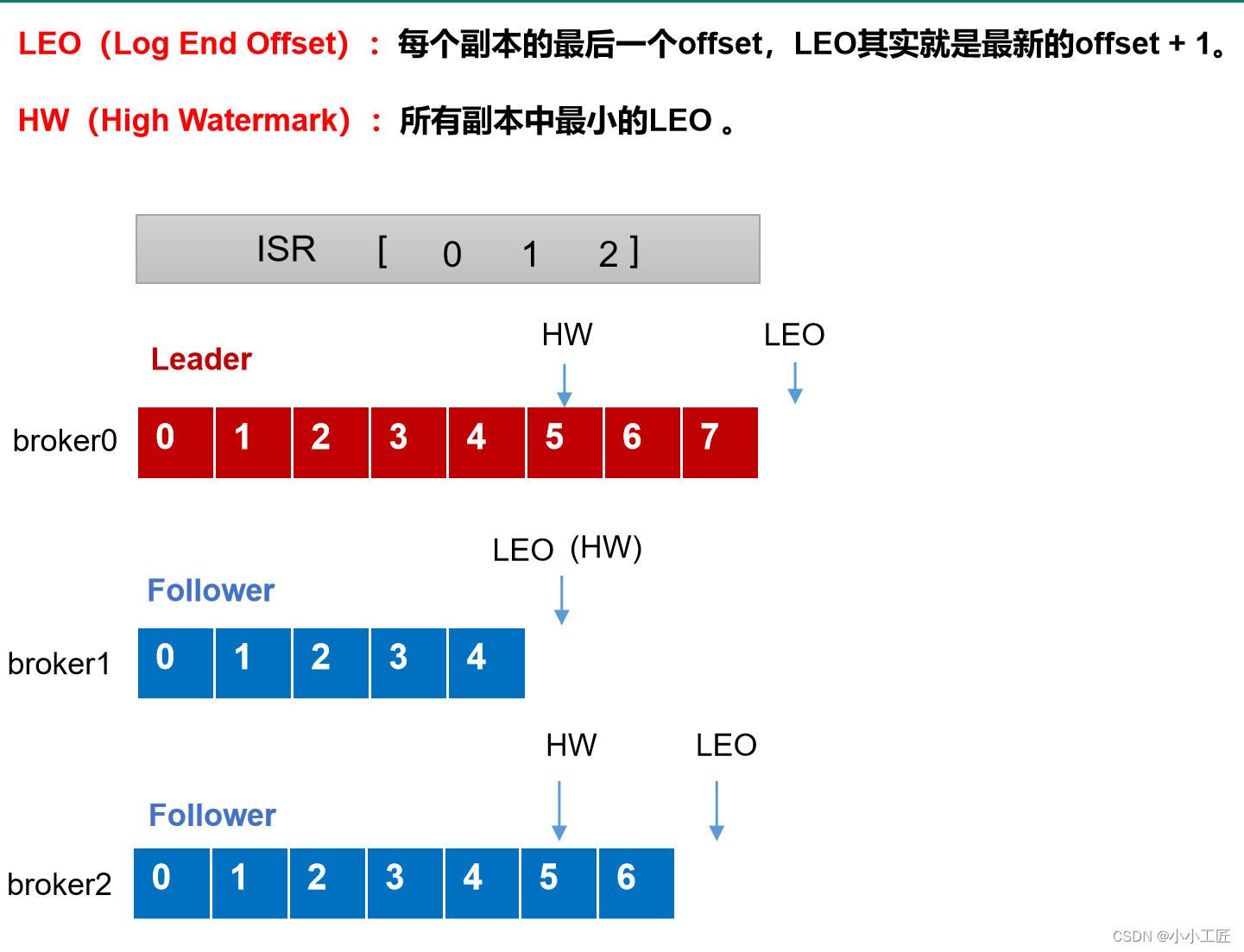
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉(HW之前