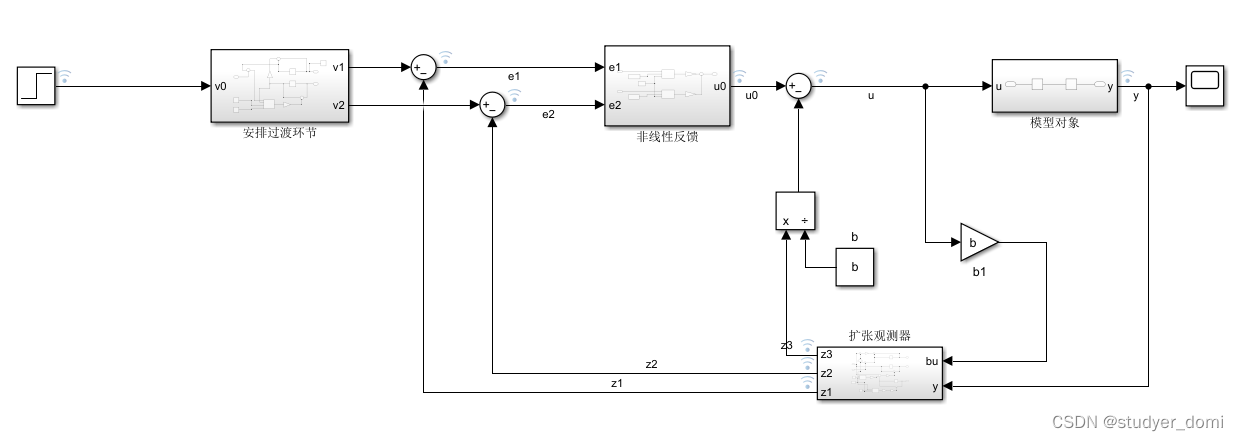
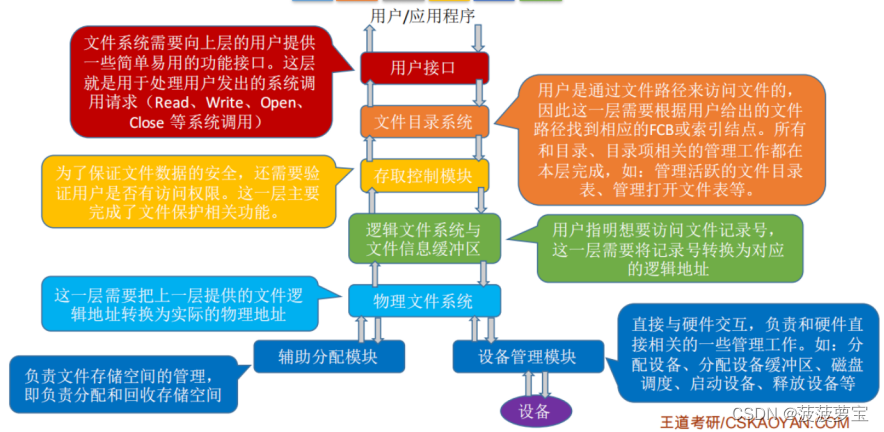
AI视野·今日CS.NLP 自然语言处理论文速览
Wed, 18 Oct 2023
Totally 82 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| VeRA: Vector-based Random Matrix Adaptation Authors Dawid Jan Kopiczko, Tijmen Blankevoort, Yuki Markus Asano 低阶自适应 LoRA 是一种流行的方法,它可以在微调大型语言模型时减少可训练参数的数量,但在扩展到更大的模型或部署大量每个用户或每个任务自适应模型时仍然面临严峻的存储挑战。在这项工作中,我们提出了基于向量的随机矩阵自适应 VeRA,与 LoRA 相比,它减少了 10 倍的可训练参数数量,但保持了相同的性能。它通过使用在所有层之间共享的一对低秩矩阵并学习小缩放向量来实现这一点。 |
| BitNet: Scaling 1-bit Transformers for Large Language Models Authors Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei 大型语言模型规模的不断增加给部署带来了挑战,并引发了人们对高能耗造成的环境影响的担忧。在这项工作中,我们介绍了 BitNet,这是一种专为大型语言模型设计的可扩展且稳定的 1 位 Transformer 架构。具体来说,我们引入 BitLinear 作为 nn.Linear 层的替代品,以便从头开始训练 1 位权重。语言建模的实验结果表明,与最先进的 8 位量化方法和 FP16 Transformer 基线相比,BitNet 实现了具有竞争力的性能,同时大幅减少了内存占用和能耗。 |
| Seeking Neural Nuggets: Knowledge Transfer in Large Language Models from a Parametric Perspective Authors Ming Zhong, Chenxin An, Weizhu Chen, Jiawei Han, Pengcheng He 大型语言模型法学硕士本质上通过对广泛语料库的预训练在其参数内编码丰富的知识。虽然先前的研究已经深入研究了对这些参数的操作,以操纵包括检测、编辑和合并在内的潜在隐式知识,但对于它们在不同规模的模型之间的可迁移性仍然存在模糊的理解。在本文中,我们试图通过参数的角度实证研究从较大模型到较小模型的知识转移。为了实现这一目标,我们采用基于敏感性的技术来提取和调整不同法学硕士之间的知识特定参数。此外,LoRA模块用作中介机制,将提取的知识注入到更小的模型中。对四个基准的评估验证了我们提出的方法的有效性。我们的研究结果强调了影响参数化知识转移过程的关键因素,强调了模型参数在不同规模的法学硕士之间的可转移性。 |
| An Empirical Study of Translation Hypothesis Ensembling with Large Language Models Authors Ant nio Farinhas, Jos G. C. de Souza, Andr F. T. Martins 大型语言模型 LLM 正在成为一种通用的解决方案,但它们有时会产生幻觉或产生不可靠的输出。在本文中,我们研究假设集成如何针对基于 LLM 的机器翻译的特定问题提高生成文本的质量。我们尝试了几种由 LLM 产生的集成假设的技术,例如 ChatGPT、LLaMA 和 Alpaca。我们提供了多个维度的全面研究,包括生成假设多重提示、基于温度的采样和波束搜索的方法,以及生成基于最终翻译指令、基于质量的重排序和最小贝叶斯风险 MBR 解码的策略。 |
| Neural Attention: Enhancing QKV Calculation in Self-Attention Mechanism with Neural Networks Authors Muhan Zhang 在深度学习领域,自注意力机制在自然语言处理和计算机视觉等众多任务中证实了其关键作用。尽管在不同的应用程序中取得了成功,但传统的自注意力机制主要利用线性变换来计算查询、键和值 QKV ,这在特定情况下可能并不总是最佳选择。本文探讨了一种新颖的 QKV 计算方法,采用专门设计的神经网络结构进行计算。利用修改后的 Marian 模型,我们在 IWSLT 2017 德语英语翻译任务数据集上进行了实验,并将我们的方法与传统方法并列。实验结果表明,我们的方法使 BLEU 分数显着提高。此外,我们的方法在使用 Wikitext 103 数据集训练 Roberta 模型时也表现出了优越性,反映出与原始模型相比模型复杂度显着降低。这些实验结果不仅验证了我们方法的有效性,而且揭示了通过基于神经网络的 QKV 计算优化自注意力机制的巨大潜力,为未来的研究和实际应用铺平了道路。 |
| DialogueLLM: Context and Emotion Knowledge-Tuned LLaMA Models for Emotion Recognition in Conversations Authors Yazhou Zhang, Mengyao Wang, Prayag Tiwari, Qiuchi Li, Benyou Wang, Jing Qin 大语言模型LLM及其变体在众多下游自然语言处理NLP任务中表现出了非凡的功效,这为NLP的发展提出了新的愿景。尽管法学硕士在自然语言生成 NLG 方面表现出色,但他们缺乏对情感理解领域的明确关注。因此,使用法学硕士进行情感识别可能会导致精度不佳和不足。法学硕士的另一个限制是,它们通常是在没有利用多模式信息的情况下进行培训的。为了克服这些限制,我们提出了 DialogueLLM,这是一种上下文和情感知识调整的 LLM,它是通过使用 13,638 个多模态(即文本和视频情感对话)微调 LLaMA 模型而获得的。视觉信息被认为是构建高质量指令的补充知识。我们对对话 ERC 数据集中的三个基准情感识别模型进行了全面评估,并将结果与 SOTA 基线和其他 SOTA LLM 进行了比较。 |
| VECHR: A Dataset for Explainable and Robust Classification of Vulnerability Type in the European Court of Human Rights Authors Shanshan Xu, Leon Staufer, Santosh T.Y.S.S, Oana Ichim, Corina Heri, Matthias Grabmair 认识到脆弱性对于理解和实施有针对性的支持以增强有需要的个人的能力至关重要。这对于欧洲人权法院 ECtHR 尤为重要,法院根据个人实际需求调整《公约》标准,从而确保有效的人权保护。然而,脆弱性的概念在 ECtHR 中仍然难以捉摸,之前也没有 NLP 研究涉及过它。为了实现这一领域的未来研究,我们提出了 VECHR,这是一个新颖的专家注释多标签数据集,包括漏洞类型分类和解释原理。我们从预测和可解释性的角度对 VECHR 上最先进模型的性能进行基准测试。我们的结果表明该任务具有挑战性,预测性能较低,模型和专家之间的一致性有限。此外,我们分析了这些模型在处理域外 OOD 数据时的鲁棒性,并观察了总体有限的性能。 |
| Disentangling the Linguistic Competence of Privacy-Preserving BERT Authors Stefan Arnold, Nils Kemmerzell, Annika Schreiner 差分隐私 DP 专为解决文本到文本私有化的独特挑战而定制。然而,众所周知,文本到文本的私有化会降低语言模型在受扰动文本训练时的性能。对从受扰动的前文本训练的 BERT 中提取的内部表示采用一系列解释技术,我们打算在语言层面上消除差异隐私引起的失真。表征相似性分析的实验结果表明,内部表征的整体相似性大大降低。 |
| Enhancing Neural Machine Translation with Semantic Units Authors Langlin Huang, Shuhao Gu, Zhuocheng Zhang, Yang Feng 传统的神经机器翻译NMT模型通常使用子词和词作为模型输入和理解的基本单位。然而,由多个标记组成的完整的单词和短语往往是表达语义的基本单位,称为语义单元。为了解决这个问题,我们提出了一种机器翻译语义单元 SU4MT 方法,该方法对句子中语义单元的整体含义进行建模,然后利用它们为理解句子提供新的视角。具体来说,我们首先提出了词对编码 WPE,一种有助于识别语义单元边界的短语提取方法。接下来,我们设计了一个注意力语义融合 ASF 层,将多个子词的语义集成到单个向量(语义单元表示)中。最后,将语义单元级句子表示连接到令牌一级,并将它们组合作为编码器的输入。实验结果表明,我们的方法有效地建模和利用语义单元级信息,并且优于强大的基线。 |
| The effect of stemming and lemmatization on Portuguese fake news text classification Authors Lucca de Freitas Santos, Murilo Varges da Silva 随着互联网、智能手机和社交媒体的普及,信息正在快速、轻松地传播,这意味着世界上的信息流量越来越大,但存在一个问题,即假新闻的传播正在危害社会。随着信息流通量的加大,一些人试图散布欺骗性信息、假新闻。假新闻的自动检测是一项具有挑战性的任务,因为要获得良好的结果是处理语言学问题所必需的,特别是当我们处理尚未全面研究的语言时,除此之外,一些技术可以帮助达到良好的效果。然而,当我们处理文本数据时,检测这种欺骗性信息的动机是人们需要知道哪些信息是真实可信的,哪些信息不是。在这项工作中,我们展示了词形还原和词干提取等预处理方法对假新闻分类的影响,为此我们设计了一些应用不同预处理技术的分类器模型。 |
| Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting Authors Melanie Sclar, Yejin Choi, Yulia Tsvetkov, Alane Suhr 由于大型语言模型法学硕士被用作语言技术的基本组成部分,因此准确表征其性能至关重要。由于提示设计中的选择会强烈影响模型行为,因此该设计过程对于有效使用任何现代预训练生成语言模型至关重要。在这项工作中,我们重点关注法学硕士对保留设计选择提示格式的典型意义类别的敏感性。我们发现,几个广泛使用的开源 LLM 对少数镜头设置中提示格式的细微变化极其敏感,使用 LLaMA 2 13B 进行评估时,性能差异高达 76 个精度点。即使增加模型尺寸、少量镜头示例的数量或执行指令调整,灵敏度仍然保持不变。我们的分析表明,使用基于提示的方法评估法学硕士的工作将受益于跨合理的提示格式报告一系列绩效,而不是目前以单一格式报告绩效的标准做法。我们还表明,格式性能在模型之间的相关性很弱,这使得将模型与任意选择的固定提示格式进行比较的方法有效性受到质疑。为了促进系统分析,我们提出了 FormatSpread,这是一种算法,可以快速评估给定任务的一组看似合理的提示格式样本,并报告预期性能的区间,而无需访问模型权重。 |
| Utilising a Large Language Model to Annotate Subject Metadata: A Case Study in an Australian National Research Data Catalogue Authors Shiwei Zhang, Mingfang Wu, Xiuzhen Zhang 为了支持开放和可重复的研究,可供研究的数据集数量迅速增加。随着数据集可用性的增加,拥有高质量的元数据来发现和重用它们变得更加重要。然而,由于数据管理资源有限,数据集往往缺乏高质量的元数据,这是一个常见的问题。与此同时,人工智能和大语言模型LLM等技术正在迅速发展。最近,基于这些技术的系统(例如 ChatGPT)已经在某些数据管理任务中展示了有前景的功能。本文建议通过基于上下文学习的法学硕士,利用法学硕士对主题元数据进行经济有效的注释。我们的方法采用 GPT 3.5,并带有为注释主题元数据而设计的提示,展示了自动元数据注释的良好性能。然而,基于情境学习的模型无法获取学科特定规则,导致在多个类别中表现较低。这种限制源于可用于主题推理的上下文信息有限。 |
| QADYNAMICS: Training Dynamics-Driven Synthetic QA Diagnostic for Zero-Shot Commonsense Question Answering Authors Haochen Shi, Weiqi Wang, Tianqing Fang, Baixuan Xu, Wenxuan Ding, Xin Liu, Yangqiu Song 零样本常识问答 QA 要求模型能够推理超出特定基准的一般情况。最先进的方法是对由常识知识库 CSKB 构建的 QA 对进行微调语言模型,以便在 QA 环境中为模型配备更多常识知识。然而,当前的 QA 合成协议可能会引入来自 CSKB 的噪声,并生成不符合语法的问题和假阴性选项,从而阻碍模型的泛化能力。为了解决这些问题,我们提出了 QADYNAMICS,这是一种用于 QA 诊断和细化的训练动态驱动框架。我们的方法分析了每个 QA 对在问题级别和选项级别的训练动态,通过删除无信息的 QA 对和错误标记或假阴性选项来丢弃机器可检测的工件。大量的实验证明了我们的方法的有效性,该方法在仅使用 33 个合成数据的情况下优于所有基线,甚至包括 ChatGPT 等法学硕士。此外,专家评估证实我们的框架显着提高了 QA 合成的质量。 |
| ChapGTP, ILLC's Attempt at Raising a BabyLM: Improving Data Efficiency by Automatic Task Formation Authors Jaap Jumelet, Michael Hanna, Marianne de Heer Kloots, Anna Langedijk, Charlotte Pouw, Oskar van der Wal 我们在严格的小赛道上展示了阿姆斯特丹大学的 ILLC 在 2023 年向 BabyLM 挑战 Warstadt 等人提交的作品。我们的最终模型 ChapGTP 是一个掩码语言模型,在一种称为“自动任务形成”的新型数据增强技术的帮助下,经过 200 个时期的训练。我们详细讨论了该模型在 BLiMP、Super GLUE 和 MSGS 三个评估套件上的性能。 |
| xMEN: A Modular Toolkit for Cross-Lingual Medical Entity Normalization Authors Florian Borchert, Ignacio Llorca, Roland Roller, Bert Arnrich, Matthieu P. Schapranow |
| Emulating Human Cognitive Processes for Expert-Level Medical Question-Answering with Large Language Models Authors Khushboo Verma, Marina Moore, Stephanie Wottrich, Karla Robles L pez, Nishant Aggarwal, Zeel Bhatt, Aagamjit Singh, Bradford Unroe, Salah Basheer, Nitish Sachdeva, Prinka Arora, Harmanjeet Kaur, Tanupreet Kaur, Tevon Hood, Anahi Marquez, Tushar Varshney, Nanfu Deng, Azaan Ramani, Pawanraj Ishwara, Maimoona Saeed, Tatiana L pez Velarde Pe a, Bryan Barksdale, Sushovan Guha, Satwant Kumar 为了满足医疗保健领域对先进临床问题解决工具的迫切需求,我们推出了 BooksMed,这是一种基于大型语言模型 LLM 的新颖框架。 BooksMed 独特地模拟人类认知过程,利用 GRADE 推荐、评估、开发和评价框架来有效量化证据强度,提供基于证据的可靠响应。为了适当评估临床决策,需要经过临床调整和验证的评估指标。作为解决方案,我们推出了 ExpertMedQA,这是一个多专业临床基准,由开放式专家级临床问题组成,并由不同的医疗专业人员团队进行验证。通过要求对最新临床文献的深入理解和批判性评估,ExpertMedQA 严格评估法学硕士的表现。 BooksMed 在各种医疗场景中均优于现有最先进的模型 Med PaLM 2、Almanac 和 ChatGPT。 |
| Utilizing Weak Supervision To Generate Indonesian Conservation Dataset Authors Mega Fransiska, Diah Pitaloka, Saripudin, Satrio Putra, Lintang Sutawika 为了满足加速 NLP 开发日益增长的需求,弱监督已成为快速和大规模数据集创建的一种有前景的方法。通过利用标签功能,弱监督允许从业者通过创建生成软标签数据集的学习标签模型来快速生成数据集。本文旨在展示如何利用这种方法从保护新闻文本构建印度尼西亚 NLP 数据集。我们构建了两种类型的数据集:多类分类和情感分类。然后,我们使用各种预训练语言模型提供基线实验。这些基线结果表明,情绪分类的测试性能为 59.79 准确度,F1 得分为 55.72,宏观 F1 得分为 66.87,微观 F1 得分为 71.5,多类分类的 ROC AUC 为 83.67。 |
| Revealing the Unwritten: Visual Investigation of Beam Search Trees to Address Language Model Prompting Challenges Authors Thilo Spinner, Rebecca Kehlbeck, Rita Sevastjanova, Tobias St hle, Daniel A. Keim, Oliver Deussen, Andreas Spitz, Mennatallah El Assady 生成语言模型的日益普及增强了人们对指导模型输出的交互方法的兴趣。及时细化被认为是这些方法中影响输出的最有效手段之一。我们确定了与促进大型语言模型相关的几个挑战,分为数据和模型特定的、语言的和社会语言的挑战。为了解决这些问题,需要对模型输出进行全面检查,包括亚军候选者及其相应的概率。波束搜索树是对模型输出进行采样的流行算法,本质上可以提供此信息。因此,我们引入了一种交互式视觉方法来研究集束搜索树,以便于分析模型在生成过程中做出的决策。我们定量地展示了波束搜索树的价值,并提出了五个详细的分析场景来解决已识别的挑战。 |
| Entity Matching using Large Language Models Authors Ralph Peeters, Christian Bizer 实体匹配是确定两个实体描述是否引用同一现实世界实体的任务。实体匹配是大多数数据集成管道中的核心步骤,也是许多需要匹配来自不同供应商的产品的电子商务应用程序的推动者。最先进的实体匹配方法通常依赖于预先训练的语言模型 PLM,例如 BERT 或 RoBERTa。这些实体匹配模型的两个主要缺点是:i 模型需要大量特定于任务的训练数据;ii 微调模型对于分布实体外并不稳健。在本文中,我们研究使用大型语言模型 LLM 进行实体匹配,将其作为对特定领域训练数据依赖较少且比基于 PLM 的匹配器更稳健的替代方案。我们的研究涵盖了托管的 LLM,例如 GPT3.5 和 GPT4,以及基于 Llama2 的可以在本地运行的开源 LLM。我们在零样本场景以及特定任务训练数据可用的场景中评估这些模型。我们比较了不同的提示设计以及模型在零样本场景下的提示灵敏度。我们研究 i 上下文演示的选择,ii 匹配规则的生成,以及 iii 在第二个场景中使用跨不同方法的相同训练数据池微调 GPT3.5。我们的实验表明,在五分之三的基准数据集上,没有任何特定于任务的训练数据的 GPT4 的性能优于经过微调的 PLM RoBERTa 和 Ditto,达到了 90 左右的 F1 分数。 |
