一、背景
在Python通过pyecharts对爬虫房地产数据进行数据可视化分析(一)基础上添加Flask框架实现web可视化功能,把生成的所有图表生成一份完整的数据分析报告,这样就可以方便直接在网页上看到整体的数据分析可视化结果。
二、步骤实现
这个步骤的实现主要包括如下三个部分组成:
- 用flask库实现的app.py脚本,这个脚本主要干如下几件事:
- 启动一个web服务;
- 读取我们要分析的原始数据;
- 实现一个函数负责将读取的数据传给不同的数据图表生成函数,拿到生成的数据图表对象,然后调用模版进行渲染;
- 绑定一个url路由关系,映射到步骤三的函数;
- 用来渲染生成最终数据分析报告的HTML文件,这个文件主要干如下几件事:
- 对每个数据图表定义一个div;
- 使用ECharts组件对div进行初始化;
- 通过变量拿到flask返回的数据图表数据,对ECharts组件进行设置;
- HTML渲染和计算所依赖的静态资源文件,主要有如下三个:
- echarts-wordcloud.min.js,主要用于词云图生成;
- hu2_bei3_wu3_han4.js,主要用于苏州地图生成;
- echarts.min.js,是所有数据图表依赖的基础js;
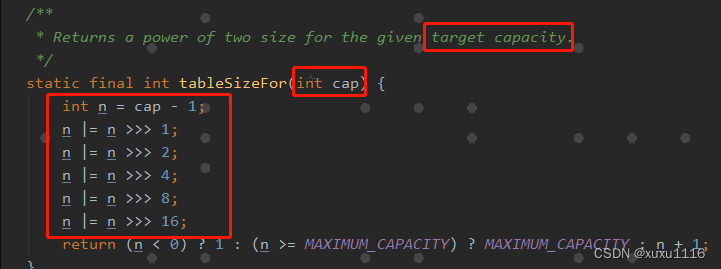
如上三个部分需要按照如下的代码目录结构来组织:
三、代码实现
数据分析主体代码文件为:drawCharts.py,与之前的在最后稍微有点不同,把最后的主函数部分注释掉就好了
"""
读取excel数据,分析数据并生成图表
"""
# -*- coding: UTF-8-*-
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Pie, Scatter, WordCloud, Map, Page
import numpy as np
import jieba
import jieba.analyse
from pyecharts.commons.utils import JsCode
def cal_square_district(row):
if row['面积'] <= 60:
return '[0,60]'
if row['面积'] > 60 and row['面积'] <= 90:
return '[60,90]'
if row['面积'] > 90 and row['面积'] <= 120:
return '[90,120]'
if row['面积'] > 120 and row['面积'] <= 150:
return '[120,150]'
if row['面积'] > 150 and row['面积'] <= 200:
return '[150,200]'
if row['面积'] > 200 and row['面积'] <= 300:
return '[200, 300]'
if row['面积'] > 300:
return '[300,-]'
return '[未知]'
def order_layout_ascending(row):
if row['室'] == '1室':
return 0
if row['室'] == '2室':
return 1
if row['室'] == '3室':
return 2
if row['室'] == '4室':
return 3
if row['室'] == '5室':
return 4
if row['室'] == '6室':
return 5
layout_color_function = """
function (params) {
if (params.value > 17000 && params.value < 18000) {
return 'red';
} else if (params.value > 18000 && params.value < 20000) {
return 'blue';
}else if (params.value > 20000 && params.value < 25000){
return 'green'
}else if (params.value > 25000 && params.value < 35000){
return 'purple'
}else if (params.value > 35000 && params.value < 40000){
return 'black'
}
return 'brown';
}
"""
def unit_price_analysis_by_layout(df, isembed):
# 增加一列[面积区间]
df['面积区间'] = df.apply(cal_square_district, args=(), axis=1)
# 获取要分析的数据行和列
analysis_df = df.loc[:, ['室', '均价']]
analysis_df.loc[:, '室'] = analysis_df.loc[:, '室'].astype('str')
# 对面积区间列group by,然后按分组计算总价和均价的平均值
group = analysis_df.groupby('室', as_index=False)
group_df = group.mean()
group_df.loc[:, '均价'] = group_df.loc[:, '均价'].astype('int')
# 给室这个字段排个序
group_df['order'] = group_df.apply(order_layout_ascending, axis=1)
group_df.sort_values('order', ascending=True, inplace=True)
bar = (
Bar()
.add_xaxis(group_df['室'].tolist())
.add_yaxis("单价均价", group_df["均价"].tolist(),
