一、说明
请考虑查阅更多文章。不要忘记在https://blog.devops.dev/和 https://twitter.com/devops_blog 上关注我们机器学习模型中的超参数是不是从训练数据中学习而是设置的参数训练前。这些参数会影响模型在训练期间的行为,并对模型的性能和泛化到新数据的能力产生重大影响。
二、超参数有啥内涵?
超参数的示例包括学习率(控制优化期间采取的步长)、正则化强度(控制应用于模型参数以防止过度拟合的惩罚程度)、神经网络中隐藏层的数量、树的数量在随机森林中,以及在支持向量机中使用的核函数。
网格搜索是机器学习中使用的一种超参数调整技术,用于查找模型超参数的最佳值。它涉及定义要搜索的超参数值网格,然后详尽地评估网格中的每个值组合。
我将使用 Kaggle 中的笔记本电脑价格数据集来演示如何在 Python 中使用网格搜索。您可以在这里获取数据。
三、基于Xgboost的网格搜索实践
首先,我们需要预处理数据集并为模型开发做好准备。由于这不是本文的重点,因此对此进行了简要介绍。
import pandas as pd
import xgboost as xgb
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
df = pd.read_csv("laptopPrice.csv")
# there are some duplicates in the dataset
df = df.drop_duplicates()
df.reset_index(drop=True,inplace=True)
# some replacements
df['ram_gb'] = df['ram_gb'].str.replace(' GB', '').astype(int)
df['ssd'] = df['ssd'].str.replace(' GB', '').astype(int)
df['hdd'] = df['hdd'].str.replace(' GB', '').astype(int)
df['graphic_card_gb'] = df['graphic_card_gb'].str.replace(' GB', '').astype(int)
df['os_bit'] = df['os_bit'].str.replace('-bit', '').astype(int)
df["rating"] = df["rating"].replace({"1 star": "1 stars"})
df['rating'] = df['rating'].str.replace(' stars', '').astype(int)
mapping = {'ThinNlight': 1, 'Casual': 2, 'Gaming': 3}
df["weight"] = df["weight"].replace(mapping)
mapping = {'No warranty': 0, '1 year':1, '2 years':2, '3 years':3}
df["warranty"] = df["warranty"].replace(mapping)
mapping = {'No': 0, 'Yes': 1}
df["Touchscreen"] = df["Touchscreen"].replace(mapping)
mapping = {'No': 0, 'Yes': 1}
df["msoffice"] = df["msoffice"].replace(mapping)
df.head(10)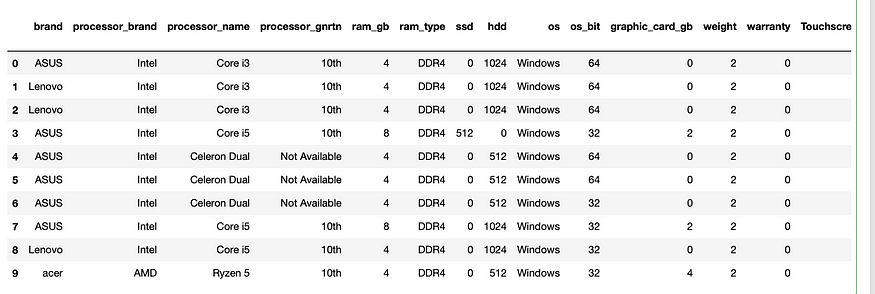
前 10 行。图片由作者提供。
num_features = [feature for feature in df.columns if df[feature].dtype != 'object' and feature != "Price"]
cat_features = [feature for feature in df.columns if df[feature].dtype == 'object']
print("Numerical features: ", num_features)
print("Categorical featues:", cat_features)
"""
Numerical features: ['ram_gb', 'ssd', 'hdd', 'os_bit', 'graphic_card_gb', 'weight', 'warranty', 'Touchscreen', 'msoffice', 'rating', 'Number of Ratings', 'Number of Reviews']
Categorical featues: ['brand', 'processor_brand', 'processor_name', 'processor_gnrtn', 'ram_type', 'os']
"""# feature transformation
cat_transformer = OneHotEncoder(handle_unknown='ignore')
num_transformer = StandardScaler()
preprocessor = ColumnTransformer(
transformers=[
('cat', cat_transformer, cat_features),
('num', num_transformer, num_features)
])
X = preprocessor.fit_transform(df)
y = df["Price"].values.reshape(-1,1)
print(f"X: {X.shape}, y: {y.shape}")
# X: (802, 51), y: (802, 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle=True)好的,我们现在已经对输入数据和目标数据进行了预处理,并且它们已准备好在模型中使用。
让我们训练我们的基本模型。我将使用 XGBoost 及其默认超参数。