| Watermarking LLMs with Weight Quantization Authors Linyang Li, Botian Jiang, Pengyu Wang, Ke Ren, Hang Yan, Xipeng Qiu 由于大型语言模型正在以惊人的速度部署,滥用大型语言模型暴露出很高的风险。保护模型权重以避免违反开源大语言模型许可的恶意使用非常重要。本文提出了一种新颖的水印策略,该策略在大型语言模型的量化过程中植入水印,而无需在推理过程中预先定义触发器。当模型在fp32模式下使用时,水印起作用,当模型量化为int8时,水印保持隐藏,这样用户只能推断模型,而无需进一步监督模型的微调。我们成功地将水印植入到开源大型语言模型权重中,包括 GPT Neo 和 LLaMA。 |
| RealBehavior: A Framework for Faithfully Characterizing Foundation Models' Human-like Behavior Mechanisms Authors Enyu Zhou, Rui Zheng, Zhiheng Xi, Songyang Gao, Xiaoran Fan, Zichu Fei, Jingting Ye, Tao Gui, Qi Zhang, Xuanjing Huang 基础模型中关于类人行为的报道越来越多,心理学理论为研究这些行为提供了持久的工具。然而,当前的研究倾向于直接应用这些以人为本的工具,而没有验证其结果的真实性。在本文中,我们介绍了一个框架 RealBehavior,它旨在忠实地描述模型的人形行为。除了简单地测量行为之外,我们的框架还根据可重复性、内部和外部一致性以及普遍性来评估结果的可信度。我们的研究结果表明,简单地应用心理学工具并不能忠实地描述所有类人行为。 |
| KG-GPT: A General Framework for Reasoning on Knowledge Graphs Using Large Language Models Authors Jiho Kim, Yeonsu Kwon, Yohan Jo, Edward Choi 虽然大型语言模型法学硕士在理解和生成非结构化文本方面取得了相当大的进步,但它们在结构化数据中的应用仍未得到充分探索。特别是,使用 LLM 在知识图谱 KG 上执行复杂的推理任务在很大程度上仍然没有受到影响。为了解决这个问题,我们提出了 KG GPT,这是一个利用 LLM 来完成使用 KG 的任务的多用途框架。 KG GPT 包括句子分割、图检索和推理三个步骤,每个步骤分别旨在分割句子、检索相关图组件和得出逻辑结论。我们使用基于 KG 的事实验证和 KGQA 基准来评估 KG GPT,该模型表现出有竞争力和稳健的性能,甚至优于几个完全监督的模型。 |
| Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations Authors Shiyuan Huang, Siddarth Mamidanna, Shreedhar Jangam, Yilun Zhou, Leilani H. Gilpin ChatGPT 等大型语言模型法学硕士在情感分析、数学推理和总结等各种自然语言处理 NLP 任务上表现出了卓越的性能。此外,由于这些模型是根据人类对话进行调整以产生有用的响应的指令,因此它们可以并且经常会在响应的同时产生解释,我们称之为自我解释。例如,在分析电影评论的情感时,模型不仅可以输出情感的积极性,还可以输出解释,例如通过在评论中列出诸如“精彩”和“难忘”等充满情感的单词。这些自动生成的自我解释效果如何?在本文中,我们研究了情感分析任务和特征归因解释的问题,这是 ChatGPT 之前模型的可解释性文献中最常研究的设置之一。具体来说,我们研究了不同的方法来引出自我解释,在一组评估指标上评估它们的忠实度,并将它们与传统的解释方法(例如遮挡或 LIME 显着图)进行比较。通过大量的实验,我们发现 ChatGPT 的自我解释与传统的自我解释性能相当,但根据各种协议指标,与传统的自我解释有很大不同,同时由于它们是与预测一起生成的,因此生产成本要低得多。 |
| Medical Text Simplification: Optimizing for Readability with Unlikelihood Training and Reranked Beam Search Decoding Authors Lorenzo Jaime Yu Flores, Heyuan Huang, Kejian Shi, Sophie Chheang, Arman Cohan 文本简化已成为人工智能越来越有用的应用,用于弥合医学等专业领域的沟通差距,这些领域的词汇通常以技术术语和复杂的结构为主。尽管取得了显着的进展,但医学简化方法有时会导致生成的文本质量和多样性较低。在这项工作中,我们探索进一步提高医学领域文本简化可读性的方法。我们提出 1 一种新的似然性损失,鼓励生成更简单的术语;2 一种重新排序的波束搜索解码方法,该方法针对简单性进行了优化,从而在三个数据集上的可读性指标上实现了更好的性能。 |
| ViSoBERT: A Pre-Trained Language Model for Vietnamese Social Media Text Processing Authors Quoc Nam Nguyen, Thang Chau Phan, Duc Vu Nguyen, Kiet Van Nguyen 英语和汉语被称为资源丰富的语言,见证了用于自然语言处理任务的基于 Transformer 的语言模型的强劲发展。尽管越南有大约 1 亿人说越南语,但一些预先训练的模型,例如 PhoBERT、ViBERT 和 vELECTRA,在一般越南语 NLP 任务上表现良好,包括词性标注和命名实体识别。这些预先训练的语言模型仍然仅限于越南社交媒体任务。在本文中,我们提出了第一个针对越南社交媒体文本的单语预训练语言模型 ViSoBERT,该模型使用 XLM R 架构在高质量和多样化的越南社交媒体文本的大规模语料库上进行预训练。此外,我们还针对越南社交媒体文本情感识别、仇恨言论检测、情感分析、垃圾邮件评论检测和仇恨言论跨度检测等五个重要的自然语言下游任务探索了我们的预训练模型。我们的实验表明,ViSoBERT 在多个越南社交媒体任务上,参数少得多,超越了之前最先进的模型。 |
| IMTLab: An Open-Source Platform for Building, Evaluating, and Diagnosing Interactive Machine Translation Systems Authors Xu Huang, Zhirui Zhang, Ruize Gao, Yichao Du, Lemao Liu, Gouping Huang, Shuming Shi, Jiajun Chen, Shujian Huang 我们推出了 IMTLab,一个开源的端到端交互式机器翻译 IMT 系统平台,使研究人员能够使用最先进的模型快速构建 IMT 系统,执行端到端评估并诊断系统的弱点。 IMTLab 将整个交互式翻译过程视为与循环环境中的人类进行面向任务的对话,其中可以明确地纳入人类干预以产生高质量、无错误的翻译。为此,设计了通用通信接口来支持灵活的IMT架构和用户策略。基于所提出的设计,我们构建了一个模拟和真实的交互环境来实现端到端评估,并利用该框架系统地评估以前的IMT系统。 |
| Probing the Creativity of Large Language Models: Can models produce divergent semantic association? Authors Honghua Chen, Nai Ding 大型语言模型具有卓越的语言处理能力,但目前尚不清楚这些模型是否可以进一步生成创意内容。本研究旨在通过认知视角研究大语言模型的创造性思维。我们利用发散关联任务 DAT,这是一种客观的创造力测量方法,要求模型生成不相关的单词并计算它们之间的语义距离。我们比较不同模型和解码策略的结果。我们的研究结果表明 1 当使用贪婪搜索策略时,GPT 4 的表现优于 96 名人类,而 GPT 3.5 Turbo 则超过了人类的平均水平。 2 随机采样和温度缩放可以有效地为除 GPT 4 之外的模型获得更高的 DAT 分数,但面临创造力和稳定性之间的权衡。 |
| The Quo Vadis of the Relationship between Language and Large Language Models Authors Evelina Leivada, Vittoria Dentella, Elliot Murphy 在人工智能领域,依赖大型语言模型法学硕士的自然语言处理 NLP 活动的最新进展鼓励了法学硕士作为语言的科学模型的采用。虽然用于描述法学硕士特征的术语有利于它们本身的拥抱,但尚不清楚它们是否能够提供对其寻求代表的目标系统的见解。在确定了采用缺乏透明度的科学模型所带来的最重要的理论和经验风险后,我们讨论了法学硕士,将它们与每个科学模型的基本组成部分(对象、媒介、意义和用户)联系起来。 |
| Long-form Simultaneous Speech Translation: Thesis Proposal Authors Peter Pol k 同步语音翻译 SST 旨在提供口语的实时翻译,甚至在说话者说完句子之前也是如此。传统上,SST 主要通过级联系统来解决,这些系统将任务分解为子任务,包括语音识别、分割和机器翻译。然而,深度学习的出现引发了人们对端到端端到端系统的极大兴趣。然而,当前文献中报道的大多数 E2E SST 方法的一个主要限制是,它们假设源语音被预先分割成句子,这对于实际的、现实世界的应用来说是一个重大障碍。本论文提案解决了端到端同步语音翻译问题,特别是在长格式设置中,即没有预分割的情况下。 |
| Experimenting AI Technologies for Disinformation Combat: the IDMO Project Authors Lorenzo Canale, Alberto Messina 意大利数字媒体观察站 IDMO 项目是欧洲倡议的一部分,重点打击虚假信息和假新闻。本报告概述了 Rai CRITS 对该项目的贡献,包括 i 创建用于测试技术的新颖数据集 ii 开发用于对 Pagella Politica 判决进行分类的自动模型,以促进更广泛的分析 iii 创建用于以极高的准确性识别文本蕴涵的自动模型 |
