GGML
以纯C语言编写的框架,让用户可以在MacBook电脑上轻松运行大型语言模型,这种模型通常在本地运行成本较高。目前,这一框架主要被业余爱好者使用,但在企业模型部署方面也有广泛的应用前景。
量化快速入门
我们首先简单介绍一下量化的概念:
量化是一种减少用于表示数字或值的比特数的技术。由于量化减少了模型大小,因此它有利于在cpu或嵌入式系统等资源受限的设备上部署模型。
一种常用的方法是将模型权重从原始的16位浮点值量化为精度较低的8位整数值。
llm已经展示了出色的能力,但是它需要大量的CPU和内存,所以我们可以使用量化来压缩这些模型,以减少内存占用并加速计算推理,并且保持模型性能。我们将通过将权重存储在低精度数据类型中来降低模型参数的精度。
计划
LLMOPS:
【算法、向量DB、图数据库、langchain】
MLOPS:
【算法仓库、数据管理、标定、训练、推理、量化、连接和下发、向量DB、图数据库】
LLM@AI,输出到dataq
云原生:kubeDL,PAI,kubeflow
KubeDL 是阿里开源的基于 Kubernetes 的 AI 工作负载管理框架,取自 “Kubernetes-Deep-Learning” 的缩写;旨在使深度学习工作负载能够更轻松、更高效地在 Kubernetes 上运行。KubeDL 是一个 CNCF Sandbox 项目。
AI量化
AI应用
数据工程
AutoGPT AgentGPT
AgentGPT是一种基于web的解决方案。它允许配置和部署自治AI代理,并让它完成任何目标。它将尝试通过思考要做的任务、执行任务并从结果中学习来达到目标。
相关大模型:
Llama,Chatglm,BLOOM,Baichuan,通义,文心
相关网站和插件
Local AI,Close AI,Langchain
https://console.bce.baidu.com/qianfan/overview
https://modelscope.cn/home
https://openbayes.com/
https://fastgpt.run/account?currentTab=inform
多模态(multimodal)
是指涉及到多种模态(如视觉、语音、文本等)的数据或信息。在AI领域中,多模态通常指将多种类型的数据或信息相结合,来解决特定的问题或任务。以图像识别为例,图像可以被视为一种视觉模态,而对图像的分类或识别就是单模态任务。而如果将图像和语音或文本数据相结合,就可以做更复杂的任务,这些任务需要利用图像和语言模态的信息。
以下是一些常见的多模态任务:
图像分类(Classification): 给定一张图片,需要将其分类到不同的类别。
图像描述(Image Caption): 给定一张图片,根据图片生成相应的文字描述。
视觉问答(VQA): 根据对图像的理解,回答与之相关的问题。
什么是大模型?
通常至少具备两个要素:
1.跨任务的通用性;
2.跨领域的通用性;
大模型的强大之处,正是来自于这种令人惊喜的通用性,统一了诸多任务的形式并具有强大的泛化能力,可以处理多个不同领域的问题。而训练数据、参数规模、计算量的“大”是大模型的一个必要而不充分条件,是为了涌现出强大通用能力所必要的Scaling Up。
行业大模型?
