接着 上一篇的谈论, 继续谈论抽象在重复性管理中的重要作用.
好的抽象与糟糕的抽象?
通过前面的一些例子, 你可能形成了一个印象: 所谓抽象很多时候就是把一些代码封装到一个方法中.
不过事实上并不是这么简单的. 抽象的结果确实很多时候产生了一个方法, 但不是说我把一堆代码整在一块就是一个抽象, 又或者说, 即便它是一个抽象, 但可能却不是一个好的抽象, 而是一个糟糕的抽象.
假如你看到一段代码很长, 然后你"啪"的一声把它从中间拦腰截断, 划分出两个方法来, 一个叫 firstPart(), 一个叫 secondPart(), 那么这算是怎样的一个抽象呢?
我们还是回到前面的例子, 假如把它分成两个部分,
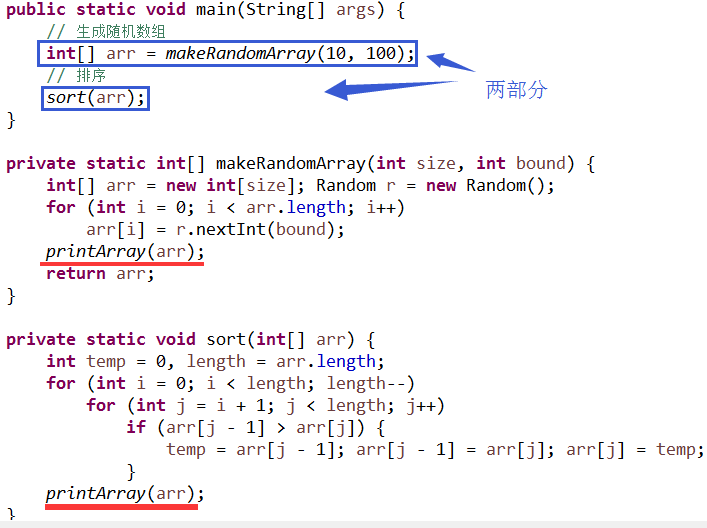
那么, 这两个抽象是存在问题的. 如果我们足够诚实的话, 就应该把前面的方法命名为 makeRandomArrayAndPrint, 因为这样才算较好的概括了它的行为. 但这样一来这个名字就显得很别扭了.
别人看到这个名字可能就不想调用它了, 虽然他可能需要一个随机数组, 但他也许并不需要把它打印出来. 如果看到你的方法不能满足需要, 自然他又只能是重新发明一个更为"纯粹的" makeRandomArray, 重复又产生了.
另一方面, 像代码中那样没有暗示存在打印, 那别人看到这个方法名觉得 OK, 然后使用它, 结果却出现了副作用, 输出中多了一些莫名其妙的东西, 而这是他不希望出现的.
如果生成的数组很大, 这些输出甚至会导致严重的性能问题, 最终可能还是导致别人放弃调用你的方法.
所以问题出在哪里呢? 其实就在于我们做了一个错误的, 糟糕的抽象. 生成随机数组的方法中是不应该包含打印的, 这实际是两件不同的事, 但我们却把它们整合在一起, 然后起了一个不适当的名字.
这样一来代码的灵活性就下降了. 以 sort 为例. 有些初学者可能在写完排序的代码后就顺手也写个打印在里边, 这样一来, sort 实际就变成了 sortAndPrint.
一个方法越大越长, 自然是离具体越近而离抽象越远.
是的, 其它地方会有很多对单独的 sort 的需求, 也会有很多对单纯的 print 的需求;但同时需要 sort 跟 print 的需求有多少呢? 恐怕就不多了.
越是具体, 能恰好匹配的需求就越少, 所以, 硬是把 sort 和 print 封装在一起, 这样的代码能被复用的几率就小很多了, 或者在勉强复用它的情况下, 不得不忍受它所带来的副作用, 而最终, 别人可能还是觉得重复发明一个"纯粹的"轮子用得舒服些.
所以, 有意无意地往 sort 里增加一个打印, 就属于画蛇添足, 破坏了抽象, 好心办了坏事.
所谓的内聚性
综上, 代码不是机械地把它们分开就是抽象. 被一个方法所封装在一起的一系列语句它们应该是紧密围绕一个主题的, 这就是所谓的"内聚性(Cohesion)".
只有当把彼此关系非常紧密的一系列语句封装在一起, 这样才能构成一个好的抽象.