model = xgb.XGBRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
rmse_train = np.sqrt(mean_squared_error(y_train, model.predict(X_train)))
rmse_test = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Train RMSE: {rmse_train}, Test RMSE: {rmse_test}")
# Train RMSE: 2079.484814769608, Test RMSE: 19711.16864024852我们的模型似乎严重过度拟合。因此,我们现在将合并网格搜索来解决这个问题。
from sklearn.model_selection import GridSearchCV 现在,让我们仔细看看GridSearchCV课堂。它接受的参数如下:
estimator是将用于训练的模型。param_grid指定要搜索的超参数空间。它应该是一个字典或一个字典列表,其中每个字典都包含一组要尝试的超参数。scoring是用于评估模型性能的指标。它可以采用多种不同的形式,包括字符串、可调用函数和多个指标的字典。分类指标:准确度、精确度、召回率、f1。回归指标:neg_mean_squared_error,r2。聚类指标:adjusted_rand_score、silhoutte_score。这些是最受欢迎的,请访问此处查看整个列表。n_jobs指定用于并行计算的 CPU 核心数。值-1表示应使用所有可用的内核。refit指定是否使用搜索过程中找到的最佳超参数在整个数据集上重新拟合最佳估计器。默认情况下,refit设置为True,这意味着网格搜索完成后,GridSearchCV对象将使用找到的最佳超参数自动重新拟合整个数据集上的最佳估计器。cv指定交叉验证分割策略。它可以是一个整数值来指定折叠次数,也可以是一个交叉验证生成器,可用于定义更高级的交叉验证策略。verbose控制搜索期间输出的详细程度。pre_dispatch用于控制网格搜索期间并行启动的作业数量。它采用一个整数值,指定在任何给定时间可以启动的最大作业数。例如,如果pre_dispatch=2,则在任何给定时间不会并行启动超过 2 个作业。error_score用于指定如果无法完成拟合过程,应为超参数组合分配什么分数。在网格搜索过程中,GridSearchCV算法为每个超参数组合训练和评估模型。但有时,由于内存不足或数值不稳定等原因,模型可能无法拟合或评分。在这种情况下,GridSearchCV算法需要为失败的超参数组合分配一个分数,以便它可以继续搜索。return_train_score指定是否在输出中包含训练分数。
param_grid = {
'learning_rate': [0.01, 0.1],
'n_estimators': [100, 500],
'max_depth': [3, 5],
'colsample_bytree': [0.5, 0.9],
'gamma': [0, 0.1, 0.5],
'reg_alpha': [0, 1, 10],
'reg_lambda': [0, 1, 10],
}
xgb = xgb.XGBRegressor(random_state=1)
grid_search = GridSearchCV(xgb, param_grid=param_grid, cv=5, n_jobs=-1, verbose=1,
scoring="neg_root_mean_squared_error", )
grid_search.fit(X_train, y_train)
#Fitting 5 folds for each of 432 candidates, totaling 2160 fits GridSearchCV对搜索空间中 432 个不同的超参数组合中的每一个执行 5 倍交叉验证(即,将数据分成 5 个部分并训练模型 5 次,每次使用不同的部分作为验证集)。这导致总共 2160 次拟合(即训练模型并评估其性能 2160 次)。
我们现在已经创建了网格搜索对象。接下来,让我们探索一下可以使用的可用属性。
best_estimator_返回根据指定的评分指标在所有候选者中被选为最佳的估计器。best_score_返回最佳估计器在测试数据上获得的平均交叉验证分数。best_params_返回产生最佳结果的超参数的字典。cv_results_返回一个字典,其中包含有关每个超参数组合性能的详细信息,包括交叉验证分数的平均值和标准差、对每个模型进行拟合和评分所需的时间以及每个模型的超参数值。best_index_返回字典中最佳超参数组合的索引cv_results_。scorer_表示用于评估网格搜索期间模型性能的评分函数。n_splits_表示网格搜索期间交叉验证过程中使用的折叠数。refit_time_表示在整个数据集上重新拟合最佳估计器所花费的时间。multimetric_指示网格搜索期间是否使用了多个评估指标。classes_返回目标变量中的唯一类标签。n_features_in_返回输入数据中的特征数量。feature_names_in_是拟合期间看到的特征的名称。
print("Best estimator: ", grid_search.best_estimator_)
"""
Best estimator: XGBRegressor(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=0.5,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.1, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=5, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=100, n_jobs=0,
num_parallel_tree=1, predictor='auto', random_state=1, reg_alpha=0,
reg_lambda=0, ...)