若是基于以上对大模型的认识,我们可以理解为什么行业大模型会受到人们的质疑。
因为,使用垂直领域数据所训练出来的行业大模型,大都在某种程度上牺牲了其在诸多领域上的通用性,换来在特定领域上的优异效果,也就不再符合大模型的定义了。
所以,行业大模型,更准确的说法或许是通用大模型在垂直领域的应用,也就是在通用大模型的基础上基于行业数据进行训练、微调,用于解决行业问题,从概念上讲已经一定程度不再属于大模型。
通过这种新的定义角度来看,就可以更好地理解行业大模型究竟是什么。
为了保持行文的一致性,以下继续采用行业大模型的称呼。
1.向量召回
向量召回(Vector Retrieval)是一种信息检索技术,通常应用于大规模文本或内容检索系统,以快速有效地检索相关的文档或内容。它基于向量空间模型(Vector Space Model)和相似性度量来实现检索,其中文档和查询都被表示为向量,并通过计算它们之间的相似度来找到最相关的文档。
以下是一个示例来说明向量召回的工作方式:
示例:新闻文章检索
假设你正在构建一个新闻文章检索系统,用户可以输入一个关键词或查询,系统将返回最相关的新闻文章。这是向量召回如何应用的一个例子:
建立文档向量:
首先,需要为每篇新闻文章构建一个文档向量。这可以通过将文章中的关键词或短语映射到一个高维向量空间中的位置来完成。这些向量通常被称为文档向量。
建立查询向量:
当用户输入一个查询时,该查询也被映射为一个向量,通常称为查询向量。这个查询向量包含了查询中的关键词或短语在向量空间中的位置。
计算相似度:
接下来,系统会计算查询向量与每个文档向量之间的相似度。常见的相似度度量包括余弦相似度(Cosine Similarity)。
召回:
系统会按相似度的降序排列文档向量,然后返回与查询向量相似度最高的文档,通常是前几篇。这些文档就是向量召回的结果。
例如,如果用户在搜索框中输入了查询 “技术新闻”,系统会将这个查询映射为一个查询向量,然后与存储在系统中的所有新闻文章的文档向量计算相似度。系统将返回与查询向量相似度最高的新闻文章,这些文章通常包括了与技术相关的新闻。
向量召回是一种高效的检索方法,尤其适用于处理大规模的文本或内容检索任务。它能够快速找到与查询相关的文档,以满足用户信息检索的需求。
2.什么是奖励模型
奖励模型:
奖励模型是强化学习中的一个关键概念。它代表了一个问题的目标或任务。在强化学习中,一个代理(agent)尝试通过与环境互动来学习最佳的行为策略。这个学习的过程是通过最大化获得的累积奖励来实现的。奖励模型定义了环境对代理行为的评估方式,给出了代理在不同状态下采取不同动作的反馈信号。奖励通常是一个数值,代理的目标是找到一种策略,最大化长期累积奖励。