如前面把打印的功能跟生成随机数组的代码整合在一块, 但它们彼此的关系却是疏远的, 不是非得要在一起的. 硬是把它们的绑在一块, 那就成了强扭的瓜, 成了拉郎配.
它们在一起擦出的不是火花而是火光, 也因此阻碍了复用, 因为很可能会带来各种副作用.
在前面 小程序中的大道理之四–单元测试 也曾经介绍过所谓的"单一职责原则(SRP: Single Responsibility Principle.)", 简单地讲, 那就是:
一个方法只做好一件事.
而很多时候, 命名是一件非常重要的事, 因为命名本身就是一个对事物进行抽象的过程. 如果你的一个方法做了太多的事, 你为它取名时就会面临很大的困难.
正如前面的 makeRandomArrayAndPrint 这个方法名会很长很别扭那样.
反之, 如果你面对一个别扭的名字, 你应该想到这可能是个糟糕的抽象. 很不幸, 我们可能会时不时看到诸如:
doSomeThing, handle, process, execute, apply
等这样特别抽象的名字, 而这倒不是说这些方法中干的是多么抽象的事,
毕竟你并不是在写那些特别抽象的如解析器之类的,
最大可能其实是方法中做了太多的事, 以至于不知道要怎样给它取名了, 最后只好取一个特别抽象的名, 这样仅从方法名中就基本得不到什么有效的信息了.
当别人想复用你的代码时, 基本都会先从方法名入手, 而不会深入到里面去看.
太抽象的名字让人不知所云, 最终别人会放弃尝试你的方法, 哪怕你的方法确实能解决他的问题.
当然, 如果名字特别抽象, 更大概率是它没有被复用的可能性.
所以, 一个好的名字是特别重要的, 因为它是一种适当的, 良好的抽象的暗示, 而这样的抽象是正是可复用性的关键, 也只有这样才能更好的管理系统中的重复.
在编程中, 我们可能不自觉地就会在一个方法中塞入太多的语句, 或在一个类中塞入太多的方法, 或在一个模块或 jar 塞入太多的类, 这样它们的主题必然就是模糊的, 而没有聚焦到"尽量做好唯一的一件事情"上.
这样的东西即便你把打成一个 jar 包, 别人可能还是不愿意去使用, 因为他也许只想使用其中一小块功能, 却必须引入一个庞大的 jar 包(还可能潜在地传递性地依赖更多的其它 jar), 其中可能有一堆的东西他都是不需要的, 导致系统特别臃肿.
所以更可能的情况就是他说, 算了, 别引入了, 还是自己发明轮子吧.
如果你看现在的有些框架, 比如 spring, 你会发现它现在分得很细,
比如 IoC 成为一个模块, 打包成一个单独的 jar, AOP 可能成为另一模块, 另一个 jar;
而早期这些东西可能都是在一起的, 一个单独的巨大的 spring.jar
那么这些细分的抽象自然有它的好处, 比如我只要 IoC 的功能, 那我就只引入 IoC 的, AOP 我则已有其它的解决方案, 我不要它的.
这样一来我就能避免引入重复的解决方案, 系统也不用那么臃肿.
甚至说, 这还不单单是重复性的问题. 类似的东西太多还可能存在潜在的冲突, 给未来带来潜在的不确定性.
毕竟, 代码越多, 就越容易出错, 这是一条最基本的原理.
概念层次上的匹配
最后, 回到概念层次的匹配这个话题上来. 在前面的例子中谈到, 当没有抽象时, 是用"具体对抽象", 而只有建立了抽象后, 才能有"抽象对抽象":

而这点为什么特别重要呢? 有人可能会说: "你怎么知道有人可能要复用它呢? 你是不是过度抽象了? 这也没几行代码呀? "
是的, 在这里, 你没抽象出来一个 makeRandomArray 来, 也许可能并不是很大的问题, 但有时候事情不是这样的.
我们再举一个例子, 下面的一段程序, 计算二月份的天数和一年的天数:

那么其中的 ((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0), 我相信你也清楚, 就是判断一个年份是否是闰年(leap year).
