文章目录
- 一、背景
- 二、方法
- 2.1 Adaptive Scale Fusion (ASF) 模块
- 2.2 Binarization
- 2.3 Adaptive Threshold
- 2.4 Deformable Convolution
- 2.5 Label Generation
- 2.6 Optimization
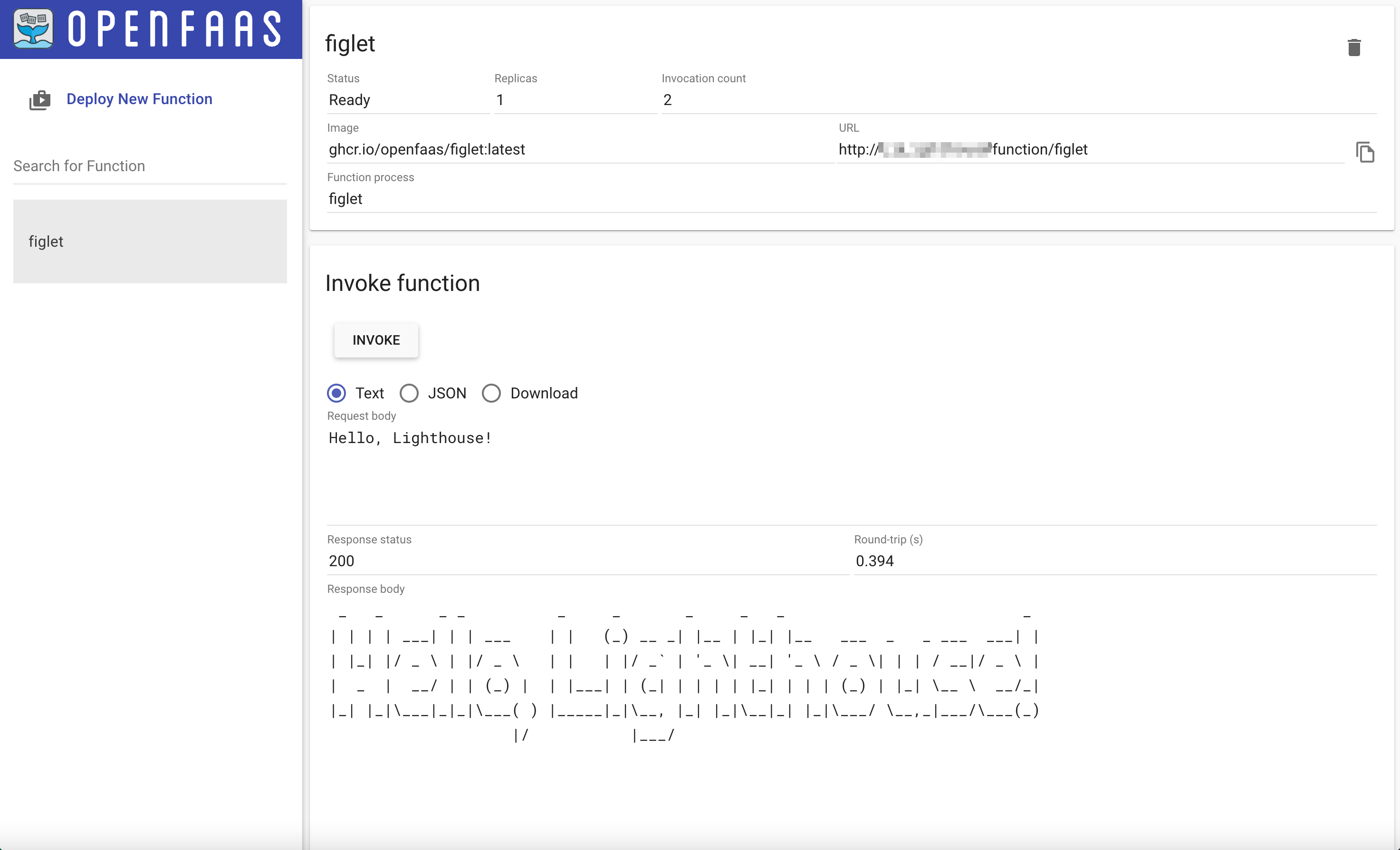
- 三、效果
论文:Real-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
代码:https://github.com/open-mmlab/mmocr/tree/main/configs/textdet/dbnetpp
出处:TPAMI 2022 | 和 DBNet 出自同一团队
一、背景
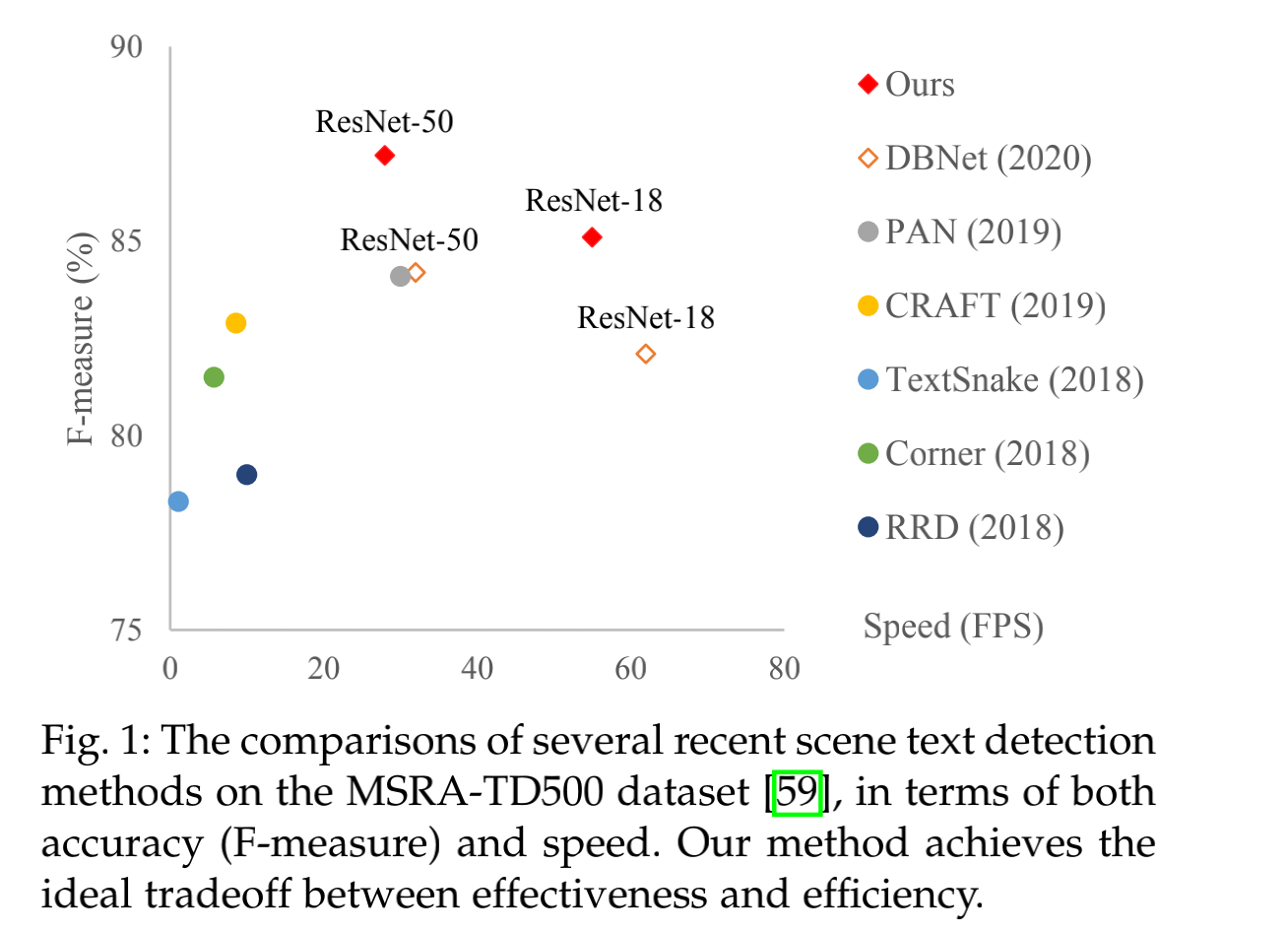
文本检测的目的是在图像中定位出文本的位置,是文本识别的基础。
基于分割的方法能够得到像素级的表达,但是,后处理的处理方式对检测结果影响很大。
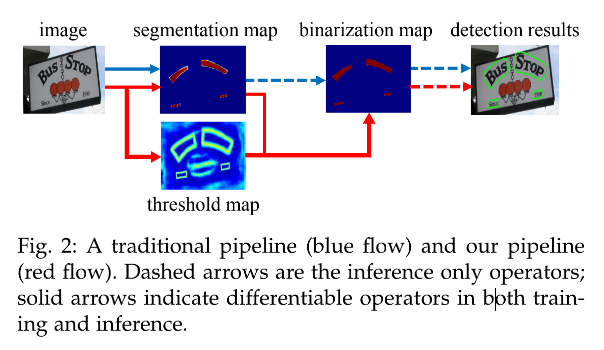
如图 2 所示的蓝色箭头表示的后处理方式是基于分割方法的基础处理方式:
- 首先,将分割结果图使用二值化的方式变成二值化图
- 然后,使用启发式的方法(如像素聚合)将一簇的像素聚合成文本区域
- 这两个过程是独立进行的,不能参与训练过程,会导致检测准确率较低
本文的作者首先提出了 DBNet,将特征图二值化的过程构建成了一个可微的过程,可以直接参与到训练中,如图 2 红色箭头所示:
