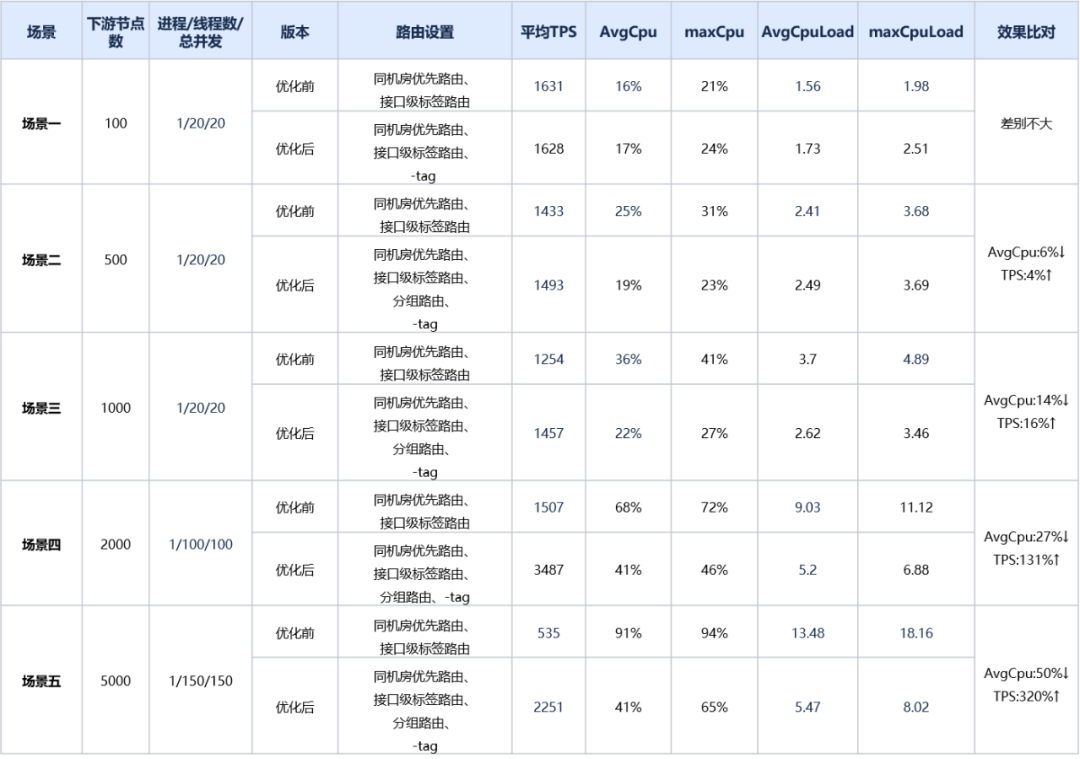
上一节使用的高斯核的指数部分可以视为注意力评分函数(attention scoring function),简称评分函数(scoring function)。
后续把评分函数的输出结果输入到softmax函数中进行运算。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。该过程可描述为下图:

用数学语言描述为:
f ( q , ( k 1 , v 1 ) , … , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i ∈ R v f(\boldsymbol{q},(\boldsymbol{k}_1,\boldsymbol{v}_1),\dots,(\boldsymbol{k}_m,\boldsymbol{v}_m))=\sum^m_{i=1}{\alpha(\boldsymbol{q},\boldsymbol{k}_i)\boldsymbol{v}_i}\in\R^v f(q,(k1,v1),…,(km,vm))=i=1∑mα(q,ki)vi∈Rv
其中查询 q \boldsymbol{q} q 和键 k i \boldsymbol{k}_i ki 的注意力权重(标量)是通过注意力评分函数 a a a 将两个向量映射成标量,再经过softmax运算得到的:
α ( q , k i ) = s o f t m a x ( a ( q , k i ) ) = a ( q , k i ) ∑ j = 1 m exp a ( q , k i ) ∈ R \alpha(\boldsymbol{q},\boldsymbol{k}_i)=\mathrm{softmax}(a(\boldsymbol{q},\boldsymbol{k}_i))=\frac{a(\boldsymbol{q},\boldsymbol{k}_i)}{\sum^m_{j=1}{\exp{a(\boldsymbol{q},\boldsymbol{k}_i)}}}\in\R α(q,ki)=softmax(a(q,ki))=∑j=1mexpa(q,ki)a(q,ki)∈R
import math
import torch
from torch import nn
from d2l import torch as d2l
以下介绍的是两个流行的评分函数。
10.3.1 遮蔽 softmax 操作
并非所有的值都应该被纳入到注意力汇聚中。下面的 masked_softmax 函数实现了这样的掩蔽softmax操作(masked softmax operation),其中任何超出有效长度的位置都被掩蔽并置为0。
#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
print(masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))) # 两样本有效长度分别为 2 和 3
print(masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))) # 也可以给每一行指定有效长度
tensor([[[0.4297, 0.5703, 0.0000, 0.0000],
[0.6186, 0.3814, 0.0000, 0.0000]],
[[0.2413, 0.3333, 0.4254, 0.0000],
[0.4165, 0.2801, 0.3034, 0.0000]]])
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
[0.3277, 0.4602, 0.2121, 0.0000]],
[[0.5026, 0.4974, 0.0000, 0.0000],
[0.2684, 0.2599, 0.2613, 0.2103]]])
10.3.2 加性注意力
当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。加性注意力(additive attention)的评分函数为:
a ( q , k i ) = w v T tanh ( W q q + W k k ) ∈ R a(\boldsymbol{q},\boldsymbol{k}_i)=\boldsymbol{\mathrm{w}}_v^T\tanh{(\boldsymbol{\mathrm{W}}_q\boldsymbol{q}+\boldsymbol{\mathrm{W}}_k\boldsymbol{k})}\in\R a(q,ki)=wvTtanh(Wqq+Wkk)∈R
参数字典:
-
q ∈ R q \boldsymbol{q}\in\R^q q∈Rq 表示查询
-
k ∈ R k \boldsymbol{k}\in\R^k k∈Rk 表示键
-
W q ∈ R h × q \boldsymbol{\mathrm{W}}_q\in\R^{h\times q} Wq∈Rh×q、 W k ∈ R h × k \boldsymbol{\mathrm{W}}_k\in\R^{h\times k} Wk∈Rh×k 和 W v ∈ R h \boldsymbol{\mathrm{W}}_v\in\R^h Wv∈Rh 均为可学习参数。
#@save
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout) # 使用了暂退法进行模型正则化
def forward(self, queries, keys, values, valid_lens):
# 初始 q 和 k 的形状如下,不好直接加
# queries 的形状:(batch_size,查询的个数,num_hidden)
# key 的形状:(batch_size,“键-值”对的个数,num_hiddens)
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries 的形状:(batch_size,查询的个数,1,num_hidden)
# key 的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
features = queries.unsqueeze(2) + keys.unsqueeze(1) # 优雅,实在优雅 使用广播方式进行求和
features = torch.tanh(features)
# self.w_v 仅有一个输出,因此从形状中移除最后那个维度。
# scores 的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1) # 把最后一个维度去掉
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2)) # 查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小)
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(
2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens) # 注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)), # 本例子中每个键都是相同的,所以注意力权重是均匀的,由指定的有效长度决定。
xlabel='Keys', ylabel='Queries')

10.3.3 缩放点积注意力
使用点积可以得到计算效率更高的评分函数,缩放点积注意力(scaled dot-product attention)评分函数为:
a ( q , k ) = q T k d a(\boldsymbol{q},\boldsymbol{k})=\boldsymbol{q}^T\boldsymbol{k}\sqrt{d} a(q,k)=qTkd
在实践中,我们通常从小批量的角度来考虑提高效率:
s o f t m a x ( Q K T d ) V ∈ R n × v \mathrm{softmax}\left(\frac{\boldsymbol{Q}\boldsymbol{K}^T}{\sqrt{d}}\right)\boldsymbol{V}\in\R^{n\times v} softmax(dQKT)V∈Rn×v
#@save
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
queries = torch.normal(0, 1, (2, 1, 2)) # 点积操作需要查询的特征维度与键的特征维度大小相同
attention = DotProductAttention(dropout=0.5) # 使用了暂退法进行模型正则化
attention.eval()
attention(queries, keys, values, valid_lens)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]])
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')

练习
(1)修改小例子中的键,并且可视化注意力权重。可加性注意力和缩放的“点-积”注意力是否仍然产生相同的结果?为什么?
不一样,评分函数不一样,键值不同的话那注意力汇聚肯定不一样的。
queries_new, keys_rand = torch.normal(0, 1, (2, 1, 2)), torch.rand((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(
2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention_rand = AdditiveAttention(key_size=2, query_size=2, num_hiddens=8,
dropout=0.1)
attention_rand.eval()
attention_rand(queries_new, keys_rand, values, valid_lens)
d2l.show_heatmaps(attention_rand.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')

attention_rand = DotProductAttention(dropout=0.5)
attention_rand.eval()
attention_rand(queries_new, keys_rand, values, valid_lens)
d2l.show_heatmaps(attention_rand.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')

(2)只使用矩阵乘法,能否为具有不同矢量长度的查询和键设计新的评分函数?
可以想办法把他俩映射到一个长度。
(3)当查询和键具有相同的矢量长度时,矢量求和作为评分函数是否比“点-积”更好?为什么?
不会,略。