那么这段程序存在什么问题呢? 我们经常说程序是对现实世界的一个映射, 如果把这段程序跟现实对比一下:
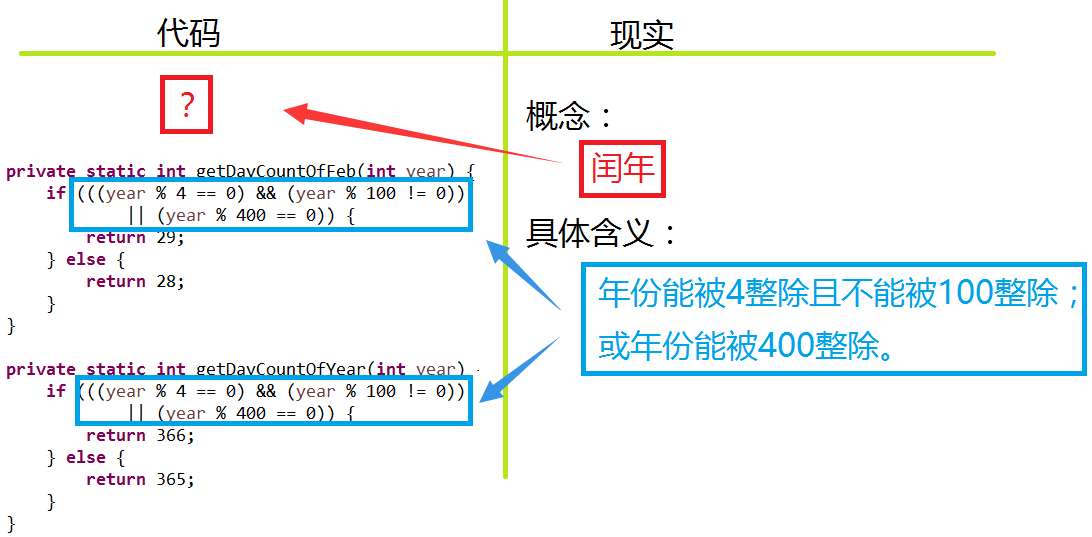
会发现, 现实世界的一个"概念"(也就是"闰年")在程序中没有对应! 现实世界的一处"具体的细节"则在程序中出现了两次.
我们的程序中缺失了一个概念!
而所谓"概念"的"概", 也就是"概括的"的意思, 其实也就是"抽象的"的一个近义词, 也就是说我们的程序实际缺少了一个"抽象".
现在把这个抽象补上, 增加一个叫"isLeapYear"的判断:

现在再来看对应关系:

是不是合理了很多呢? 现实中你有一个概念"闰年", 在程序中我则有一个抽象"isLeapYear"跟你对应;
因为在程序中主要用于判断, 所以变成了 isXXX 这样的形式.
现实中你有一个具体的含义"年份能被4整除且不能被100整除;或年份能被400整除", 在程序中我则有一段具体的代码 ((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0) 跟你对应.
而且这段具体的代码只出现一次!
现在, 我们的程序也拥有了一套完整的词汇, 无论是抽象的还是具体的, 无论在哪一个层次上, 我都能跟现实对应上, 达到了层次与概念上的匹配.
这种匹配特别重要, 特别是抽象层次上的匹配, 它为程序中的其它部分构筑了一道抽象的屏障(abstract barrier):
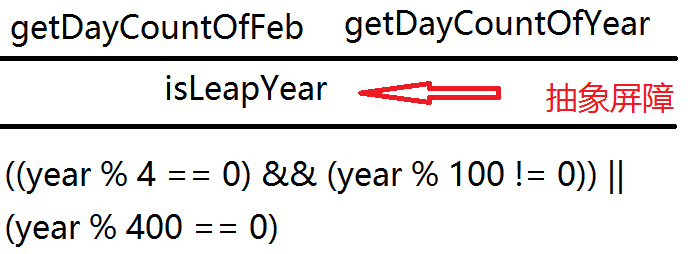
现在, getDayCountOfFeb 和 getDayCountOfYear 只依赖于抽象的isLeapYear, 细节被隔绝了, 被隐藏了, 被压制在了抽象之下.
它们不需要也不应该知道那些细节.
为什么这些细节的隐藏很重要呢? 首先, 正如前面引入"环比"和"同比"这些概念类似, 抽象的 isLeapYear 要比具体的 ((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0) 的更为简短.
更为重要的则是, 细节是很可能会发生变化的. 你可能有所不知的是, 在早期, 闰年的具体含义仅仅是"年份能被4整除. "
但按照每四年一个闰年计算, 结合地球公转的实际情况, 平均每年就要多算出0.0078 天, 经过四百年就会多出大约 3 天来, 这个误差不断累积, 所以后来就把闰年的具体含义调整为现在这样.