- 首先,还是生成分割结果图,但也同时会预测一个 threshold map,也就是图 2 中高亮的那个特征图,这样不同位置的阈值是不同的,这样做的原因在于,作者认为文本区域的边界区域的置信度应该是比中心区域低的。
- 然后,作者引入了二值化操作的一个近似方法:Differentiable Binarization (DB),使用 threshold map 来对分割图进行二值化,这样就可以联合优化分割过程和二值化过程,可以得到更好的检测结果
DBNet++ 的出发点:
- 在 DBNet 中,作者在分割网络中直接对多尺度的特征图聚合来提高对不同尺度的鲁棒性,直接聚合缺少了对特征的选择性
- DBNet++ 中,作者提出了 Adaptive Scale Fusion (ASF) module,来动态聚合多尺度特征图
ASF 模块的特点:
- ASF 是一个 stage-wise attention 模块,并且其中引入了 spatial attention 模块,能够在空间维度学习不同尺度和不同空间位置的权重,达到 scale-robust 特征融合
DBNet++ 和 DBNet 的关联:
- 第一点,DBNet++ 在 DBNet 的基础上引入了 ASF 模块,加强分割网络中不同尺度特征的融合
- 第二点,DBNet++ 将 DBNet 中的理论分析更完善化了
DBNet 的贡献:
- 联合优化分割网络的 DB 模块,能够获得更加鲁棒的结果并提升文本检测的效果
- 在 infer 过程中,DB 模块可以被移除且对最终效果没有明显的影响,故在 infer 过程中不会带来额外的时间消耗
- ASF 模块能够给分割网络引入更鲁棒的特征
- DBNet++ 在多个文本检测数据集上达到了 SOTA 的效果,包括水平、多方向旋转、弯曲形状等
