这是做什么用的
框架用途
在采集大量新闻网站时,不可避免的遇到动态加载的网站,这给配模版的人增加了很大难度。本来配静态网站只需要两个技能点:xpath和正则,如果是动态网站的还得抓包,遇到加密的还得js逆向。
所以就需要用浏览器渲染这些动态网站,来减少了配模板的工作难度和技能要求。动态加载的网站在新闻网站里占比很低,需要的硬件资源相对于一个人工来说更便宜。
实现方式
采集框架使用浏览器渲染有两种方式,一种是直接集成到框架,类似GerapyPyppeteer,这个项目你看下源代码就会发现写的很粗糙,它把浏览器放在_process_request方法里启动,然后采集完一个链接再关闭浏览器,大部分时间都浪费在浏览器的启动和关闭上,而且采集多个链接会打开多个浏览器抢占资源。
另一种则是将浏览器渲染独立成一个服务,类似scrapy-splash,这种方式比直接集成要好,本来就是两个不同的功能,实际就应该解耦成两个单独的模块。不过听前辈说这东西不太好用,会有内存泄漏的情况,我就没测试它。
自己实现
原理:在自动化浏览器中嵌入http服务实现http控制浏览器。这里我选择aiohttp+pyppeteer。之前看到有大佬使用go的rod来做,奈何自己不会go语言,还是用Python比较顺手。
后面会考虑用playwright重写一遍,pyppeteer的github说此仓库不常维护了,建议使用playwright。
开始写代码
web服务
from aiohttp import web
app = web.Application()
app.router.add_view('/render.html', RenderHtmlView)
app.router.add_view('/render.png', RenderPngView)
app.router.add_view('/render.jpeg', RenderJpegView)
app.router.add_view('/render.json', RenderJsonView)然后在RenderHtmlView类中写/render.html请求的逻辑。/render.json是用于获取网页的某个ajax接口响应内容。有些情况网页可能不方便解析,想拿到接口的json响应数据。
初始化浏览器
浏览器只需要初始化一次,所以启动放到on_startup,关闭放到on_cleanup
c = LaunchChrome()
app.on_startup.append(c.on_startup_tasks)
app.on_cleanup.append(c.on_cleanup_tasks)其中on_startup_tasks和on_cleanup_tasks方法如下:
async def on_startup_tasks(self, app: web.Application) -> None:
page_count = 4
await asyncio.create_task(self._launch())
app["browser"] = self.browser
tasks = [asyncio.create_task(self.launch_tab()) for _ in range(page_count-1)]
await asyncio.gather(*tasks)
queue = asyncio.Queue(maxsize=page_count+1)
for i in await self.browser.pages():
await queue.put(i)
app["pages_queue"] = queue
app["screenshot_lock"] = asyncio.Lock()
async def on_cleanup_tasks(self, app: web.Application) -> None:
await self.browser.close()page_count为初始化的标签页数,这种常量一般定义到配置文件里,这里我图方便就不写配置文件了。
首先初始化所有的标签页放到队列里,然后存放在app这个对象里,这个对象可以在RenderHtmlView类里通过self.request.app访问到, 到时候就能控制使用哪个标签页来访问链接
我还初始化了一个协程锁,后面在RenderPngView类里截图的时候会用到,因为多标签不能同时截图,需要加锁。
超时停止页面继续加载
async def _goto(self, page: Optional[Page], options: AjaxPostData) -> Dict:
try:
await page.goto(options.url,
waitUntil=options.wait_util, timeout=options.timeout*1000)
except PPTimeoutError:
#await page.evaluate('() => window.stop()')
await page._client.send("Page.stopLoading")
finally:
page.remove_all_listeners("request")有时间页面明明加载出来了,但还在转圈,因为某个图片或css等资源访问不到,强制停止加载也不会影响到网页的内容。
Page.stopLoading和window.stop()都可以停止页面继续加载,忘了之前为什么选择前者了
定义请求参数
class HtmlPostData(BaseModel):
url: str
timeout: float = 30
wait_util: str = "domcontentloaded"
wait: float = 0
js_name: str = ""
filters: List[str] = []
images: bool = 0
forbidden_content_types: List[str] = ["image", "media"]
cache: bool = 1
cookie: bool = 0
text: bool = 1
