阅读时间:2023-10-27
1 介绍
年份:2017
作者:Sylvestre-Alvise Rebuffi; Alexander Kolesnikov; Georg Sperl; Christoph H. Lampert ,牛津大学
期刊:Proceedings of the IEEE conference on Computer Vision and Pattern Recognition
引用量:2892
提出了一种名为iCaRL(增量分类器和表示学习)的学习系统的开发,它可以从数据流中随着时间学习新的概念。论文讨论了现有增量学习方法的局限性,并提出了一种训练策略,可以实现类增量学习,只需要同时存在少量类的训练数据,并且可以逐步添加新的类别。iCaRL同时学习强大的分类器和数据表示,这与以前的工作不同,以前的工作只能使用固定的数据表示,并且与深度学习架构不兼容。论文解释了iCaRL的主要组成部分,包括基于最近均值示例规则的分类、基于牧羊的优先选择例子和使用知识蒸馏和原型重演进行表示学习。对CIFAR-100和ImageNet数据集的实验证明,iCaRL可以在很长一段时间内逐步学习许多类别,而其他策略很快失败。
iCaRL(增量分类器和表示学习)是一种学习系统,通过处理数据流,可以随着时间的推移学习新的概念。iCaRL的主要组成部分包括分类器学习、样本管理和表示学习。分类器学习使用最接近均值的例子规则进行分类,样本管理使用基于聚集的方法选择重要的样本,表示学习使用知识蒸馏和原型演奏来提高性能。
2 创新点
(1)提出了一种名为iCaRL的学习系统,可以从数据流中逐步学习新概念。这种系统可以在只有少数几个类别的训练数据同时存在的情况下进行增量学习,并能够逐步添加新的类别。
(2)iCaRL同时学习强大的分类器和数据表示,这与之前的方法不同。之前的方法只能使用固定的数据表示,并且不适用于深度学习架构。
(3)iCaRL的主要组成部分包括使用最近样本均值规则进行分类、基于套牛算法的优先选择样本、使用知识蒸馏和原型回放进行表示学习等。
(4)在CIFAR-100和ImageNet数据集上的实验证明,iCaRL可以在很长时间内逐步学习许多类别,而其他策略很快失败。