itemstyle_opts=opts.ItemStyleOpts(color=JsCode(layout_color_function)))
.set_global_opts(title_opts=opts.TitleOpts(title="武汉二手房按户型的房屋单价"),
legend_opts=opts.LegendOpts(is_show=False))
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return bar.render_embed()
else:
return bar
def order_square_ascending(row):
if row['面积区间'] == '[0,60]':
return 0
if row['面积区间'] == '[60,90]':
return 1
if row['面积区间'] == '[90,120]':
return 2
if row['面积区间'] == '[120,150]':
return 3
if row['面积区间'] == '[150,200]':
return 4
if row['面积区间'] == '[200,300]':
return 5
if row['面积区间'] == '[300,-]':
return 6
square_color_function = """
function (params) {
if (params.value > 17000 && params.value < 18000) {
return 'red';
} else if (params.value > 18000 && params.value < 20000) {
return 'blue';
}else if (params.value > 20000 && params.value < 25000){
return 'green'
}else if (params.value > 25000 && params.value < 35000){
return 'purple'
}else if (params.value > 35000 && params.value < 40000){
return 'black'
}
return 'brown';
}
"""
def unit_price_analysis_by_square(df, isembed):
# 增加一列[面积区间]
df['面积区间'] = df.apply(cal_square_district, args=(), axis=1)
# 获取要分析的数据行和列
analysis_df = df.loc[:, ['面积区间', '均价']]
analysis_df.loc[:, '面积区间'] = analysis_df.loc[:, '面积区间'].astype('str')
# 对面积区间列group by,然后按分组计算总价和均价的平均值
group = analysis_df.groupby('面积区间', as_index=False)
group_df = group.mean()
group_df.loc[:, '均价'] = group_df.loc[:, '均价'].astype('int')
# 把面积区间按从小到大排个序
group_df['order'] = group_df.apply(order_square_ascending, axis=1)
group_df.sort_values('order', ascending=True, inplace=True)
bar = (
Bar()
.add_xaxis(group_df['面积区间'].tolist())
.add_yaxis("单价均价", group_df["均价"].tolist(),
itemstyle_opts=opts.ItemStyleOpts(color=JsCode(square_color_function)))
.set_global_opts(
title_opts=opts.TitleOpts(title="武汉二手房按面积区间的房屋单价"),
legend_opts=opts.LegendOpts(is_show=False))
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return bar.render_embed()
else:
return bar
top10_color_function = """
function (params) {
if (params.value > 27000 && params.value < 27500) {
return 'red';
} else if (params.value > 27500 && params.value < 27800) {
return 'blue';
}else if (params.value > 27800 && params.value < 28000){
return 'green'
}else if (params.value > 28000 && params.value < 29000){
return 'purple'
}else if (params.value > 29000 && params.value < 30000){
return 'brown'
}else if (params.value > 30000 && params.value < 35200){
return 'gray'
}else if (params.value > 35200 && params.value < 37000){
return 'orange'
}else if (params.value > 37000 && params.value < 40000){
return 'pink'
}else if (params.value > 40000 && params.value < 45000){