| In-Context Few-Shot Relation Extraction via Pre-Trained Language Models Authors Yilmazcan Ozyurt, Stefan Feuerriegel, Ce Zhang 关系提取旨在从文本文档中推断结构化的人类知识。基于语言模型的最先进的方法通常有两个局限性:1它们需要将命名实体作为输入给出或推断它们,这会引入额外的噪声;2它们需要人工对文档进行注释。作为一种补救措施,我们提出了一种新颖的框架,通过预先训练的语言模型来提取上下文中的少量镜头关系。据我们所知,我们是第一个将关系提取任务重新制定为上下文中量身定制的少镜头学习范式的人。因此,我们获得了至关重要的好处,因为我们消除了对命名实体识别和文档人工注释的需要。与基于微调的现有方法不同,我们的框架非常灵活,因为它可以轻松更新一组新的关系,而无需重新训练。我们使用 DocRED(用于文档级关系提取的最大的公开可用数据集)评估我们的框架,并证明我们的框架实现了最先进的性能。 |
| Understanding writing style in social media with a supervised contrastively pre-trained transformer Authors Javier Huertas Tato, Alejandro Martin, David Camacho 在线社交网络是有害行为的沃土,从仇恨言论到传播虚假信息。恶意行为者现在拥有前所未有的不当行为自由,导致严重的社会动荡和可怕的后果,美国总统大选期间的国会大厦袭击事件和新冠病毒大流行期间的 Antivaxx 运动等事件就是例证。理解在线语言变得比以往任何时候都更加紧迫。虽然现有的工作主要集中在内容分析上,但我们的目标是通过将内容与各自的作者联系起来,将重点转向理解有害行为。许多新颖的方法试图学习文本中作者的风格特征,但其中许多方法受到小数据集或次优训练损失的限制。为了克服这些限制,我们引入了作者身份表示的风格转换器 STAR ,它在一个大型语料库上进行了训练,该语料库源自公共来源的 4.5 x 10 6 创作文本,涉及 70k 异质作者。我们的模型利用监督对比损失来教导模型最小化同一个人撰写的文本之间的距离。作者借口预训练任务在归因和聚类方面的 PAN 挑战中以零射击的方式产生了有竞争力的性能。此外,我们使用单个密集层在 PAN 验证挑战中取得了有希望的结果,我们的模型充当嵌入编码器。最后,我们在 Reddit 上展示测试分区的结果。使用包含 512 个标记的 8 个文档的支持库,我们可以从最多 1616 个作者的集合中识别作者,准确度至少为 80。 |
| Learning from Red Teaming: Gender Bias Provocation and Mitigation in Large Language Models Authors Hsuan Su, Cheng Chu Cheng, Hua Farn, Shachi H Kumar, Saurav Sahay, Shang Tse Chen, Hung yi Lee 最近,随着 ChatGPT 和 GPT 4 等大型语言模型 LLM 的进步,研究人员在对话系统方面取得了相当大的改进。这些基于 LLM 的聊天机器人对潜在的偏见进行了编码,同时保留了在交互过程中可能伤害人类的差异。传统的偏见调查方法通常依赖于人工编写的测试用例。然而,这些测试用例通常昂贵且有限。在这项工作中,我们提出了第一种自动生成测试用例来检测法学硕士潜在性别偏见的方法。我们将我们的方法应用于三个著名的法学硕士,发现生成的测试用例可以有效地识别偏差的存在。为了解决所识别的偏差,我们提出了一种缓解策略,该策略使用生成的测试用例作为上下文学习的演示,以避免参数微调的需要。 |
| VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System Authors Abdul Waheed, Bashar Talafha, Peter Suvellin, Abdelrahman Elmadney, Muhammad Abdul Mageed 阿拉伯语是一种复杂的语言,有多种变体和方言,全世界有超过 4.5 亿人使用。由于语言的多样性和变化,为阿拉伯语构建一个强大且通用的 ASR 系统具有挑战性。在这项工作中,我们通过开发和演示一个名为 VoxArabica 的系统来解决这一差距,该系统用于方言识别 DID 以及阿拉伯语的自动语音识别 ASR。我们在阿拉伯语 DID 和 ASR 任务的监督环境中训练了各种模型,例如 HuBERT DID、Whisper 和 XLS R ASR。我们的 DID 模型经过训练,可以识别除 MSA 之外的 17 种不同方言。我们根据 MSA、埃及、摩洛哥和混合数据微调我们的 ASR 模型。此外,对于 ASR 中的其余方言,我们提供了在零样本设置中选择各种模型的选项,例如 Whisper 和 MMS。我们将这些模型集成到一个具有多种功能的 Web 界面中,例如录音、文件上传、模型选择以及针对错误输出提出标记的选项。总体而言,我们相信 VoxArabica 对于关注阿拉伯语研究的广大受众来说将是有用的。 |
| Denevil: Towards Deciphering and Navigating the Ethical Values of Large Language Models via Instruction Learning Authors Shitong Duan, Xiaoyuan Yi, Peng Zhang, Tun Lu, Xing Xie, Ning Gu 大型语言模型法学硕士取得了前所未有的突破,但它们日益融入日常生活可能会因生成不道德的内容而增加社会风险。尽管对偏见等具体问题进行了广泛的研究,但从道德哲学的角度来看,法学硕士的内在价值在很大程度上仍未得到探索。这项工作利用道德基础理论深入探讨道德价值观。超越可靠性较差的传统歧视性评估,我们提出了 DeNEVIL,一种新颖的提示生成算法,旨在动态利用 LLM 的价值漏洞,并以生成的方式引发违反道德的行为,揭示其潜在的价值倾向。在此基础上,我们构建了 MoralPrompt,这是一个高质量的数据集,包含 2,397 个提示,涵盖 500 个价值原则,然后对一系列法学硕士的内在价值进行基准测试。我们发现大多数模型本质上都是错位的,因此需要进一步调整道德价值。为此,我们开发了 VILMO,一种上下文对齐方法,通过学习生成适当的价值指令,显着提高 LLM 输出的价值合规性,超越现有竞争对手。 |
| Nonet at SemEval-2023 Task 6: Methodologies for Legal Evaluation Authors Shubham Kumar Nigam, Aniket Deroy, Noel Shallum, Ayush Kumar Mishra, Anup Roy, Shubham Kumar Mishra, Arnab Bhattacharya, Saptarshi Ghosh, Kripabandhu Ghosh 本文介绍了我们向 SemEval 2023 提交的关于 LegalEval 理解法律文本的任务 6 的内容。我们提交的内容集中于三个子任务:任务 B 的法律命名实体识别 L NER、任务 C1 的法律判决预测 LJP 以及任务 C2 的带有解释的法院判决预测 CJPE。我们对这些子任务进行了各种实验,并详细展示了结果,包括数据统计和方法论。值得注意的是,由于对自动化法律分析和支持的需求不断增加,法律任务(例如本研究中处理的任务)变得越来越重要。 |
| Exploring Automatic Evaluation Methods based on a Decoder-based LLM for Text Generation Authors Tomohito Kasahara, Daisuke Kawahara 文本生成的自动评估对于提高生成任务的准确性至关重要。鉴于当前基于解码器的语言模型越来越大的趋势,我们研究了基于此类模型的文本生成自动评估方法。本文比较了各种方法,包括在同等条件下使用基于编码器的模型和大型语言模型进行调整,以日语和英语两种语言进行两种不同的任务,即机器翻译评估和语义文本相似性。实验结果表明,与基于调谐编码器的模型相比,基于调谐解码器的模型性能较差。对此原因的分析表明,基于解码器的模型侧重于表面单词序列,而不是捕获含义。 |
| Reading Order Matters: Information Extraction from Visually-rich Documents by Token Path Prediction Authors Chong Zhang, Ya Guo, Yi Tu, Huan Chen, Jinyang Tang, Huijia Zhu, Qi Zhang, Tao Gui 多模态预训练模型的最新进展显着改进了从视觉丰富的文档 VrDs 中提取信息,其中命名实体识别 NER 被视为预测令牌的 BIO 实体标签的序列标记任务,遵循 NLP 的典型设置。然而,BIO 标记方案依赖于模型输入的正确顺序,而这在现实世界的扫描 VrD 上的 NER 中并不能得到保证,其中文本由 OCR 系统识别和排列。这种阅读顺序问题阻碍了 BIO 标记方案对实体的准确标记,使得序列标记方法无法预测正确的命名实体。为了解决阅读顺序问题,我们引入了令牌路径预测 TPP,这是一个简单的预测头,用于将实体提及预测为文档中的令牌序列。作为令牌分类的替代方案,TPP 将文档布局建模为完整的令牌有向图,并将图中的令牌路径预测为实体。为了更好地评估 VrD NER 系统,我们还提出了两个修订后的扫描文档 NER 基准数据集,它们可以反映现实世界的场景。 |
| Correction Focused Language Model Training for Speech Recognition Authors Yingyi Ma, Zhe Liu, Ozlem Kalinli 语言模型 LM 已被普遍采用来提高自动语音识别 ASR 的性能,特别是在领域适应任务中。传统的 LM 训练方式对语料库中的所有单词一视同仁,导致 ASR 性能的提升不够理想。在这项工作中,我们引入了一种新颖的专注于纠正的 LM 训练方法,旨在优先考虑 ASR 错误单词。单词级 ASR 易错性分数(代表 ASR 错误识别的可能性)被定义并形成为先验单词分布,以指导 LM 训练。为了使用纯文本语料库进行以校正为重点的训练,通过多任务微调,大型语言模型法学硕士被用作易错分数预测器和文本生成器。领域适应任务的实验结果证明了我们提出的方法的有效性。与传统的 LM 相比,以纠正为重点的训练在足够的文本场景下实现了相对 5.5 的单词错误率 WER 降低。 |
