目录
前言
一、熔断是什么?
二、服务降级
三、雪崩是如何发生的
四、hystrix使用
五、降级机制要如何做
总结
前言
在“双十一”的巨大流量中,商品促销过程中出现了几次短暂的服务不可用,这给部分用户造成了不好的使用体验。事后,你们进行了细致的复盘,追查出现故障的根本原因,你发现,原因主要可以归结为两大类。
第一类原因是由于依赖的资源或者服务不可用,最终导致整体服务宕机。举例来说,在你的电商系统中就可能由于数据库访问缓慢,导致整体服务不可用。
另一类原因是你们乐观地预估了可能到来的流量,当有超过系统承载能力的流量到来时,系统不堪重负,从而出现拒绝服务的情况。
那么,你要如何避免再次出现这两类问题呢?我建议你采取降级、熔断以及限流的方案。今天这节课,我主要讲一下解决第一类问题的思路:降级和熔断。
限流、熔断和降级都是系统容错的重要设计模式。
一、熔断是什么?
是在流量过大时(或下游服务出现问题时),可以自动断开与下游服务的交互,并可以通过自我诊断下游系统的错误是否已经修正,或上游流量是否减少至正常水平,来自我恢复。熔断更像是自动化补救手段,可能发生在服务无法支撑大量请求或服务发生其他故障时,对请求进行限制处理,同时还可尝试性的进行恢复。
二、服务降级
主要是针对非核心业务功能,而核心业务如果流程超过预估的峰值,就需要进行限流。降级一般考虑的是分布式系统的整体性,从源头上切断流量的来源。降级更像是预估手段,在预计流量峰值前提下,提前通过配置功能降低服务体验,或暂停次要功能,保证系统主要流程功能平稳响应。
三、雪崩是如何发生的
局部故障最终会导致全局故障,这种情况有一个专业的名词儿,叫做“雪崩”。那么,为什么会发生雪崩呢?我们知道,系统在运行的时候是需要消耗一些资源的,包括 CPU、内存等系统资源,也包括执行业务逻辑的时候,需要的线程资源。
举个例子,一般在业务执行的容器内,都会定义一些线程池来分配执行任务的线程,比如在Tomcat 这种 Web 容器的内部,定义了线程池来处理 HTTP 请求;RPC 框架也给 RPC 服务端初始化了线程池来处理 RPC 请求。
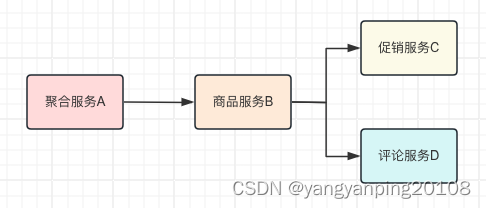
这些线程池中的线程资源是有限的,如果这些线程资源被耗尽,那么服务自然也就无法处理新的请求,服务提供方也就宕机了。比如,你的垂直电商系统有四个服务 聚合服务A、商品服务B、促销服务C、评论服务D,A调用 B,B 调用 C 和 D。其中,聚合服务A、商品服务B、促销服务C是系统的核心服务,论服务D 是非核心服务。
所以,一旦作为入口的 A 流量增加,你可能会考虑把 A、B 和 C 服务扩容,忽略 D。那么D 就有可能因为无法承担这么大的流量,导致请求处理缓慢,进一步会让 B 在调用 D 的时候,B 中的请求被阻塞,等待 D 返回响应结果。这样一来,B 服务中被占用的线程资源就不能释放。
久而久之,B 就会因为线程资源被占满,无法处理后续的请求。那么从 A 发往 B 的请求,就会被放入 B 服务线程池的队列中,然后 A 调用 B 响应时间变长,进而拖垮 A 服务。你看,仅仅因为非核心服务 D 的响应时间变长,就可以导致整体服务宕机,这就是我们经常遇到的一种服务雪崩情况。
那么我们要如何避免出现上面这种情况呢?从我刚刚的介绍中你可以看到,因为服务调用方等待服务提供方的响应时间过长,它的资源被耗尽,才引发了级联反应,发生雪崩。所以在分布式环境下,系统最怕的反而不是某一个服务或者组件宕机,而是最怕它响应缓慢,因为,某一个服务或者组件宕机也许只会影响系统的部分功能,但它响应一慢,就会出现雪崩拖垮整个系统。
而我们在部门内部讨论方案的时候,会格外注意这个问题,解决的思路就是在检测到某一个服务的响应时间出现异常时,切断调用它的服务与它之间的联系,让服务的调用快速返回失败,从而释放这次请求持有的资源。这个思路也就是我们经常提到的降级和熔断机制。那么降级和熔断分别是怎么做的呢?它们之间有什么相同点和不同点呢?你在自己的项目中要如何实现熔断降级呢?