"""print("Best score: ", grid_search.best_score_)
print("Best hyperparameters: ", grid_search.best_params_)
"""
Best score: -23298.387344638286
Best hyperparameters: {'colsample_bytree': 0.5, 'gamma': 0, 'learning_rate': 0.1, 'max_depth': 5, 'n_estimators': 100, 'reg_alpha': 0, 'reg_lambda': 0}
"""results_df = pd.DataFrame(grid_search.cv_results_)
results_df.head()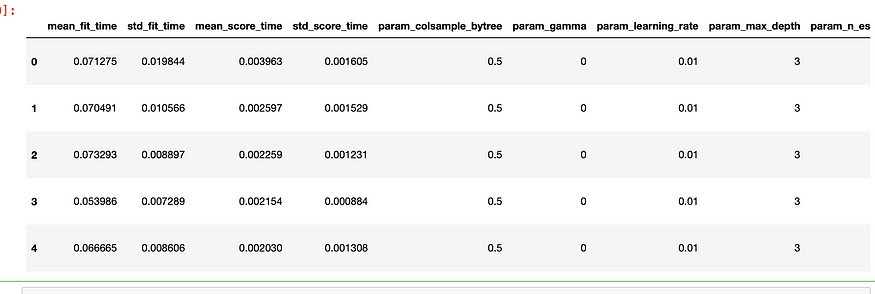
简历结果数据框。图片由作者提供。
print("Best index: ", grid_search.best_index_)
print("Best scorer: ", grid_search.scorer_)
print("Best n splits: ", grid_search.n_splits_)
print("Best refit time: ", grid_search.refit_time_)
print("Best multi metric: ", grid_search.multimetric_)
print("Best n features: ", grid_search.n_features_in_)
"""
Best index: 54
Best scorer: make_scorer(mean_squared_error, greater_is_better=False, squared=False)
Best n splits: 5
Best refit time: 0.055130958557128906
Best multi metric: False
Best n features: 51
"""我们现在可以使用最好的模型。我们已经取得了一些小小的进步。
best_model = grid_search.best_estimator_
best_model.fit(X_train, y_train)
y_pred = best_model.predict(X_test)
rmse_train = np.sqrt(mean_squared_error(y_train, best_model.predict(X_train)))
rmse_test = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"Train RMSE: {rmse_train}, Test RMSE: {rmse_test}")
"""
Train RMSE: 6502.070891973686, Test RMSE: 17419.48195947506
"""四、后记
GridSearchCV 评估指定超参数的所有可能组合,这可以帮助识别给定模型的最佳超参数集。而且,它确保在模型的不同运行中使用相同的超参数,从而促进可重复性。
评估超参数的所有可能组合的计算成本可能很高,尤其是对于更大的数据集和更复杂的模型。如果搜索空间太大,它也可能容易出现过度拟合,这可能导致对未见过的数据的泛化性能较差。


![buuctf[强网杯 2019]随便注 1(超详细,三种解法)](https://img-blog.csdnimg.cn/img_convert/1aa5220a282ceac998065c80dc38af21.png)