这是一个来自 API 的间歇性 500 个内部服务器错误的故事,这些错误最终是由 Go 包中的硬编码常量引起的database/sql。我将主要为您省去冗长的故事,并直接讨论问题以及我们发现的原因。我们注意到来自特定 API 端点的 500 错误数量有所增加,并开始进行故障排除。我们最初发现了一些奇怪的事情。当我们重试失败的调用时,有时会成功。几分钟后,我们发现只需对失败的 API 调用进行 CURL 几次,就可以轻松地“解决”问题。之后,就会一次又一次的成功。这让我们一时感到困惑,但随后我们意识到,在让 API 闲置一段时间后,调用会再次失败。与此同时,另一位团队成员查看了我们在该 API 开始失败时所做的更改。(我们使用chatops和其他技术来帮助解决此类故障。)事实证明,这个糟糕的更改将API请求的并行度从10个增加到25个。我们并行执行一些大规模时间序列操作,并将其提高以及其他一些变化。该解释与以下事实有关:
我们database/sql为每个客户环境使用单独的连接池,以确保资源隔离并避免饥饿和嘈杂邻居影响等问题。
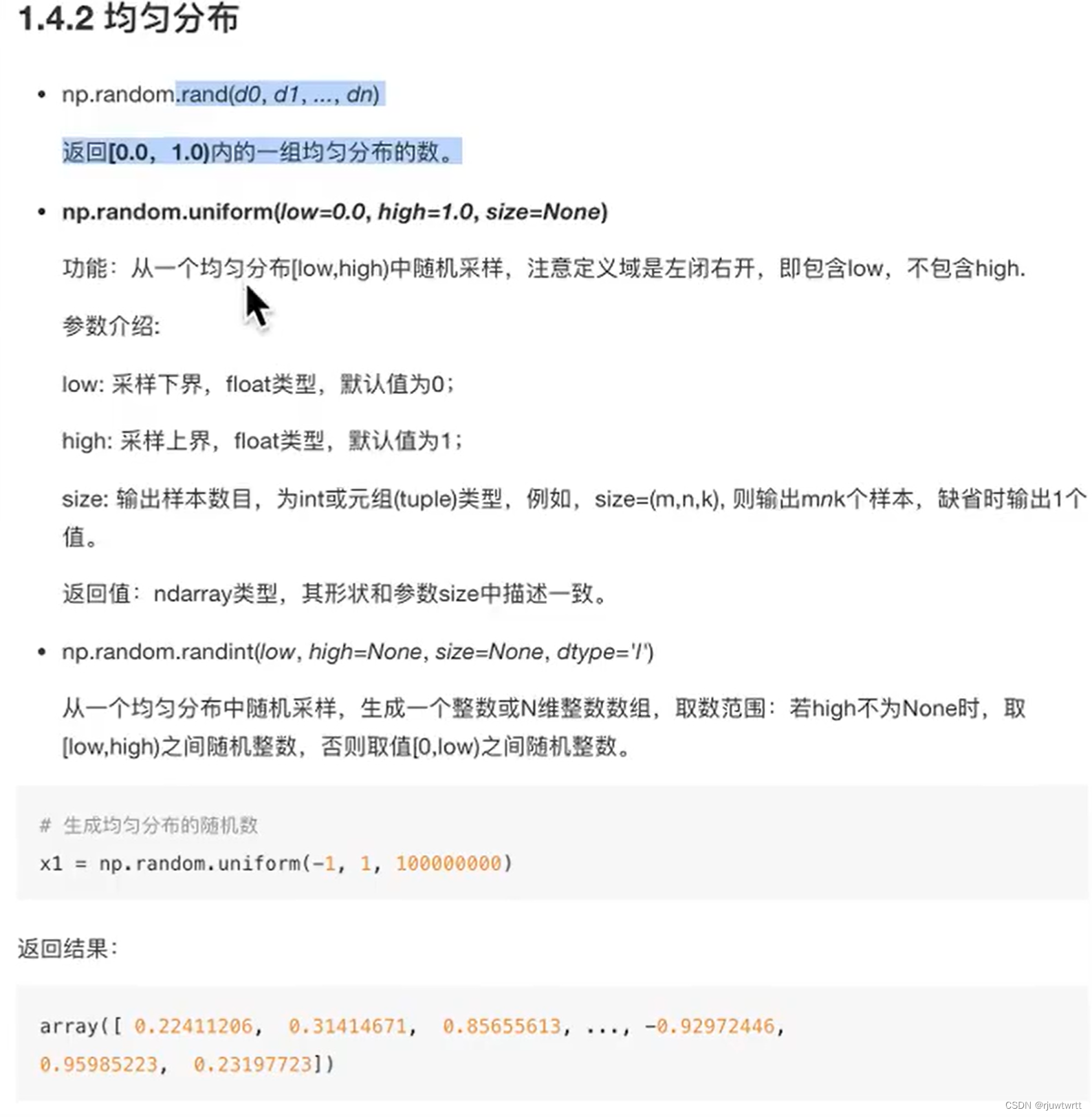
我们将连接池的大小database/sql从 10 个增加到 25 个,以提高并行度。
因为我们有很多客户和很多 API 服务,每个服务都有单独的池,所以我们在服务器端设置了一个较短的连接超时,以避免wait_timeoutMySQL 端的连接过多。