return 'navy'
}
return 'gold';
}
"""
def unit_price_analysis_by_estate(df, isembed):
# 获取要分析的数据列
analysis_df = df.loc[:, ['小区名称', '均价']]
analysis_df.loc[:, '小区名称'] = analysis_df.loc[:, '小区名称'].astype('str')
# 对小区名称分组,然后按照分组计算单价均价
group = analysis_df.groupby('小区名称', as_index=False)
group_df = group.mean()
group_df.loc[:, '均价'] = group_df.loc[:, '均价'].astype('int')
# 按照均价列降序排序
group_df.sort_values('均价', ascending=False, inplace=True)
# 取Top10
top10_df = group_df.head(10)
# print(top10_df)
# 为了横向柱状图展示,再从低到高排序一下
top10_df.sort_values('均价', ascending=True, inplace=True)
bar = (
Bar(init_opts=opts.InitOpts(width="1500px"))
.add_xaxis(top10_df['小区名称'].tolist())
.add_yaxis("房价单价", top10_df['均价'].tolist(),
itemstyle_opts=opts.ItemStyleOpts(color=JsCode(top10_color_function)))
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="武汉各小区二手房房价TOP10"),
xaxis_opts=opts.AxisOpts(axislabel_opts={'interval': '0'}),
legend_opts=opts.LegendOpts(is_show=False))
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return bar.render_embed()
else:
return bar
def unit_price_analysis_by_district(df):
# 获取要分析的数据列
analysis_df = df.loc[:, ['区', '均价']]
analysis_df.loc[:, '区'] = analysis_df.loc[:, '区'].astype('str')
# 对小区名称分组,然后按照分组计算单价均价
group = analysis_df.groupby('区', as_index=False)
group_df = group.mean()
group_df.loc[:, '均价'] = group_df.loc[:, '均价'].astype('int')
# 按照均价列降序排序
group_df.sort_values('均价', ascending=True, inplace=True)
bar = (
Bar(init_opts=opts.InitOpts(width="1500px"))
.add_xaxis(group_df['区'].tolist())
.add_yaxis("房价单价", group_df['均价'].tolist())
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="武汉各区域二手房房价排行榜"),
xaxis_opts=opts.AxisOpts(axislabel_opts={'interval': '0'}))
)
return bar.render_embed()
def add_sale_estate_col(row):
return 0
def sale_estate_analysis_by_year(df, isembed):
# 增加一列待售房屋数,初始值均为0
df.loc[:, '待售房屋数'] = df.apply(add_sale_estate_col, axis=1)
# 获取要用作数据分析的两列:建筑年份和待售房屋数
analysis_df = df.loc[:, ['建筑年份', '待售房屋数']]
# 因为建筑年份列有空值,先预处理一下
analysis_df.dropna(inplace=True)
# 按照建筑年份进行分组
group = analysis_df.groupby('建筑年份', as_index=False)
# 对每个分组进行统计计数
group_df = group.count()
group_df.loc[:, '待售房屋数'] = group_df.loc[:, '待售房屋数'].astype('int')
pie = Pie(init_opts=opts.InitOpts(width='800px', height='600px', bg_color='white'))
pie.add("pie", [list(z) for z in zip(group_df['建筑年份'].tolist(), group_df['待售房屋数'].tolist())]
, radius=['40%', '60%']
, center=['50%', '50%']
, label_opts=opts.LabelOpts(
position="outside",
formatter="{b}:{c}:{d}%", )
).set_global_opts(
title_opts=opts.TitleOpts(title='武汉二手房不同建筑年份的待售数量', pos_left='300', pos_top='20',