假设我们正在考虑一个经典的强化学习问题:训练一个智能代理来玩一个迷宫游戏。在这个游戏中,代理会从起始位置开始,然后根据它的行动选择来移动,直到到达目标位置或者走入陷阱。
在这个例子中,奖励模型将是一个定义了在每个状态下采取不同行动的奖励信号。
起始状态:
奖励模型会为起始状态(比如迷宫的初始位置)分配一个初始奖励值,通常为0。
目标状态:
当代理到达目标位置时,奖励模型会给予一个正奖励,比如+10分,表示代理成功完成了任务。
陷阱:
如果代理走入了陷阱,奖励模型会给予一个负奖励,比如-5分,表示代理走入了一个不好的状态。
中间状态:
对于中间的状态,奖励模型会根据当前状态和采取的行动来分配奖励。例如,如果代理选择了向前移动,并且没有走入陷阱,奖励模型可能会给予一个小正奖励,比如+1分,以鼓励代理朝着目标前进。
奖励模型的目的是引导代理在每个状态下采取最佳行动,以最大化长期累积奖励。代理的目标是通过学习一个策略来选择动作,以使得在每个状态下的期望累积奖励最大化。
这只是一个简单的例子,实际上,奖励模型可能会更加复杂,包括连续的状态空间、大量的行动选择等等。不过,这个例子可以帮助你理解奖励模型是如何在强化学习中起作用的。
3.预训练和微调
深度学习中常用的两个阶段,用于训练神经网络模型,特别是在自然语言处理领域中非常流行。这两个阶段通常结合使用,以获得更好的模型性能。
预训练(Pretraining):
预训练是指在大规模的数据集上,使用一个深度神经网络模型(通常是一个较大的模型)进行初始训练。这个初始训练的目标通常是学习到数据的通用表示。在自然语言处理中,这意味着模型学习了大量文本数据的语言知识,包括词汇、语法、语义等。
在计算机视觉中,预训练可以包括对大量图像数据的特征学习。
预训练的模型通常是一个自编码器或一个Transformer架构,其中最著名的包括BERT、GPT(Generative Pre-trained Transformer)、ResNet等。这些模型在预训练阶段,通常使用大规模的无标签数据,如维基百科、互联网文本或图像,来学习通用的特征表示。
微调(Fine-tuning):
微调是在预训练模型的基础上,使用特定任务的有标签数据进行进一步训练的过程。在微调阶段,模型的权重被调整以适应特定任务,如文本分类、命名实体识别、图像分类等。微调的目标是将模型的通用知识与特定任务的知识结合起来,从而提高模型在该任务上的性能。
由于大模型的无监督预训练非常耗时(预训练太慢啦)、耗力(没有精力从头预训练)、耗钱(啥不需要钱啊)、耗资源(没有那么多显卡可用,能用的显卡配置也不好)。因此大模型的训练(对于我们非专业大模型工作者来说)只能是微调,现有的各种大模型训练基本上都指的是微调。