在内部,当它遇到从池中获取的连接database/sql时,具有硬编码的重试功能。driver.ErrBadConn删除失败的连接并获取另一个连接后,它将重试查询,最多 10 次。
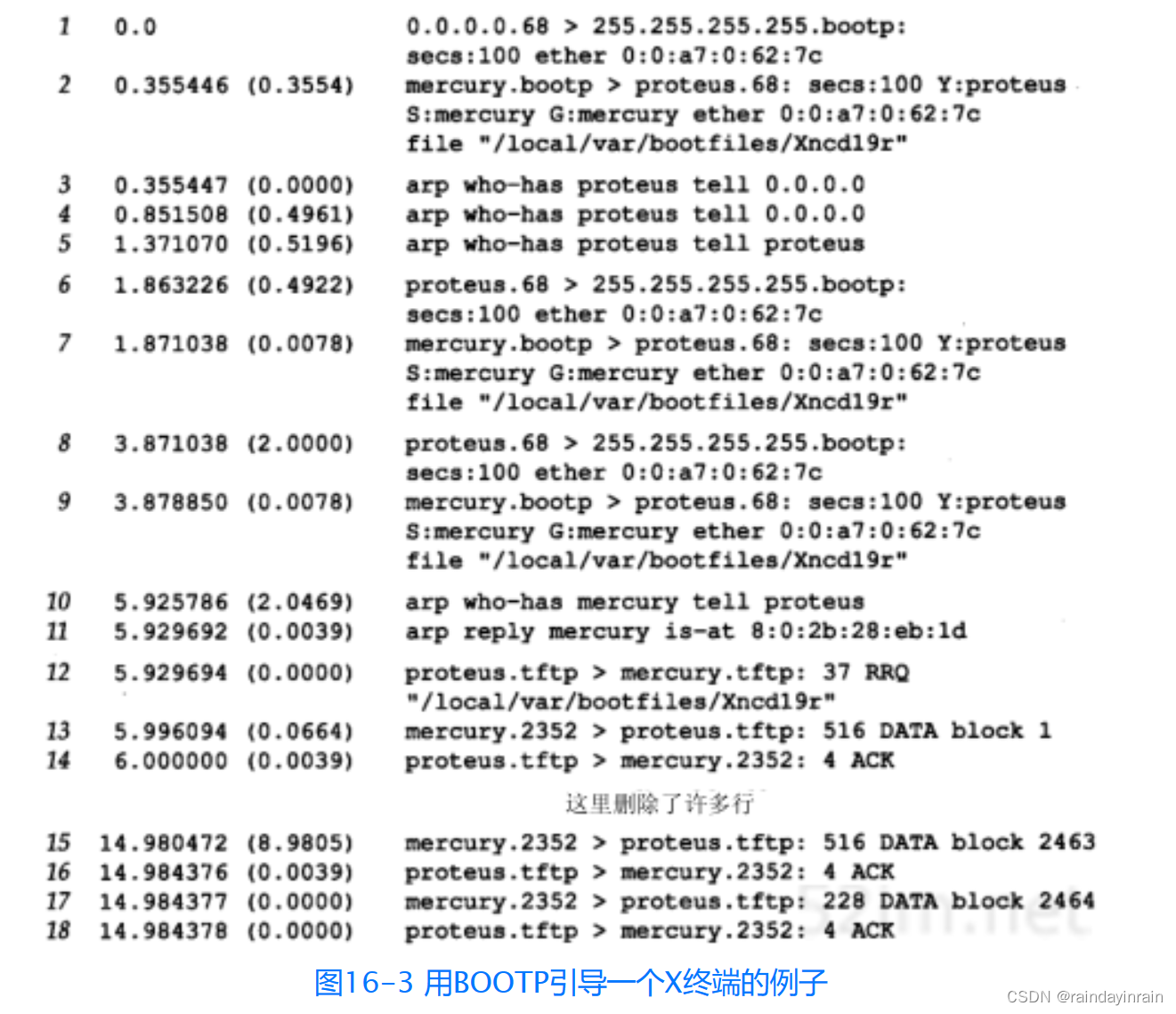
问题是这样发生的:
API 请求最多打开 25 个与数据库的连接,完成后将它们返回到池中。
API 闲置了一会儿,数据库上的所有连接都超时并被关闭。
API 收到另一个请求并开始尝试来自池的连接。
尝试 10 次后,它放弃了(这又是database/sql行为,而不是 API 本身)并返回错误 500。
如果您立即再次运行该请求,它将从池中清除另外 10 个连接。第三个请求将丢弃最后 5 个连接,然后在第六次重试时,将打开新的有效连接并成功。
由于我们无法在不更改database/sql代码的情况下更改 10 次重试的硬编码限制,因此我们选择暂时减少并行度。归根结底,我们的硬件还不支持这么高的并行度;这是为未来的一些变化做准备的步骤。我们计划使重试次数可配置(可能通过暂时更改供应商database/sql并向上游提交)。这个故事的道德意义是什么?只是平常的事情:了解您的工具,让合适的人员参与故障排除等。这里没有惊天动地的教训;只是一些有趣的事情,我认为值得分享,以防对其他人有所帮助。