二、方法
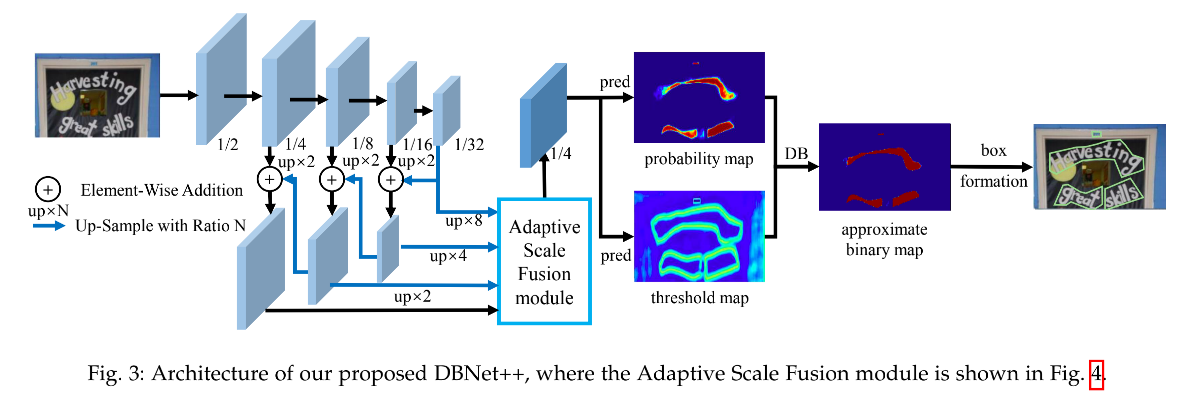
DBNet++ 的总体框架结构如图 3 所示:
- 首先,将图像输入金字塔形式的 backbone 中
- 然后,将金字塔特征图上采样到相同大小,并输入 ASF 模块,得到特征图 F F F
- 之后,将 F 用于预测 probability map P P P 和 threshold map T T T,并使用 P P P 和 F F F 计算得到 approximate binary map B ^ \hat{B} B^
- 训练时,同时监督 P P P、 T T T 和 B ^ \hat{B} B^, P P P 和 B ^ \hat{B} B^ 共享监督信号
- 推理时,可以通过 box formation process 的方式从
P
P
P 或
B
^
\hat{B}
B^ 中来得到文本框
2.1 Adaptive Scale Fusion (ASF) 模块
不同尺度的特征图可以看做是从不同角度和感受野得到的特征图,所以如何融合不同尺度的特征图来得到文本区域是很重要的。
比如,浅层特征或大尺度的特征图可以看到更多的细节信息和小的文本实例,深层特征或小尺度的特征图可以看到大尺度的文本实例并且捕捉到全局信息。
为了更好的利用不同尺度的特征图,特征金字塔或 U-Net 结构在分割网络中使用的比较广泛
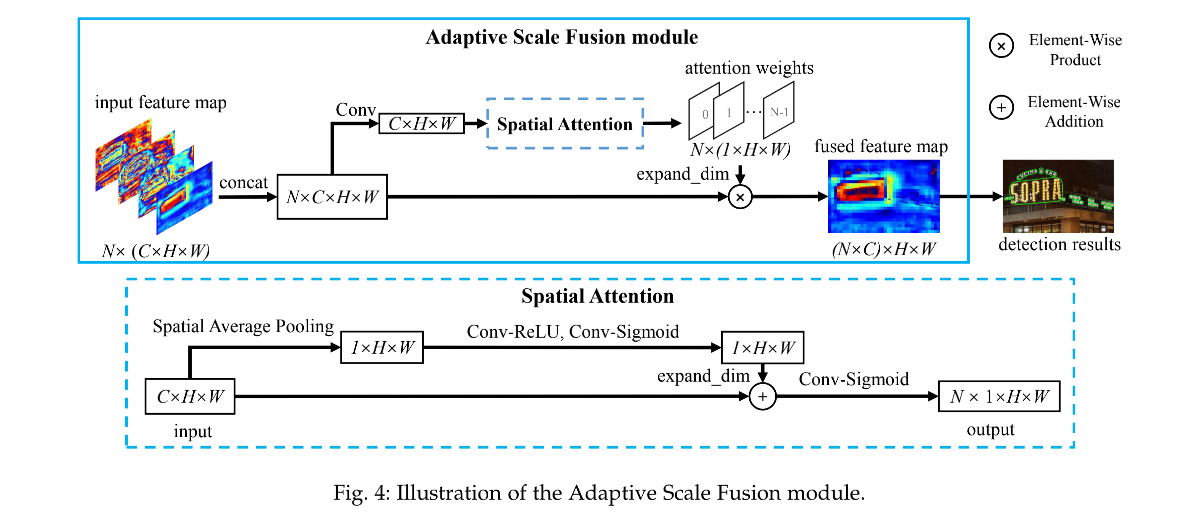
ASF 模块为了更好的融合不同尺度的特征,没有使用简单相加的方式,而是让网络自己选择不同尺度和不同位置特征的重要性,对特征进行动态的聚合。
ASF 模块的结构如图 4 所示:
