作者:苍何,CSDN 2023 年 实力新星,前大厂高级 Java 工程师,阿里云专家博主,土木转码,现任部门技术 leader,专注于互联网技术分享,职场经验分享。
🔥热门文章推荐:
- (1)对程序员来说,技术能力和业务逻辑哪个更重要?
- (2)搭建GitHub免费个人网站(详细教程)
- (3)itchat实现微信聊天机器人
- (4)嗖嗖移动业务大厅(源码下载+注释全 值得收藏)

大家好,我是苍何。在 1024 程序员节的前一天发生了一件震撼的事情,那就是语雀停服了近 8 个小时,期间包括官网、APP、客户端、 Web 端全面崩溃,且经过了漫长的 8 小时才得以修复。
这一故障简直可以载入软件开发史册,可以用不可思议来形容。我是第一次见互联网公司产品奔溃后是 502 或者重定向的错误,就连 B 站当年奔溃也会有友好提示页面,而语雀的这次奔溃,连静态错误页面都没有,真是让人大跌眼镜。
因为当时我正在语雀上写文档,也算是见证了整个事件的过程,这里也记录一下。
一、语雀是什么
语雀是蚂蚁集团内部孵化的一款笔记类工具,友好的 Markdown 支持,丰富的绘图模板、简洁的界面和近乎完美的知识库管理使得语雀收获了大量的用户,除去整个阿里和蚂蚁集团内部用户外,保守估计用户量千万级别以上,可谓是非常庞大的用户体系了。
我也是一路见证了语雀的成长,早年间,还只是我们在整个集团内部使用,后面扩展到整个阿里,所有文档的沉淀都在语雀进行。后面因受到集团内一致好评以及从集团毕业后的用户的强烈渴望开放外网使用,于是有了外网的版本,从最初的 web 页面,到后面的 APP 和客户端的支持,到后面的数字花园,语雀产品始终走在同类产品前列,而且这个产品对互联网行业有着天然的支持,他甚至比我们更懂我们。