什么是微调呢?简单来说,就是在别人训练好的大模型之后,通过少部分数据再训一训,来适应自己领域的需求。那么问题来哩:再训一训,我也训不动啊,大模型的参数量真的太多了,那怎么办呢?最直观的想法就是:那我就不全量参数微调,只更新部分参数呗。这就衍生了指令微调的几种方法。
指令微调
IFT(Instruction Fine-Tuning):指令微调,指令是指用户传入的目的明确的输入文本,指令微调用以让模型学会遵循用户的指令。OpenAI叫做SFT(Supervised Fine-Tuning),是一样的意思。
除了指令微调以外,大模型还有一个绝佳的法宝—人类反馈强化学习(RLHF),听名字挺复杂的,简单来说,就是通过人工的标注来强化模型的能力,去修正模型的一些不当输出,让大模型的输出真的像是人在回答一样。具体的做法在第三节介绍。可惜的是,由于需要大量的人工标注的工作,还是需要人力、财力,大部分的场景都无法支持。因此,我们很难应用到人类反馈强化学习。
常用算法
-
LORA的原理就是在模型的Linear层,的旁边,增加一个“旁支”,这个“旁支”的作用,就是代替原有的参数矩阵W进行训练。
-
PERT全称Parameter-Efficient Fine-Tuning,旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
-
Freeze 方法,即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,以达到在单卡或不进行 TP 或 PP 操作,就可以对大模型进行训练。在语言模型模型微调中,Freeze 微调方法仅微调 Transformer 后几层的全连接层参数,而冻结其它所有参数。优点:大量减少了大语言模型的微调参数,是一种参数高效的微调方法;由于只需微调高层特征,加快了模型的收敛,节约了微调的时间;最大程度地保留了大语言模型预训练所学习到的语言的 “共性”,可解释性较强。
人类反馈强化学习(RLHF)
论文:《Training language models to follow instructions with human feedback》InstructGPT是ChatGPT的前身,主要探究了用RLHF(Reinforcement Learning from Human Feedback)方法使大模型中对齐人类意图。
GPT等大型语言模型基于Prompt的zero shot的学习范式有一个很大的问题是,预训练的模型完成的任务是后继文本的预测,这和具体任务的要求有一些偏离,生成的结果也不一定符合人的意图。因此需要以某种形式fine-tune来对齐这一点。
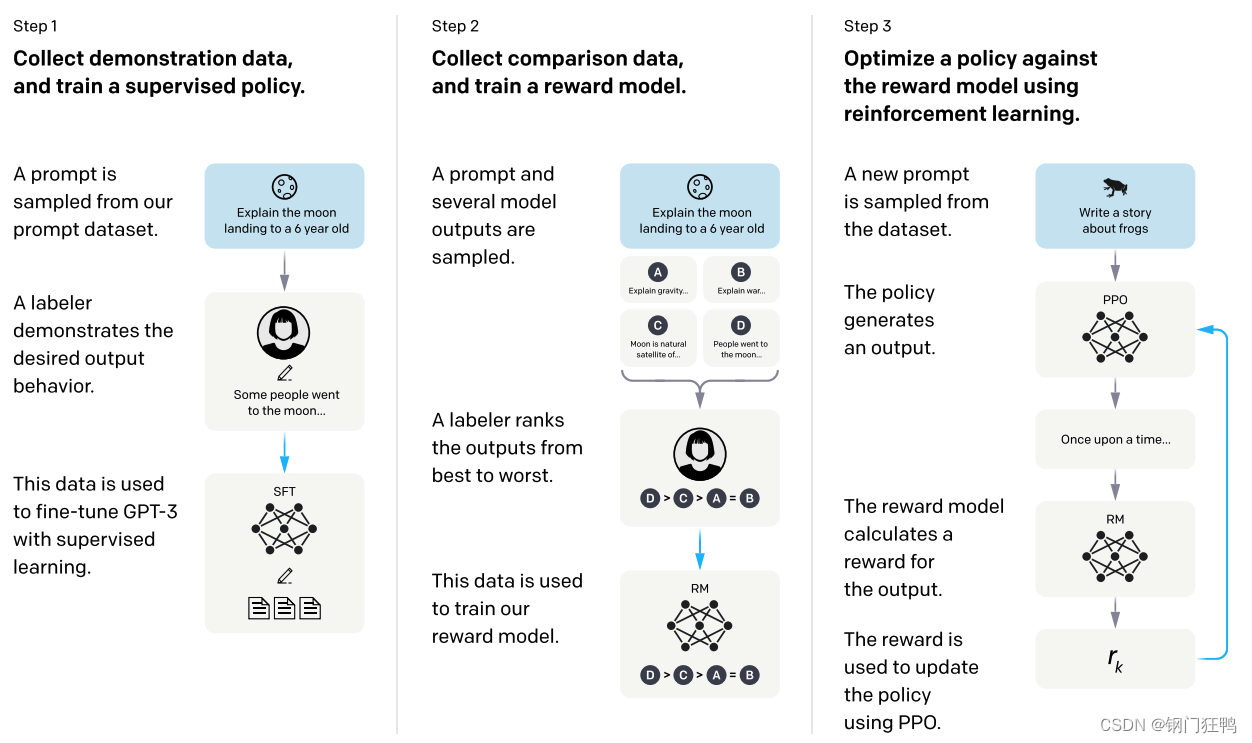
方法是三步走:
- 使用人工给出的示范性数据监督训练策略模型(SFT微调模型)
- 使用人工排序的对比性数据训练奖赏模型(训练reward model)
- 通过强化学习(使用了奖赏模型)训练策略模型(强化学习)
预训练和微调区别?1、费用差距巨大。2、时间成本差异巨大。
推理
在机器学习中,模型的推理是指在训练完成后,将输入数据输入到模型中,以生成预测结果或执行特定任务。
NL TO SQL
将自然语言(NL)转换为SQL(Structured Query Language)是一项自然语言处理(NLP)任务,其中系统尝试从用户提供的自然语言问题或指令中生成相应的数据库查询语句。这个任务通常涉及到文本理解、语法分析、语义理解和数据库查询生成。
以下是一个简单的示例,将一个自然语言问题转化为SQL查询:
自然语言问题: “找出所有年龄小于30岁的学生的名字和课程名称。”
对应的SQL查询:
sql
SELECT Students.name, Courses.name
FROM Students
JOIN Enrollments ON Students.student_id = Enrollments.student_id
JOIN Courses ON Enrollments.course_id = Courses.course_id
WHERE Students.age < 30;
这个SQL查询使用了SQL语法来从数据库中检索所需的信息。它涉及到了以下几个步骤:
SELECT Students.name, Courses.name:这是选择要返回的列的部分,它要求返回学生的名字和他们所选课程的名称。
FROM Students:这是指定要从哪个表中检索数据,即"Students"表。
JOIN:这是连接不同表的方式,它连接了"Students"表、"Enrollments"表和"Courses"表。
ON:这是指定连接条件的部分,它告诉数据库如何将这些表连接在一起,通常基于共享的键(在这种情况下是学生ID和课程ID)。
WHERE Students.age < 30:这是一个筛选条件,它限制了只返回年龄小于30岁的学生的信息。
需要注意的是,NL to SQL任务是一个复杂的自然语言处理任务,需要强大的自然语言理解和数据库查询生成技术。实际的系统可能会涉及更复杂的查询,多表连接,聚合函数等。通常,这种任务需要训练大规模的模型来实现。
参考:https://developer.aliyun.com/article/1353018
基于文档的大模型
Temperature & Top-k & Top-p
较低的Temperature意味着较少的随机性;Temperature为 0 将始终产生相同的输出。执行具有“正确”答案的任务(如问题回答或总结)时,较低的Temperature(小于 1)更合适。如果模型开始自我重复,则表明Temperature过低。