每个节点都有,故安全),从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了
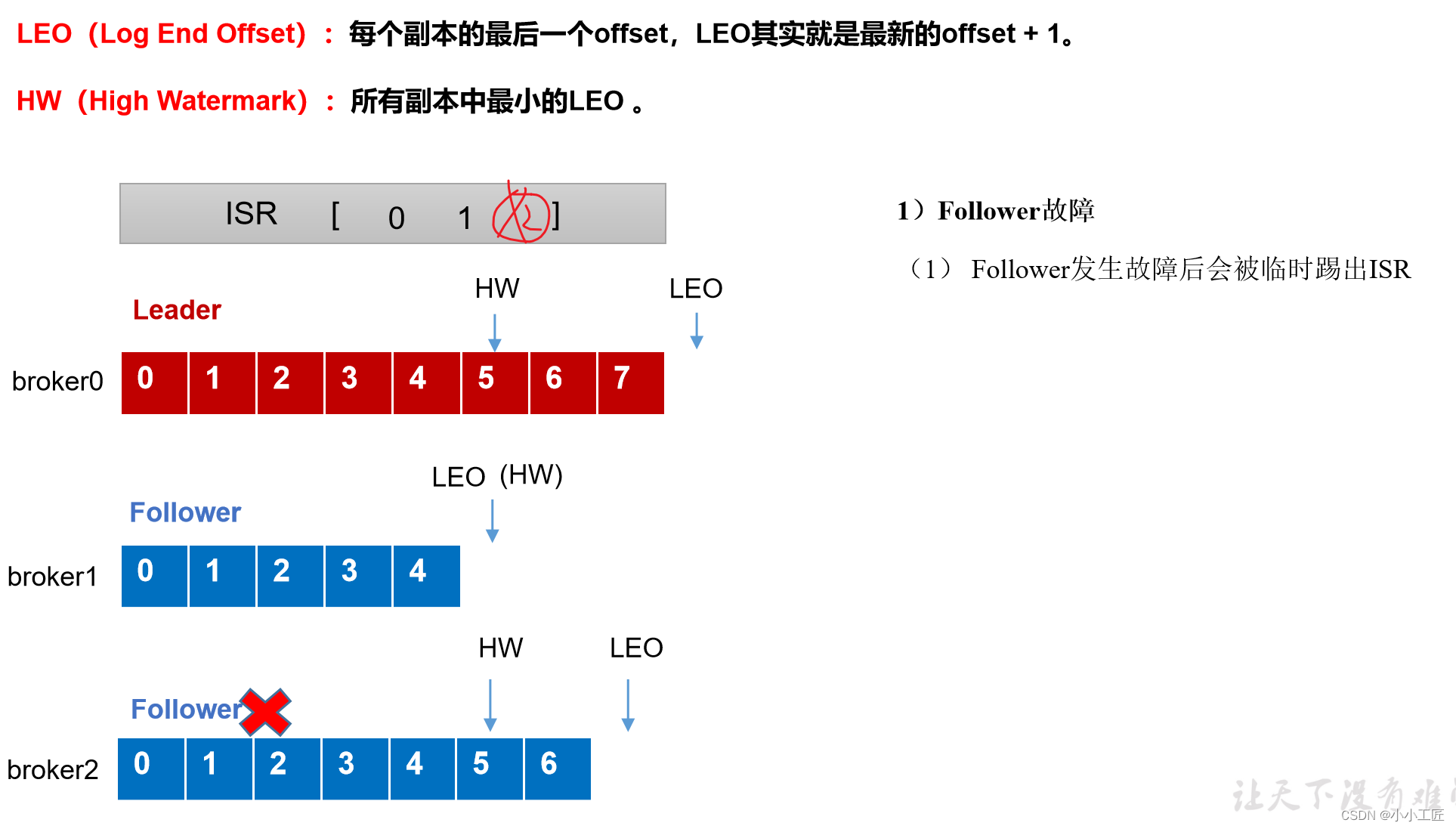