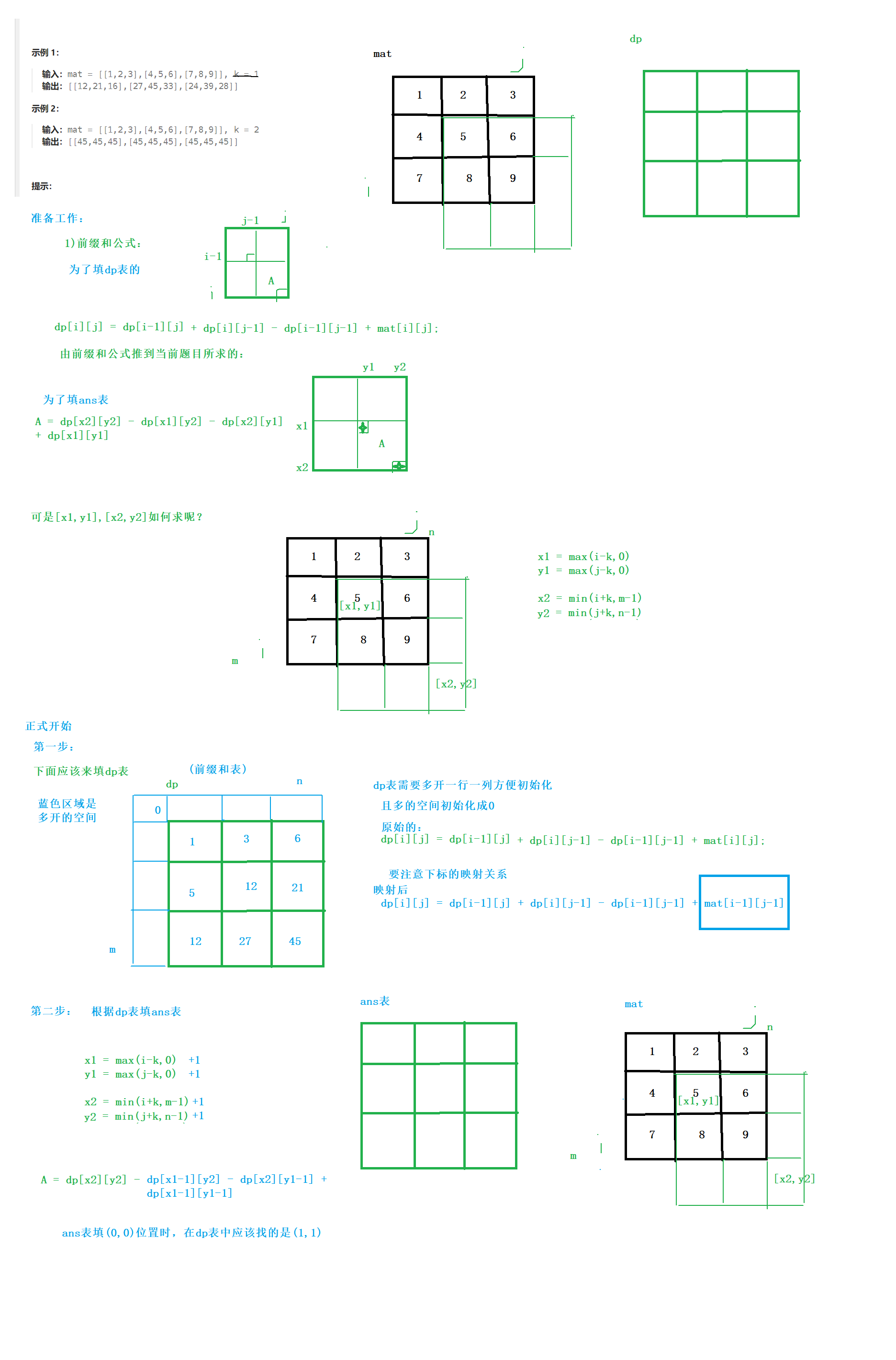
3 算法
(1)使用特征提取器
φ
(
⋅
)
\varphi (\cdot)
φ(⋅)对新旧数据(旧数据只取一部分)提取特征向量,并计算出各自的平均特征向量
把某一类的图像的特征向量都计算出来,然后求均值,注意本文对于旧数据,只需要计算一部分的数据的特征向量。

(2)通过最近均值分类算法(Nearest-Mean-of-Examplars) 计算出新旧数据的预测值

(3)在上面得到的预测值代入如下loss函数进行优化,最终得到模型。
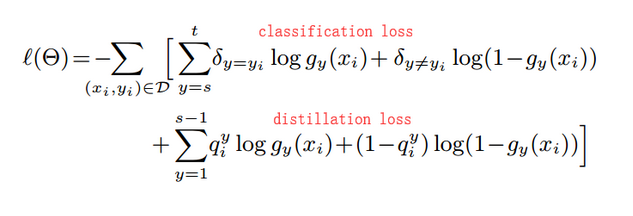
4 实验结果分析
iCaRL的实现,对于iCIFAR-100,我们依赖于theano包,并训练了一个具有32层的ResNet 。
对于iILSVRC,最大样本数为K = 20000,我们使用tensorflow框架训练一个具有18层的ResNet 。
iCIFAR-100基准:使用CIFAR-100[16]数据,并以每次2、5、10、20或50个类的批次进行训练。评估指标是测试集上的标准多类准确率。由于数据集规模适中,我们使用不同的类别顺序运行了该基准测试十次,并报告结果的平均值和标准差。
iILSVRC基准:使用ImageNet ILSVRC 2012[34]数据集的两个设置:只使用100个类的子集,按照每次10个类的批次进行训练(iILSVRC-small)或使用全部1000个类,按照每次100个类的批次进行训练(iILSVRC-full)。评估指标是数据集的val部分的top-5准确率。
(1)准确率评价
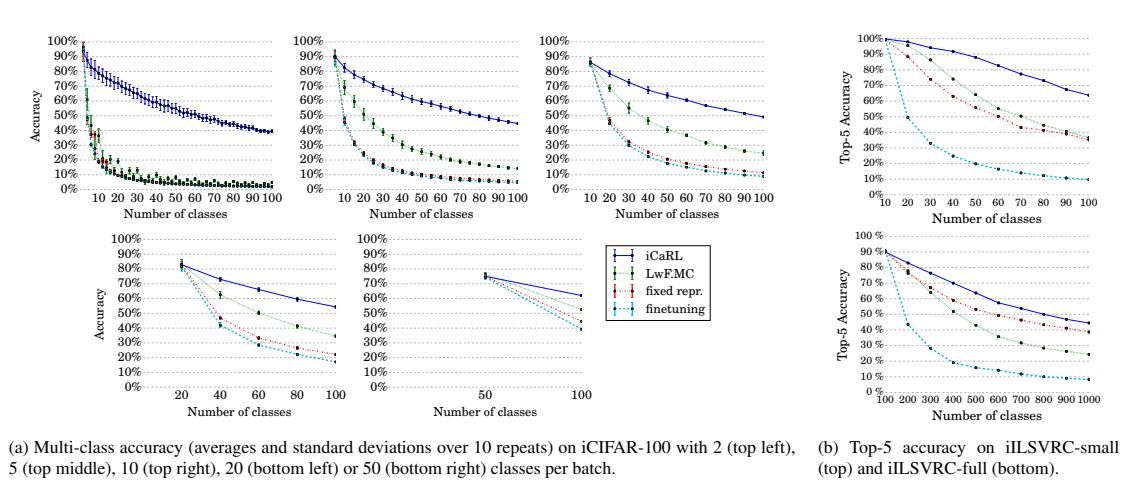
iCaRL明显优于其他方法。在训练完第一批数据后固定数据表示(fixed repr.)的结果比基于蒸馏的LwF.MC差,除了iILSVRC-full。在没有防止灾难性遗忘的情况下对网络进行微调(finetuning)获得最差的结果。作为对比,使用所有可用数据训练的相同网络的多类准确率为68.6%。
(2)混淆矩阵评价
