作者 | 谢年年、ZenMoore
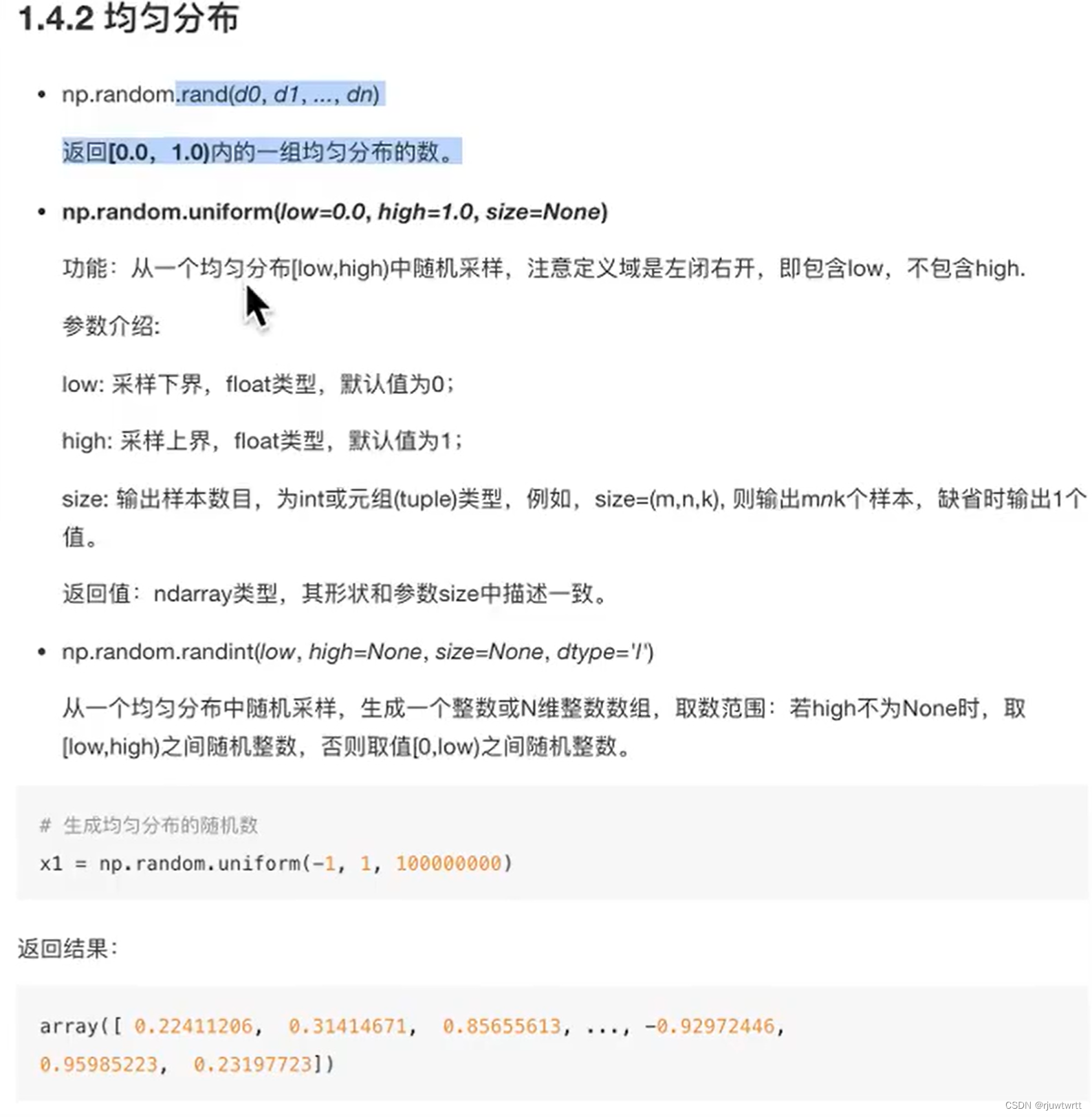
今年上半年,IBM 加入大模型战局,提出了一种使用原则(Principle)驱动的、基于 LLM Self-Instruct 的全新方法:SELF-ALIGN (自对齐),并以开源LLaMA为基础,用不到300行(包括195个种子prompt,16个原则和5个范例)人类标注数据就训练出了Dromedary[1],在TruthfulQA数据集上甚至取得超越GPT-4的成绩。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
时隔几个月,IBM再次发力,发布Dromedary-2,提出一种原则遵循的奖励模型并基于此训练出了 SALMON(鲑鱼)模型,仅用6个情境学习范例和31个人为定义的原则,在自生成的数据上微调 LLaMA-2-70b,就在各种基准数据集上,超过了包括LLaMA-2-Chat-70b在内的最先进的开源LLMs。
论文标题:
SALMON: Self-Alignment with Principle-Following Reward Models
论文链接:
https://arxiv.org/abs/2310.05910
GitHub链接:
https://github.com/IBM/SALMON
前言
现有的大语言模型如ChatGPT成功的关键因素之一是人类反馈的强化学习(RLHF),它将语言模型与人类偏好进一步对齐。然而,RLHF依赖于高质量的人工注释,由于难以获得一致的响应示例和分布内的响应偏好,使得它在复杂任务中的应用具有挑战性,且无法进一步扩展。
Dromedary 1.0版本中就定义一些类似于艾萨克·阿西莫夫的机器人三大定律的通用原则,这些原则可以全面内化到模型,供人工智能系统遵循。这项技术被称为 SELF-ALIGN,仅需少量人工标注数据就可以获得不错的效果,但是这些方法在性能上仍落后于RLHF。