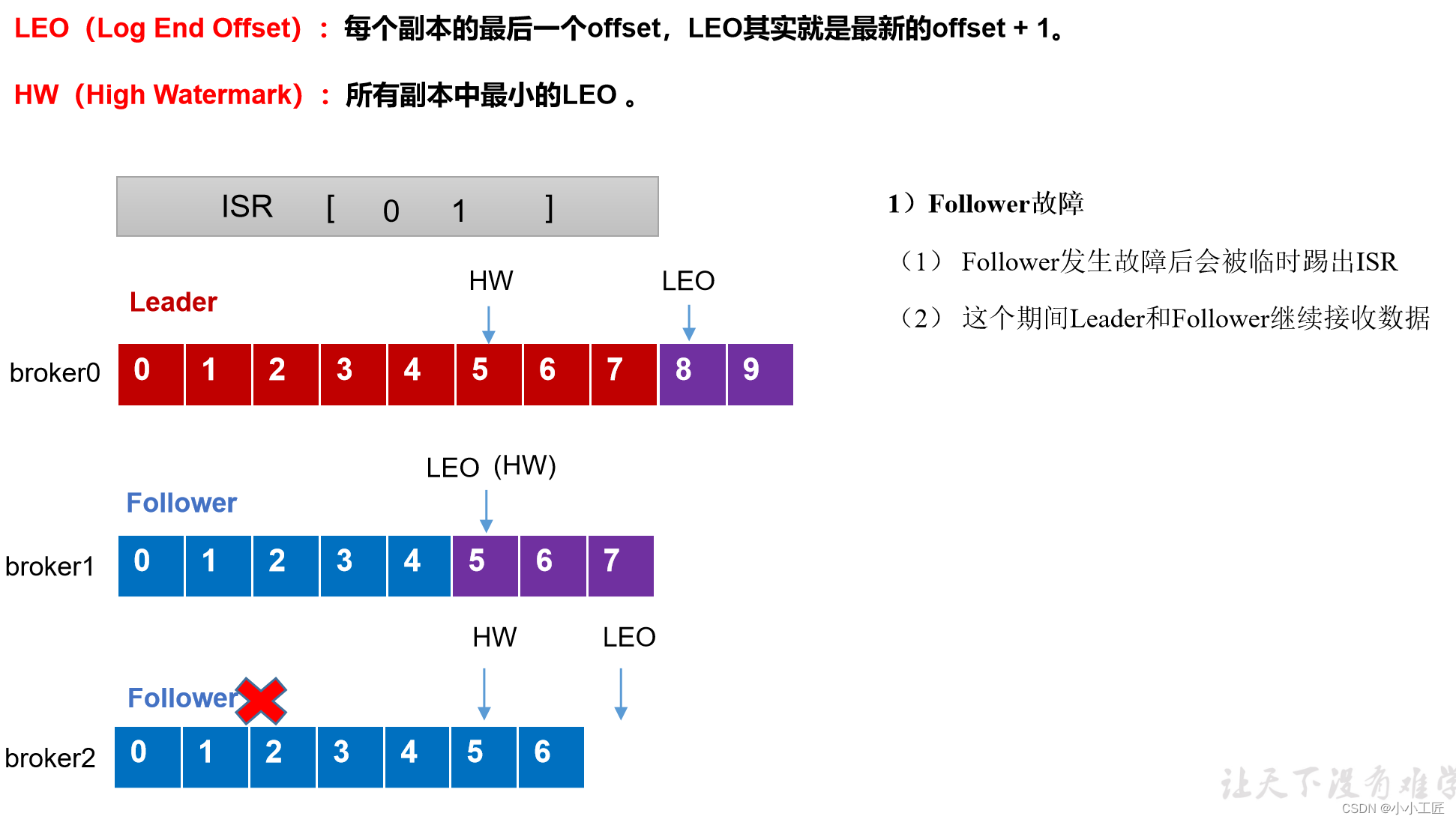
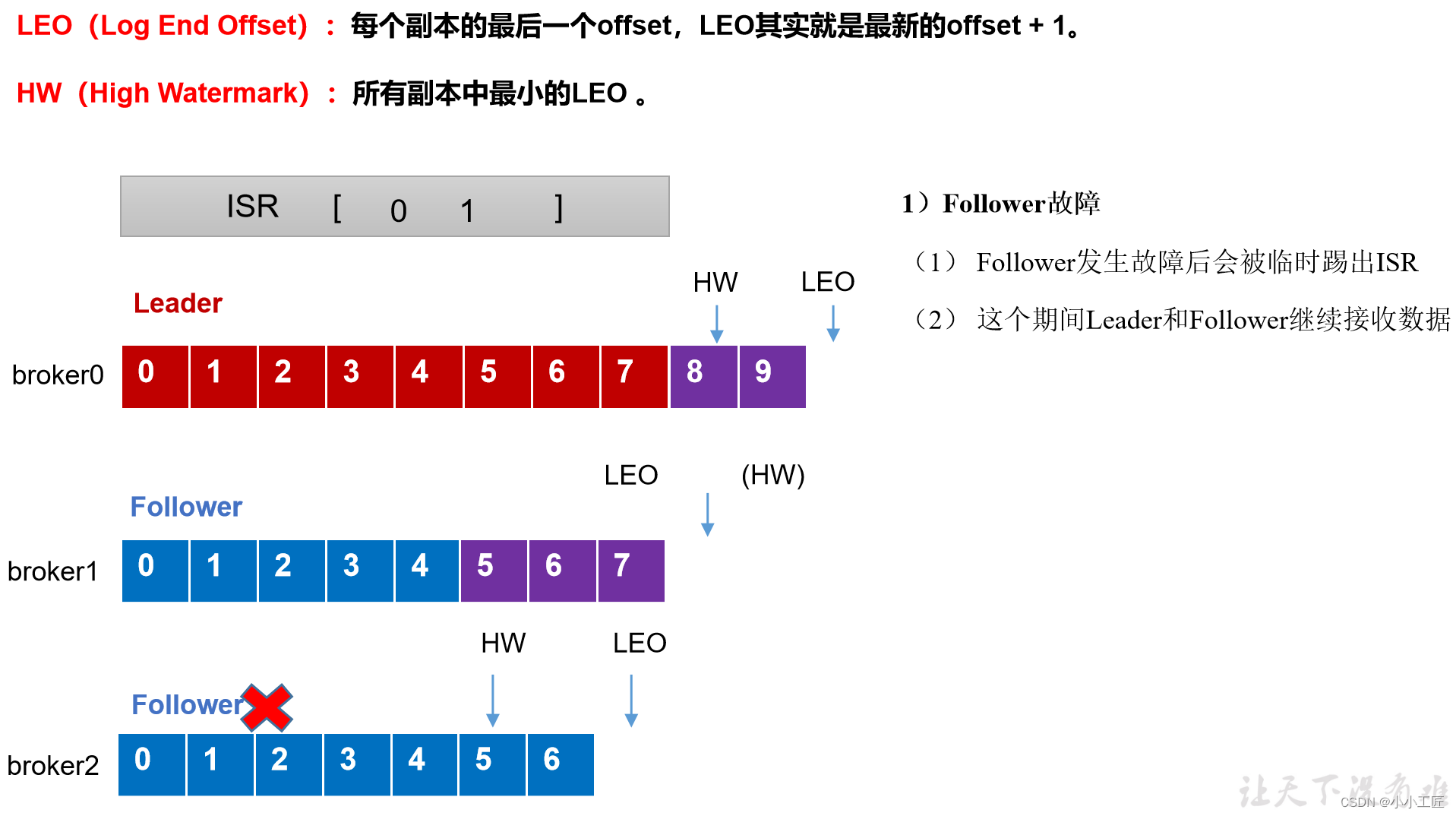
