一共16日的练习,分为选择题与编程题,涵盖了C语言所学以及数据结构的重点,以及一些秋招、春招面试的高频考点,难度会随着天数而上升。1-8day为C语言,9-16day为数据结构。
(建议在电脑客户端进行,将鼠标选中被遮挡的地方,即可看到解析。)
专栏放在:【C语言】经典题目
选择题
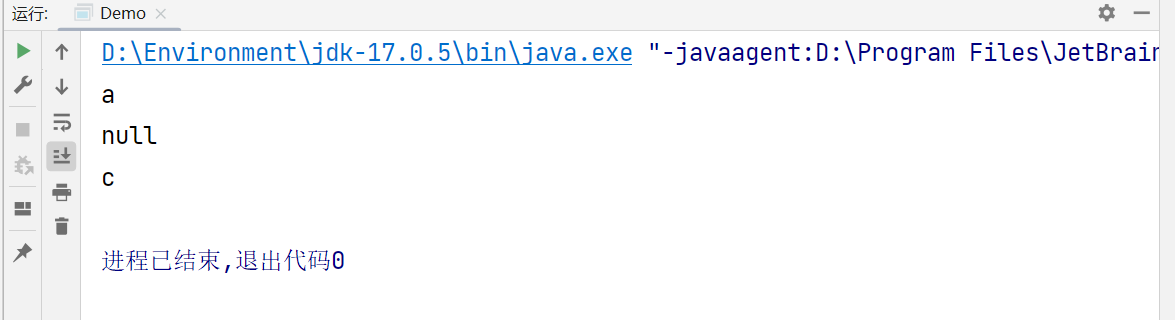
1、以下代码执行后的输出结果为:
#include <stdio.h>
void fun(char **p)
{
int i;
for(i = 0; i < 4; i++)
printf("%s", p[i]);
} in
t main()
{
char *s[6] = {"ABCD", "EFGH", "IJKL", "MNOP", "QRST", "UVWX"};
fun(s);
printf("\n");
return 0;A、ABCDEFGHIJKL B、ABCD C、AEIM D、ABCDEFGHIGKLMNOP
答案:->D
解析:首先我们要知道,s是一个指针数组共6个元素,元素类型为char*,fun(s),这里s表示数组首元素的地址,指针的地址,所以用二级指针接收,而数组首元素在这里指的是“ABCD”的首字符,p+1也就是s+1,即指向“EFGH”的‘E’,而打印一个字符串时知道该字符串的首字符便可以打印出来完整的该字符串,因此这里会打印出ABCDEFGHIJKLMNOP
2、数组 a 的定义为: int a[3][4]; 下面哪个不能表示 a[1][1]?
