LLM系列-大模型技术汇总
- 1. 大模型技术汇总-参数高效迁移学习方法
- 2. 千亿模型并行训练技术
- 2.1. 数据并行(Data Parallelism,DP)
- 2.2. 模型并行(Model Parallelism,MP)
- 2.2.1. 流水线并行(Pipeline Parallelism,PP)
- 2.2.2. 张量并行 (Tensor Parallelism,TP)
- 3. 大模型面试高频问题整理
- 3.1. GPT和Bert的区别?
- 3.2. NLP哪些场景不适用大模型?
- 3.3. ChatGPT的优缺点?
- 3.4. GPT系列的演进?
- 3.5. 为什么现在的大模型大多是decoder-only的架构?
- 3.6. LLaMA的主要结构?
- 3.7. 旋转位置编码的原理?
- 3.8. RMSNorm和LayerNorm的区别?
- 3.9. GLM是如何结合三种架构的?
- 3.10. encoder的attention和decoder的attention的区别?
- 3.11. 常见的大模型finetune方法?
- 3.12. LoRA的原理,一般用在什么层?
- 3.13. 低秩矩阵为什么表达能力弱?
- 3.14. ChatGPT的训练步骤?
- 3.15. RLHF分为几个阶段?
- 3.16. PPO的原理?
- 3.17. 为什么in-context learning有效?
- 3.18. ChatGPT思维链能力是如何获取的?
- 3.19. ChatGPT和 instructGPT的区别?
- 3.20. BPE、wordpiece、sentencepiece的区别?
- 3.21. attention的复杂度?attention的优化?
- 3.22. Multihead self-attention代码实现?
- 3.23. self-attention参数量计算?
- 3.24. attention中QKV的含义和作用?
- 3.25. attention mask是如何实现的?
- 3.26. layer normalization的优化?
- 3.27. layer normalization和batch normalization的区别?
- 3.28. 位置编码的方式对比?
- 3.29. Decoding方式对比?
- 3.30. Bert的优缺点?MLM和NSP两个任务后续的改进?
- 3.31. 国内做自研大模型的意义?
1. 大模型技术汇总-参数高效迁移学习方法
(Parameter-efficient Transfer Learning),即固定住Pretrain Language model的大部分参数,仅调整模型的一小部分参数来达到与Full fine-tuning接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)。
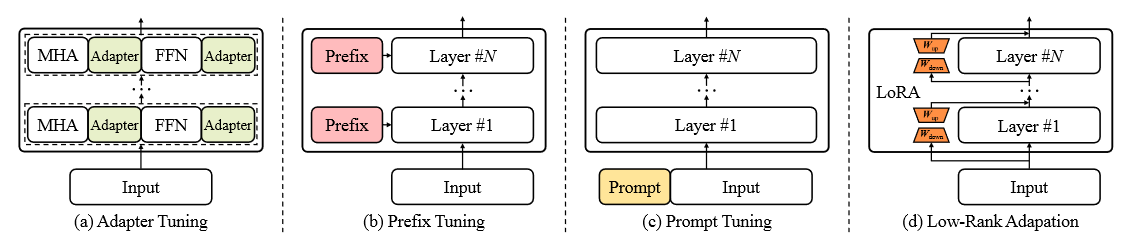
下面这 3 类方法在微调时都固定了预训练参数,只训练添加的额外模块。
- adapter
把一个称为 adapter 的模块插入到预训练模型的中间层 - Prefix Tuning
Prefix-tuning是一种基于前缀的轻量化微调方法,为了增加前缀向量在训练时的稳定性,作者采用了重参数化的方法,通过一个若干较小的前缀向量经过单层MLP生成正常规模的前缀向量。在输入或者隐层添加多个可学习的前缀 tokens
2.1 - Prompt-Tuning
是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题,主要在T5预训练模型上做实验。随着预训练模型参数量的增加,Prompt Tuning的方法会逼近Fine-tune的结果。
2.2. P-tuning
P-Tuning同样提出将Prompt转换为可以学习的Embedding层,但同时考虑到直接对Embedding参数进行优化会存在这样两个挑战:
-
- Discretenes:对输入正常语料的Embedding层已经经过预训练,而如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优。
-
- Association:没法捕捉到prompt embedding之间的相关关系。
2.3. P-tuning与Prefix-Tuning的区别
-
- 在Prefix Tuning是将额外的embedding加在开头,看起来更像是模仿Instruction指令;而P-Tuning的位置则不固定。
-