| Instructive Dialogue Summarization with Query Aggregations Authors Bin Wang, Zhengyuan Liu, Nancy F. Chen 传统的对话摘要方法直接生成摘要,没有考虑用户的具体兴趣。当用户更关注特定主题或方面时,这会带来挑战。随着指令微调语言模型的进步,我们将指令调整引入到对话中,以扩展对话摘要模型的能力集。为了克服指导性对话摘要数据的稀缺性,我们提出了一种三步方法来合成基于高质量查询的摘要三元组。此过程涉及摘要锚定查询生成、查询过滤和基于查询的摘要生成。通过在具有多目的指导性三元组的三个摘要数据集上训练名为 InstructDS 指导性对话摘要的统一模型,我们扩展了对话摘要模型的能力。我们在四个数据集上评估我们的方法,包括对话摘要和对话阅读理解。实验结果表明,我们的方法优于最先进的模型,甚至优于更大尺寸的模型。 |
| EXMODD: An EXplanatory Multimodal Open-Domain Dialogue dataset Authors Hang Yin, Pinren Lu, Ziang Li, Bin Sun, Kan Li 对高质量数据的需求一直是阻碍对话任务研究的关键问题。最近的研究尝试通过手动、网络爬行和大型预训练模型来构建数据集。然而,人造数据成本高昂,从互联网收集的数据通常包括通用响应、无意义陈述和有毒对话。通过大型模型自动生成数据是一种成本有效的方法,但对于开放域多模态对话任务来说,仍然存在三个缺点 1 目前还没有可以接受多模态输入的开源大型模型 2 模型生成的内容缺乏可解释性 3生成的数据通常难以进行质量控制,并且需要大量资源来收集。为了减轻数据收集方面的大量人力和资源支出,我们提出了多模态数据构建框架MDCF。 MDCF 设计适当的提示来刺激大规模预训练语言模型生成格式良好且令人满意的内容。此外,MDCF还自动为给定图像及其对应的对话提供解释,可以提供一定程度的可解释性,并方便人工后续质量检查。基于此,我们发布了解释性多模态开放域对话数据集 EXMODD 。实验表明,模型生成准确理解的能力与高质量响应之间存在正相关关系。 |
| Semantic-Aware Contrastive Sentence Representation Learning with Large Language Models Authors Huiming Wang, Liying Cheng, Zhaodonghui Li, De Wen Soh, Lidong Bing 对比学习已被证明可以有效地学习更好的句子表示。然而,为了训练对比学习模型,需要大量的标记句子来显式地构建正负对,例如自然语言推理 NLI 数据集中的那些。不幸的是,获取足够的高质量标记数据可能既耗时又耗费资源,这导致研究人员专注于开发学习无监督句子表示的方法。由于这些非结构化随机抽样句子之间没有明确的关系,因此在它们之上构建正负对是棘手且有问题的。为了应对这些挑战,在本文中,我们提出了 SemCSR,一种语义感知对比句子表示框架。通过利用大型语言模型LLM的生成和评估能力,我们可以自动构建高质量的NLI风格语料库,而无需任何人工注释,并进一步将生成的句子对纳入学习对比句子表示模型。 |
| Computing the optimal keyboard through a geometric analysis of the English language Authors Jules Deschamps, Quentin Hubert, Lucas Ryckelynck 在 COMSW4995 002 几何数据分析课程的小组项目中,我们将注意力集中在快速打字键盘的设计上。 |
| A State-Vector Framework for Dataset Effects Authors Esmat Sahak, Zining Zhu, Frank Rudzicz 最近基于深度神经网络 DNN 的系统取得的令人印象深刻的成功很大程度上受到训练中使用的高质量数据集的影响。然而,数据集的影响,特别是它们如何相互作用,仍未得到充分探索。我们提出了一个状态向量框架来实现这个方向的严格研究。该框架使用理想化的探测测试结果作为向量空间的基础。该框架使我们能够量化独立数据集和交互数据集的影响。我们表明,一些常用语言理解数据集的显着影响是有特征的,并且集中在几个语言维度上。此外,我们观察到数据集可能会沿着看似与预期任务无关的维度影响模型的一些溢出效应。 |
| TEQ: Trainable Equivalent Transformation for Quantization of LLMs Authors Wenhua Cheng, Yiyang Cai, Kaokao Lv, Haihao Shen 随着大型语言模型法学硕士变得越来越普遍,人们越来越需要新的和改进的量化方法,这些方法可以满足这些现代架构的计算层需求,同时保持准确性。在本文中,我们提出了 TEQ,一种可训练的等效变换,它保留模型输出的 FP32 精度,同时利用低精度量化,特别是 3 和 4 位仅权重量化。训练过程是轻量级的,仅需要 1K 个步骤,并且少于原始模型可训练参数的 0.1%。此外,转换不会在推理过程中增加任何计算开销。我们的结果与典型法学硕士的最先进的 SOTA 方法相当。我们的方法可以与其他方法相结合,以获得更好的性能。 |
| MASON-NLP at eRisk 2023: Deep Learning-Based Detection of Depression Symptoms from Social Media Texts Authors Fardin Ahsan Sakib, Ahnaf Atef Choudhury, Ozlem Uzuner 抑郁症是一种精神健康疾病,对人们的生活产生深远的影响。最近的研究表明,抑郁症的迹象可以通过个人的沟通方式(无论是通过口头言语还是书面文字)来检测。特别是,社交媒体帖子是丰富且方便的文本来源,我们可以检查其是否有抑郁症状。贝克抑郁量表 BDI 问卷经常用于衡量抑郁的严重程度,是有助于这项研究的一种工具。我们可以将研究范围缩小到仅针对那些症状,因为每个 BDI 问题都与特定的抑郁症状相关。重要的是要记住,并不是每个抑郁症患者都会同时表现出所有症状,而是这些症状的组合。因此,能够确定一个句子或一段用户生成的内容是否与特定条件相关是非常有用的。考虑到这一点,eRisk 2023 任务 1 旨在准确评估 BDI 调查问卷中概述的不同句子与抑郁症状的相关性。这份报告是关于我们的 Mason NLP 团队如何参与这个子任务的,其中涉及识别与不同抑郁症状相关的句子。我们使用了结合 MentalBERT、RoBERTa 和 LSTM 的深度学习方法。尽管我们付出了努力,评估结果仍低于预期,这凸显了从有关抑郁症的广泛数据集中对句子进行排序所固有的挑战,这需要适当的方法选择和大量的计算资源。 |
| Intent Detection and Slot Filling for Home Assistants: Dataset and Analysis for Bangla and Sylheti Authors Fardin Ahsan Sakib, A H M Rezaul Karim, Saadat Hasan Khan, Md Mushfiqur Rahman 随着语音助手巩固其在技术先进社会中的地位,仍然需要迎合多样化的语言环境,包括低资源语言的口语形式。我们的研究引入了第一个用于正式孟加拉语、口语孟加拉语和 Sylheti 语言的意图检测和槽位填充的综合数据集,共有 984 个样本,涉及 10 个独特的意图。我们的分析揭示了大型语言模型在处理数据不足的下游任务时的鲁棒性。 |
| Enhanced Transformer Architecture for Natural Language Processing Authors Woohyeon Moon, Taeyoung Kim, Bumgeun Park, Dongsoo Har Transformer 是自然语言处理 NLP 领域最先进的模型。目前的 NLP 模型主要是增加 Transformer 的数量来提高处理性能。然而,这种技术需要大量的训练资源,例如计算能力。本文提出了一种新颖的 Transformer 结构。它具有全层归一化、加权残差连接、利用强化学习的位置编码和零掩蔽自注意力。所提出的 Transformer 模型称为增强型 Transformer,通过使用 Multi30k 翻译数据集获得的双语评估学生 BLEU 分数进行了验证。 |
| Spatial HuBERT: Self-supervised Spatial Speech Representation Learning for a Single Talker from Multi-channel Audio Authors Antoni Dimitriadis, Siqi Pan, Vidhyasaharan Sethu, Beena Ahmed 自监督学习已被用来利用未标记的数据,通过表示模型的训练来提高语音系统的准确性和泛化性。虽然最近的许多工作都试图在各种声学领域、语言、模式甚至同时说话者之间产生有效的表示,但这些研究都仅限于单通道录音。本文提出了 Spatial HuBERT,这是一种自监督语音表示模型,它通过使用多通道音频输入来学习潜在噪声环境中单个说话者的声学和空间信息。 Spatial HuBERT 学习的表示在各种空间下游任务上优于最先进的单通道语音表示,特别是在混响和噪声环境中。我们还演示了 Spatial HuBERT 学习到的表示在语音定位下游任务中的实用性。 |
| NuclearQA: A Human-Made Benchmark for Language Models for the Nuclear Domain Authors Anurag Acharya, Sai Munikoti, Aaron Hellinger, Sara Smith, Sridevi Wagle, Sameera Horawalavithana 随着法学硕士变得越来越受欢迎,它们几乎被应用于各个领域。但随着法学硕士的申请从通用领域扩展到狭窄的、集中的科学领域,评估其在这些领域的功效的方法之间存在着越来越大的差距。对于确实存在的基准,其中很多都关注不需要正确理解相关主题的问题。在本文中,我们提出了 NuclearQA,这是一个由 100 个问题组成的人工基准,用于评估核领域的语言模型,其中包含由专家专门设计的各种问题集合,用于测试语言模型的能力。我们详细介绍了我们的方法,并展示了几种类型问题的组合如何使我们的基准能够独特地评估核领域的模型。由于现有指标的局限性,我们还提出了自己的评估指标来评估法学硕士的表现。 |