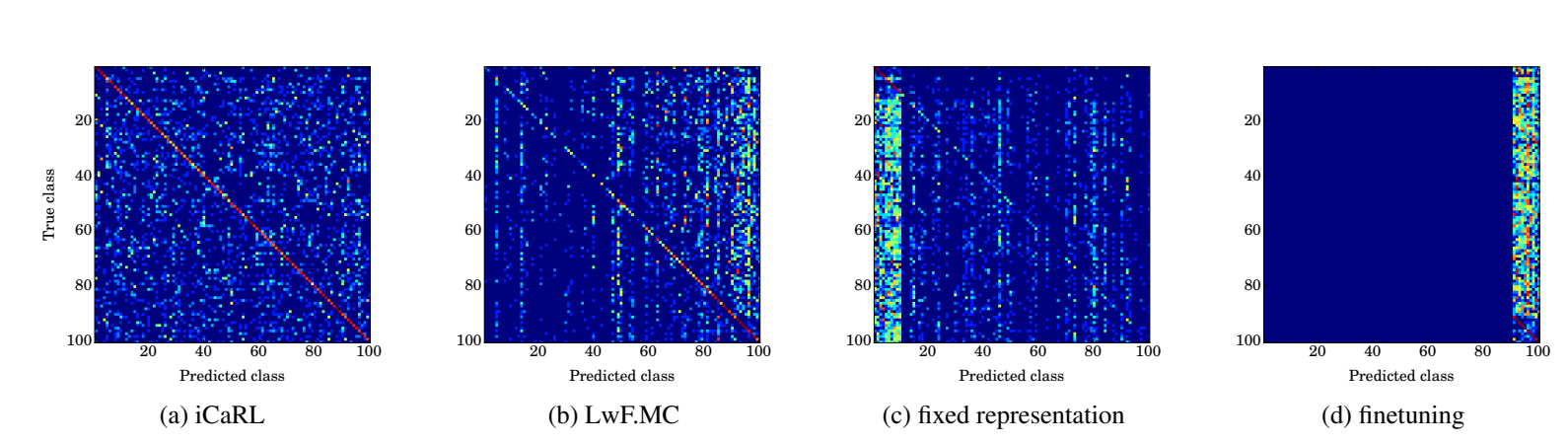
iCaRL的预测在所有类别上分布均匀,而LwF.MC倾向于更频繁地预测最近批次的类别。具有固定表示的分类器对于来自第一批次的类别有偏向性,而通过微调训练的网络仅预测来自最后一批次的类别标签。
(3)消融实验,差异性分析
从三个角度:用基于示例均值的分类规则、使用示例进行表示学习、使用蒸馏损失
- hybrid1:以与iCaRL相同的方式学习表示,但直接使用网络的输出进行分类,而不是使用基于示例均值的分类器。
- hybrid2:使用示例进行分类,但在训练过程中不使用蒸馏损失。
- hybrid3:在分类和表示学习过程中都不使用蒸馏损失和示例,但在表示学习过程中使用示例。

混合设置主要在iCaRL和LwF.MC之间取得了结果,表明确实iCaRL的所有新组成部分都对其性能有所贡献。特别是与hybrid 1相比,iCaRL的比较显示基于示例均值的分类器在较小批量大小(即执行更多表示更新时)特别有优势。比较iCaRL和hybrid 2可以看出,在非常小的类别批量大小情况下,与仅使用原型相比,蒸馏甚至可能降低分类准确率。对于更大的批量大小和较少的更新次数,使用蒸馏损失显然是有优势的。最后,将hybrid 3的结果与LwF.MC进行比较清楚地显示了示例在防止灾难性遗忘方面的有效性。
5 思考
(1)蒸馏思想来源于论文【. Distilling the knowledge in a neural network】,最初提出了蒸馏方法来在不同的神经网络之间传递信息,在iCaRL中将其用于单个网络在不同时间点之间的信息传递 。
(2)本文启发于Lwf论文【. Learning without forgetting】
(3)“iCaRL会为每个类别使用m = K/t个样例(向上取整)。通过这样做,可以确保可用的K个样例的内存限额始终被充分利用,但不会超过”。这个算法思想,在GEM算法中所沿用。但具体是如何实现的,还不清楚。
(4)算法2、4、5具体的用处,还不清楚,需要结合代码理解


6 代码
https://github.com/srebuffi/iCaRL