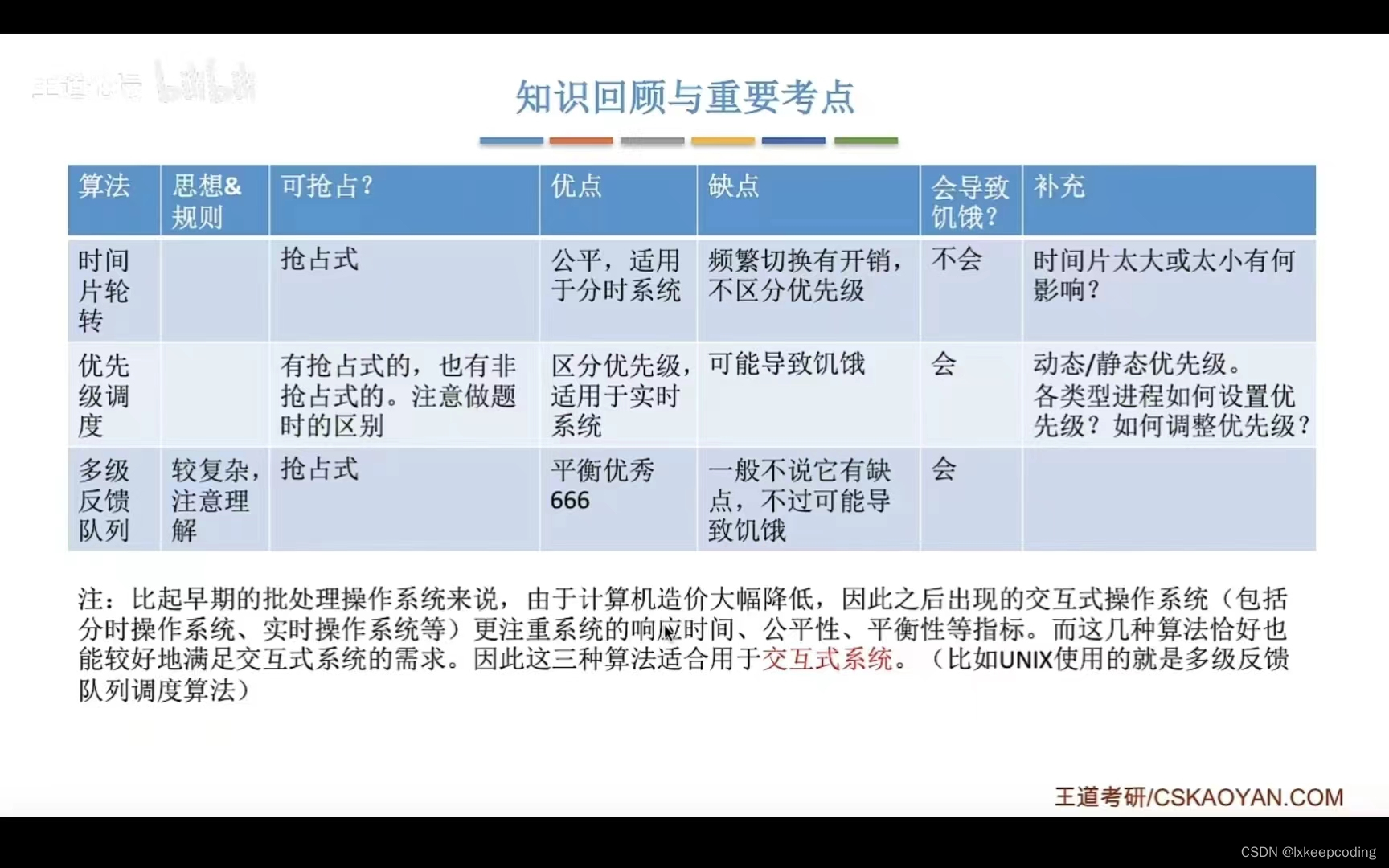
import jieba
import pandas as pd
from sklearn. feature_extraction. text import TfidfVectorizer
from sklearn. metrics. pairwise import cosine_similarity
sentences = [
"今天天气真好,阳光明媚。" ,
"关键字匹配是一种常见的文本处理任务。" ,
"计算机不认识人类语言,要转成词向量。" ,
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。" ,
"中文分词工具对文本处理很有帮助。" ,
]
query_sentence = "关键字匹配和文本处理任务"
data = { "Sentence" : sentences}
df = pd. DataFrame( data)
def preprocess ( text) :
words = jieba. lcut( text)
return " " . join( words)
df[ "Preprocessed_Sentence" ] = df[ "Sentence" ] . apply ( preprocess)
query_sentence = preprocess( query_sentence)
vectorizer = TfidfVectorizer( )
tfidf_matrix = vectorizer. fit_transform( list ( df[ "Preprocessed_Sentence" ] ) + [ query_sentence] )
similarities = cosine_similarity( tfidf_matrix)
query_similarity = similarities[ - 1 , : - 1 ]
n = 10
top_indices = query_similarity. argsort( ) [ - n: ] [ : : - 1 ]
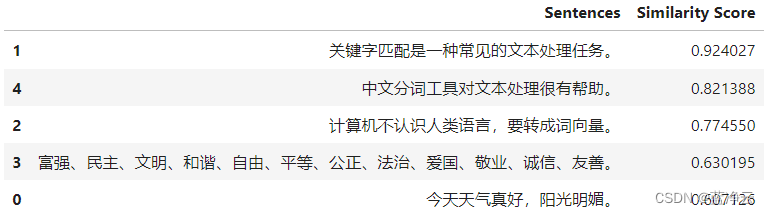
similar_sentences = df. loc[ top_indices, "Sentence" ] . tolist( )
similarity_scores = [ query_similarity[ i] for i in top_indices]
result_data = { "Similar_Sentence" : similar_sentences, "Similarity_Score" : similarity_scores}
result_df = pd. DataFrame( result_data)
print ( "查询句子:" , query_sentence)
print ( "\n相似度最高的句子:" )
result_df
import warnings
warnings. filterwarnings( "ignore" )
import spacy
import pandas as pd
nlp = spacy. load( "zh_core_web_sm" )
data = {
"Sentences" : [
"今天天气真好,阳光明媚。" ,
"关键字匹配是一种常见的文本处理任务。" ,
"计算机不认识人类语言,要转成词向量。" ,
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。" ,
"中文分词工具对文本处理很有帮助。" ,
]
}
df = pd. DataFrame( data)