我离开蚂蚁后,也像大多数人一样,使用习惯了语雀,参加活动得了一年的会员,把所有的知识都从印象笔记移到了语雀,基本是 ALL in 语雀。
二、语雀暂别的这 8 小时
在 2023年10月23 日 14:10,突然语雀客户端断开连接,我重试了好几次也没用,一直提示的是这个界面:
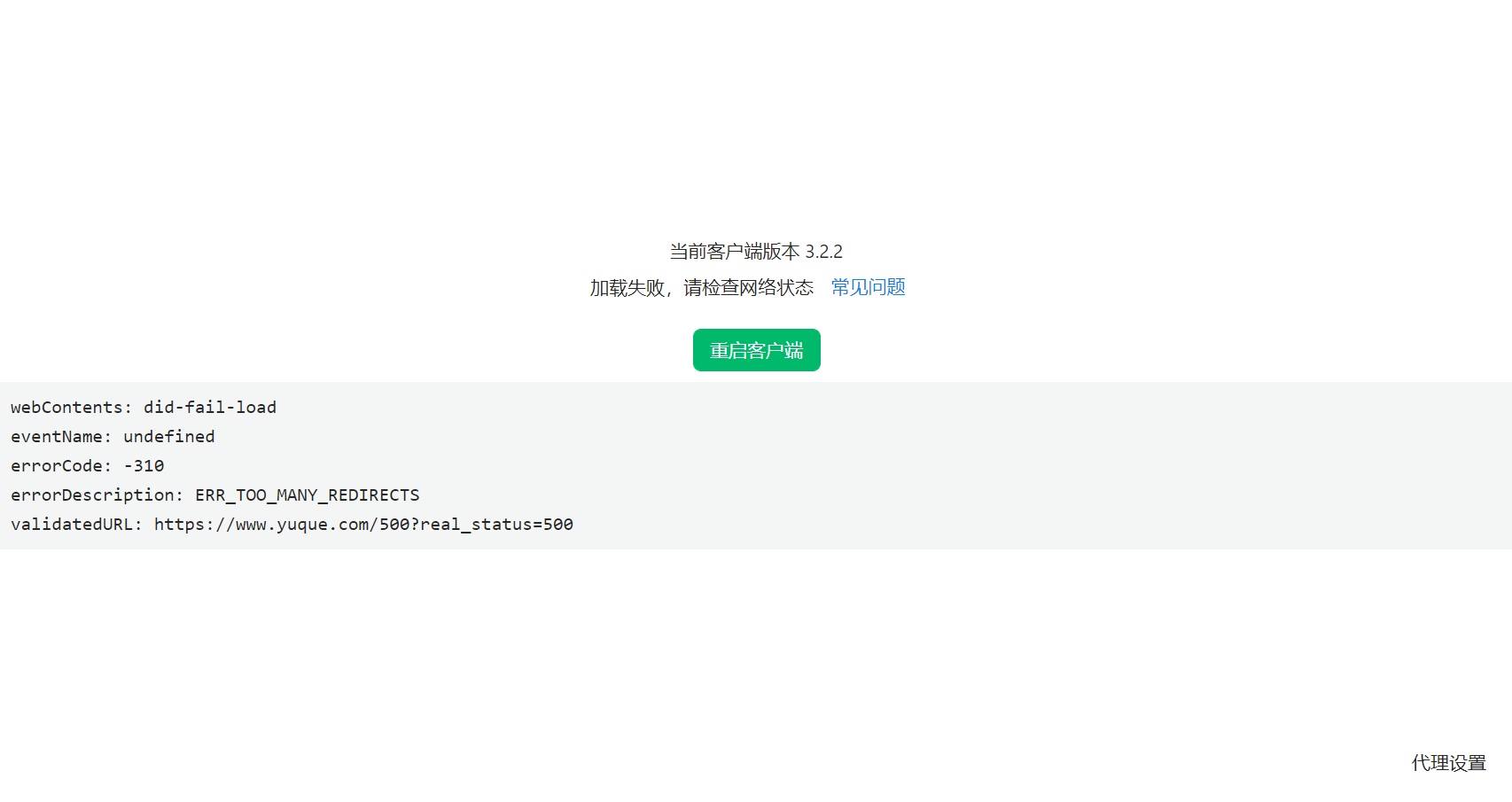
刚开始以为是网络问题,关掉代理后重试也无果,后我又去网页版打开,也还是提示多次重定向失败。
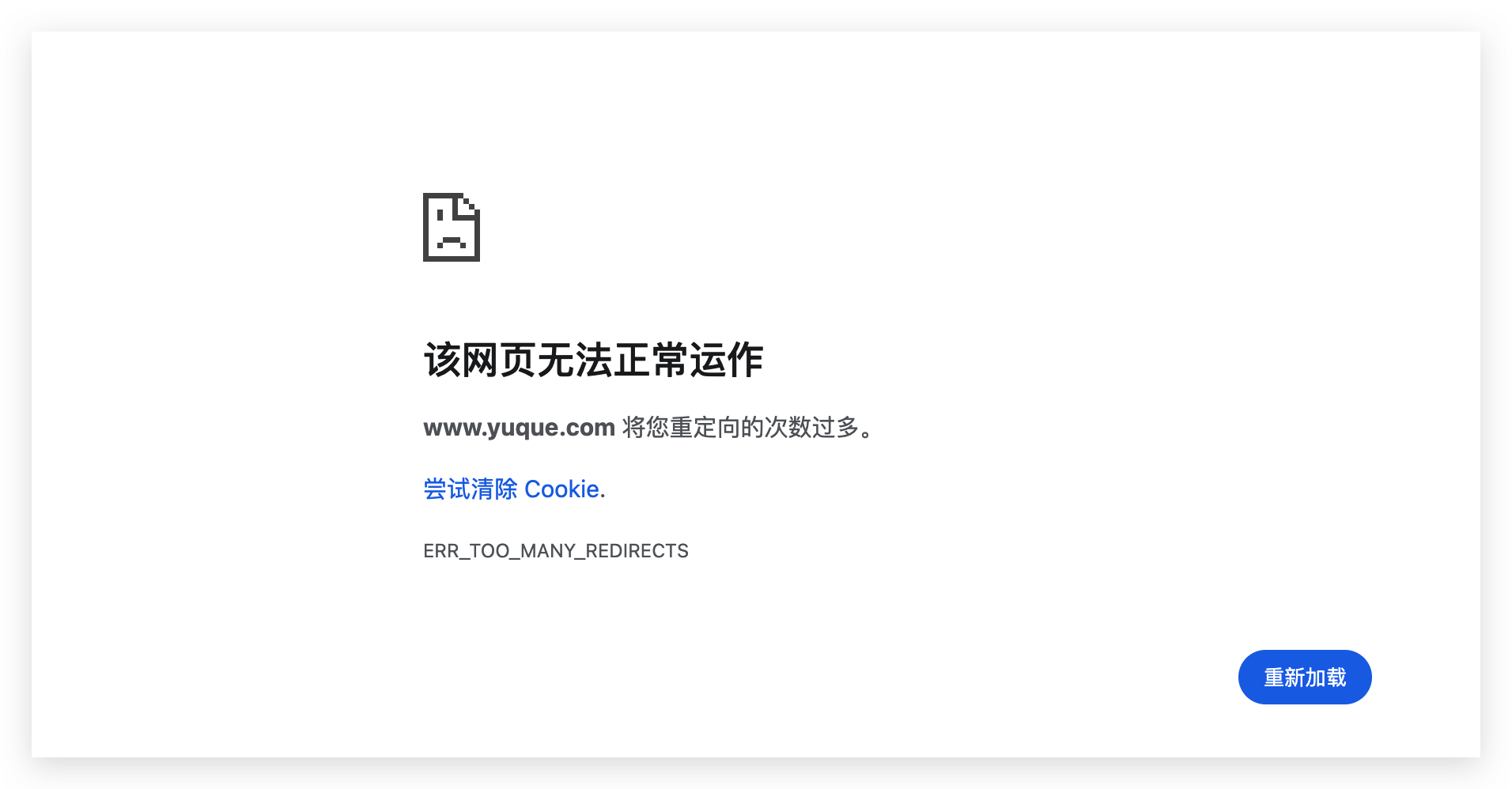
我知道事情没这么简单,于是 14:19 我在用户群寻求帮助,相继其他小伙伴也发现了问题。
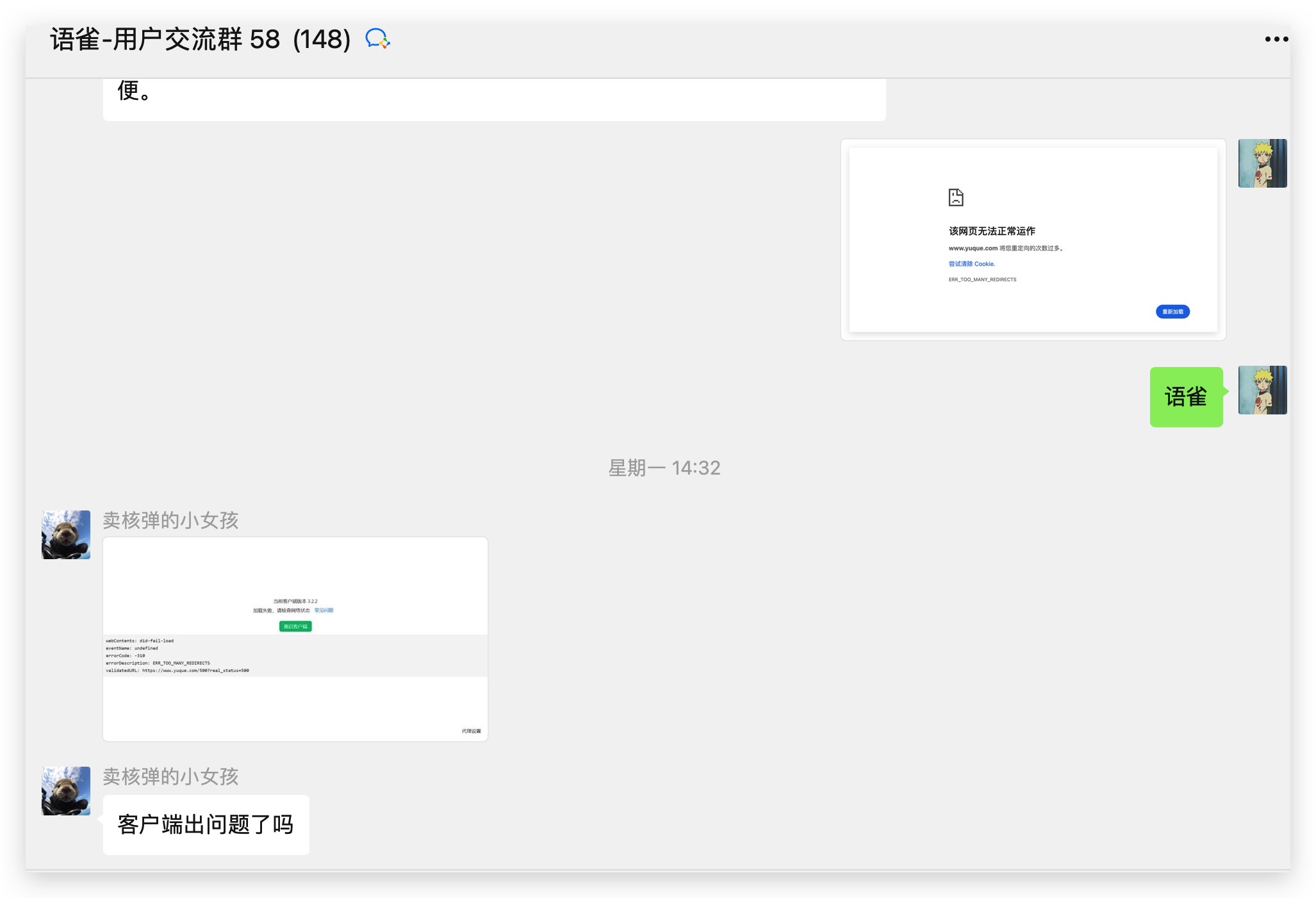
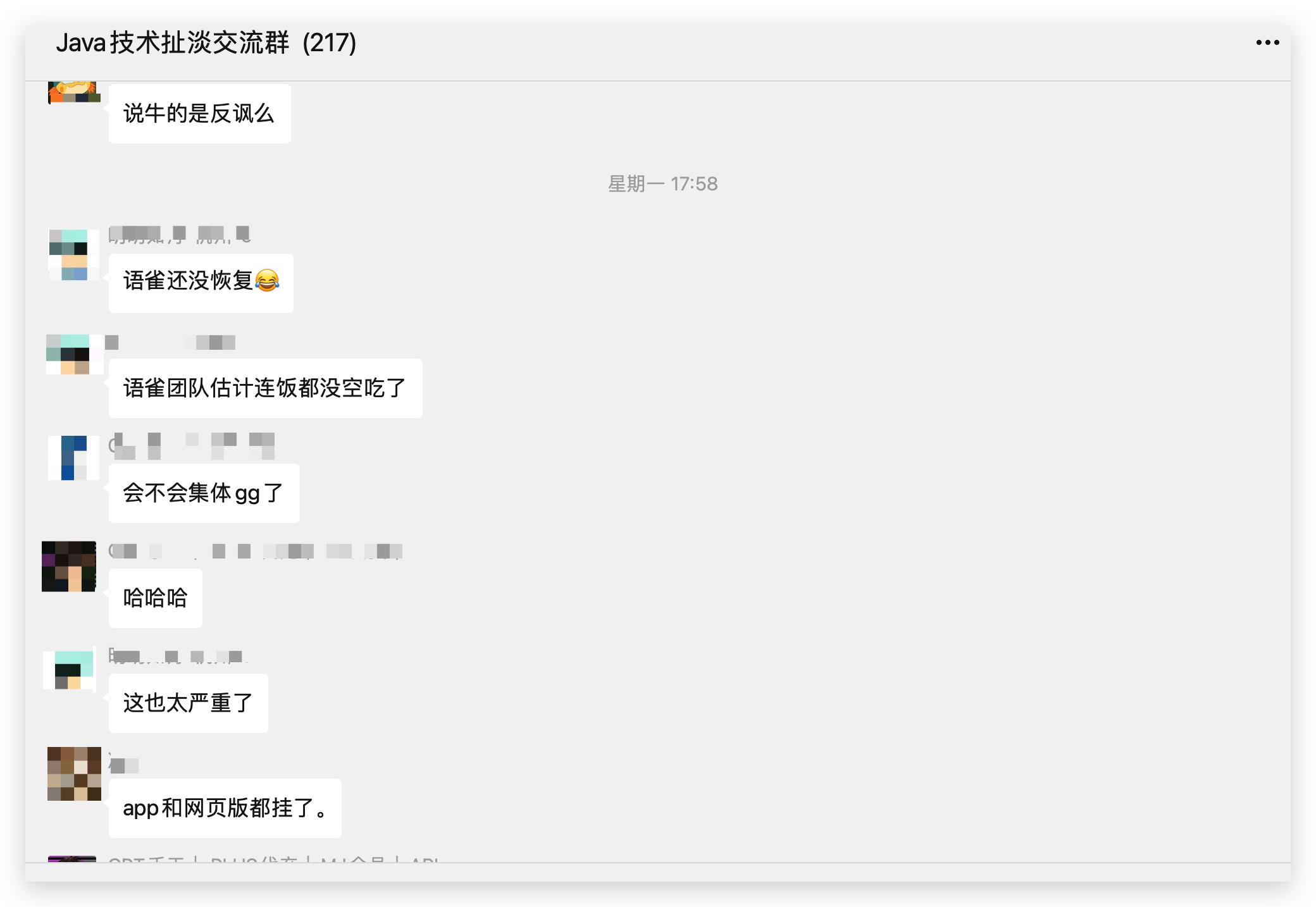