A、*(&a[0][0]+5) B、*(*(a+1)+1) C、*(&a[1]+1) D、*(a[1]+1)
答案:->C
解析:首先,A选项,二维数组在内存中的存储它的地址也是连续的,所以a[ 1 ] [ 1 ]与a[ 0 ][ 0 ]之间隔了五个int,所以a[ 0 ][ 0 ]的地址+5后就是a[ 1 ][ 1 ]的地址,再解引用进行访问。B与D选项表示的是同一个意思,a[ 1 ]就等价于*(a+1),表示指向a的下一行,再+1表示指向下一列,B和D都可以写为a[ 1 ][ 1 ]. C选项,&a[ 1 ]表示的是取出整个这一行的地址,+1跳过整个一行,指向下一行,即指向a[ 2 ]这一整行,与题意不符,因此选C。
3、void (*s[5])(int) 表示意思为
A、函数指针 B、函数指针数组 C、数组指针函数 D、语法错误
答案:-> B
解析:[]优先级高于*,因此s与[]结合,说明s是一个数组,数组共5个元素,去掉数组名表示数组元素类型,这里为void(*)(int),即函数指针类型,该函数指针指向的函数返回值为void,参数类型为int,因此选B,函数指针数组。
4、在64位机器下,下面程序的运行结果:
#include<stdio.h>
int main()
{
int* k[10][30];
printf("%d\n", sizeof(k));
return 0;
}A、4 B、8 C、1200 D、2400
答案:->C