headers: bool = 1url: 访问的链接timeout: 超时时间wait_util: 页面加载完成的标识,一般都是domcontentloaded,只有截图的时候会选择networkidle2,让网页加载全一点。更多的选项的选项请看:Puppeteer waitUntil Optionswait: 页面加载完成后等待的时间,有时候还得等页面的某个元素加载完成js_name: 预留的参数,用于在页面访问前加载js,目前就只有一个js(stealth.min.js)用于去浏览器特征filters: 过滤的请求列表, 支持正则。比如有些css请求你不想让他加载images: 是否加载图片forbidden_content_types: 禁止加载的资源类型,默认是图片和视频。所有的类型见: resourcetypecache: 是否启用缓存cookie: 是否在返回结果里包含cookietext: 是否在返回结果里包含htmlheaders: 是否在返回结果里包含headers
图片的参数
class PngPostData(HtmlPostData):
render_all: int = 0
text: bool = 0
images: bool = 1
forbidden_content_types: List[str] = []
wait_util: str = "networkidle2"参数和html的基本一样,增加了一个render_all用于是否截取整个页面。截图的时候一般是需要加载图片的,所以就启用了图片加载
怎么使用
多个标签同时采集
默认是启动了四个标签页,这四个标签页可以同时访问不同链接。如果标签页过多可能会影响性能,不过开了二三十个应该没什么问题
请求例子如下:
import sys
import asyncio
import aiohttp
if sys.platform == 'win32':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def get_sign(session, delay):
url = f"http://www.httpbin.org/delay/{delay}"
api = f'http://127.0.0.1:8080/render.html?url={url}'
async with session.get(api) as resp:
data = await resp.json()
print(url, data.get("status"))
return data
async def main():
headers = {
"Content-Type": "application/json",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
loop = asyncio.get_event_loop()
t = loop.time()
async with aiohttp.ClientSession(headers=headers) as session:
tasks = [asyncio.create_task(get_sign(session, i)) for i in range(1, 5)]
await asyncio.gather(*tasks)
print("耗时: ", loop.time()-t)
if __name__ == "__main__":
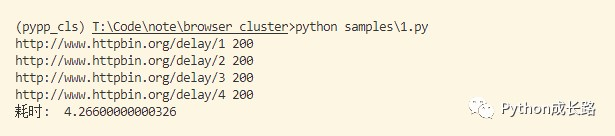
asyncio.run(main())http://www.httpbin.org/delay后面跟的数字是多少,网站就会多少秒后返回。所以如果同步运行的话至少需要1+2+3+4秒,而多标签页异步运行的话至少需要4秒
结果如图,四个链接只用了4秒多点:
拦截指定ajax请求的响应
import json
import sys
import asyncio
import aiohttp
if sys.platform == 'win32':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def get_sign(session, url):
api = f'http://127.0.0.1:8080/render.json'
data = {
"url": url,
"xhr": "/api/", # 拦截接口包含/api/的响应并返回
"cache": 0,
"filters": [".png", ".jpg"]
}
async with session.post(api, data=json.dumps(data)) as resp:
data = await resp.json()
print(url, data)
return data
async def main():
urls = ["https://spa1.scrape.center/"]
headers = {
"Content-Type": "application/json",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
loop = asyncio.get_event_loop()
t = loop.time()
async with aiohttp.ClientSession(headers=headers) as session:
tasks = [asyncio.create_task(get_sign(session, url)) for url in urls]
await asyncio.gather(*tasks)
print(loop.time()-t)
if __name__ == "__main__":
asyncio.run(main())请求https://spa1.scrape.center/这个网站并获取ajax链接中包含/api/的接口响应数据,结果如图:

请求一个网站用时21秒,这是因为网站一直在转圈,其实要的数据已经加载完成了,可能是一些图标或者css还在请求。
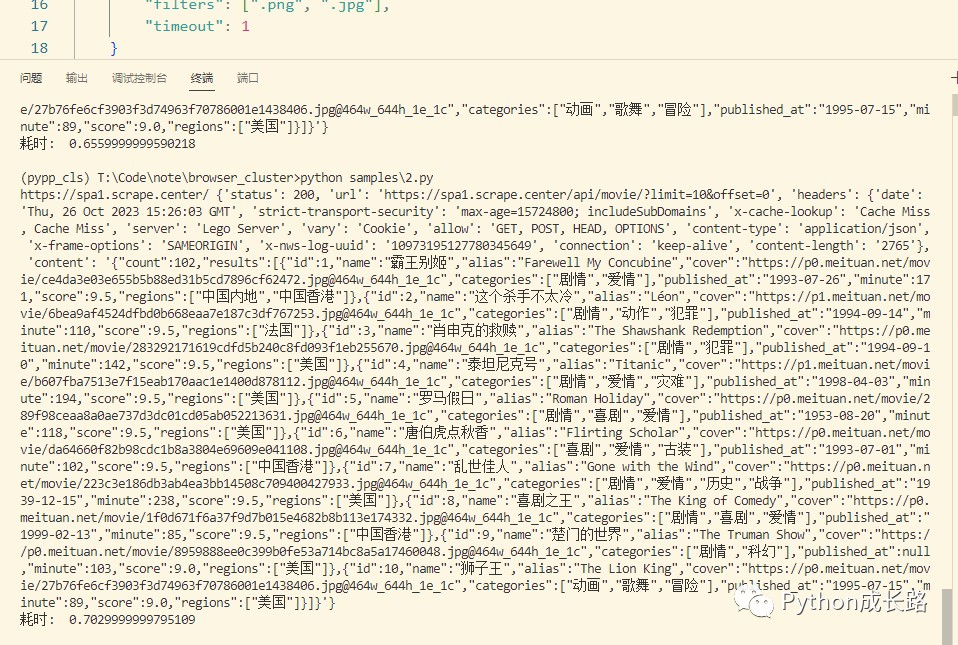
超时强制返回
加上timeout参数后,即使页面未加载完成也会强制停止并返回数据。如果这个时候已经拦截到了ajax请求会返回ajax响应内容,不然就是返回空
不过好像因为有缓存,现在时间不到1秒就返回了
截图
import json
import sys
import asyncio
import base64
import aiohttp
if sys.platform == 'win32':
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def get_sign(session, url, name):
api = f'http://127.0.0.1:8080/render.png'