之后的这段时间到语雀官方发布通告,群里各种炸开了锅,有在说这得 325 了,有在说这是要赶在 1024 拿程序员祭天啊,讨论络绎不绝。
此时,很多竞品比如飞书,开始疯狂打起了广告,速度可谓惊人。
15:07 官方公众号上发布通知:
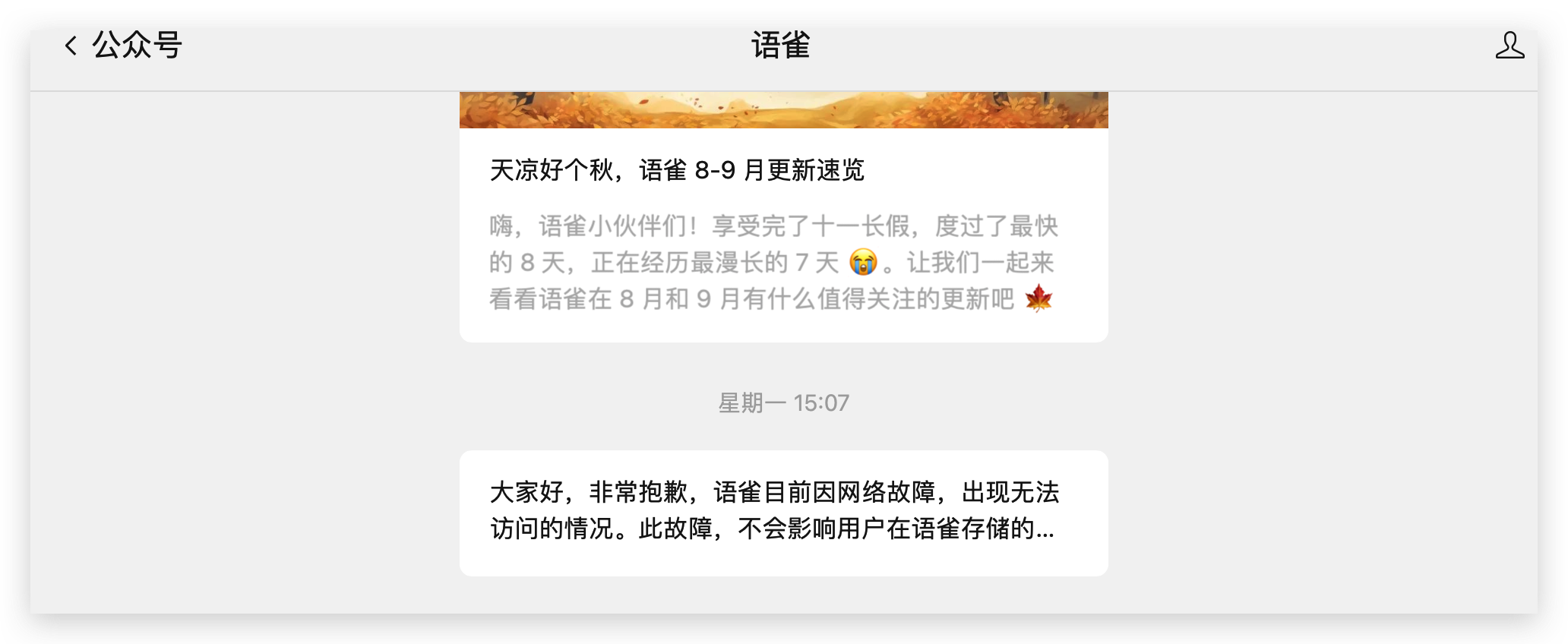
为了缓解大家数据丢失的焦虑,还特意强调数据不会丢失。
之后就是漫长的修复,期间语雀还是永远停留在了 502 这个界面。

三、故障复盘
关于这次事件,网上猜测的原因很多,最搞笑的是下面这条,当时看到笑了好久,哈哈哈!
具体原因大家也不用猜测和分析了,官方刚已经同胞了原因:关于语雀 23 日故障的公告
给官方通告做个总结:
:::info
- 故障时间:10月23日下午。
- 故障现象:语雀出现重大服务故障,持续 7 个多小时。