- Prefix Tuning通过在每个Attention层都加入Prefix Embedding来增加额外的参数,通过MLP来初始化;而P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP来初始化。
2.4. P-tuning-V2
P-Tuning v2的目标就是要让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。
-
- 不同模型规模:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差。
-
- 不同任务类型:Prompt Tuning和P-tuning这两种方法在sequence tagging任务上表现都很差。
2.5. P-tuning-V2比Prompt Tuning和P-tuning的好處
P-tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
-
- 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够parameter-efficient。
-
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
- LoRA
通过学习两个小参数的低秩矩阵来近似权重矩阵的参数更新
LoRA是一种基于低秩的轻量化微调方法,也是目前在大模型领域应用最多的方法。相较于Adapter,LoRA不需要对模型添加额外的参数化结构。而相较于Prefix-tuning,LoRA不需要对输入端进行修改。取而代之的是,LoRA通过对模型参数的优化量进行了低秩近似。
其理论依据在于:神经网络通常包含大量的全连接层,并通过执行矩阵乘法来完成前向传播。这些全连接层中的参数矩阵往往是满秩的,对模型的训练过程其实就是在学习优化这些参数矩阵。而预训练模型中的参数矩阵往往存在一个”本征维度“,即我们学习到的这些参数的优化量可以是低秩的,被映射到一个低维空间下也能保持很好的性能。在这样的前提下,我们可以只对参数矩阵中低秩的部分进行优化,并将整体的训练过程表示成一个低秩矩阵的优化过程:
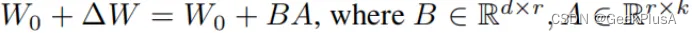
前向传播过程可以表示如下:
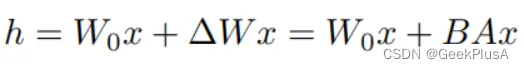
A、B是两个低维的矩阵,相较于原本的参数规模,待优化的参数规模被大大减小。整体的流程如下所示:
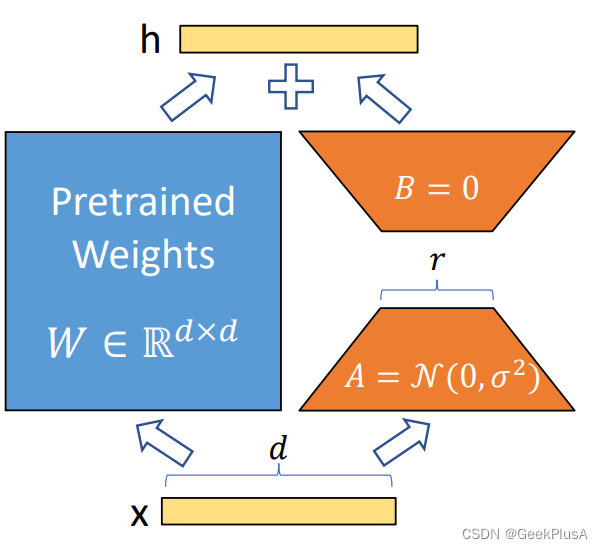
在RoBERTa,DeBERTa,GPT-2与GPT-3上,LoRA在只训练极少数参数的情况下取得了接近全参数微调的结果,证明了该方法的有效性。
參考:大模型微调技术汇总
2. 千亿模型并行训练技术
进行并行加速,可以从数据和模型两个维度进行考虑。
2.1. 数据并行(Data Parallelism,DP)
数据进行切分(Partition),并将同一个模型复制到多个设备上,并行执行不同的数据分片。
在数据并行系统中,每个计算设备都有整个神经网络模型的完整副本(Model Replica),进行迭代时,每个计算设备只分配了一个批次数据样本的子集,并根据该批次样本子集的数据进行网络模型的前向计算。假设一个批次的训练样本数为 N,使用 M 个计算设备并行计算,每个计算设备会分配到 N/M 个样本。前向计算完成后,每个计算设备都会根据本地样本计算损失误差得到 梯度 Gi(i 为加速卡编号),并将本地梯度 Gi 进行广播。所有计算设备需要聚合其他加速度卡给 出的梯度值,然后使用平均梯度 (ΣN i=1Gi)/N 对模型进行更新,完成该批次训练。
2.2. 模型并行(Model Parallelism,MP)
对模型进行划分, 将模型中的算子分发到多个设备分别完成
2.2.1. 流水线并行(Pipeline Parallelism,PP)
按模型的层切分到不同设备,即层间并 行或算子间并行(Inter-operator Parallelism)
- 流水线气泡(Pipeline Bubble)
计算图中的下游设备(Downstream Device)需要长时 间持续处于空闲状态,等待上游设备(Upstream Device)的计算完成,才能开始计算自身的任务。这种情况导致了设备的平均使用率大幅降低,形成了模型并行气泡(Model Parallelism Bubble),也称为流水线气泡(Pipeline Bubble)
2.2.2. 张量并行 (Tensor Parallelism,TP)
将计算图层内的参数切分到不同设备,即层内并行或算子内并行(Intra-operator Parallelism)