- 首先,将不同尺度的特征图缩放到相同大小,然后输入 ASF 模块中,假设输入 ASF 模块的特征图包括 N 个特征图 X ∈ R N × C × H × W = { X i } i = 0 N − 1 X\in R^{N \times C \times H \times W}=\{X_i\}_{i=0}^{N-1} X∈RN×C×H×W={Xi}i=0N−1,其中 N=4。
- 然后,将经过尺度缩放的特征图 X X X concat 起来,经过 3x3 卷积,获得中间特征 S ∈ R C × H × W S \in R^{C \times H \times W} S∈RC×H×W
- 接着,在中间特征 S S S 上使用 spatial attention 模块,得到 attention weights A ∈ R N × H × W A \in R^{N \times H \times W} A∈RN×H×W
- 最后,在 channel 维度将 attention weights 切分成 N 个 parts,然后和对应的特征图相乘,得到加权后的特征图 F ∈ R N × C × H × W F \in R^{N \times C \times H \times W} F∈RN×C×H×W
Scale Attention 定义如下:
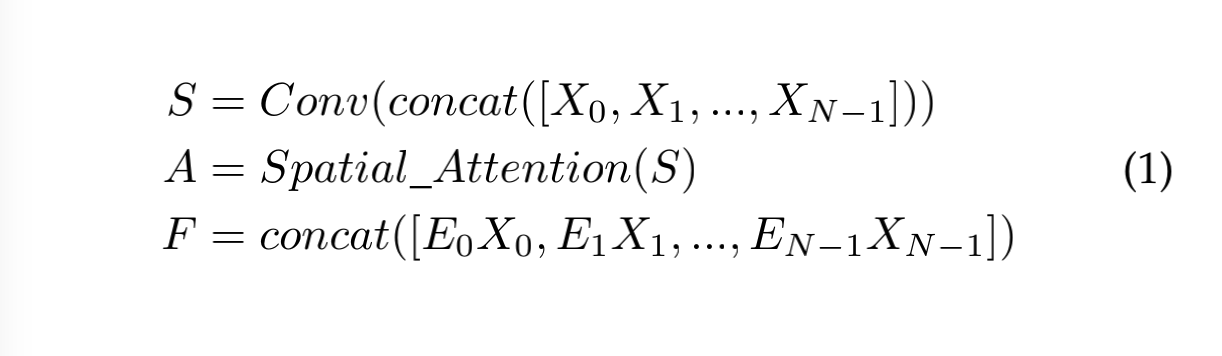
2.2 Binarization
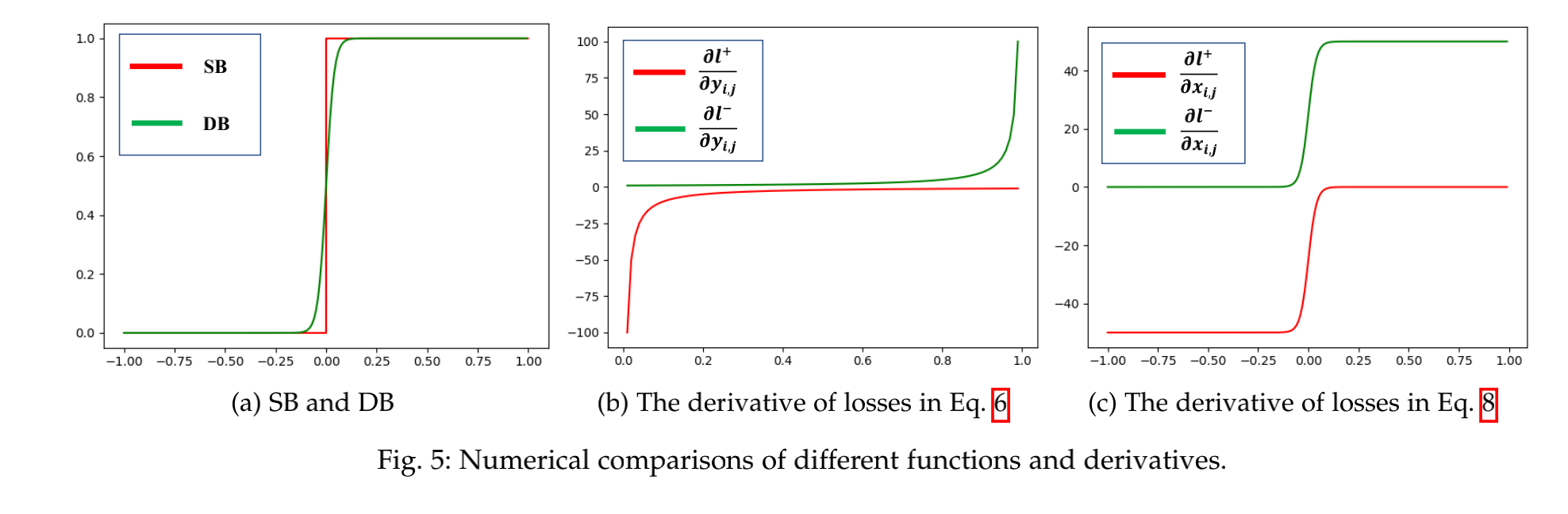
标准二值化(Standard Binarization)和可微二值化(Differentiable Binarization)的函数曲线如图 5a 所示,标准二值化在 0 处是不可微的。