title_textstyle_opts=opts.TextStyleOpts(color='black', font_size=16)),
legend_opts=opts.LegendOpts(is_show=False))
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return pie.render_embed()
else:
return pie
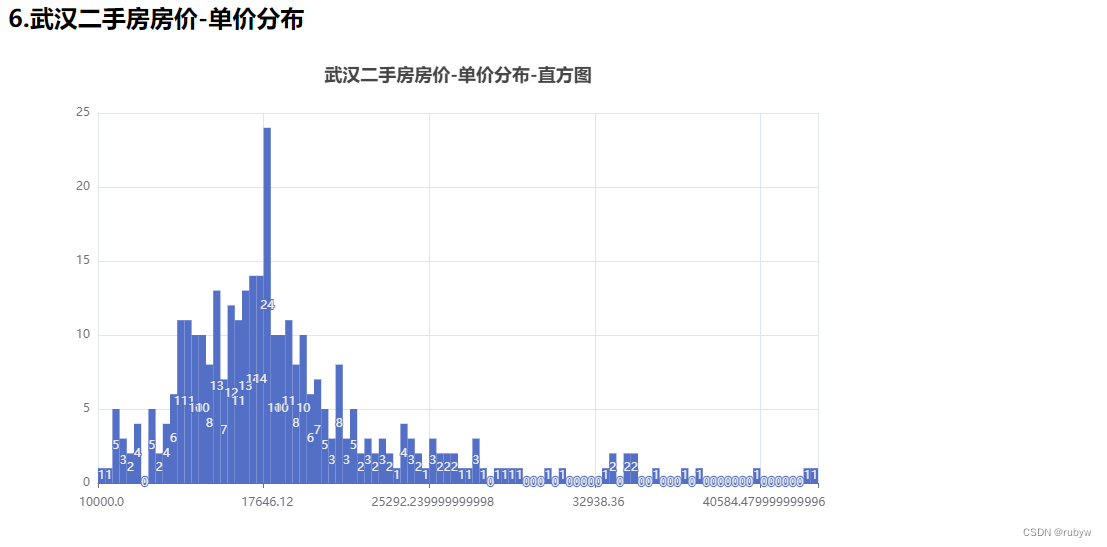
def unit_price_analysis_by_histogram(df, isembed):
hist, bin_edges = np.histogram(df['均价'], bins=100)
bar = (
Bar()
.add_xaxis([str(x) for x in bin_edges[:-1]])
.add_yaxis('价格分布', [float(x) for x in hist], category_gap=0)
.set_global_opts(
title_opts=opts.TitleOpts(title='武汉二手房房价-单价分布-直方图', pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return bar.render_embed()
else:
return bar
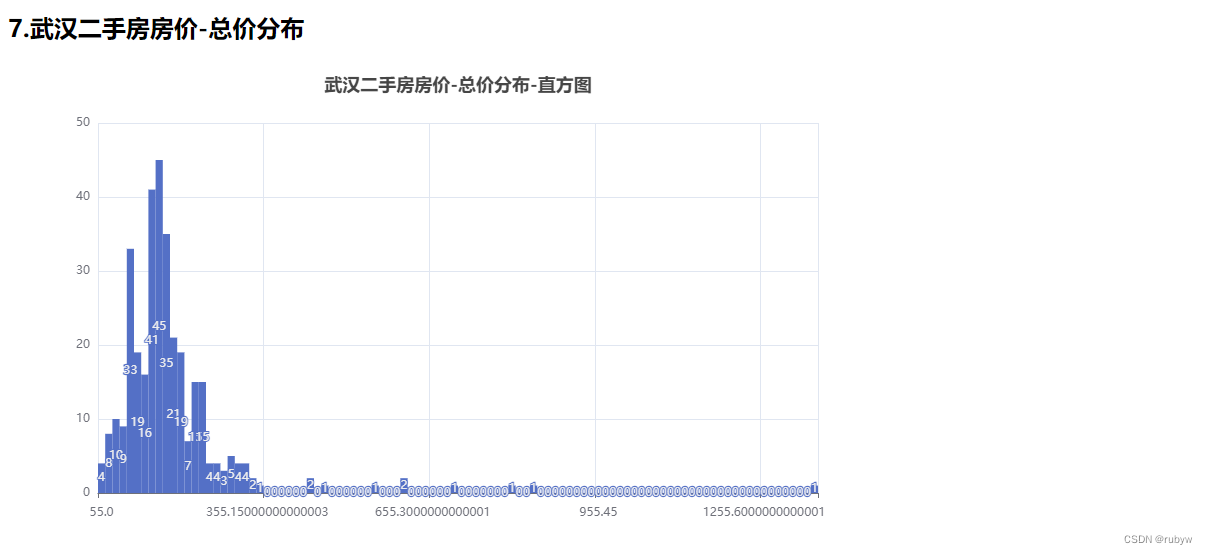
def total_price_analysis_by_histogram(df, isembed):
hist, bin_edges = np.histogram(df['总价'], bins=100)
bar = (
Bar()
.add_xaxis([str(x) for x in bin_edges[:-1]])
.add_yaxis('价格分布', [float(x) for x in hist], category_gap=0)
.set_global_opts(
title_opts=opts.TitleOpts(title='武汉二手房房价-总价分布-直方图', pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return bar.render_embed()
else:
return bar
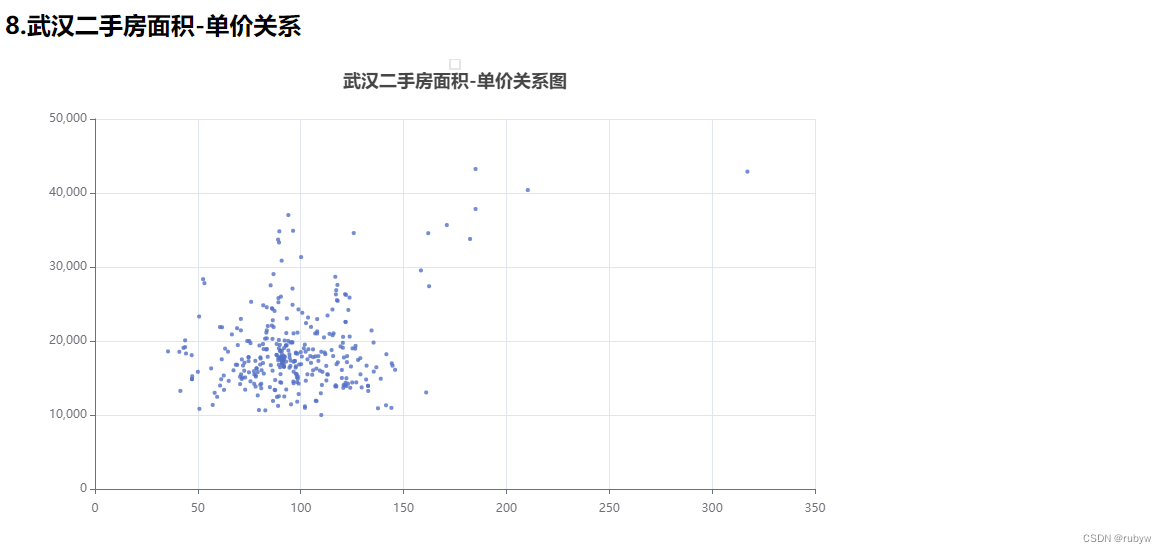
def unit_price_analysis_by_scatter(df, isembed):
df.sort_values('面积', ascending=True, inplace=True)
square = df['面积'].to_list()
unit_price = df['均价'].to_list()
scatter = (
Scatter()
.add_xaxis(xaxis_data=square)
.add_yaxis(
series_name='',
y_axis=unit_price,
symbol_size=4,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(type_='value'),
yaxis_opts=opts.AxisOpts(type_='value'),
title_opts=opts.TitleOpts(title='武汉二手房面积-单价关系图', pos_left='center')
)
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return scatter.render_embed()
else:
return scatter
def hot_word_analysis_by_wordcloud(df, isembed):
txt = ''
for index, row in df.iterrows():
txt = txt + str(row['待售房屋']) + ';' + str(row['标签']) + '\n'
word_weights = jieba.analyse.extract_tags(txt, topK=100, withWeight=True)
word_cloud = (
WordCloud()
.add(series_name='高频词语', data_pair=word_weights, word_size_range=[10, 100])
.set_global_opts(
title_opts=opts.TitleOpts(
title='武汉二手房销售热度词',
title_textstyle_opts=opts.TextStyleOpts(font_size=23),
pos_left='center'
)
)
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return word_cloud.render_embed()
else:
# png_name = 'hot_word_analysis_by_wordcloud.png'
# make_snapshot(snapshot, word_cloud.render(), f"crawler/anjuke/static/{png_name}")
# return png_name
return word_cloud
def transform_name(row):
district_name = row['区'].strip()
if district_name == '江汉' or district_name == '江岸' or district_name == '硚口' or district_name == '汉阳' or district_name == '武昌' or district_name == '东西湖' or district_name == '洪山':