Temperature意味着更多的随机性,这可以帮助模型给出更有创意的输出。如果模型开始偏离主题或给出无意义的输出,则表明Temperature过高。
“Top-k” 和 “Top-p” 是用于生成文本的自然语言处理模型中的两种不同采样技术,通常用于生成多个可能的下一个单词或标记。
Top-k 采样是一种从概率分布中选择前 k 个最有可能的单词或标记的策略。在生成文本时,模型计算每个可能的单词的概率,并选择概率最高的 k 个单词,然后从中随机选择一个作为下一个单词。这可以确保生成的文本具有较高的可预测性,因为只有概率最高的单词会被考虑。
示例:假设模型生成下一个单词的概率如下:单词 A(0.4)、单词 B(0.3)、单词 C(0.2)、单词 D(0.1)。如果 k=2,那么在Top-k采样中,模型会选择单词 A 和单词 B 中的一个。
Top-p 采样是一种从概率分布中选择一组累积概率达到给定概率阈值 p 的最高概率单词或标记的策略。这种方法可以确保生成的文本具有多样性,因为它不仅考虑了最可能的单词,还考虑了次可能的单词。
示例:假设模型生成下一个单词的概率如下:单词 A(0.4)、单词 B(0.3)、单词 C(0.2)、单词 D(0.1)。如果 p=0.7,那么在Top-p采样中,模型会选择单词 A、单词 B 和单词 C,因为它们的累积概率(0.4 + 0.3 + 0.2)达到了 0.7。
Chatglm模型部署
1.环境,_低配GPU卡( rtx-3090,24核CPU,24G显存,30G内存)
2.代码调用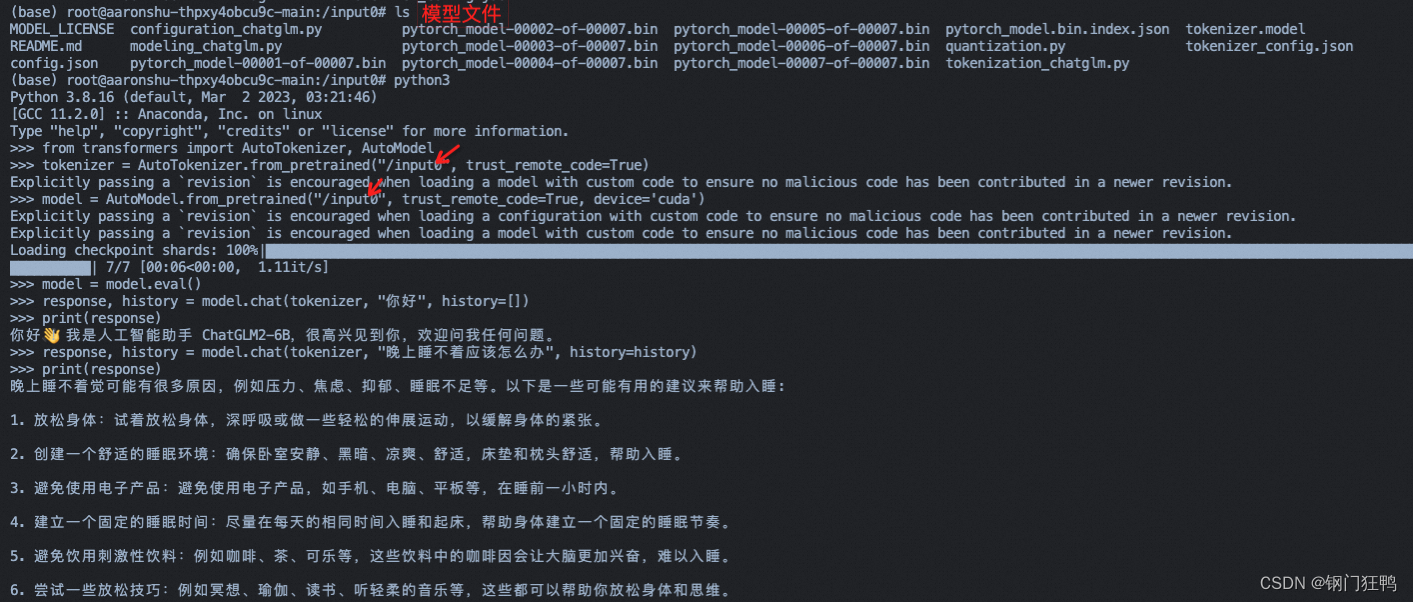
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
3.网页版 Demo
打开一个新的终端页面,输入命令 cd ChatGLM-6B 切换到目录 ChatGLM-6B,输入命令 python web_demo.py 运行 Gradio demo后按照提示打开

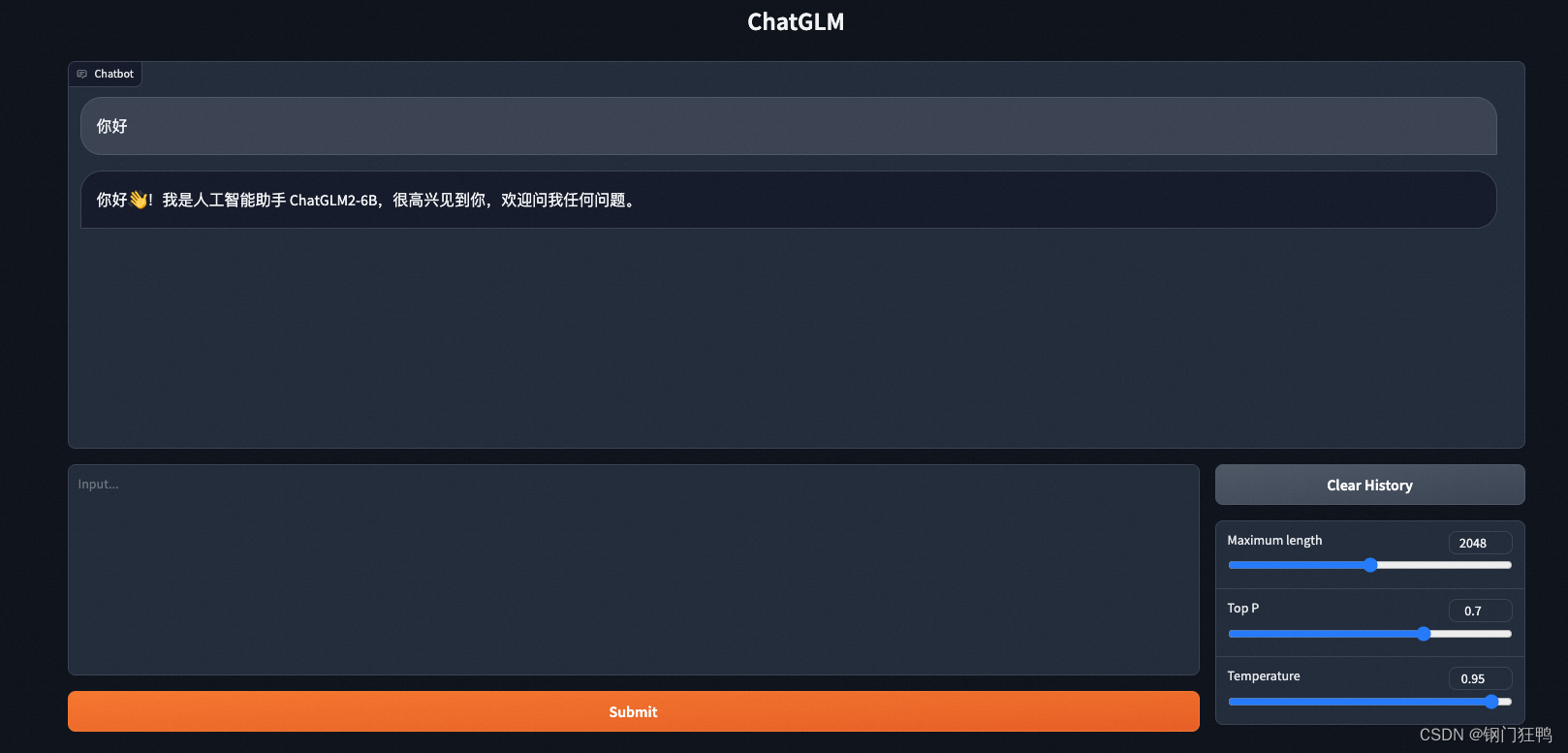
4.命令行 Demo,运行python cli_demo.py

5API调用
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
执行python api.py




![[每周一更]-(第69期):特殊及面试的GIT问题解析](https://img-blog.csdnimg.cn/d7652b7512f240bbbb1182e6abe9045d.png#pic_center)