1、标准二值化
给定从分割网络得到的 probability map P ∈ R H × W P \in R^{H \times W} P∈RH×W,将其二值化后,就会得到只包含 0 和 1 的二值化图,其中,0 表示背景,1 表示有效的文本区域,标准二值化过程如下:
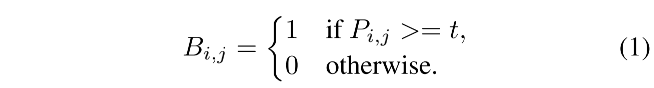
- t 是阈值
2、Differentiable binarization
如公式 1 所示的标准二值化是不可微的,所以不能和分割网络一起来训练,所以,本文作者提出了一个二值化的近似形式:
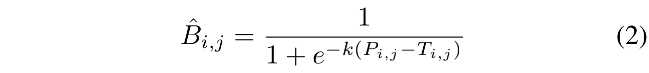
- B ^ \hat{B} B^ 是近似的二值图
- T 是从网络中学习到的 adaptive threshold map
- k 是一个增强因子,设定为 50
- 该近似的二值化函数和标准的二值函数类似,但可微,就可以随模型一起训练
DB 能够提升模型效果的原因可以用梯度的反向传播来解释,以二值化交叉熵 loss 为例。
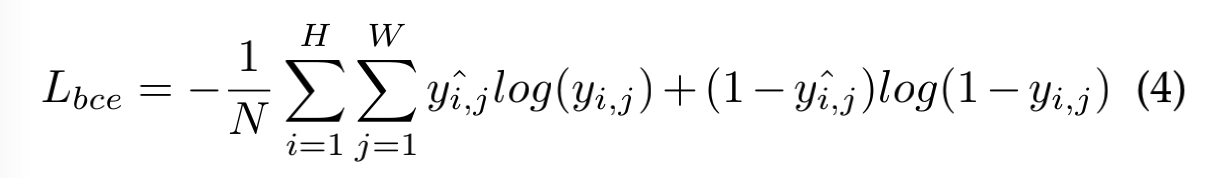
positive label 的 loss l + l_{+} l+ 和 negative label 的 loss l − l_{-} l− 如下:
segmentation loss:
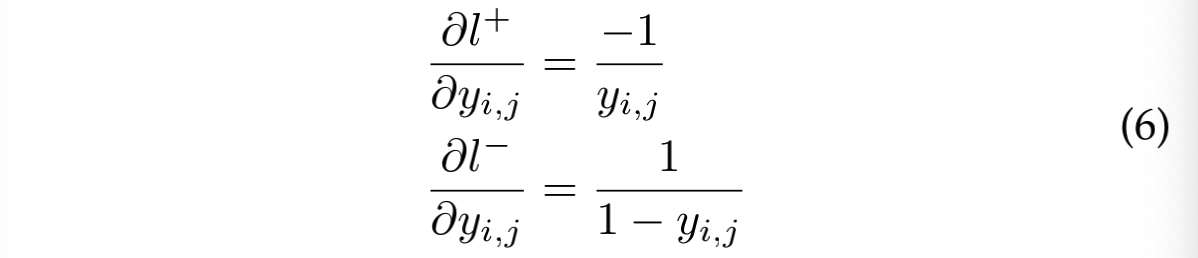
定义 DB 函数为: f ( x ) = 1 1 + e − k x f(x) = \frac{1}{1+e^{-kx}} f(x)=1+e−kx1
