从本章开始,本书将会进行深度学习图像分割的实战阶段。PyTorch作为目前最为流行的一款深度学习计算框架,在计算机视觉和图像分割任务中已经广泛使用。本章将介绍基于PyTorch的深度学习图像分割代码框架,在总体框架的基础上,基于PASCAL VOC 2012数据集,分别介绍预处理模块、数据导入模块、模型模块、工具函数模块、配置模块、主函数模块、推理模块和部署模块等。每个模块都会在基本的代码结构基础上配以简单的代码示例,帮助读者快速掌握深度学习图像分割的代码范式。
图像分割代码总体框架
深度学习项目的代码框架和范式整体较为固定,一般按照机器学习的pipeline都会有:数据预处理、数据导入、模型搭建、训练、验证、测试和部署等流程。图像分割作为经典的深度学习应用方向之一,也不例外地遵循上述范式。根据深度学习图像分割项目的特点,一个相对完整的图像分割代码框架应包含:预处理模块、数据导入模块、模型模块、工具函数模块、配置模块、主函数模块、推理模块和部署模块。
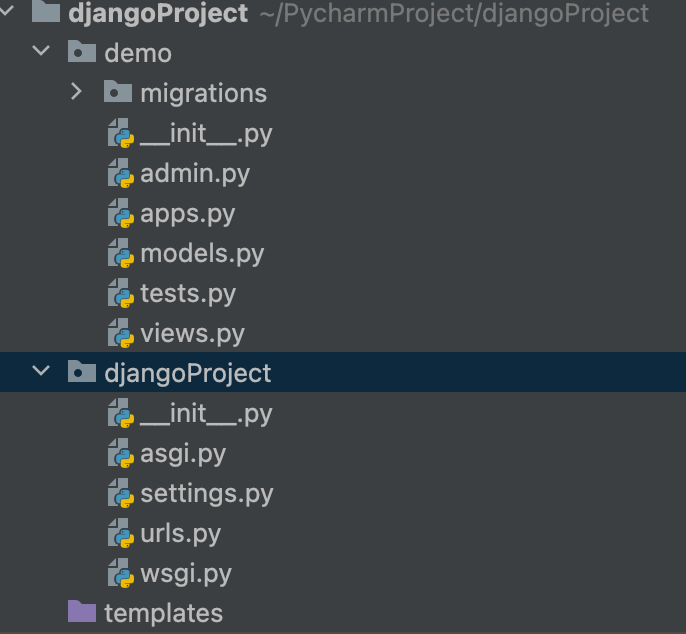
PyTorch是目前最为流行的深度学习计算框架,无论在学术界还是工业界,都被广大用户作为首选用来进行项目搭建的框架。基于PyTorch的深度学习图像分割代码框架结构如图1所示。

图1是一个典型的深度学习图像分割代码框架,也是一个分割项目的工程示例。左侧为代码目录结构,与虚线对应的右侧部分则是具体的模块和功能文档名称。除了前述的8个核心模块之外,图中还补充了基于Jupyter Notebook的experiment.ipynb实验文档,方便开发者在将代码写成工程文件前进行一些尝试性的实验和探索。README.md文档则是关于该项目的说明文档,具体可包括项目的基本情况介绍,训练、验证和测试方法等。需要注意的是,图11-1仅是一个典型的参考代码框架,具体的目录结构可能会因开发者的习惯和项目的特殊需要而有所不同。但不论什么样的深度学习图像分割项目,数据、模型和包含训练验证的主函数这三个部分,一定是不可或缺的。
本章将基于经典的语义分割数据集PASCAL VOC 2012,针对上述8个代码模块,在给出基本代码模板的基础上,进而给出完整的代码实现方式。关于PASCAL VOC 2012数据集相关信息,读者可直接参考本书第10章内容。
预处理模块
数据预处理模块主要用于定义一些图像预处理的功能函数,包括像数据标准化方法、图像转换方法、图像重采样方法等。预处理模块不是必须的,具体结合每个分割项目的图像数据集实际情况来定,对于PASCAL VOC 2012这样成熟的公开数据集,可能一般不需要太多预处理的流程,但对于个人收集的原始数据、一些医学影像或者遥感影像等特定领域的图像数据,可能需要一定的预处理过程。预处理模块需要用户结合个人数据集实际情况酌情进行定义。在图像分割项目中,如果我们的图像数据集需要预处理,我们可以在preprocess.py文件中定义预处理过程。
数据导入模块
PyTorch提供了数据导入的标准化代码模板,可以直接借助于torch.utils.data模块下的数据对象类Dataset来完成数据的定义和读取,然后再借助于数据导入类DataLoaders将数据按批次导入到模型中。基于Dataset的数据读取框架如代码11-1所示。
# 导入数据对象类Dataset
from torch.utils.data import Dataset
# 基于Dataset的数据定义和读取框架
class CustomDataset(Dataset):
def __init__(self, ...):
# stuff
def __getitem__(self, index):
# stuff
return (img, label)
def __len__(self):
# return examples size
return len(self.images)其中CustomDataset为自定义的数据对象类,该类继承于Dataset类,下面包括三个方法:__init__为类初始化方法,包含了数据的存放路径、输入图像、输出图像以及数据变换等属性的定义;__getitem__定义了图像读取和变换方法,一般可通过pillow库的Image.Open先完成读取,再用torchvision库下的transform完成数据变换;__len__方法则通过调用内置函数len返回数据的长度。按照该数据读取框架,我们可以定义PASCAL VOC 2012数据集的读取方法,定义voc.py文件如下。
# 导入相关模块
import numpy as np
from PIL import Image
from pathlib import Path
from torch.utils.data import Dataset
# 定义VOC数据集类
class VOCSegmentation(Dataset):
"""
A PyTorch Dataset class for the VOC Segmentation dataset.