district_name = district_name + '区'
return district_name
def unit_price_analysis_by_map(df, isembed):
data = []
# 获取要分析的数据列
analysis_df = df.loc[:, ['区', '均价']]
# 按区列分组
group_df = analysis_df.groupby('区', as_index=False)
# 根据分组对均价列求平均值
group_df = group_df.mean('均价')
# print(group_df)
# 将区的名字做一下转换,为下面的地图匹配做准备
group_df['区'] = group_df.apply(transform_name, axis=1)
group_df.loc[:, '均价'] = group_df.loc[:, '均价'].astype('int')
# 将数据转换成map需要的数据格式
for index, row in group_df.iterrows():
district_array = [row['区'], row['均价']]
data.append(district_array)
map = (
Map()
.add('武汉各区域二手房房价', data, '武汉')
.set_global_opts(
title_opts=opts.TitleOpts(title='武汉各区域二手房房价地图', pos_left='center'),
visualmap_opts=opts.VisualMapOpts(max_=26000),
legend_opts=opts.LegendOpts(is_show=False)
)
)
# 判断是否单独显示,还是和其他图表一起显示
if isembed:
return map.render_embed()
else:
# png_name = 'unit_price_analysis_by_map.png'
# make_snapshot(snapshot, map.render(), f"crawler/anjuke/static/{png_name}")
# return png_name
return map
# if __name__ == '__main__':
#
# # 读取csv
# fpath = 'data/wuhanSecondHouse.csv'
# df = pd.read_csv(fpath, header=[0], encoding='gbk')
# df.drop_duplicates(keep='first', inplace=True)
#
#
#
# # # 画图
# # unit_price_analysis_by_square.render()
# # unit_price_analysis_by_layout.render()
# # unit_price_analysis_by_estate.render()
# # sale_estate_analysis_by_year.render()
# # unit_price_analysis_by_histogram.render()
# # total_price_analysis_by_histogram.render()
# # unit_price_analysis_by_scatter.render()
# # hot_word_analysis_by_wordcloud.render()
# # unit_price_analysis_by_map.render()
#
# # 合并
# page = Page(layout=Page.DraggablePageLayout) # 可拖动布局
#
# page.add(
# unit_price_analysis_by_square,
# unit_price_analysis_by_layout,
# unit_price_analysis_by_estate,
# sale_estate_analysis_by_year,
# unit_price_analysis_by_histogram,
# total_price_analysis_by_histogram,
# unit_price_analysis_by_scatter,
# hot_word_analysis_by_wordcloud,
# unit_price_analysis_by_map
# )
#
# page.render("武汉二手房数据分析.html")
这里flask的app.py脚本为report_web.py,主要绑定一个url路由关系,映射到上面代码中的函数
"""
启动一个web网站,展示不同的分析数据图表
启动方法:进入/anjuke目录下,执行python report_web.py
"""
# -*- coding: UTF-8-*-
from flask import Flask, render_template
import drawChart as dbc
import pandas as pd
app = Flask(__name__)
# 读取csv
fpath = 'data/wuhanSecondHouse.csv'
df = pd.read_csv(fpath, header=[0], encoding='gbk')
df.drop_duplicates(keep='first', inplace=True)
@app.route("/unit_price_analysis_by_layout")
def bar_unit_price_analysis_by_layout():
result = dbc.unit_price_analysis_by_layout(df, True)
return result