參考:千亿模型并行训练技术
3. 大模型面试高频问题整理
3.1. GPT和Bert的区别?
參考:GPT和Bert的区别
3.2. NLP哪些场景不适用大模型?
- 推荐
- 知识图谱
3.3. ChatGPT的优缺点?
3.4. GPT系列的演进?
3.5. 为什么现在的大模型大多是decoder-only的架构?
LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。
3.6. LLaMA的主要结构?
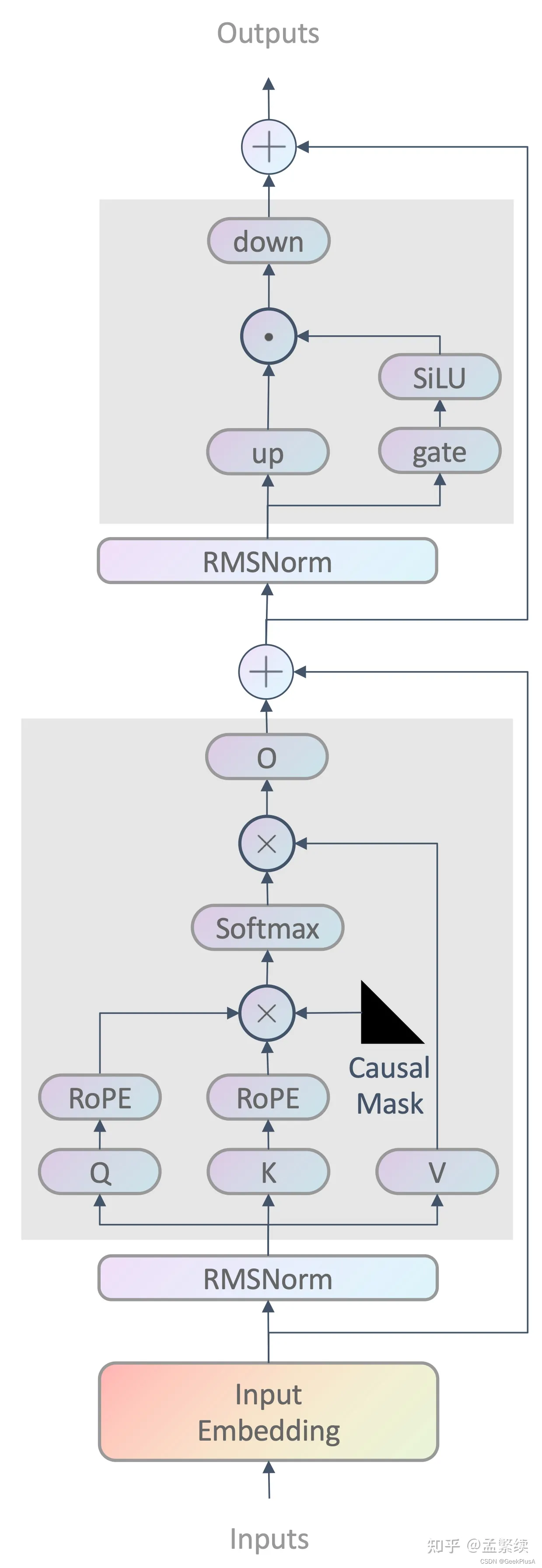
參考:LLaMA v1/2模型结构总览