"""
def __init__(self, root, image_set='train', transform=None):
"""
Initialize the dataset.
Args:
root (str): Path to the dataset root directory.
image_set (str): The image set to use ('train' or 'val').
transform (callable, optional): A function/transform to apply to the images and masks.
"""
self.root = Path(root)
self.transform = transform
self.image_set = image_set
base_dir = 'VOCdevkit/VOC2012'
voc_root = self.root / base_dir
image_dir = voc_root / 'JPEGImages'
if not voc_root.is_dir():
raise RuntimeError('Dataset not found.')
mask_dir = voc_root / 'SegmentationClass'
splits_dir = voc_root / 'ImageSets/Segmentation'
split_f = splits_dir / f"{image_set.rstrip()}.txt"
with open(split_f, "r") as f:
file_names = [x.strip() for x in f.readlines()]
self.images = [image_dir / f"{x}.jpg" for x in file_names]
self.masks = [mask_dir / f"{x}.png" for x in file_names]
assert (len(self.images) == len(self.masks))
def __getitem__(self, index):
"""
Get an item from the dataset.
Args:
index (int): Index of the item to get.
Returns:
tuple: (image, target) where target is the image segmentation.
"""
img = Image.open(self.images[index]).convert('RGB')
target = Image.open(self.masks[index])
if self.transform is not None:
img, target = self.transform(img, target)
return img, target
def __len__(self):
return len(self.images)如代码11-2所示,我们通过pathlib库来定义数据路径,通过pillow的Image.open函数来读取图像并进行同步转换。除此之外,VOC数据集掩码还需要单独进行颜色编码的接码,所以实际操作时要单独定义voc_map函数以及在VOCSegmentation类中补充一个掩码图像的解码方法decode_target。完整代码可参考本书配套代码对应章节。
需要特别说明的是,torchvision库中提供的transform模块提供了各种图像变换方法,也就是我们通常所说的在线数据增强(Online Data Augmentation)。在线数据增强是指在训练过程中,每次读取一个样本时都会进行数据增强操作。也就是说,数据增强是在每个小批量(batch)的数据上实时进行的。在线数据增强可以通过数据转换的方式,在每个训练迭代中生成多个不同的数据样本,以增加训练集的多样性,但不实际增加训练数据的数量。常见的在线数据增强操作包括随机裁剪(random cropping)、翻转(flipping)、旋转(rotation)、缩放(scaling)等。与在线数据增强对应的是离线数据增强(Offline Data Augmentation)。离线数据增强是指在训练开始之前,将原始数据集进行增强,并将增强后的数据保存为新的训练集。然后,在训练过程中,使用增强后的训练集进行模型训练。离线数据增强的好处是可以节省训练时间,因为数据增强只需在训练开始之前完成一次。常见的离线数据增强操作包括扩充数据集,例如通过旋转、平移、缩放等方式生成新的图像。常用的离线数据增强库包括imgaug、albumentations和Augmentor等。在代码11-2中,我们在初始化方法里面提供数据transform方式,同步接收img和target作为输入进行在线数据增强,以增强训练样本的多样性。当然了,这需要我们对torchvision中的transform方法稍微进行改动。
后续全书内容和代码将在github上开源,请关注仓库:
https://github.com/luwill/Deep-Learning-Image-Segmentation
(未完待续)


![JWT的封装、[Authorize]的使用](https://img-blog.csdnimg.cn/85870169bd3e43c0909cf35764f5cdb6.png)