四、Hystrix简介
Spring Cloud Hystrix是一款优秀的服务容错和保护组件,也是Spring Cloud的重要组件之一。
Spring Cloud Hystrix是基于Netfilx公司的开源组件Hystrix实现的。提供熔断器功能,能够有效阻止分布式服务系统中出现联动故障,以提高微服务系统的弹性。Spring Cloud Hystrix具有服务降级,服务熔断,线程隔离,请求缓存,请求合并以及实时故障监控等强大功能。
Hystrix能做什么
- 保护线程资源:防止单个服务的故障耗尽系统中所有的线程资源。
- 快速失败机制:当某个服务发生了故障,不让服务调用方一直等待,而直接返回一个可预期的,可处理的降级响应。
- 提供降级(FallBack)方案:在请求失败后,提供一个设计好的降级方案,当请求失败后调用此方法。
- 防止故障扩散:使用熔断机制,防止故障扩散到其他服务。
- 提供熔断器故障监控组件Hystrix Dashboard,随时监控熔断器的状态。
Hystrix服务熔断
熔断机制是为了应对雪崩效应而出现一种微服务链路保护机制。
当微服务系统的某个微服务不可用或响应时间太长时,为了保护系统的服务整体可用性,熔断器会暂时切断对该服务的请求调用,并快速返回一个友好的错误响应信息。这种熔断状态不是永久的,在经历了一定时间后,熔断器会再次检测该微服务是否恢复正常,若恢复正常则恢复调用链路。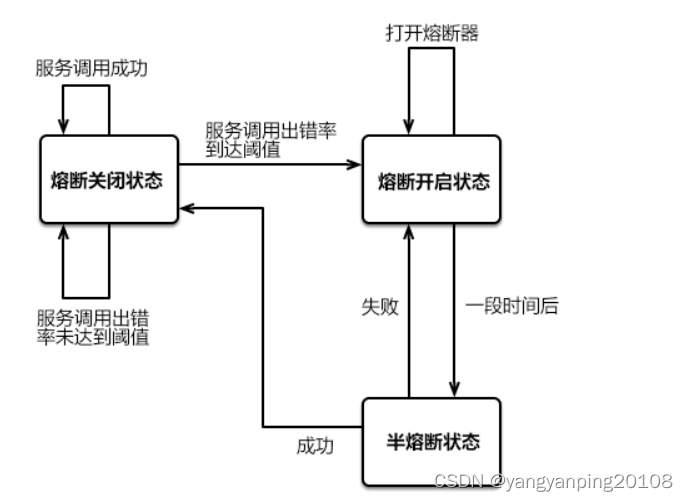
- 熔断关闭状态(Closed):当服务访问正常时,熔断器处于关闭状态,服务调用方可以正常地对服务进行调用。
- 熔断开启状态(Open):默认情况下,在固定时间内接口调用出错比率达到一个阈值(例如 50%),熔断器会进入熔断开启状态。进入熔断状态后,后续对该服务的调用都会被切断,熔断器会执行本地的降级(FallBack)方法。
- 半熔断状态(Half-Open): 在熔断开启一段时间之后,熔断器会进入半熔断状态。在半熔断状态下,熔断器会尝试恢复服务调用方对服务的调用,允许部分请求调用该服务,并监控其调用成功率。如果成功率达到预期,则说明服务已恢复正常,熔断器进入关闭状态;如果成功率仍旧很低,则重新进入熔断开启状态。
Hystrix实现熔断机制
在SpringCloud中,熔断机制是通过Hystrix实现的。Hystrix会监控微服务间调用的情况,当失败调用达到一定比例时(例如5秒内失败20次),就会启动熔断机制。
- 当服务的调用出错率达到后超过Hystirx规定的出错比率(默认为50%),熔断器进入熔断开启状态。
- 熔断器进入熔断开启状态后,Hystrix会启动一个休眠时间窗,在这个时间窗内,该服务的降级逻辑会临时充当业务主逻辑,而原来的业务主逻辑不可用。
- 当有请求再次调用该服务时,会直接调用降级逻辑快递返回失败效应,以避免系统雪崩。
- 当休眠时间窗到期后,Hystrix会进入半熔断状态,允许部分请求对由原来的业务主逻辑进行调用,并监控其成功率。
- 如果调用成功率达到预期,说明服务恢复正常,Hystrix进入熔断关闭状态,服务原来的业务逻辑恢复。否则Hystrix将进入熔断开启状态,休眠时间窗口重新计时。
Hystrix熔断实现
在pom.xml导入Hystrix依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.7.12</version>
</dependency>WebApplication 启动类 开启Hystrix
@EnableHystrix
@SpringBootApplication
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}HystrixController 代码
@EnableCircuitBreaker
@RestController
public class HystrixController {