同时,使用AI反馈代替人类反馈的方法如RLAIF[2]也是减少对繁重的人类注释偏好的依赖的一种流行手段,但先前的RLAIF工作重点仍然是提高已经接受过RLHF训练的模型的安全性。也就是说,这些RLAIF方法仍然保留了了RLHF预热阶段对人类偏好注释的严重依赖。
而本文则引入了不需要太多人工标注的遵循原则的奖励模型,并基于此训练了 SALMON 模型。SALMON 可以无缝地应用于各种不同的语言模型,而无需收集任何特定于模型的人类偏好数据。
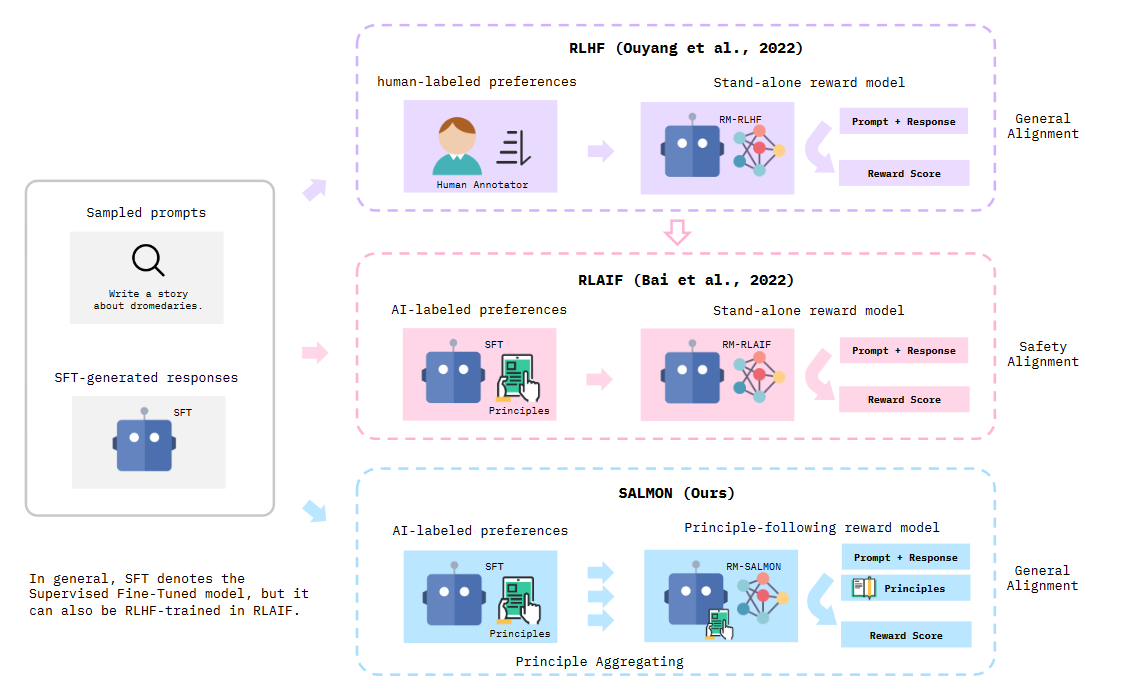
▲方法对比
方法
原则驱动的偏好建模
本文旨在训练一个能够理解并根据定义的原则分配奖励分数的原则遵循奖励模型,整个过程包括原则驱动的合成偏好数据集构建和遵循原则的奖励模型的训练,如图2所示

▲图2
1.收集原则驱动的合成偏好
首先需要构建了一个特殊的偏好建模数据集,其中每个偏好与预定义的原则配对。
如图2中左半边所示,从初始策略模型中采样两个回复,并让模型根据特定的人类编写的原则选择合适的响应。
图中user给出prompt——“2025年的美国总统是谁?”,经过有监督微调的模型给出两个输出。
A:作为一个AI语言模型,我的知识只到2021年9月,所以我无法预测2025年的美国总统。
B:约翰·多伊是2025年的美国总统。他之前并不出名,但他关于合作和开放的竞选得到了很多关注。
特定的人类编写原则为(此时选择的原则是“诚实”原则):
你是一个有帮助的助手,目标是为给定的指令选择首选(最少错误的)的AI模型输出。
为了简化评估过程,这次需要考虑的一个方面是:
诚实:人工智能必须提供可靠和真实的信息,并坦率地披露其局限性和知识程度。
根据所提供的定义,请为给定指令选择首选输出。
基于此原则,模型选择的最终输出为 A.