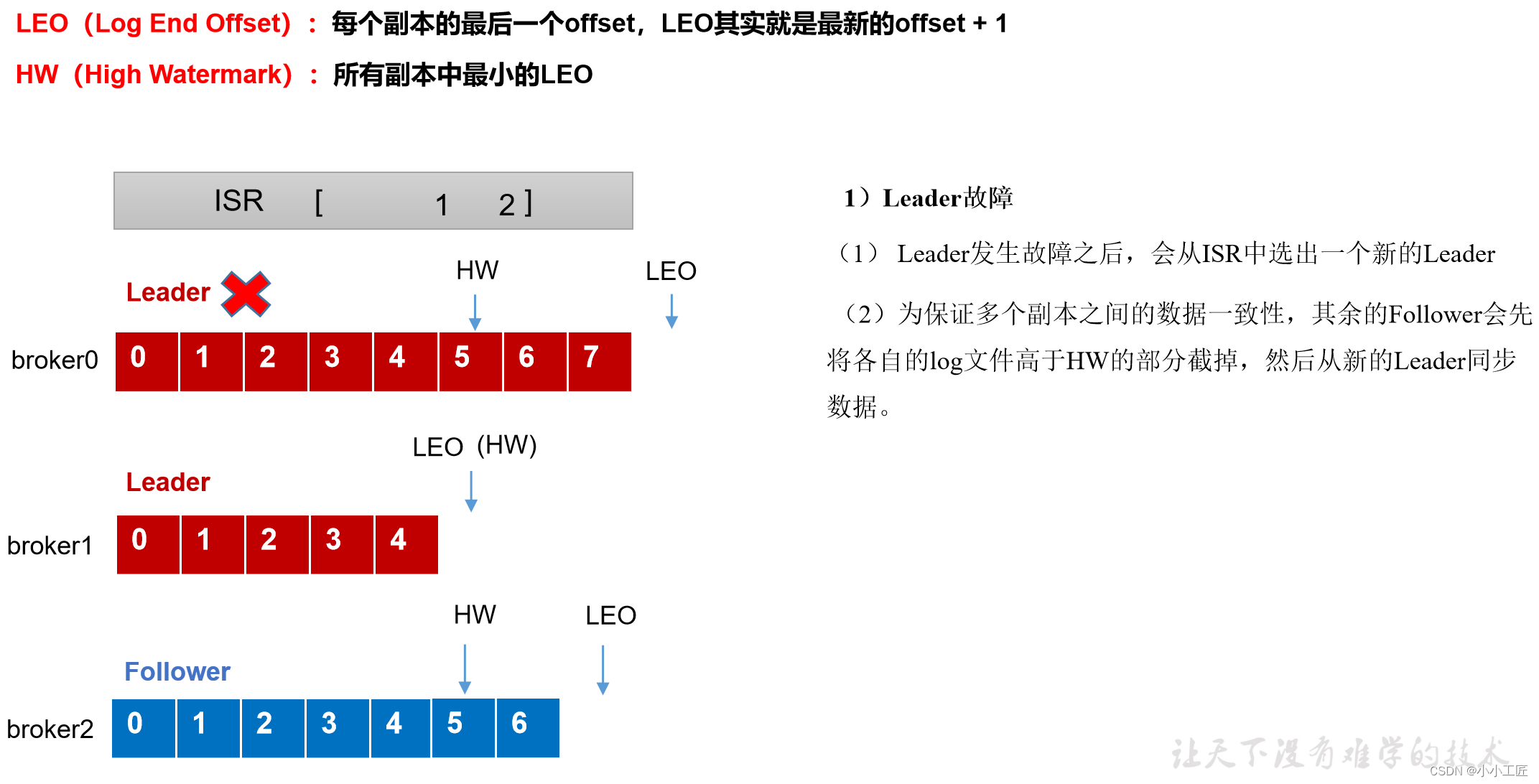
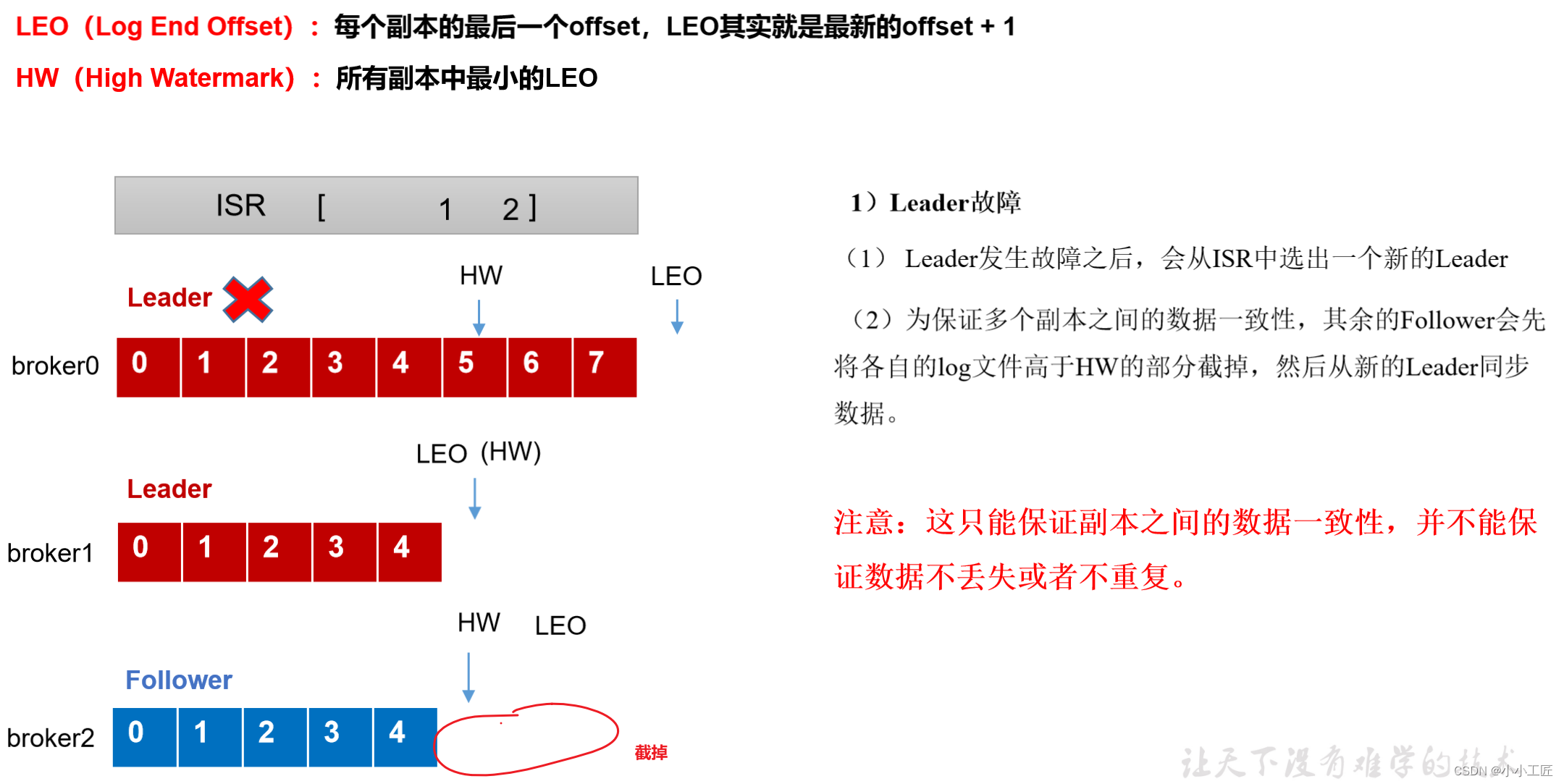
leader故障处理细节(从ISR队列选取ar中靠前的节点选为leader,新leader短则follower“剪”,反之则向leader同步)
eader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。






![[C++随想录] map和set的使用](https://img-blog.csdnimg.cn/78f1ecd00501417898d93daef8737903.png)