data = {
"url": url,
#"render_all": 1,
"images": 1,
"cache": 1,
"wait": 1
}
async with session.post(api, data=json.dumps(data)) as resp:
data = await resp.json()
if data.get('image'):
image_bytes = base64.b64decode(data["image"])
with open(name, 'wb') as f:
f.write(image_bytes)
print(url, name, len(image_bytes))
return data
async def main():
urls = [
"https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=44004473_102_oem_dg&wd=%E5%9B%BE%E7%89%87&rn=50",
"https://www.toutiao.com/article/7145668657396564518/",
"https://new.qq.com/rain/a/NEW2022092100053400",
"https://new.qq.com/rain/a/DSG2022092100053300"
]
headers = {
"Content-Type": "application/json",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
loop = asyncio.get_event_loop()
t = loop.time()
async with aiohttp.ClientSession(headers=headers) as session:
tasks = [asyncio.create_task(get_sign(session, url, f"{n}.png")) for n,url in enumerate(urls)]
await asyncio.gather(*tasks)
print(loop.time()-t)
if __name__ == "__main__":
asyncio.run(main())集成到scrapy
import json
import logging
from scrapy.exceptions import NotConfigured
logger = logging.getLogger(__name__)
class BrowserMiddleware(object):
def __init__(self, browser_base_url: str):
self.browser_base_url = browser_base_url
self.logger = logger
@classmethod
def from_crawler(cls, crawler):
s = crawler.settings
browser_base_url = s.get('PYPPETEER_CLUSTER_URL')
if not browser_base_url:
raise NotConfigured
o = cls(browser_base_url)
return o
def process_request(self, request, spider):
if "browser_options" not in request.meta or request.method != "GET":
return
browser_options = request.meta["browser_options"]
url = request.url
browser_options["url"] = url
uri = browser_options.get('browser_uri', "/render.html")
browser_url = self.browser_base_url.rstrip('/') + '/' + uri.lstrip('/')
new_request = request.replace(
url=browser_url,
method='POST',
body=json.dumps(browser_options)
)
new_request.meta["ori_url"] = url
return new_request
def process_response(self, request, response, spider):
if "browser_options" not in request.meta or "ori_url" not in request.meta:
return response
try:
datas = json.loads(response.text)
except json.decoder.JSONDecodeError:
return response.replace(url=url, status=500)
datas = self.deal_datas(datas)
url = request.meta["ori_url"]
new_response = response.replace(url=url, **datas)
return new_response
def deal_datas(self, datas: dict) -> dict:
status = datas["status"]
text: str = datas.get('text') or datas.get('content')
headers = datas.get('headers')
response = {
"status": status,
"headers": headers,
"body": text.encode()
}
return response 开始想用aiohttp来请求,后面想了下,其实都要替换请求和响应,为什么不直接用scrapy的下载器
完整源代码
现在还只是个半成品玩具,还没有用于实际生产中,集群打包也没做。有兴趣的话可以自己完善一下
如果感兴趣的人比较多,后面也会系统的完善一下,打包成docker和发布第三方库到pypi
github:https://github.com/kanadeblisst00/browser_cluster