【JCIM 2020】数据增强+预训练+基于模板
Template methods
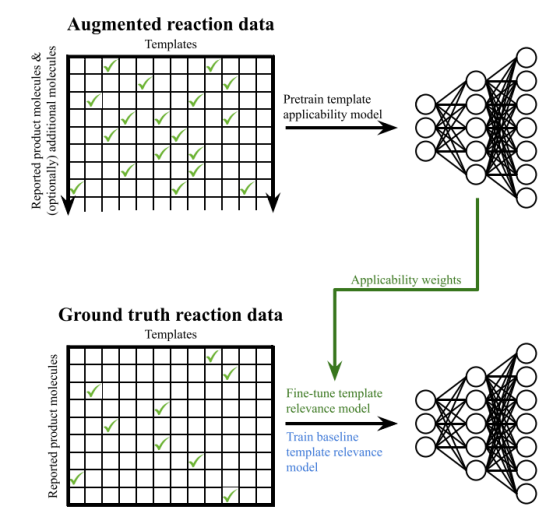
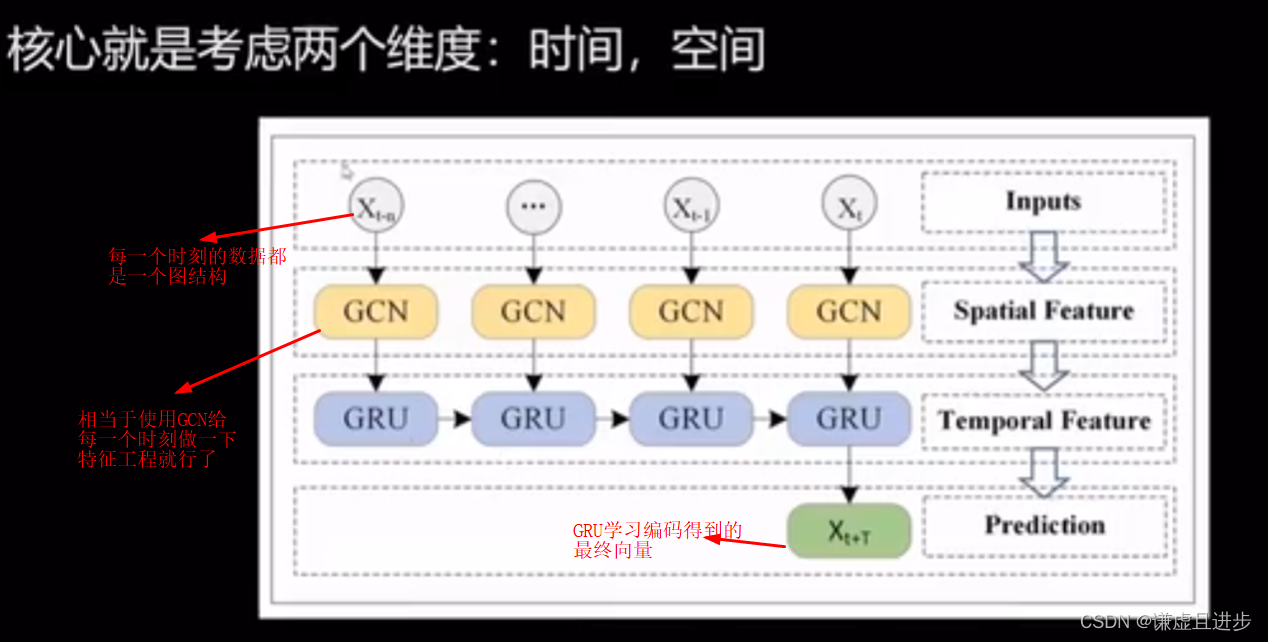
Figure 1. 预训练+微调 workflow
- 首先,通过增强的反应数据(真实存在的数据+计算机生成的反应数据)进行Pretrain Encoder A,
2、只使用真实反应数据对Pretrain Encoder A 进行微调
【AAAI 2023】Learning Chemical Rules of Retrosynthesis with Pre-training
template-free methods
使用预训练 --> .增强chemical rules encoded:
具体来说,我们通过分子重构(molecule reconstruction)预训练任务来执行原子守恒规则(atom conservation rule),通过反应类型引导的对比预训练任务来指导反应中心的反应规则
molecule recovery(MR)预训练任务
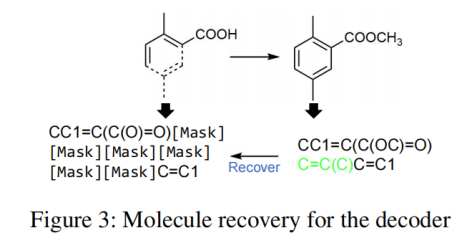
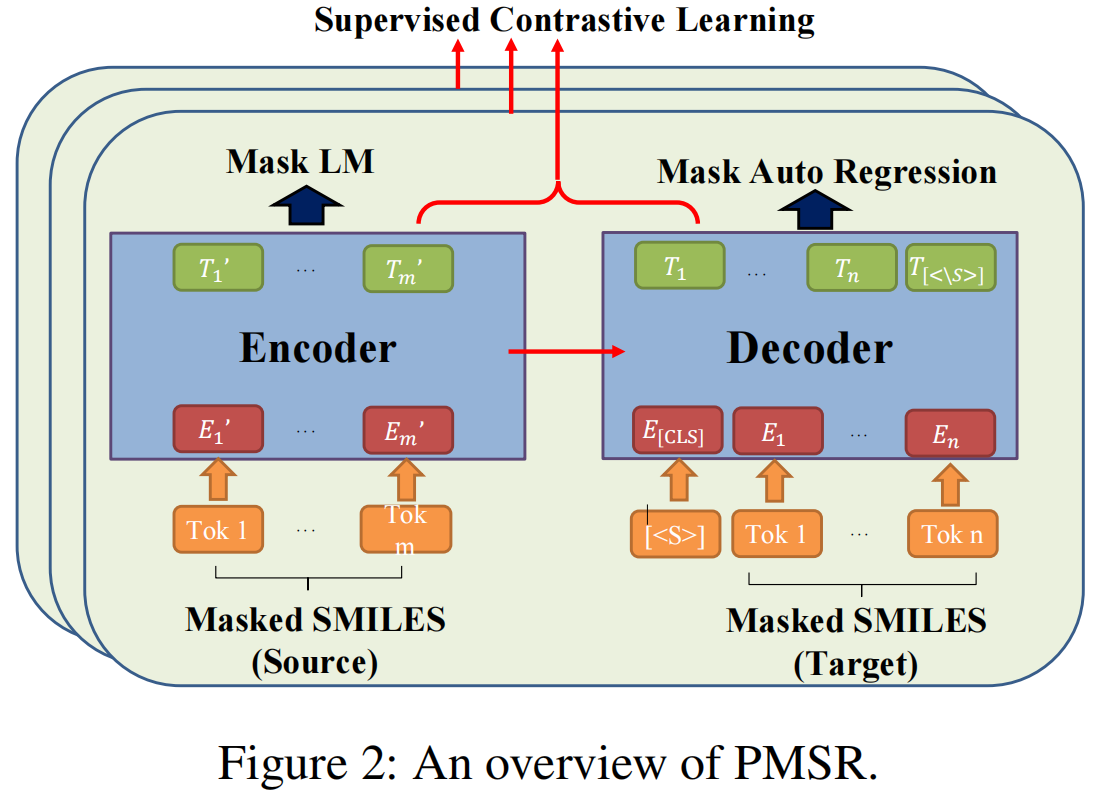
-
Masked SMILES (Source) & Masked SMILES (Target): 图中的"Masked SMILES"表示一个化学结构的文本表示,其中某些部分可能被掩盖或隐藏了。"Source"是输入模型的数据,而"Target"是模型的预测目标。
-
Encoder & Decoder: 这是一个典型的编码器-解码器结构。编码器将输入的Masked SMILES转化为一个中间的表示(可能是向量形式),而解码器将这个中间表示解码为目标的Masked SMILES。
-