- 其中, x = P i , j − T i , j x = P_{i,j}-T_{i,j} x=Pi,j−Ti,j
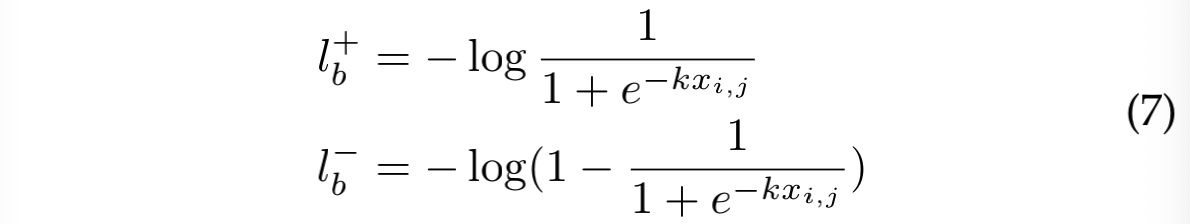
包含 DB 的 loss 微分如下:
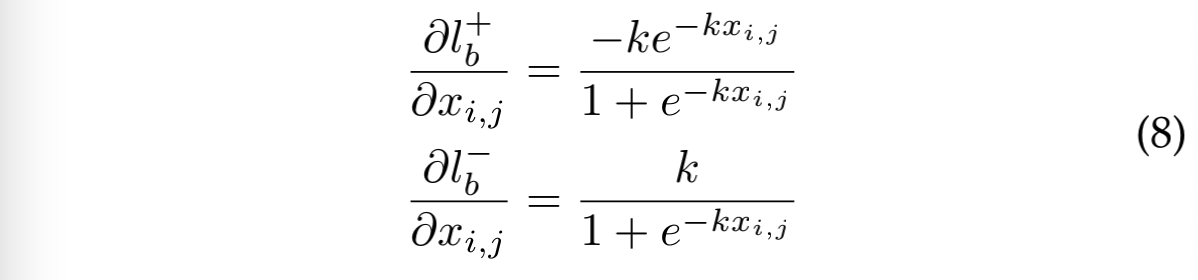
考虑激活函数 sigmoid:
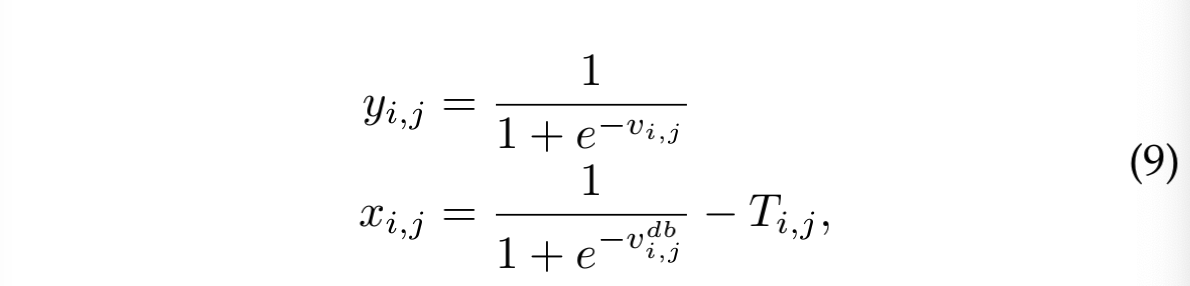
激活后的梯度如下:
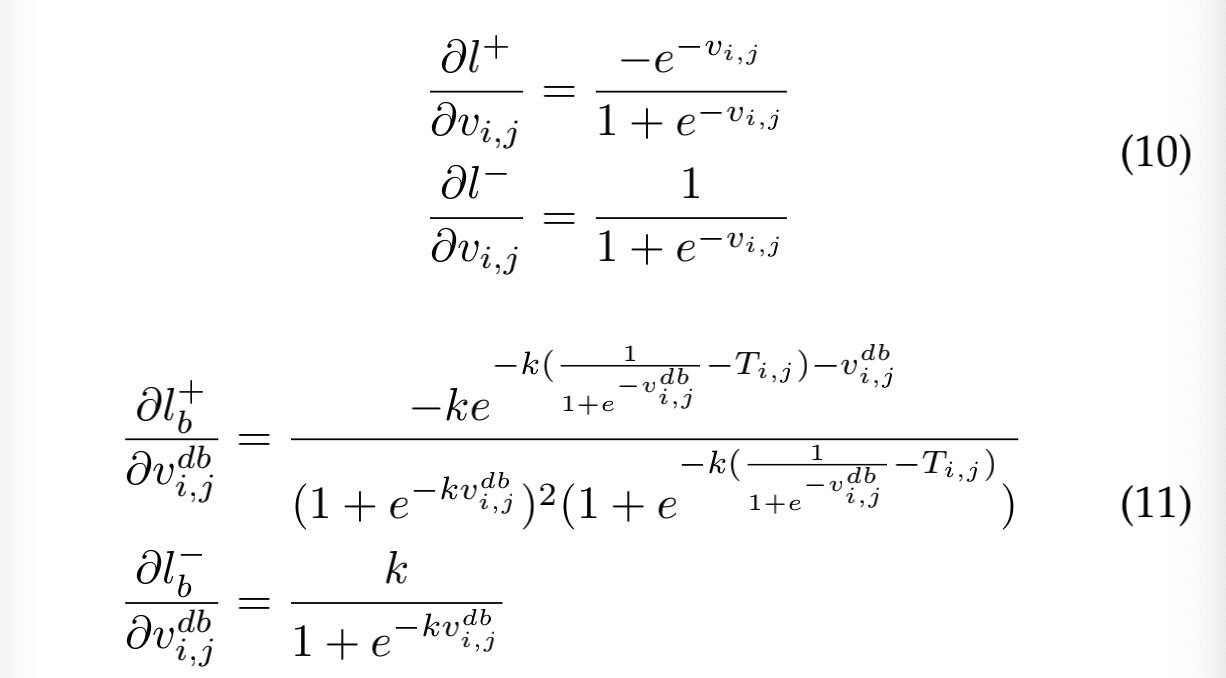
从图 6 可以看出,当错误的预测距离边界较近的时候,DB 能够增强梯度反向传播,能够让模型更关注于优化那些模棱两可的区域,此外 sigmoid 激活函数能够缓解最低上限和最大下限,DN 能够进一步降低对极值的惩罚。
2.3 Adaptive Threshold
threshold map 是否有监督信号得到的结果如图 7 所示,当有监督信号的时候,就有高亮清洗的文本边界,这说明 border-like threshold map 有利于最终的结果。所以,作者给 threshold map 施加了 border-like 监督信号,然后用 threshold map 来二值化分割结果。

2.4 Deformable Convolution
为了覆盖到更多的 aspect ratio,作者在 res-18 和 res-50 的 conv3、conv4、conv5 中使用了 3x3 的可变形卷积。
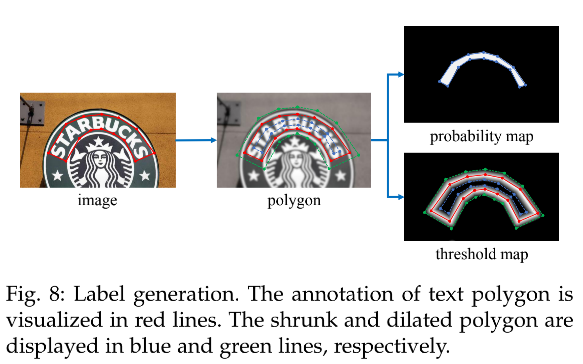
2.5 Label Generation
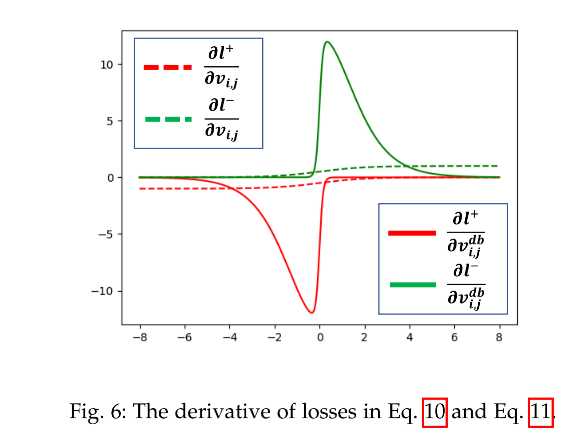
