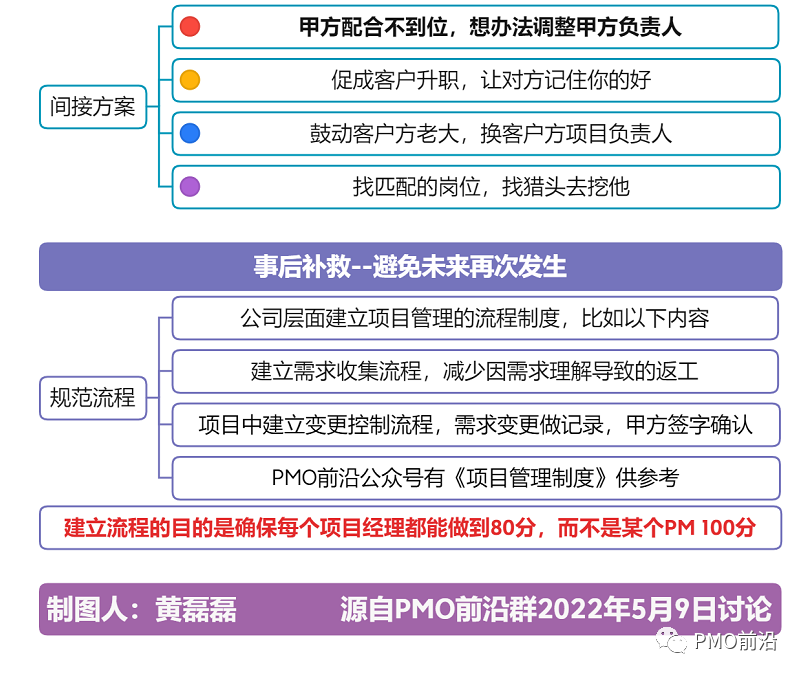
如果你是一位后端工程师,面试时八成会被问到 Redis,特别是那些大型互联网公司,不仅要求面试者能简单使用 Redis,还要深入理解其底层实现原理,具备解决常见问题的能力。可以说,熟练使用 Redis 就是后端工程师的必备技能。
但我发现,在工作或面试时,大家还是会有这样那样的疑问,比如:如何用 Redis 实现分布式锁?Redis 怎样处理过期键?缓存雪崩、穿透、热点问题怎么解决?持久化、集群方案怎么选择?如何优雅地给 Redis 做键值分析?等等。
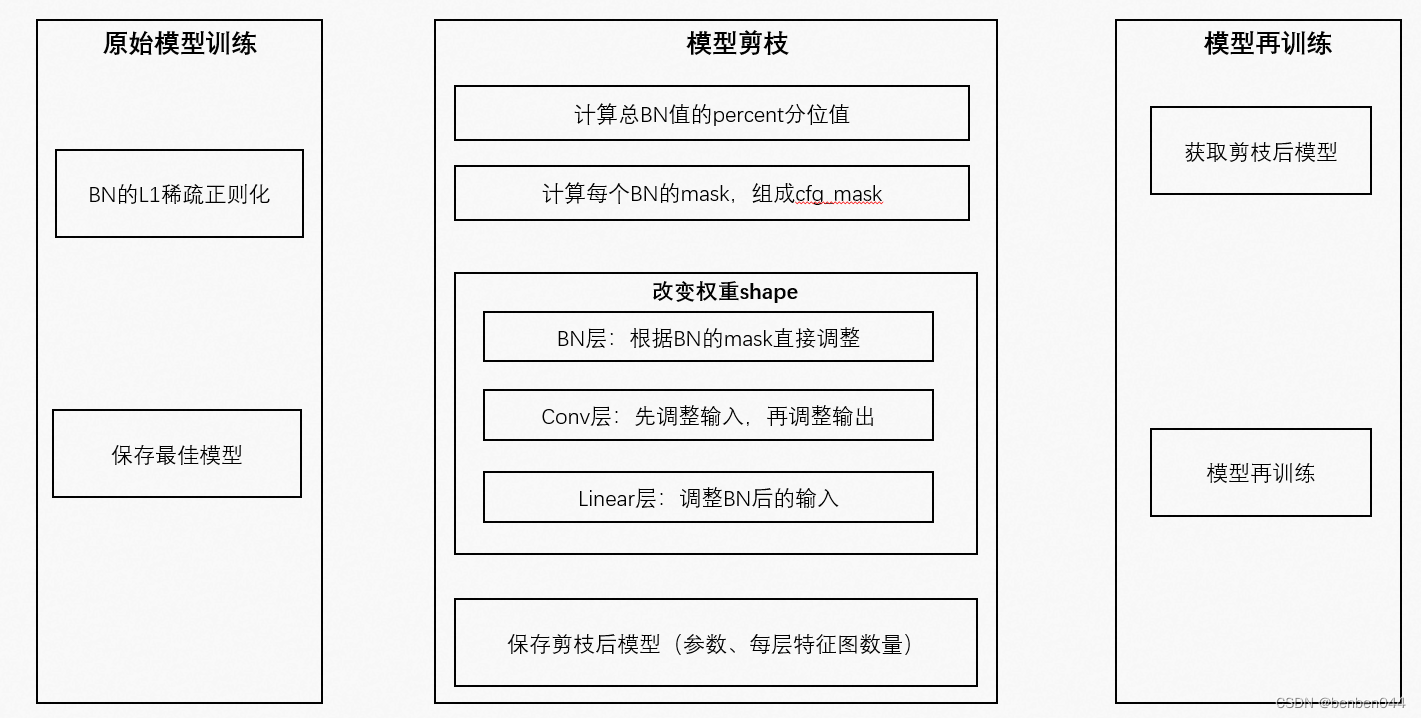
这里,分享给你一张 Redis 问题画像图,帮你快速查找问题对应的 Redis 主线模块,进而定位相应的技术点。