可是你注意到一个事实没有, 那就是"闰年"这个概念本身是稳定的, 不管具体含义怎么变, 闰年还是叫闰年.
名字是我们取的, 变不变我们说了算, 况且本身就是抽象的, 也没什么可变的;
具体含义则不受我们控制, 而且可能经常发生变化.
说到二月份的天数, 我们还是这么说:
如果是闰年, 则是 29 天, 否则是 28 天.
说到一年的天数, 我们还是这么说:
如果是闰年, 则是 366 天, 否则是 365 天.
当我们引入一个概念时, 后续的很多叙述就会建立在这个抽象的概念之上, 具体含义的变化不会影响到这些叙述;
与此类似, 建立在抽象屏障之上的代码也不会受到这些具体细节调整变化的冲击:

不难看出, 代码中的叙述跟现实中的是匹配的, 都是构筑在抽象的基础上, 根本就不知道细节是怎样的, 自然也不会受到细节变化的冲击.
反之, 如果早期只是简单地用具体的 if (year % 4 == 0) 来做判断, 那么现在就要一一调整为 if ((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0).
如果有两处, 就要做两处调整;如果有 N 处, 就要做 N 处调整. 显然, 这种重复性的劳动是不受欢迎的.
更为严重的是, 参数名可能有的地方叫 year, 而有的地方则叫 y;
而做具体判断时, 有的地方可能把
(year % 400 == 0)写在前面, 种种情况下使得你很难一一找出那些需要更改的地方!你可能要写点复杂的正则表达式而不是一个简单的查找才能把那些地方一一揪出来.
那么这种情况就属于细节没有被压制, 它逃逸了, 泄露了, 具体的形式上也可能出现了一些变形, 这些细节可能散落在系统的各个角落, 最终在面临调整变化时, 我们可能需要大量的重复性劳动, 甚至可能无法确保每一处都得到了调整. 真是糟糕!
而有了抽象屏障, 并把一切都建立在这个屏障之上后呢, 一切就轻松很多了:

因为抽象让细节集中到了一处, 现在只要简单改改具体定义即可, 一切就调整过来了.
而且能很清楚知道哪些地方会受到调整的冲击, 因为只需看看什么地方调用了它即可.
简单粗暴的方法就是暂时删掉方法定义, 看哪些地方报编译的错误就知道了;
也可以简单地查找方法名, 这比查找那些具体定义简单稳定多了, 也不需要什么高超的正则表达式技巧;
又或者, 有了现代 IDE 的帮助, 比如在 Eclipse 中, 你只需简单选中方法名, 然后选择"菜单–Navigate—Open Call Hierarchy", 也就是"打开调用层级"即可查看有哪些地方调用了它.
IDEA 中也有类似操作, 具体细节此处从略.
有了这些在概念层次上的良好匹配, 现实中的一处改动, 系统中也只需要一处改动.
在软件的开发活动中, 你可能会经常碰到这样的情景: 需求方说, 某某地方我想做个小调整, 这时程序员则连连摆手, “不行不行, 改动太大了”, 那么需求方可能会想"这只是一个小调整呀, 为什么会改动很大呢? "他想不明白.
自然, 有些小调整确实可能会造成大改动, 这时你可以甩锅给需求方: "怎么不早说呢? "但是有时, 正如现在举的这个例子这样, 这个锅也许需要我们程序员自己来背.
我们需要经常反思所写的代码, 概念层次跟现实是否形成了良好的匹配? 是否做到了足够的抽象? 重复的细节被管理起来了吗?
很多时候, 变化根本不受我们的控制, 我们唯一能做的, 就是使所写的代码保持足够的弹性, 能够面对各种变化的冲击.
在未来, 当误差不断累积, 闰年具体含义还可能会再次变化, 但有了抽象屏障的保驾护航, 我们不需要担心太多.
从某种意义上说, 当建立好适当的抽象后, 我们不但消除了现在的重复, 甚至也消除了未来的重复. 我们的代码能够抵御未来未知变化的冲击, 使得在未来变化来临时, 无需那些重复性的折腾.
所以, 这就是抽象在重复性管理中的巨大作用, 关于这个主题就暂时讨论到这里.