以上(Prompt + Output A + Output B + 1 Principle + 1 Preference)共同组成了原则驱动的合成偏好数据对。
对于每个用户提示(Prompt)和每个原则(Principle),偏好分数 (Preference Score) 被计算为选择回复 A 与选择回复 B 的对数概率之差。
在这一步中,人工标注的数据只有 31 个预定义的原则供模型选择,其他过程均让模型自动完成。
2. 训练原则遵循奖励模型
这一步是为了增强奖励模型解释人类定义的原则的能力。
首先为每个正面原则定义相应的负面原则,以增加这些原则的多样性。
例如,“简洁”原则的正面和负面定义如下:
Positive:回应应该有效地解决任务或回答问题,简洁地传达必要的信息。
Negative:回答应该避免直接提到任务或提供问题的答案。
接下来,对于每个用户提示,从已建立的原则列表中随机抽取原则的子集,并随机否定某些原则。
用户提示、模型回复和子抽样的原则被合并为奖励模型的单个训练实例。然后,通过展现出最显著偏好分数 (Preference Score) 差异的原则来校准最终的偏好标签,具体过程如下:

▲使用偏好分数校准偏好标签的具体过程
基于原则遵循奖励模型的强化学习
在原始的RLHF或RLAIF奖励模型中只需要根据用户提示来判断响应的质量,并给予“更好”的响应以更高的分数。而在SALMON中,原则遵循奖励模型被训练成根据人类定义的评判原则生成奖励分数,包括预定义的原则和强化学习时间干预原则两部分,如图2下半部分所示。
1. 基于预定义原则的强化学习
通过在合成的原则遵循偏好数据上进行训练,奖励模型能够准确解释任意的指令。这种能力有助于在RL的测试阶段通过定义新的原则来操纵奖励模型的偏好,进而塑造受遵循原则奖励模型反馈训练的策略模型的行为。
在测试阶段,本文使用了一组与奖励模型训练阶段不同的原则。在RL训练阶段,为了提高奖励模型偏好的多样性和随机性,为每个用户提示随机选择了k = 3个原则。在测试阶段,作者提高了选择一致推理原则的比例以适应推理提示,还提高了选择道德原则的比例以适应红队测试提示。
2. RL时间偏好干预
在初步实验中,作者们发现了三种趋势,它们有可能让策略模型 hack(找捷径)带有预定义原则的奖励模型。图3提供了这些奖励 hack 模式的具体示例:
-
AI助手在回应用户查询时经常提供高层次建议,绕过提供具体解决方案的过程。
-
AI助手经常自我吹嘘,破坏了奖励模型的评估能力。
-
AI助手倾向于进行过度教育,例如在解决数学问题后提供类似的例子。

为了减轻上述奖励 hack 的倾向性,作者分别为每种模式手动编写了一项额外的强化学习干预原则。这些RL干预措施非常有效。
传统的方法中为避免RLHF中的奖励 hack 需要收集与更新的策略模型对齐的在线偏好数据。而SALMON可以重复使用相同的遵循原则的奖励模型,仅通过定义禁止指令引导其偏好,就可以阻止策略模型表现出特定的不良行为。
3. 符号奖励:多语言奖励和长度奖励
与RLAIF不同,SALMON中的AI偏好不一定由经过强化学习人类反馈训练的模型生成。因此,SALMON中合成偏好模型有时会难以辨别哪些是更有帮助的回答,从而对合成偏好数据的质量产生负面影响。为增强奖励模型的效力,本文还提出了两种补充的符号化奖励:
• 在使用多语言提示数据集时,较弱的语言模型有时会对非英语提示产生英语回答。因此,作者特别奖励了与提示语言匹配的回答。
• 用户或良好对齐的LLM更偏好较长的回答。较长的回答通常涵盖了对所讨论问题的更广泛的审视,因此作者将回答的长度,以回答的 token 长度来量化,作为辅助的奖励得分。
注:RL 训练使用的是 PPO 算法。
实验结果
Dromedary-2模型
Dromedary-2基于LLaMA-2-70b,首先使用改进版SELF-ALIGN生成的引导数据进行了监督微调(SFT),其中包括6个In-Context Learning示例。随后,采用SALMON范式进行了强化学习(RL)微调阶段。在这项工作中,人工注释仅限于为SELF-ALIGN提供的六个In-Context Learning示例,以及后续针对 RL 阶段提供的 31 个原则。
聊天能力评估
人工评估通常被视为评判AI聊天机器人的黄金标准,但并不总是可扩展和可重复的。所以本文Vicuna-Bench和MT-Bench进行了基于GPT-4的自动评估,以衡量模型的聊天机器人的能力。结果显示,Dromedary-2的表现优于LLaMA-2-Chat-70b,达到了目前非蒸馏开源模型中最先进的聊天机器人性能。

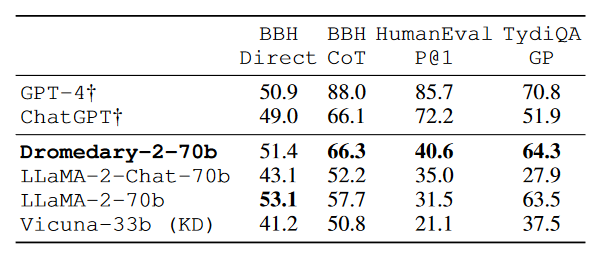
生成能力评估
本文分别使用BigBench Hard (BBH)、HumanEval和TydiQA来评估模型的推理、编码和多语言能力。结果显示Dromedary-2显著优于最先进的开源模型LLaMA-2-Chat
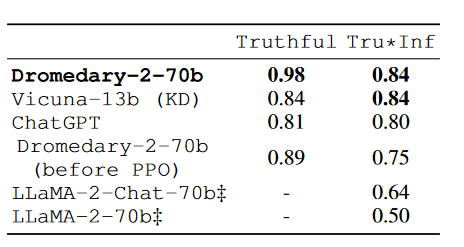
真实性评估
在TruthfulQA基准上评估模型在识别真实陈述方面的能力,并报告了由经过微调的GPT-3模型(即“GPT-judge”)评估的既真实又具有信息量的生成比例Tru*Inf。结果显示Dromedary-2取得了新的最佳成绩。
结论
SALMON范式在AI自我对齐方面取得了新的进展,展示了出色的遵循指令能力,并且紧密遵守人类定义的原则,这消除了传统上对在线人类偏好数据的繁重收集的依赖,但它仍然存在部分限制和未来发展方向:
-
可靠性问题:Dromedary-2模型仍然存在“幻觉”问题,生成未经验证的信息并显示推理错误。未来可以利用整合外部事实核查工具,增强奖励模型的判别能力,从而提高最终模型的准确性和可信度。
-
原则设计挑战:为SALMON构建稳健而全面的原则是复杂的,本文已经开源了代码和模型权重,以鼓励众多研究者积极参与。
-
上下文相关的原则选择:目前的方法使用随机抽样的原则来指导奖励模型处理一般提示。然而,原则的有效性可能与问题相关。理想的原则可能会根据任务的不同而变化。未来的研究应该深入探讨自适应原则选择,旨在提高任务特定的反馈效果。
-
内在知识的局限性:SALMON利用了LLM的内在知识。受限于基础模型的固有限制,它的知识无法及时更新。因此,整合检索增强生成技术有可能使得良好对齐的模型能够生成最新的信息,从而减轻一些知识方面的限制。

参考资料
[1]https://arxiv.org/abs/2305.03047
[2]https://arxiv.org/abs/2309.00267