最近,总结了一条系统高效的 Redis 路径,帮你透彻理解 Redis 核心原理,并通过上手实战,掌握高并发场景下的缓存解决方案,解锁 Redis 高频面试题,让你无论在工作还是面试中,都能无往不利。
我发现,很多人都是带着具体问题学 Redis 的,这些问题当然重要,但如果只关注零散的技术点,没有建立起完整的知识框架,你的使用能力很难得到质的提升。
那么,怎样才能形成 Redis 系统观呢?在我看来,就是“两大维度,三大主线”:前者指系统维度和应用维度,后者就是高性能、高可靠和高可扩展。

从系统维度上说,我们要了解 Redis 各项关键技术的设计原理,掌握一些系统设计规范,例如 run-to-complete 模型、epoll 网络模型,以便应用到后续的系统开发中。但 Redis 的知识点很零碎,所以,可以按照“三大主线”为它们进行分类:
- 高性能主线,包括线程模型、数据结构、持久化、网络框架;
- 高可靠主线,包括主从复制、哨兵机制;
- 高可扩展主线,包括数据分片、负载均衡。
其次,在应用维度上,可以按照 “应用场景驱动”和“典型案例驱动”两种方式学习,一个是“面”的梳理,一个是“点”的掌握。
我们都知道,缓存和集群是 Redis 最广泛的两大应用场景。在这些场景中,本身就具有一条显式的技术链。比如,提到缓存就会想到缓存机制、缓存替换、缓存异常等一连串问题。
但并不是所有都适合这种方式,比如 Redis 丰富的数据模型,以及一些隐藏得比较深、在特定业务场景下才会出现的问题,就可以用“典型案例驱动”方式,深入拆解一些对 Redis “三高”特性影响较大的案例,例如,各个大厂在万亿级访问量、数据量的情况下,对 Redis 的深度优化实践。
这样,才能透彻理解 Redis,建立起结构化的知识体系,快速找到引发问题的关键因素,甚至整理成 Checklist,作为遇到问题时信手拈来的“锦囊妙计”。
再具体一点说,内容主要分为五部分:
一、Redis 基本数据结构与实战场景
二、Redis 常见异常及解决方案
三、分布式环境下常见的应用场景
四、Redis 集群模式
五、Redis 常见面试题目详解
下面是完整的目录:

一、Redis 基本数据结构与实战场景


二、Redis 常见异常及解决方案


三、分布式环境下常见的应用场景

四、Redis 集群模式


五、Redis 常见面试题目详解
- Redis相比memcached有哪些优势?
- Redis支持哪几种数据类型?
- Redis主要消耗什么物理资源?
- Redis的全称是什么?
- Redis有哪几种数据淘汰策略?
- Redis官方为什么不提供Windows版本?
- 一个字符串类型的智能存储最大容量是多少?
- 为什么Redis需要把所有数据放到内存中?
- Redis集群方案应该怎么做?都有哪些方案?
- Redis集群方案什么情况下会导致整个集群不可用?
- Redis事务相关的命令有哪几个?
- Redis如何做内存优化?
- Redis回收进程如何工作的?
- Redis回收使用的是什么算法?
- Redis如何做大型数据插入?
- 为什么要做Redis分区?
- 你知道有哪些Redis分区实现方案?
- Redis分区有什么缺点?
- Redis持久化数据和缓存怎么做扩容?
- 分布式Redis是前期做还是后期规模上来了再做好?为什么?
- Twemproxy是什么?
- 支持一致性哈希的客户端有哪些?
- Redis与其他key-value存储有什么不同?
- Redis的内存占用情况怎么样?
- 都有哪些办法可以降低Redis的内存使用情况呢?
- 一个Redis实例最多能存放多少的keys?
- Redis常见性能问题和解决方案?
- Redis提供了哪几种持久化方式?

ps:资料已整理成文档,需要获取的小伙伴可以直接转发+关注后私信(学习)即可获取哦!