@app.route("/unit_price_analysis_by_suqare")
def bar_unit_price_analysis_by_square():
result = dbc.unit_price_analysis_by_square(df, True)
return result
@app.route("/unit_price_analysis_by_estate")
def bar_unit_price_analysis_by_estate():
str = dbc.unit_price_analysis_by_estate(df, True)
return str
@app.route("/unit_price_analysis_by_district")
def bar_unit_price_analysis_by_district():
str = dbc.unit_price_analysis_by_district(df)
return str
@app.route("/pie_sale_estate_analysis_by_year")
def pie_sale_estate_analysis_by_year():
str = dbc.sale_estate_analysis_by_year(df, True)
return str
@app.route("/histogram_unit_price_analysis")
def histogram_unit_price_analysis():
str = dbc.unit_price_analysis_by_histogram(df, True)
return str
@app.route("/histogram_total_price_analysis")
def histogram_total_price_analysis():
str = dbc.total_price_analysis_by_histogram(df, True)
return str
@app.route("/scatter_unit_price_analysis")
def scatter_unit_price_analysis():
str = dbc.unit_price_analysis_by_scatter(df, True)
return str
@app.route("/word_cloud_hot_word_analysis")
def word_cloud_hot_word_analysis():
str = dbc.hot_word_analysis_by_wordcloud(df, True)
return str
@app.route("/map_unit_price_analysis")
def map_unit_price_analysis():
str = dbc.unit_price_analysis_by_map(df, True)
return str
@app.route("/show_all_analysis_chart")
def show_all_analysis_chart():
# 获取按面积区间的单价分析数据
unit_price_analysis_by_square = dbc.unit_price_analysis_by_square(df, False)
# 获取按室区分的单价分析数据
unit_price_analysis_by_layout = dbc.unit_price_analysis_by_layout(df, False)
# 获取苏州各小区二手房房价TOP10
unit_price_analysis_by_estate = dbc.unit_price_analysis_by_estate(df, False)
# 获取不同建筑年份的待售房屋数
sale_estate_analysis_by_year = dbc.sale_estate_analysis_by_year(df, False)
# 苏州二手房房价-单价分布-直方图
unit_price_analysis_by_histogram = dbc.unit_price_analysis_by_histogram(df, False)
# 苏州二手房房价-总价分布-直方图
total_price_analysis_by_histogram = dbc.total_price_analysis_by_histogram(df, False)
# 苏州二手房面积-单价关系图
unit_price_analysis_by_scatter = dbc.unit_price_analysis_by_scatter(df, False)
# 苏州二手房销售热度词
# hot_word_analysis_by_wordcloud_png_name = dbc.hot_word_analysis_by_wordcloud(df,False)
hot_word_analysis_by_wordcloud = dbc.hot_word_analysis_by_wordcloud(df, False)
# 苏州各区域二手房房价
# unit_price_analysis_by_map_png_name = dbc.unit_price_analysis_by_map(df,False)
unit_price_analysis_by_map = dbc.unit_price_analysis_by_map(df, False)
return render_template("show_analysis_chart.html",
# dump_options():将经过get_options方法处理过的echarts配置项序列化为JSON格式(JsCode 生成的函数不带引号)
unit_price_analysis_by_square_option=unit_price_analysis_by_square.dump_options(),