解析:这道题可能有的铁子一看,64位机器,k还是指针,直接选B,但其实忽略了一点,sizeof(数组名),这里表示的是整个数组的大小,不能被64位机器给蒙蔽了双眼,一共10*30=300个元素,元素类型位int*,这是一个二维的指针数组。因此选C
5、假设函数原型和变量说明如下,则调用合法的是( )
void f(int **p);
int a[4]={1,2,3,4};
int b[3][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
int *q[3]={b[0],b[1],b[2]};A、f(a) B、f(b) C、f(q) D、f(&a)
答案:->C
解析:数组名表示数组首元素,可以用一级指针接收,而调用的函数参数为二级指针,因此A错误。B同理,不可以用二级指针接收,C选项正确,q为数组名表示数组首元素地址,而数组的元素类型为int *,一级指针的地址所以用二级指针接收。D、&数组名表示的是取出整个数组的地址,因此也不能用二级指针接收。
编程题
描述
在一个长为 字符串中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写).(从0开始计数)
数据范围:100000≤n≤10000,且字符串只有字母组成。
要求:空间复杂度 O(n)O(n),时间复杂度 O(n)O(n)
例
输入:
"google"返回值:
4
思路:这道题既然限定了时间复杂度为O(N),所以我们不可以用暴力求解两次遍历,但是空间复杂度可以为O(N),因此我们可以借助一个数组来搞,由于这里输入的是字符串,我们可以利用它的ASCII码来做题。