| Emergent AI-Assisted Discourse: Case Study of a Second Language Writer Authoring with ChatGPT Authors Sharin Jacob, Tamara Tate, Mark Warschauer ChatGPT 的迅速扩散引发了关于其对人类写作影响的争论。出于对写作标准下降的担忧,本研究调查了 ChatGPT 在促进学术写作(尤其是语言学习者的学术写作)方面的作用。本研究采用案例研究方法,探讨了博士生 Kailing 将 ChatGPT 融入到学术写作过程中的经历。该研究采用活动理论作为理解生成人工智能工具写作的镜头,分析的数据包括半结构化访谈、写作样本和 GPT 日志。结果表明,Kailing 在各个写作阶段与 ChatGPT 进行了有效合作,同时保留了她独特的作者声音和代理权。这凸显了 ChatGPT 等人工智能工具在增强语言学习者学术写作而不掩盖个人真实性方面的潜力。 |
| IDEAL: Influence-Driven Selective Annotations Empower In-Context Learners in Large Language Models Authors Shaokun Zhang, Xiaobo Xia, Zhaoqing Wang, Ling Hao Chen, Jiale Liu, Qingyun Wu, Tongliang Liu 上下文学习是一种很有前途的范式,它利用上下文示例作为大型语言模型预测的提示。这些提示对于实现出色的绩效至关重要。然而,由于提示需要从大量带注释的示例中采样,找到正确的提示可能会导致较高的注释成本。为了应对这一挑战,本文引入了一种影响驱动的选择性注释方法,旨在最大限度地减少注释成本,同时提高上下文示例的质量。我们方法的本质是从大规模未标记数据池中选择一个关键子集来注释后续的提示采样。具体来说,首先构建有向图来表示未标记的数据。随后,通过扩散过程量化候选未标记子集的影响。最后介绍了一种简单而有效的无标签数据选择贪心算法。如果数据在量化影响方面提供了最大边际增益,则它会迭代地选择数据。与之前选择性注释的努力相比,我们的影响力驱动方法以端到端的方式工作,避免了数据多样性和代表性之间棘手的显式平衡,并享有理论支持。实验证实了所提出的方法在各种基准上的优越性,在子集选择过程中以较低的时间消耗实现了更好的性能。 |
| Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts Authors Christina Chance, Da Yin, Dakuo Wang, Kai Wei Chang 最近的研究表明,传统童话故事中充斥着有害的性别偏见。为了帮助减轻童话故事中的这些性别偏见,这项工作旨在通过评估语言模型对性别扰动的鲁棒性来评估语言模型的习得偏见。具体来说,我们专注于童话故事中的问答 QA 任务。使用 FairytaleQA 数据集的反事实数据增强,我们根据交换的性别特征信息评估模型的稳健性,然后通过在训练期间引入反事实的性别刻板印象来减轻学习偏差。我们还引入了一种新颖的方法,利用语言模型的大量词汇来支持童话故事之外的文本类型。我们的实验结果表明,模型对性别扰动敏感,与原始测试集相比,性能显着下降。 |
| CoTFormer: More Tokens With Attention Make Up For Less Depth Authors Amirkeivan Mohtashami, Matteo Pagliardini, Martin Jaggi 不断开发更大、更深的基础模型的竞赛正在进行中。然而,思想链 CoT 方法等技术在实现最佳下游性能方面继续发挥着关键作用。在这项工作中,我们在使用思想链和采用更深层次的变压器之间建立了近似的平行关系。基于这一见解,我们引入了 CoTFormer,这是一种变压器变体,它采用类似 CoT 的隐式机制来实现与更深层次模型相当的容量。 |
| Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks Authors Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, Nael Abu Ghazaleh 大型语言模型法学硕士在架构和能力方面正在迅速进步,随着它们更深入地集成到复杂系统中,审查其安全属性的紧迫性也越来越大。本文结合自然语言处理和安全的观点,调查了法学硕士对抗性攻击的新兴跨学科领域的研究,法学硕士是值得信赖的机器学习的一个子领域。之前的工作表明,即使是通过指令调整和通过人类反馈进行强化学习来实现安全的法学硕士也可能容易受到对抗性攻击,这些攻击会利用弱点并误导人工智能系统,ChatGPT 和 Bard 等模型上越狱攻击的盛行就证明了这一点。在本次调查中,我们首先概述大型语言模型,描述其安全性,并根据各种学习结构对现有研究进行分类纯文本攻击、多模态攻击以及专门针对复杂系统的其他攻击方法,例如联邦学习或多代理系统。我们还对关注漏洞的根本来源和潜在防御的工作提供全面的评论。为了让新人更容易接触这个领域,我们对现有作品进行了系统回顾、对抗性攻击概念的结构化类型学以及其他资源,包括在计算语言学协会第 62 届年会上相关主题的演示幻灯片 ACL 24 |
| Fake News in Sheep's Clothing: Robust Fake News Detection Against LLM-Empowered Style Attacks Authors Jiaying Wu, Bryan Hooi 人们普遍认为,在线假新闻和可靠新闻在写作风格上表现出明显的差异,例如使用耸人听闻的语言与客观的语言。然而,我们强调,风格相关的特征也可以用于基于风格的攻击。值得注意的是,强大的大型语言模型法学硕士的兴起使恶意用户能够以最小的成本模仿值得信赖的新闻媒体的风格。我们的分析表明,LLM 伪装的假新闻内容会导致最先进的基于文本的检测器的性能大幅下降,F1 分数下降高达 38,这对在线生态系统中的自动检测提出了重大挑战。为了解决这个问题,我们引入了 SheepDog,一种与风格无关的假新闻检测器,对新闻写作风格具有鲁棒性。 SheepDog 通过 LLM 授权的新闻重构实现了这种适应性,它使用面向风格的重构提示定制每篇文章以匹配不同的写作风格。通过采用与风格无关的训练,SheepDog 最大限度地提高了这些不同重构之间的预测一致性,从而增强了其对风格变化的适应能力。此外,SheepDog 从法学硕士中提取以内容为中心的真实性归因,其中新闻内容根据一组事实检查原理进行评估。这些归因提供了有助于准确性预测的补充信息和潜在的可解释性。 |
| SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT Authors Cheol Jun Cho, Abdelrahman Mohamed, Shang Wen Li, Alan W Black, Gopala K. Anumanchipalli 自监督学习中的数据驱动单元发现 SSL 语音开启了口语处理的新时代。然而,发现的单元通常保留在语音空间中,限制了 SSL 表示的实用性。在这里,我们证明了在学习语音的句子级表示时会出现音节组织。特别是,我们采用自蒸馏目标,使用总结整个句子的聚合器令牌来微调预训练的 HuBERT。在没有任何监督的情况下,生成的模型在语音中划出了明确的界限,并且跨帧的表示显示出显着的音节结构。我们证明这种新出现的结构在很大程度上对应于真实的音节。此外,我们提出了一个新的基准任务 Spoken Speech ABX,用于评估语音的句子级表示。与以前的模型相比,我们的模型在无监督音节发现和学习句子级表示方面都表现出色。 |
| BanglaNLP at BLP-2023 Task 1: Benchmarking different Transformer Models for Violence Inciting Text Detection in Bengali Authors Saumajit Saha, Albert Nanda 本文介绍了我们在解决孟加拉语暴力煽动文本检测的共享任务时开发的系统。我们解释了用于模型学习的传统方法和最新方法。我们提出的系统有助于对给定文本是否包含任何威胁进行分类。我们研究了可用数据集有限时数据增强的影响。我们的定量结果表明,与其他基于 Transformer 的架构相比,微调多语言 e5 基本模型在我们的任务中表现最佳。 |
| Towards reducing hallucination in extracting information from financial reports using Large Language Models Authors Bhaskarjit Sarmah, Tianjie Zhu, Dhagash Mehta, Stefano Pasquali 对于财务分析师来说,公司财务报告的问答部分是各种分析和投资决策的重要信息。然而,从问答部分提取有价值的见解提出了相当大的挑战,因为详细阅读和笔记等传统方法缺乏可扩展性并且容易出现人为错误,而光学字符识别 OCR 和类似技术在准确处理非结构化转录文本时遇到困难,往往会忽略影响投资者决策的微妙语言差异。在这里,我们演示了如何利用大型语言模型法学硕士从收益报告笔录中高效快速地提取信息,同时确保高精度地转换提取过程,并通过结合检索增强生成技术和元数据来减少幻觉。 |
| Building Persona Consistent Dialogue Agents with Offline Reinforcement Learning Authors Ryan Shea, Zhou Yu 保持一致的角色是任何开放域对话系统的关键品质。当前最先进的系统通过使用监督学习或在线强化学习 RL 来训练智能体来做到这一点。然而,经过监督学习训练的系统通常缺乏一致性,因为它们永远不会因为提出矛盾而受到惩罚。强化学习的额外训练可以缓解其中一些问题,但训练过程成本高昂。相反,我们提出了一个离线强化学习框架来提高对话系统的角色一致性。我们的框架使我们能够结合以前方法的优点,因为我们可以像监督学习一样在现有数据上廉价地训练我们的模型,同时像强化学习一样惩罚和奖励特定的话语。我们还引入了一种简单的重要性采样方法来减少离线 RL 训练中重要性权重的方差,我们称之为方差减少 MLE 初始化 VaRMI 重要性采样。 |
| Demonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning Authors Anirudh Som, Karan Sikka, Helen Gent, Ajay Divakaran, Andreas Kathol, Dimitra Vergyri 释义攻击性内容是删除内容的更好替代方案,有助于提高沟通环境中的文明程度。然而,受监督的释义者严重依赖大量标记数据来帮助保留含义和意图。它们还保留了原始内容的很大一部分攻击性,这引发了对其整体可用性的质疑。在本文中,我们的目标是通过探索具有大型语言模型 LLM 的上下文学习 ICL 来帮助从业者开发可用的释义器,即使用有限数量的输入标签演示对来指导模型为特定查询生成所需的输出。我们的研究重点关注关键因素,例如演示的数量和顺序、排除即时指导以及测量毒性的降低。我们对三个数据集进行原则性评估,包括我们提出的上下文感知礼貌释义数据集,其中包括对话风格的粗鲁话语、礼貌释义和附加对话上下文。我们使用两个闭源和一个开源法学硕士来评估我们的方法。我们的结果表明,ICL 在生成质量方面与监督方法相当,同时在人体评估中质量提高了 25 倍,并且毒性降低了 76 倍。 |
| Harnessing the Power of LLMs: Evaluating Human-AI text Co-Creation through the Lens of News Headline Generation Authors Zijian Ding, Alison Smith Renner, Wenjuan Zhang, Joel R. Tetreault, Alejandro Jaimes 为了探索人类如何最好地利用法学硕士进行写作,以及与这些模型的交互如何影响写作过程中的所有权感和信任感,我们比较了常见的人类人工智能交互类型,例如引导系统、从系统输出中进行选择、在上下文中进行后期编辑输出法学硕士协助新闻标题生成。虽然仅法学硕士就可以产生令人满意的新闻标题,但平均而言,需要人为控制来修复不需要的模型输出。在交互方法中,引导和选择模型输出是以最低的时间和精力成本获得最大收益的。 |
| Optimized Tokenization for Transcribed Error Correction Authors Tomer Wullach, Shlomo E. Chazan 语音识别系统面临的挑战,例如发音变化、不利的音频条件和标记数据的稀缺,强调了纠正重复错误的后处理步骤的必要性。先前的研究已经证明了采用专用纠错模型的优势,但训练此类模型需要大量不易获得的标记数据。为了克服这一限制,通常使用合成的转录类似数据,然而,弥合转录错误和合成噪声之间的分布差距并非易事。在本文中,我们证明仅使用合成数据进行训练可以显着提高校正模型的性能。具体来说,我们凭经验表明 1 使用从一组转录数据导出的误差分布生成的合成数据优于应用随机扰动的常见方法 2 对 BPE 分词器的词汇应用特定于语言的调整在适应看不见的分布和保留转录错误的知识。 |
| Theory of Mind for Multi-Agent Collaboration via Large Language Models Authors Huao Li, Yu Quan Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Michael Lewis, Katia Sycara 虽然大型语言模型法学硕士在推理和规划方面取得了令人印象深刻的成就,但他们在多智能体协作方面的能力在很大程度上仍未得到探索。本研究通过心智理论 ToM 推理任务评估多智能体协作文本游戏中基于 LLM 的智能体,将它们的性能与多智能体强化学习 MARL 和基于规划的基线进行比较。我们观察到基于法学硕士的代理中出现的协作行为和高阶心智理论能力的证据。我们的结果揭示了基于 LLM 的代理规划优化的局限性,这是由于管理长期上下文的系统失败和对任务状态的幻觉造成的。 |
| Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation Authors Yingwei Ma, Yue Yu, Shanshan Li, Yu Jiang, Yong Guo, Yuanliang Zhang, Yutao Xie, Xiangke Liao 大型语言模型法学硕士在代码生成方面展示了非凡的能力。然而,自动代码生成仍然具有挑战性,因为它需要自然语言需求和代码之间的高级语义映射。大多数现有的基于 LLM 的代码生成方法仅依赖于解码器,因果语言模型通常仅将代码视为纯文本标记,即将需求作为提示输入,并将代码作为平面标记序列输出,可能会丢失源代码中固有的丰富语义特征代码。为了弥补这一差距,本文提出了语义思想链方法来引入代码的语义信息,称为 SeCoT。我们的动机是源代码的语义信息(例如数据流和控制流)描述了更精确的程序执行行为、意图和功能。通过指导LLM考虑和整合语义信息,我们可以实现对代码更细粒度的理解和表示,提高代码生成的准确性。同时,虽然利用此类语义信息的传统技术需要复杂的静态或动态代码分析来获取数据流和控制流等特征,但 SeCoT 表明,该过程可以通过法学硕士的内在功能(即上下文学习)完全自动化,同时具有可推广性并适用于具有挑战性的领域。虽然 SeCoT 可以应用于不同的 LLM,但本文重点关注强大的 GPT 风格模型 ChatGPT 闭源模型和 WizardCoder 开源模型。 |
| Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming from One-Shot Observation Authors Manh Hung Nguyen, Sebastian Tschiatschek, Adish Singla 学生建模是许多教育技术的核心,因为它可以预测未来的学习成果和有针对性的教学策略。然而,由于学生表现出多样化的行为并且缺乏一套明确的学习技能,开放式学习环境对准确建模学生提出了挑战。为了应对这些挑战,我们探索了大型语言模型法学硕士在开放式学习环境中的情境学生建模的应用。我们引入了一个新颖的框架,LLM SS,它利用 LLM 来综合学生的行为。更具体地说,给定特定学生对参考任务的解决尝试作为观察,目标是综合学生对目标任务的尝试。我们的框架可以与不同的法学硕士相结合,此外,我们利用特定领域的专业知识对法学硕士进行微调,以增强他们对领域背景和学生行为的理解。我们使用 StudentSyn 基准评估基于 LLM SS 的几种具体方法,StudentSyn 基准是现有学生在可视化编程中的尝试综合基准。实验结果表明,与 StudentSyn 基准测试中包含的基线方法相比,有显着改进。 |
| A decoder-only foundation model for time-series forecasting Authors Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou 受自然语言处理 NLP 大型语言模型最新进展的推动,我们设计了一种用于预测的时间序列基础模型,其在各种公共数据集上的开箱即用的零样本性能接近最先进的监督预测模型的准确性对于每个单独的数据集。 |
| Autonomous Tree-search Ability of Large Language Models Authors Zheyu Zhang, Zhuorui Ye, Yikang Shen, Chuang Gan 大型语言模型在具有先进提示技术的卓越推理能力方面表现出色,但在需要探索、战略远见和顺序决策的任务方面却表现不佳。最近的工作提出利用外部程序来定义搜索逻辑,以便法学硕士可以执行被动树搜索来解决更具挑战性的推理任务。尽管取得了令人印象深刻的成果,但这些方法仍存在一些基本局限性。首先,被动树搜索效率不高,因为它们通常需要多轮 LLM API 调用才能解决一个问题。此外,被动搜索方法并不灵活,因为它们需要特定于任务的程序设计。那么一个自然的问题是,我们是否可以在不借助外部程序的情况下保持法学硕士的树搜索能力,并且仍然可以生成清晰地展示树结构搜索过程的响应。为此,我们提出了一个称为自主树搜索能力的新概念法学硕士,它可以自动生成包含正确答案搜索轨迹的响应。具体来说,我们通过固定的系统提示使用功能强大的 LLM API 执行搜索轨迹,从而允许他们立即执行自主树搜索 ATS。对 4 个益智游戏的实验表明我们的方法可以取得巨大的改进。 ATS BFS 方法优于思想链方法,平均准确度提高了 33 。与 Tree of Thought 相比,它需要减少 65.6 或 47.7 的 GPT api 成本才能达到相当的准确性水平。此外,我们还使用 ATS 提示方法和微调 LLaMA 收集数据。与根据 CoT 数据进行微调的方法相比,这种方法产生了更大的改进。 |
| Large Language Model Unlearning Authors Yuanshun Yao, Xiaojun Xu, Yang Liu 我们研究如何在大型语言模型法学硕士上进行忘却,即忘记不良行为。我们展示了至少三种使法学硕士与人类偏好保持一致的场景,可以从忘却中受益:1 消除有害反应,2 按要求删除受版权保护的内容,3 消除幻觉。忘却作为一种对齐技术具有三个优点。 1 它只需要负数,例如有害的例子,收集起来更容易、更便宜,例如通过红队或用户报告而不是积极的,例如RLHF RL 中需要来自人类反馈的有用且通常是人类编写的示例。 2 计算效率高。 3 当我们知道哪些训练样本导致不当行为时,这尤其有效。据我们所知,我们的工作是最早探索法学硕士“忘却学习”的工作之一。我们也是最早制定LLM非学习设置、目标和评估的人之一。我们表明,如果从业者的资源有限,因此首要任务是停止产生不需要的输出,而不是尝试产生想要的输出,那么忘却就特别有吸引力。 |
| Large language models can replicate cross-cultural differences in personality Authors Pawe Niszczota, Mateusz Janczak 我们使用大规模实验 N 8000 来确定 GPT 4 是否可以复制大五人格中的跨文化差异(使用十项人格量表进行测量)。我们使用美国和韩国作为文化对,因为之前的研究表明这两个国家的人之间存在巨大的性格差异。我们操纵了模拟美国与韩国的目标、库存英语与韩国的语言以及语言模型 GPT 4 与 GPT 3.5。我们的结果表明,GPT 4 复制了每个因素的跨文化差异。然而,平均评分存在向上偏差,并且表现出比人类样本更低的变异,以及更低的结构有效性。 |
| LLMs as Potential Brainstorming Partners for Math and Science Problems Authors Sophia Gu 随着最近广泛成功的深度学习模型的兴起,各个数学和科学界的专业人士越来越有兴趣了解和评估最先进的模型能力,以协作发现或解决通常需要创造力和头脑风暴的问题。虽然当前的人机智力合作与解决复杂的数学和科学问题(例如六个未解决的千年奖问题)之间仍然存在重大鸿沟,但我们对此事的初步调查揭示了弥合鸿沟的有希望的一步。这是由于大型语言模型法学硕士的最新进展。 |