target_sentence = "关键字匹配和文本处理任务"
similarity_scores = [ ]
for sentence in df[ "Sentences" ] :
doc1 = nlp( target_sentence)
doc2 = nlp( sentence)
similarity = doc1. similarity( doc2)
similarity_scores. append( similarity)
df[ "Similarity Score" ] = similarity_scores
n = 10
top_n_similar_sentences = df. sort_values( by= "Similarity Score" , ascending= False ) . head( n)
top_n_similar_sentences
import warnings
warnings. filterwarnings( "ignore" )
from transformers import AutoTokenizer, AutoModel
import pandas as pd
import torch
from sklearn. metrics. pairwise import cosine_similarity
model_name = "model/bert-base-chinese"
tokenizer = AutoTokenizer. from_pretrained( model_name)
model = AutoModel. from_pretrained( model_name)
data = {
"Sentences" : [
"今天天气真好,阳光明媚。" ,
"关键字匹配是一种常见的文本处理任务。" ,
"计算机不认识人类语言,要转成词向量。" ,
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。" ,
"中文分词工具对文本处理很有帮助。" ,
]
}
df = pd. DataFrame( data)
target_sentence = "关键字匹配和文本处理任务"
similarity_scores = [ ]
target_embedding = model( ** tokenizer( target_sentence, return_tensors= "pt" , padding= True , truncation= True ) ) . last_hidden_state. mean( dim= 1 )
for sentence in df[ "Sentences" ] :
sentence_embedding = model( ** tokenizer( sentence, return_tensors= "pt" , padding= True , truncation= True ) ) . last_hidden_state. mean( dim= 1 )
similarity = cosine_similarity( target_embedding. detach( ) . numpy( ) , sentence_embedding. detach( ) . numpy( ) ) [ 0 ] [ 0 ]
similarity_scores. append( similarity)
df[ "Similarity Score" ] = similarity_scores
n = 10
top_n_similar_sentences = df. sort_values( by= "Similarity Score" , ascending= False ) . head( n)
top_n_similar_sentences