Mask LM & Mask Auto Regression: 这两个模块可能与预测被掩盖或隐藏的部分有关。"Mask LM"可能是一个语言模型,用于基于上下文预测被掩盖的部分;而"Mask Auto Regression"则可能是一个自回归模型,用于逐步预测序列中的每一个元素。
-
Supervised Contrastive Learning: 这可能是模型训练时采用的一个特定策略或技术,通过对比学习来提高模型的性能。
关于怎么进行训练:
-
首先,你需要有一个Masked SMILES的数据集,其中一部分SMILES字符串被部分掩盖或隐藏。
-
在训练过程中,编码器将读取这些掩盖的SMILES字符串并产生一个中间的表示。接下来,解码器将尝试基于这个中间的表示来预测被掩盖的部分。
-
使用Supervised Contrastive Learning技术,模型会被鼓励将正样本(相同或相似的SMILES)拉近,而将负样本(不同的SMILES)推远。
-
通过计算模型的预测与实际目标之间的差异,计算损失函数,并使用优化器(如Adam、SGD等)来更新模型的参数。
-
重复上述步骤,直到模型的性能达到满意的水平或满足其他的终止条件。
As shown in Figure 2, PMSR is a sequence-to-sequence chemical reaction model with a transformer-based encoder and a transformer-based decoder.
我们认为逆合成预测任务更像是条件生成,因此我们采用pointer-generator(See, Liu, and Manning 2017;Nishida et al. 2019)在我们的模型中。pointer-generator架构允许模型直接从产物中复制原子,从而改进生成稀有原子的能力。
我们设计了三个预训练任务,即molecule recovery(MR)、auto-regression(AR)和contrastive classifcation(CC)。MR和AR在编码器和解码器上进行预训练,CC是在一批数据中学习的,类似于模型的正则化。这三个预训练任务同时优化。