unit_price_analysis_by_layout_option=unit_price_analysis_by_layout.dump_options(),
unit_price_analysis_by_estate_option=unit_price_analysis_by_estate.dump_options(),
sale_estate_analysis_by_year_option=sale_estate_analysis_by_year.dump_options(),
unit_price_analysis_by_histogram_option=unit_price_analysis_by_histogram.dump_options(),
total_price_analysis_by_histogram_option=total_price_analysis_by_histogram.dump_options(),
unit_price_analysis_by_scatter_option=unit_price_analysis_by_scatter.dump_options(),
hot_word_analysis_by_wordcloud_option=hot_word_analysis_by_wordcloud.dump_options(),
unit_price_analysis_by_map_option=unit_price_analysis_by_map.dump_options()
)
if __name__ == "__main__":
app.run()
static目录下的这三个静态资源文件文件,来源之前文章中生成的html文件:武汉二手房数据分析.html
https://assets.pyecharts.org/assets/v5/echarts.min.js
https://assets.pyecharts.org/assets/v5/echarts-wordcloud.min.js
https://assets.pyecharts.org/assets/v5/echarts.min.js
在浏览器中打开上述的网址,分别把内容复制到对应的文件中就行了,注意中文乱码,自己调整好即可
然后templates目录中的show_analysis_chart.html文件就好得到了,主要对网页进行渲染,与所依赖的static目录下的静态资源和flask的程序运行文件的联系起来,最终得到我们想要的网页可视化效果
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>武汉二手房数据分析报告</title>
<script type="text/javascript" src="/static/echarts.min.js"></script>
<script type="text/javascript" src="/static/echarts-wordcloud.min.js"></script>
<script type="text/javascript" src="/static/hu2_bei3_wu3_han4.js"></script>
</head>
<body>
<h1 align="center">武汉二手房数据分析报告</h1>
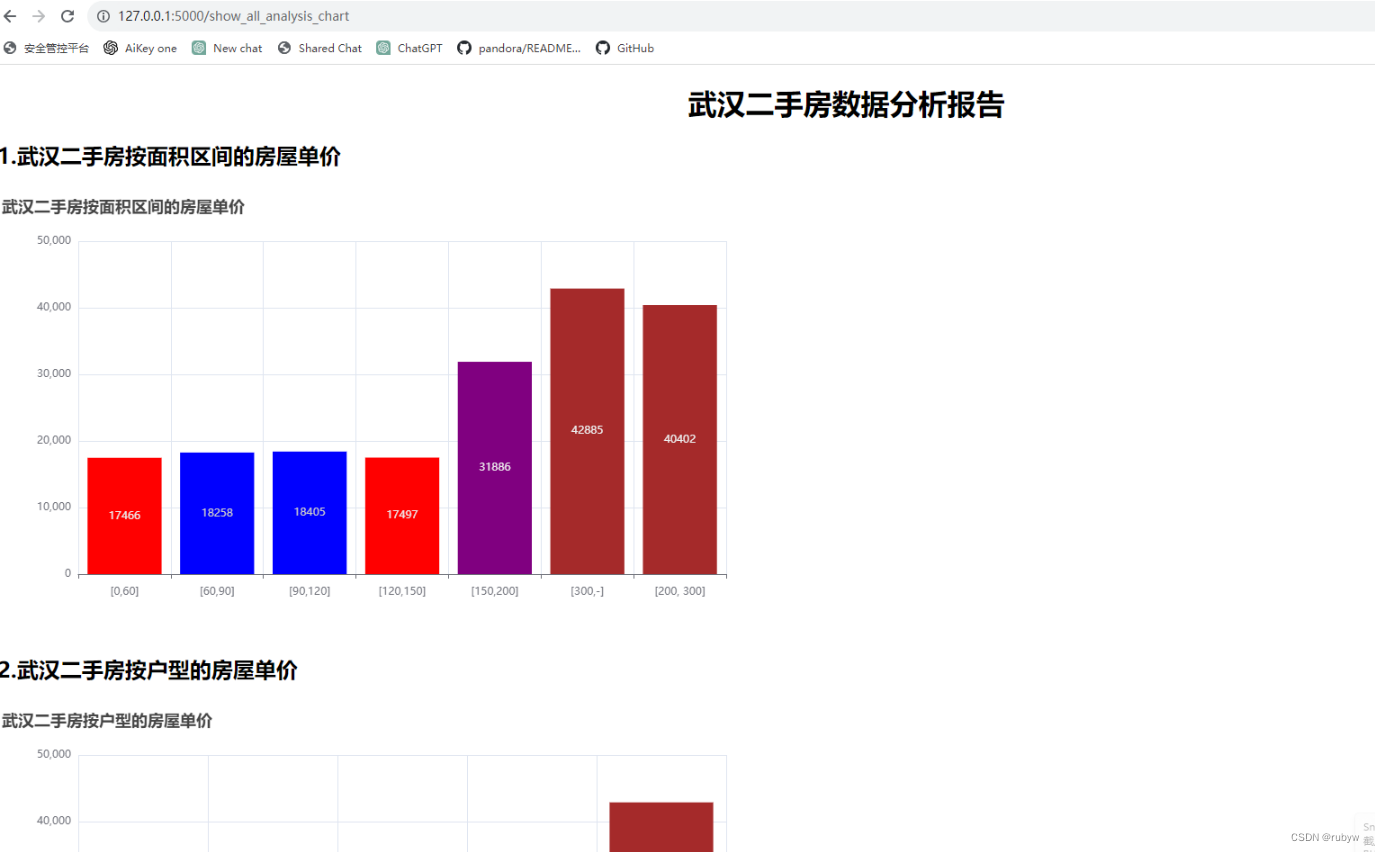
<h2>1.武汉二手房按面积区间的房屋单价</h2>
<div id="unit_price_analysis_by_square" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_square_chart = echarts.init(document.getElementById('unit_price_analysis_by_square'));
var option = {{ unit_price_analysis_by_square_option | safe }};
unit_price_analysis_by_square_chart.setOption(option);
</script>
<h2>2.武汉二手房按户型的房屋单价</h2>
<div id="unit_price_analysis_by_layout" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_layout_chart = echarts.init(document.getElementById('unit_price_analysis_by_layout'));
var option = {{ unit_price_analysis_by_layout_option | safe }};
unit_price_analysis_by_layout_chart.setOption(option);
</script>
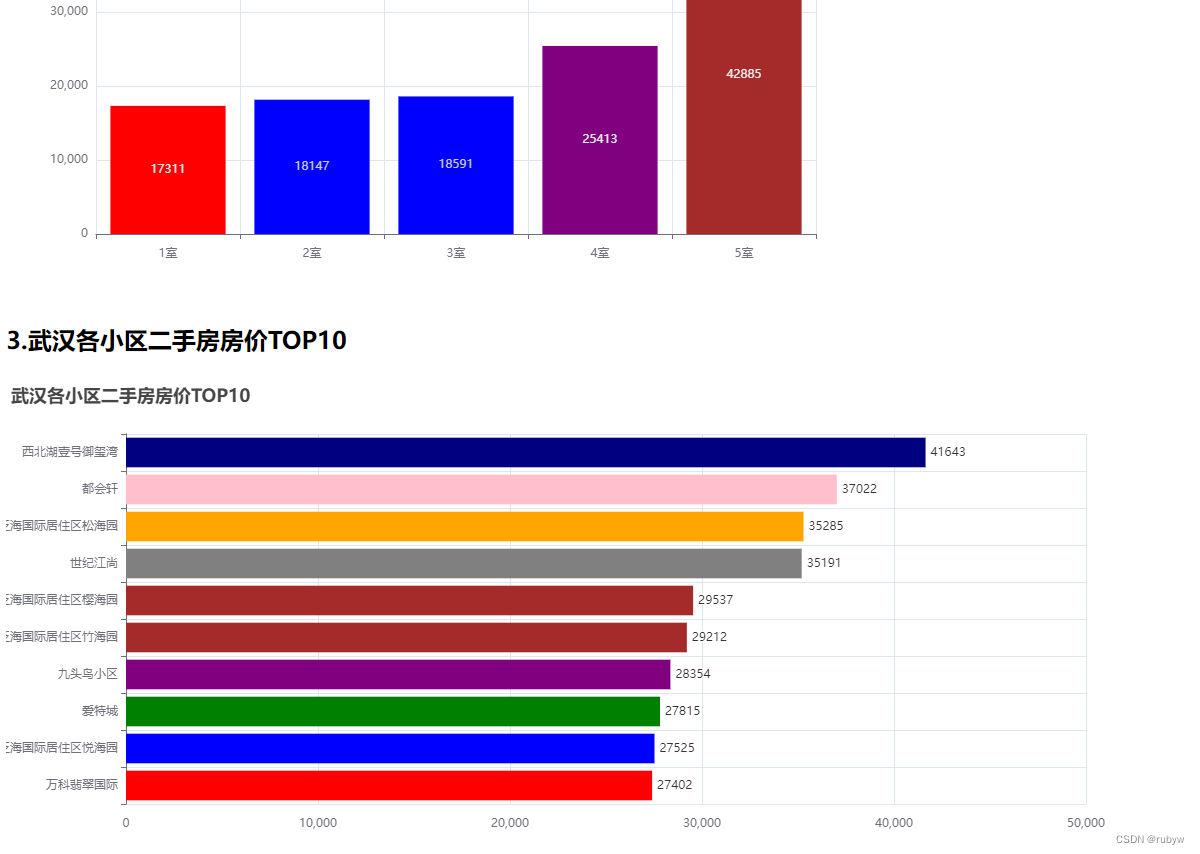
<h2>3.武汉各小区二手房房价TOP10</h2>
<div id="unit_price_analysis_by_estate" style="width:1200px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_estate_chart = echarts.init(document.getElementById('unit_price_analysis_by_estate'));
var option = {{ unit_price_analysis_by_estate_option | safe }};
unit_price_analysis_by_estate_chart.setOption(option);
</script>
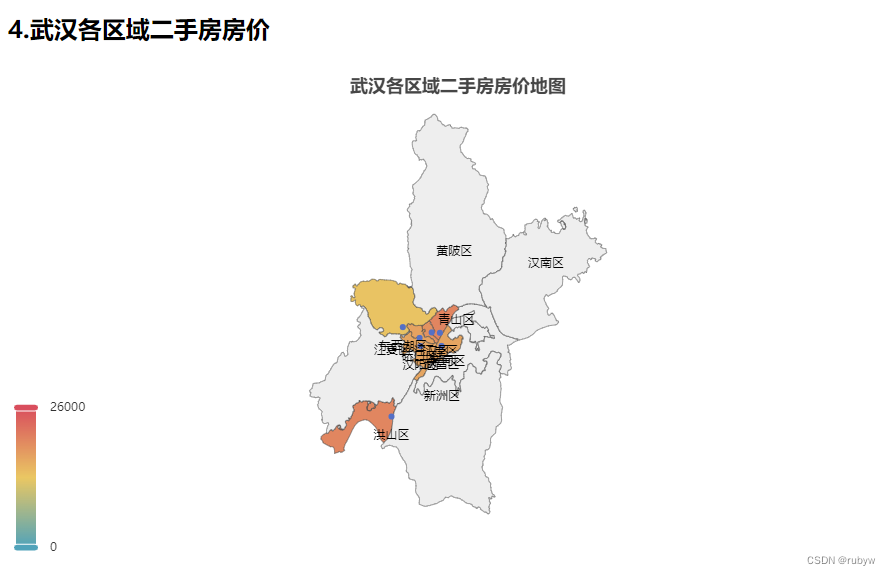