- 直接原因:数据存储运维团队在进行升级操作时,新的运维升级工具出现 bug。
- 具体细节:bug导致华东地区生产环境存储服务器被误下线,使语雀数据服务发生严重故障,造成大面积服务中断。
- 恢复过程:
- 因机器类别较老,无法直接操作上线,只能从备份系统中恢复存储数据。
- 数据恢复过程耗时较长,直到晚上 22 点,语雀的全部服务才得以恢复。
:::
此次的故障,完全脱离了蚂蚁技术军规的红线,即“可监控,可灰度,可回滚”,我记得当年在蚂蚁,从上到下,一直在强调三板斧的要求,因为大部分业务是涉及到资金嘛,所以我们的上线流程并没有想象中那么简单,通常一个小小的改动上线也要遵循上线的全套流程。
原因中说道,因新的运维工具升级出现 bug,导致华东地区生产环境存储服务器被误下线,这就有些不可思议了,按理说生产环境存储服务器的上下限是会经过严格的审批,从 TL 到业务 leader,经过层层审核才可操作,那么这中间是缺省了环节,还是相关审批人员的失职?这是语雀团队需要仔细反思的。
四、用户补偿
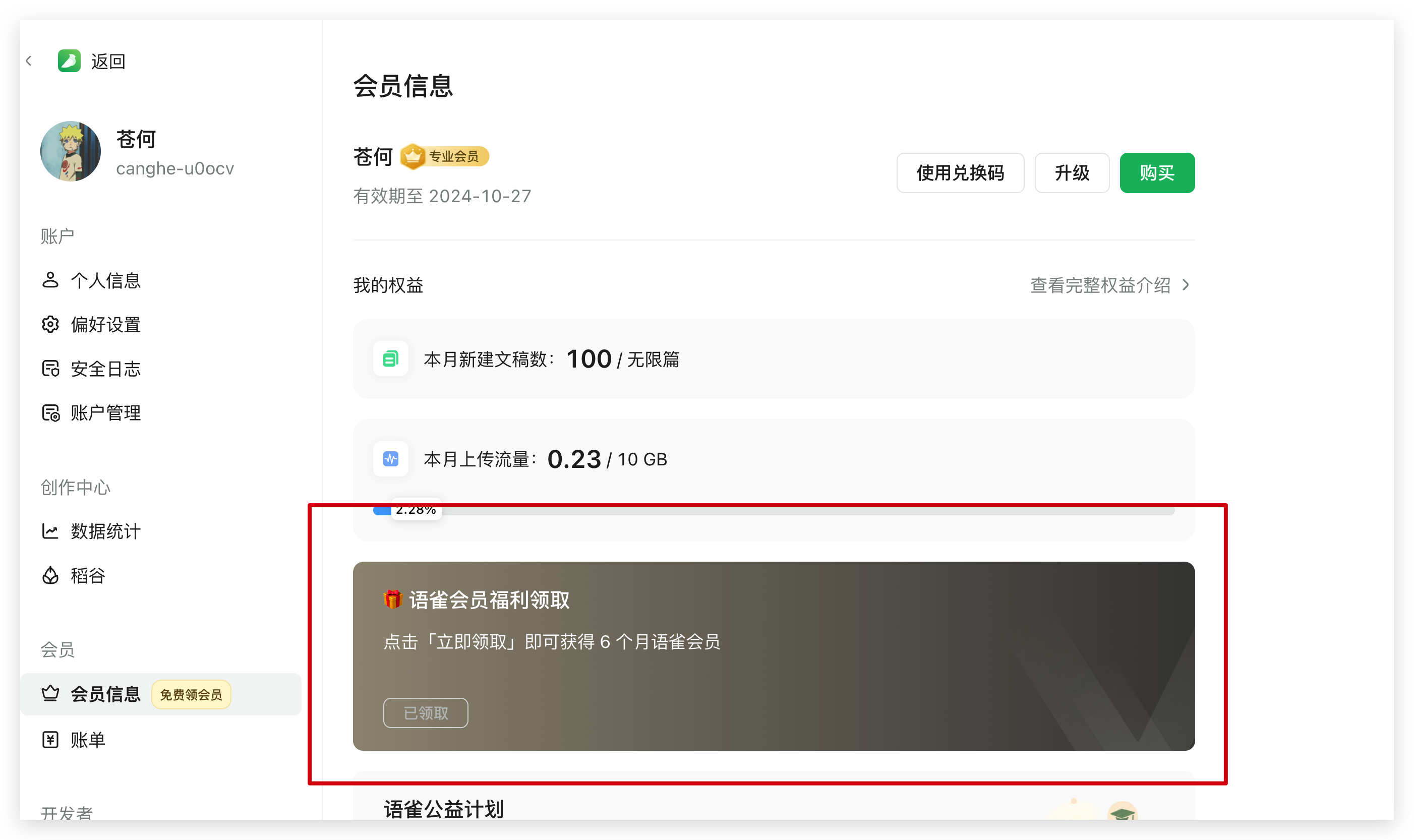
虽说这次语雀经过了长达如此之久的故障让人很震撼和不可思议,甚至有些让我对其产品失去信心,但其补偿方案看了那叫一个香。白嫖 6 个月的会员,没有领取的小伙伴赶紧冲一波了。

五、我的思考
通过这次的事件,也有一些思考。
1. 强化预防措施:
- 在进行任何系统升级或修改之前,应确保有详尽的预案和充分的测试。
- 加强运维工具的质量保障和测试,确保工具的稳定性和可靠性。
- 始终坚持三板斧原则:即“可监控,可灰度,可回滚”,
2. 优化故障应对机制:
- 在故障发生时,能够迅速准确地定位问题,缩短故障恢复时间。
- 建立健全的故障应急响应机制和流程,以便在出现问题时能够迅速、有序地进行处理。
3. 完善系统架构:
- 考虑系统的高可用性和灾备设计,减少单点故障的风险。
- 考虑到机器的更新换代,避免因硬件陈旧导致的操作限制。
4. 增强用户沟通:
- 在故障发生时,及时、准确地通知用户,降低用户的不确定感和焦虑感。
- 在故障恢复后,向用户说明故障原因和改进措施,增加用户的信任感。
5. 持续改进和学习:
- 从故障中吸取教训,总结经验,避免类似问题的再次发生。
- 定期进行故障演练,提高团队的应对能力。
通过这次故障,相信语雀团队也能更清晰地认识到自身在服务稳定性和应急响应方面的不足,从而采取更加全面和有效的措施,不断优化和提高服务质量,为用户带来更好的使用体验。
最后如果大家有兴趣,欢迎关注下我语雀的数字花园:苍何的数字花园

创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。