@HystrixCommand(fallbackMethod = "fallback", commandProperties =
{
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "100"),//指定多久超时,单位毫秒。超时进fallback
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),//判断熔断的最少请求数,默认是10;只有在一个统计窗口内处理的请求数量达到这个阈值,才会进行熔断与否的判断
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "10"),//判断熔断的阈值,默认值50,表示在一个统计窗口内有50%的请求处理失败,会触发熔断
})
@RequestMapping("/test/{id}")
public String test(@PathVariable("id") Integer id) throws Exception {
Thread.sleep(1000);
return "ok";
}
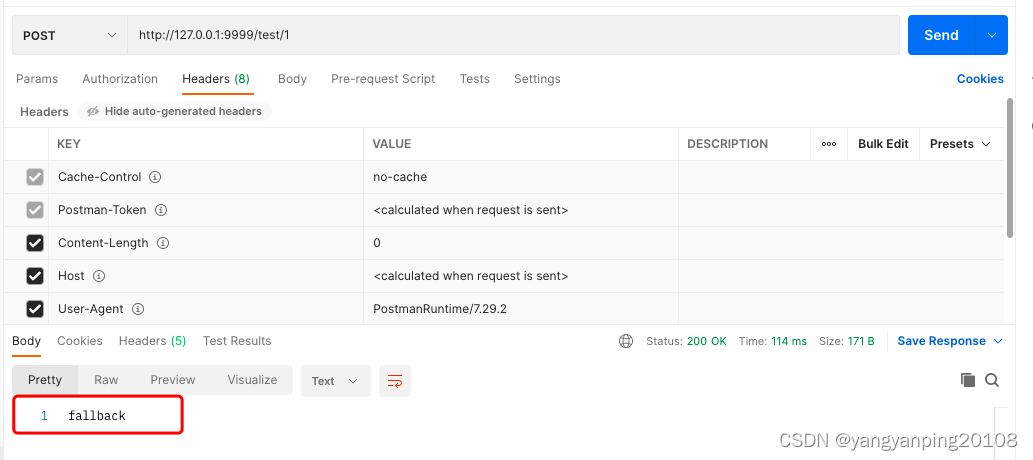
public String fallback(@PathVariable("id") Integer id) {
return "fallback";
}
}启动测试
五、降级机制要如何做
除了熔断之外,我们在听业内分享的时候,听到最多的服务容错方式就是降级,那么降级又是怎么做的呢?它和熔断有什么关系呢?其实在我看来,相比熔断来说,降级是一个更大的概念。因为它是站在整体系统负载的角度上,放弃部分非核心功能或者服务,保证整体的可用性的方法,是一种有损的系统容错方式。这样看来,熔断也是降级的一种,除此之外还有限流降级、开关降级等等(限流降级我会在下一节课中提到,这节课主要讲一下开关降级)。
开关降级指的是在代码中预先埋设一些“开关”,用来控制服务调用的返回值。比方说,开关关闭的时候正常调用远程服务,开关打开时则执行降级的策略。这些开关的值可以存储在配置中心中,当系统出现问题需要降级时,只需要通过配置中心动态更改开关的值,就可以实现不重启服务快速地降级远程服务了。还是以电商系统为例,你的电商系统在商品详情页面除了展示商品数据以外,还需要展示评论的数据,但是主体还是商品数据,在必要时可以降级评论数据。所以,你可以定义这个开关为“degrade.comment”,写入到配置中心中,具体的代码也比较简单,就像下面这样:
boolean switcherValue = getFromConfigCenter("degrade.comment"); // 从配置中心获取
if (!switcherValue) {
List<Comment> comments = getCommentList(); // 开关关闭则获取评论数据
} else {
List<Comment> comments = new ArrayList(); // 开关打开,则直接返回空评论数据
}当然了,我们在设计开关降级预案的时候,首先要区分哪些是核心服务,哪些是非核心服务。因为我们只能针对非核心服务来做降级处理,然后就可以针对具体的业务,制定不同的降级策略了。我给你列举一些常见场景下的降级策略,你在实际的工作中可以参考借鉴。针对读取数据的场景,我们一般采用的策略是直接返回降级数据。比如,如果数据库的压力比较大,我们在降级的时候,可以考虑只读取缓存的数据,而不再读取数据库中的数据;如果非核心接口出现问题,可以直接返回服务繁忙或者返回固定的降级数据。对于一些轮询查询数据的场景,比如每隔 30 秒轮询获取未读数,可以降低获取数据的频率(将获取频率下降到 10 分钟一次)。
而对于写数据的场景,一般会考虑把同步写转换成异步写,这样可以牺牲一些数据一致性和实效性来保证系统的可用性。