具体思路为:我们创建一个大小为125的数组arr(没必要创建太大的,超出ASCII即可)。然后我们将题目给的str数组的元素作为arr的下标,遍历整个str,每次arr对应的下标++,最后再遍历str,arr的下标对应的值即为str元素出现的次数。如下图:
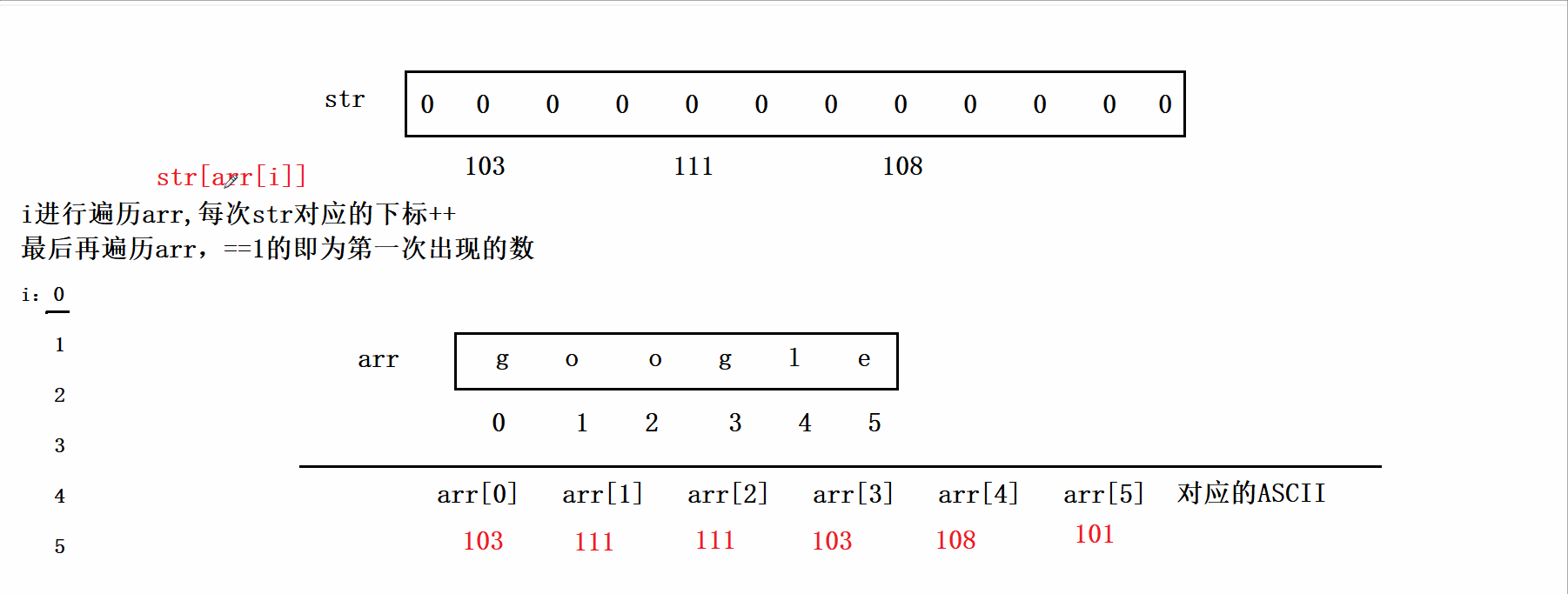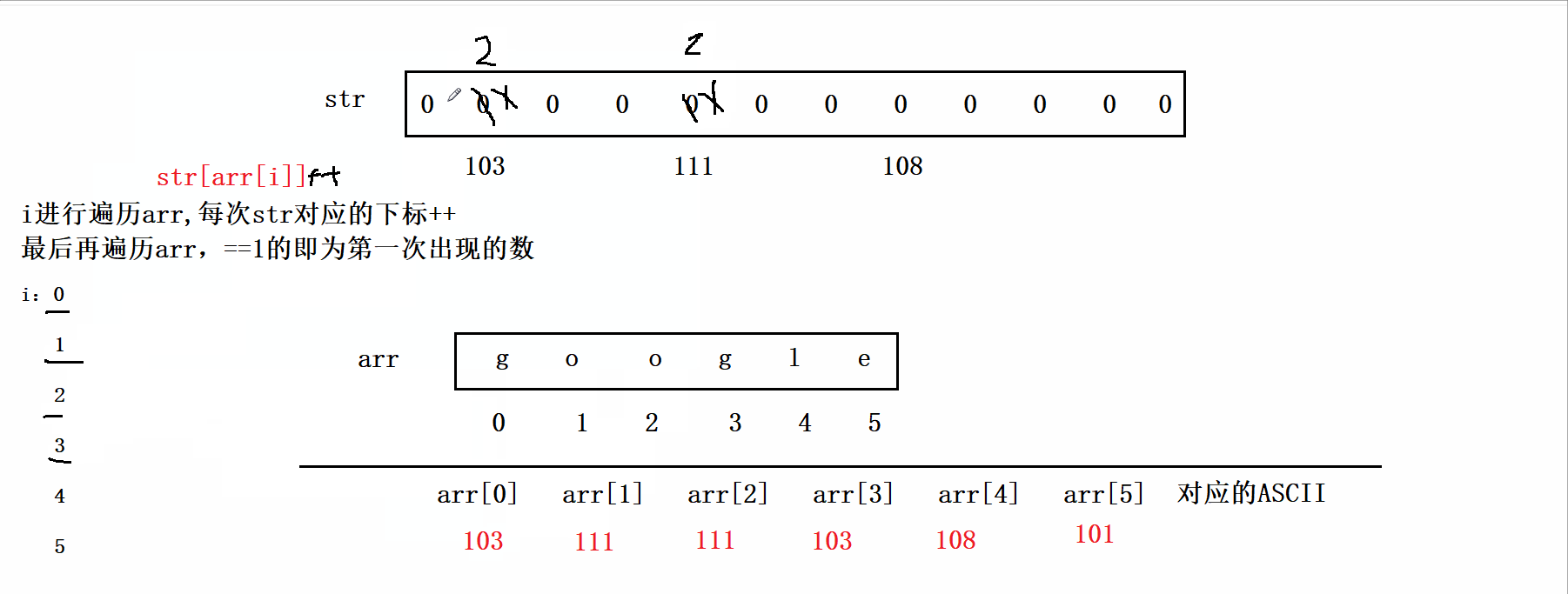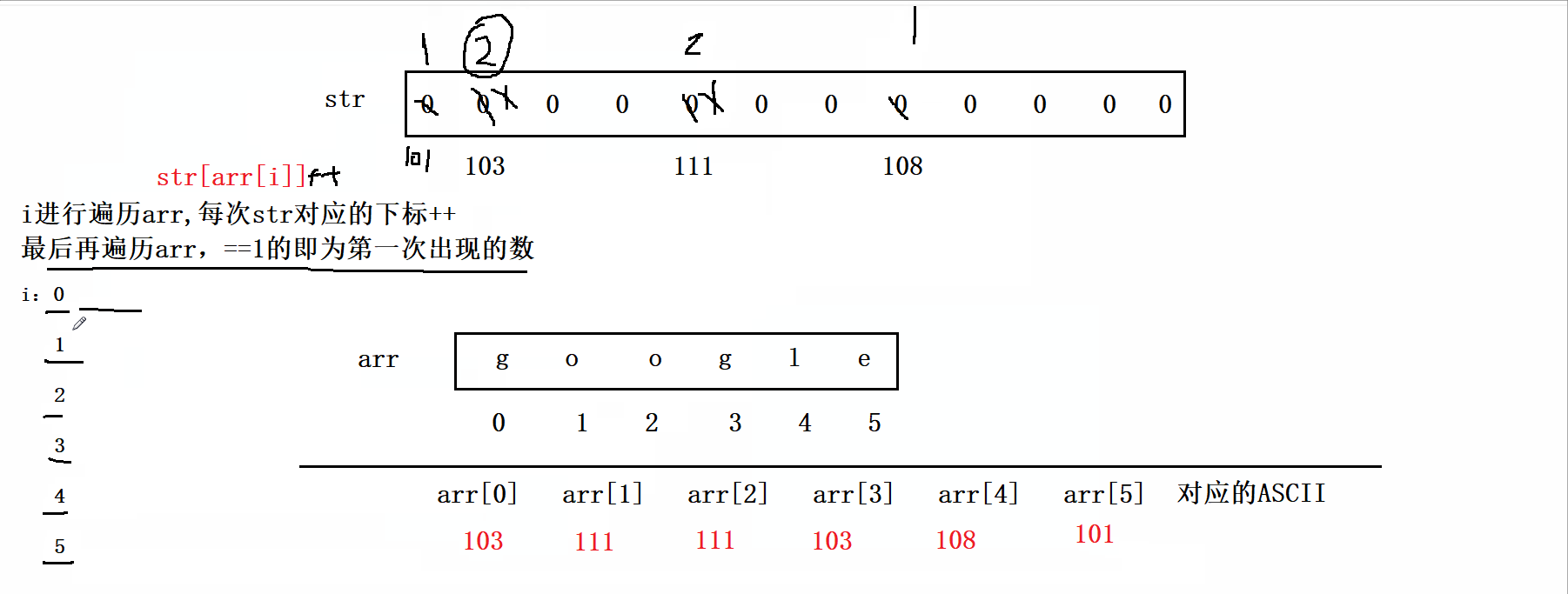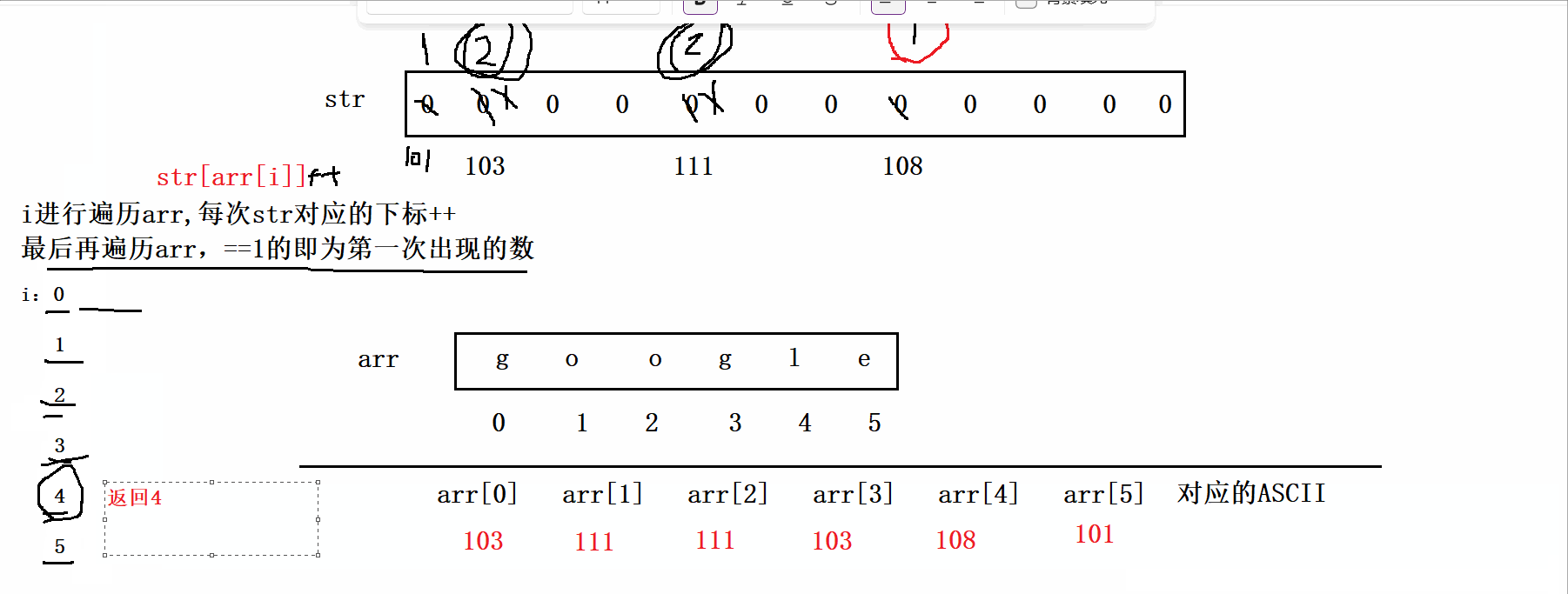
代码实现:
int FirstNotRepeatingChar(char* str ) {
if(str == NULL)
{
return true;
}
// write code here // write code here
int arr[123]={0};//初始化数组全部为0
int len=strlen(str);//数组长度
for(int i=0; i<len; i++)
{
arr[str[i]]++;//统计字母出现的次数,出现一次,对应的坐标的值就+1
}
//遍历整个数组,如果下标位置的值为1,说明只出现1次,直接返回i
for(int i=0; i<len; i++)
{
if(arr[str[i]] == 1)
{
return i;
}
}
//走到这里说明没有出现1次的
return -1;
}实现一个算法,确定一个字符串 s 的所有字符是否全都不同。(所有字母为小写)
示例 1:
输入: s = "leetcode"
输出: false
示例 2:输入: s = "abc"
输出: true
这道题与上面的题类似,这里提供两种简单的思路:1、与上面一样,借助一个数组来做。2、排序后遍历。
代码实现1:
//与上面的题一样
bool isUnique(char* astr){
int arr[200]={0};//借助一个数组
int len=strlen(astr);
for(int i=0; i<len; i++ )
{
arr[astr[i]]++;
}
for(int i=0; i<len; i++)
{
if(arr[astr[i]] != 1)
{
return false;
}
}
return true;
}代码二实现(qsort排序):
//比较的函数
int compchar(const void*a1,const void*a2)
{
return *(char*)a1-*(char*)a2;
}
bool isUnique(char* astr){
if(astr == NULL)
{
return NULL;
}
int len=strlen(astr);
//排序后遍历,遇见相同的返回false
qsort(astr,len,sizeof(char),compchar);
for(int i=0; i<len-1; i++)
{
if(astr[i] == astr[i+1])
{
return false;
}
}
return true;
}end
生活原本沉闷,但跑起来就会有风!🌹