<h2>4.武汉各区域二手房房价</h2>
<!--<div><img src="/static/{{unit_price_analysis_by_map_png}}" style="width:1200px;height:600px"/></div>-->
<div id="unit_price_analysis_by_map" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_map_chart = echarts.init(document.getElementById('unit_price_analysis_by_map'));
var option = {{ unit_price_analysis_by_map_option | safe }};
unit_price_analysis_by_map_chart.setOption(option);
</script>
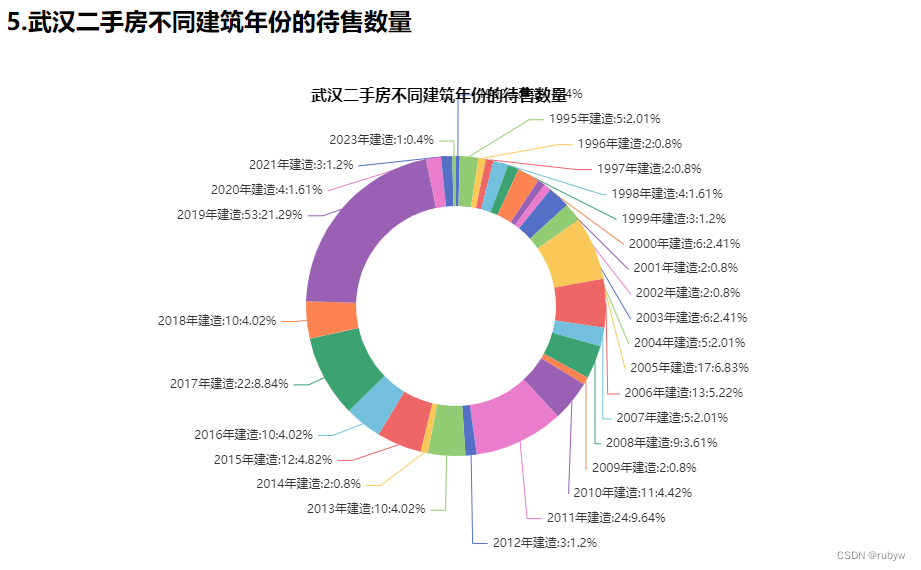
<h2>5.武汉二手房不同建筑年份的待售数量</h2>
<div id="sale_estate_analysis_by_year" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var sale_estate_analysis_by_year_chart = echarts.init(document.getElementById('sale_estate_analysis_by_year'));
var option = {{ sale_estate_analysis_by_year_option | safe }};
sale_estate_analysis_by_year_chart.setOption(option);
</script>
<h2>6.武汉二手房房价-单价分布</h2>
<div id="unit_price_analysis_by_histogram" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_histogram_chart = echarts.init(document.getElementById('unit_price_analysis_by_histogram'));
var option = {{ unit_price_analysis_by_histogram_option | safe }};
unit_price_analysis_by_histogram_chart.setOption(option);
</script>
<h2>7.武汉二手房房价-总价分布</h2>
<div id="total_price_analysis_by_histogram" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var total_price_analysis_by_histogram_chart = echarts.init(document.getElementById('total_price_analysis_by_histogram'));
var option = {{ total_price_analysis_by_histogram_option | safe }};
total_price_analysis_by_histogram_chart.setOption(option);
</script>
<h2>8.武汉二手房面积-单价关系</h2>
<div id="unit_price_analysis_by_scatter" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_scatter_chart = echarts.init(document.getElementById('unit_price_analysis_by_scatter'));
var option = {{ unit_price_analysis_by_scatter_option | safe }};
unit_price_analysis_by_scatter_chart.setOption(option);
</script>
<h2>9.武汉二手房销售热度词</h2>
<!--<div><img src="/static/{{hot_word_analysis_by_wordcloud_png}}" style="width:1200px;height:600px"/></div>-->
<div id="hot_word_analysis_by_wordcloud" class="chart-container" style="width:900px; height:500px;"></div>
<script type="text/javascript">
var hot_word_analysis_by_wordcloud_chart = echarts.init(document.getElementById('hot_word_analysis_by_wordcloud'), 'white', {renderer: 'canvas'});
var option = {{ hot_word_analysis_by_wordcloud_option | safe }};
hot_word_analysis_by_wordcloud_chart.setOption(option);
</script>
</body>
</html>
四、web可视化效果
运行report_web.py后可在浏览器打开网址**http://127.0.0.1:5000/show_all_analysis_chart**查看结果
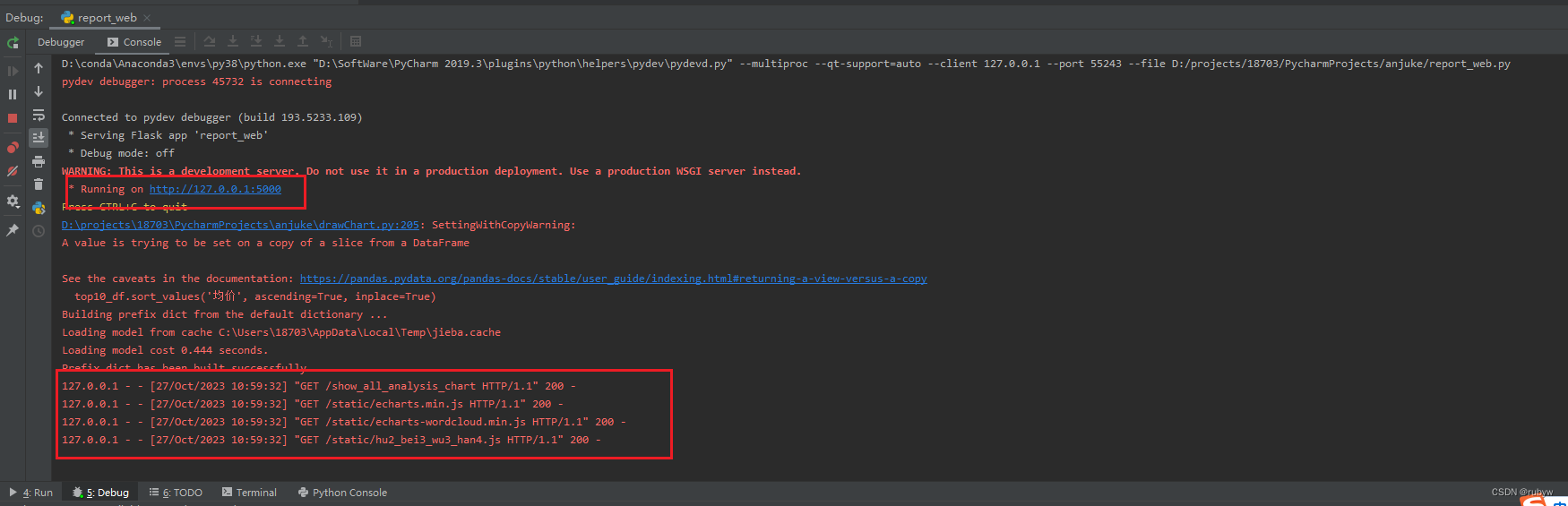
状态码全是200,说明成功,打开网址查看最终效果