Label generation 的方法和 PSENet 中一样,给定图像,每个 polygon 区域都被描述为一个分割区域集合:
- n 是顶点的数量,不同数据集中是不同的,ICDAR 2015 中是 4,CTW1500 中是 16
为分割 Label 生成 positive area:
- 使用 Vatti clipping algorithm [47] 来将 polygon G G G 收缩为 G s G_s Gs
- 收缩的 offset D D D 是从原始 polygon 的边长 L L L 和面积 A A A 通过如下方式得到的: D = A ( 1 − r 2 ) L D=\frac{A(1-r^2)}{L} D=LA(1−r2), r r r 是收拾比例,设定为 0.4
为 threshold map 生成 Label:
- 首先,将 polygon G G G 膨胀为 G d G_d Gd
- 然后,计算 G 中距离分割区域最近的距离来生成。因为作者认为 G s G_s Gs 和 G d G_d Gd 的 gap 是文本区域的边界区域,所以 threshold map 的 label 可以通过计算 G 中距离分割区域最近的距离来得到。
2.6 Optimization
训练 loss:
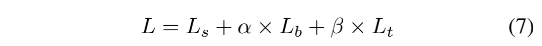
- L s L_s Ls:probability map 的 loss
- L b L_b Lb:binary map 的 loss
- L t L_t Lt:threshold map 的 loss
- α = 1 \alpha = 1 α=1, γ = 10 \gamma=10 γ=10