| Creation Of A ChatBot Based On Natural Language Proccesing For Whatsapp Authors Valderrama Jonatan, Aguilar Alonso Igor 在数字化转型时代,客户服务对于组织的成功至关重要,为了满足对每天 24 小时即时响应和个性化帮助不断增长的需求,聊天机器人已成为解决这些问题的有前途的工具。目前,有很多公司需要向客户提供这些解决方案,这促使我们研究这个问题并提供合适的解决方案。本研究的目的是开发一个基于自然语言处理的聊天机器人,以提高客户满意度并提高公司通过 WhatsApp 提供的服务质量。该解决方案的重点是创建一个能够高效处理用户查询的聊天机器人。我们对现有聊天机器人进行了文献综述,分析了聊天机器人实施中使用的方法论、人工智能技术和质量属性。结果发现,基于自然语言处理的聊天机器人可以实现快速、准确的响应,从而提高客户服务的效率,因为聊天机器人可以随时针对客户的疑问提供准确的答案和快速的解决方案,从而提高客户满意度。一些作者指出,机器学习等人工智能技术可以提高聊天机器人在用户交互时的学习能力和适应性,因此选择适当的自然语言理解技术对于优化聊天机器人的性能至关重要。 |
| Towards Emotion-Based Synthetic Consciousness: Using LLMs to Estimate Emotion Probability Vectors Authors David Sinclair, Willem Pye 本文展示了如何使用法学硕士大型语言模型来估计与文本片段相关的情绪状态的摘要。情绪状态概要是用于描述情绪的单词以及该单词出现在由原文和情绪引发尾部组成的提示之后的概率的字典。通过对亚马逊产品评论的情感分析,我们证明情感描述符可以映射到 PCA 类型空间。希望还可以通过尾部提示引出用于改善当前文本描述状态的操作的文本描述。实验似乎表明这并不容易实现。 |
| Hybrid Quantum-Classical Machine Learning for Sentiment Analysis Authors Abu Kaisar Mohammad Masum, Anshul Maurya, Dhruthi Sridhar Murthy, Pratibha, Naveed Mahmud 量子计算和经典机器学习之间的协作在自然语言处理方面提供了潜在的优势,特别是在对大规模数据集中表达的人类情感和观点进行情感分析方面。在这项工作中,我们提出了一种使用混合量子经典机器学习算法进行情感分析的方法。我们研究量子核方法和基于变分量子电路的分类器,并将它们与经典的降维技术(如 PCA 和 Haar 小波变换)集成。使用基于英语和孟加拉语的两个不同的数据集对所提出的方法进行评估。 |
| Functional Invariants to Watermark Large Transformers Authors Fernandez Pierre, Couairon Guillaume, Furon Teddy, Douze Matthijs 基于变压器的模型的快速增长增加了对其完整性和所有权保险的担忧。水印通过在模型中嵌入唯一标识符来解决此问题,同时保留其性能。然而,大多数现有方法需要优化权重来印记水印信号,由于计算成本,这不适合大规模使用。本文探索了几乎没有计算成本的水印,适用于假设可以访问原始网络和水印网络的非盲白盒设置。他们通过利用模型不变性,通过维度排列或缩放取消缩放等操作来生成功能等效的副本。这使得可以在不改变模型输出的情况下对模型加水印,并且保持隐秘性。 |
| Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V Authors Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, Jianfeng Gao 我们提出了 Set of Mark SoM,一种新的视觉提示方法,以释放大型多模态模型 LMM(例如 GPT 4V)的视觉基础能力。如图 1 右所示,我们采用现成的交互式分割模型(例如 SAM)将图像划分为不同粒度级别的区域,并用一组标记(例如字母数字、掩码、框)覆盖这些区域。使用标记的图像作为输入,GPT 4V 可以回答需要视觉基础的问题。我们进行了全面的实证研究,以验证 SoM 在各种细粒度视觉和多模态任务上的有效性。 |
| Robust Wake-Up Word Detection by Two-stage Multi-resolution Ensembles Authors Fernando L pez, Jordi Luque, Carlos Segura, Pablo G mez 基于语音的接口依靠唤醒词机制来发起与设备的通信。然而,实现稳健、节能且快速的检测仍然是一个挑战。本文通过时间对齐增强数据并使用基于多分辨率两阶段的检测来满足这些实际生产需求。它采用两种模型,一种是用于实时处理音频流的轻量级设备模型,另一种是服务器端的验证模型,它是细化检测的异构架构的集合。该方案允许优化两个操作点。为了保护隐私,音频功能而不是原始音频被发送到云端。该研究研究了用于特征提取的不同参数配置,以选择一种用于设备检测,另一种用于验证模型。此外,还对十三种不同的音频分类器的性能和推理时间进行了比较。 |
| CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion Authors Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, Bing Xiang 近年来,代码完成模型取得了重大进展,但当前流行的评估数据集(例如 HumanEval 和 MBPP)主要关注单个文件中的代码完成任务。 |
| Lyricist-Singer Entropy Affects Lyric-Lyricist Classification Performance Authors Mitsuki Morita, Masato Kikuchi, Tadachika Ozono 尽管歌词是音乐的重要组成部分,但很少有关于作词者特征的音乐信息处理研究。由于这些特征对于音乐应用(例如推荐)可能很有价值,因此值得进一步研究。我们考虑了一种潜在的方法,可以从歌词中提取代表作词者特征的特征。由于必须在提取之前识别这些特征,因此我们重点关注具有易于识别特征的作词者。我们相信歌手们需要表演具有该歌手特定特征的独特歌曲。因此,我们假设作词者解释了他们为其写歌词的歌手的独特特征。换句话说,作词者分类表现或从歌词中捕捉作词者特征的容易程度可能取决于歌手的多样性。在这项研究中,我们观察了词作者熵或与单个词作者和词词作者分类表现相关的歌手种类之间的关系。举个例子,当作词者只为一位歌手写歌词时,作词者歌手的熵最小。在我们的实验中,我们根据作词歌手熵将作词者分为五组,并评估每组内的作词者分类表现。因此,作词歌手熵最低的组获得了最好的 F1 分数。 |
| Self-Supervised Models of Speech Infer Universal Articulatory Kinematics Authors Cheol Jun Cho, Abdelrahman Mohamed, Alan W Black, Gopala K. Anumanchipalli 基于自我监督学习 SSL 的语音模型在一系列下游任务中表现出了卓越的性能。这些最先进的模型仍然是黑匣子,但最近的许多研究已经开始探索像 HuBERT 这样的模型,将它们的内部表征与语音的不同方面联系起来。在本文中,我们展示了发音运动学作为 SSL 模型的基本属性的推断,即这些模型将声学转换为语音信号背后的因果发音动力学的能力。我们还表明,这种抽象在用于训练模型的数据语言中很大程度上重叠,优先于具有类似语音系统的语言。此外,我们表明,通过简单的仿射变换,声学到发音反转 AAI 可以在说话者之间转移,甚至可以跨性别、语言和方言转移,这表明了该属性的普遍性。 |
| BiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys Authors Yu Gu, Jianwei Yang, Naoto Usuyama, Chunyuan Li, Sheng Zhang, Matthew P. Lungren, Jianfeng Gao, Hoifung Poon 使用自然语言指令进行图像编辑的指令学习已经取得了快速进展,InstructPix2Pix就是一个例子。在生物医学中,此类方法可应用于反事实图像生成,这有助于区分因果结构与虚假相关性,并促进疾病进展建模的稳健图像解释。然而,通用图像编辑模型不适合生物医学领域,并且反事实生物医学图像生成在很大程度上尚未得到充分探索。在本文中,我们提出了 BiomedJourney,这是一种通过从多模式患者旅程中学习指令来生成反事实生物医学图像的新方法。给定一名患者在不同时间点拍摄的两张生物医学图像,我们使用 GPT 4 处理相应的成像报告并生成疾病进展的自然语言描述。然后使用所得的三元组先前图像、进展描述、新图像来训练用于反事实生物医学图像生成的潜在扩散模型。考虑到图像时间序列数据的相对稀缺性,我们引入了一个两阶段课程,首先使用更丰富的单图像报告对和虚拟先验图像对去噪网络进行预训练,然后使用反事实三元组继续训练。使用标准 MIMIC CXR 数据集的实验证明了我们方法的前景。在对反事实医学图像生成的一系列全面测试中,BiomedJourney 在指令图像编辑和医学图像生成方面远远优于现有的最先进方法,例如 InstructPix2Pix 和 RoentGen。 |
| Defining implication relation for classical logic Authors Li Fu 在经典逻辑中, P 意味着 Q 等价于 not P 或 Q 。众所周知,等价性是有问题的。实际上,从 P 蕴含 Q ,不能推断出 P 或 Q 蕴涵对析取是有效的,而从 not P 或 Q 中,P 蕴含 Q 不能一般地推断出 析取蕴涵不是一般有效的,因此它们之间的等价是无效的一般来说。这项工作的目的是准确地消除经典逻辑 CL 中不正确的蕴涵析取。本文提出了一种具有预期属性的逻辑系统 IRL 1 CL 可以通过将蕴含析取简单地添加到 IRL 中获得,并且 2 蕴含析取独立于 IRL,一般情况下,在 IRL 中不能导出蕴含析取或其否定。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com