1、 L s L_s Ls 和 L b L_b Lb 的 loss 都使用二值交叉熵,为了平衡正负样本,使用了难例挖掘
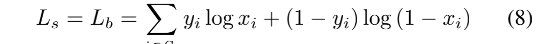
- S l S_l Sl 是正负样本 1:3 的样本集合
2、 L t L_t Lt 是计算了在膨胀文本多边形区域 G d G_d Gd 内的 prediction 和 label 的 L1 距离之和
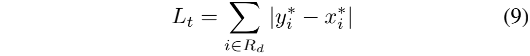
- R d R_d Rd:在膨胀多边形区域 G d G_d Gd 内的像素的索引
- y ∗ y* y∗:threshold map 的 label
推理过程:
推理的时候,可以使用 probability map 或 approximate binary map 来生成 text bounding boxes,两者生成的很接近。为了高效,作者使用 probability map 来生成,所以 threshold map 就可以舍弃了。
box 生成包含 3 步:
- probability map 首先使用 0.2 的阈值进行二值化
- 从二值图中得到连接的区域(收缩 text 区域的方式来实现)
- 使用 offset D ′ D' D′ 来进行收缩区域的膨胀, D ′ = A ′ × r ′ L ′ D' = \frac{A' \times r'}{L'} D′=L′A′×r′,其中, A ′ A' A′ 是收缩后多边形的面积, L ′ L' L′ 是收缩后多边形的周长, r ′ = 1.5 r'=1.5 r′=1.5
三、效果

1、可变形卷积、ASF 模块、DB 模块分别带了的效果提升
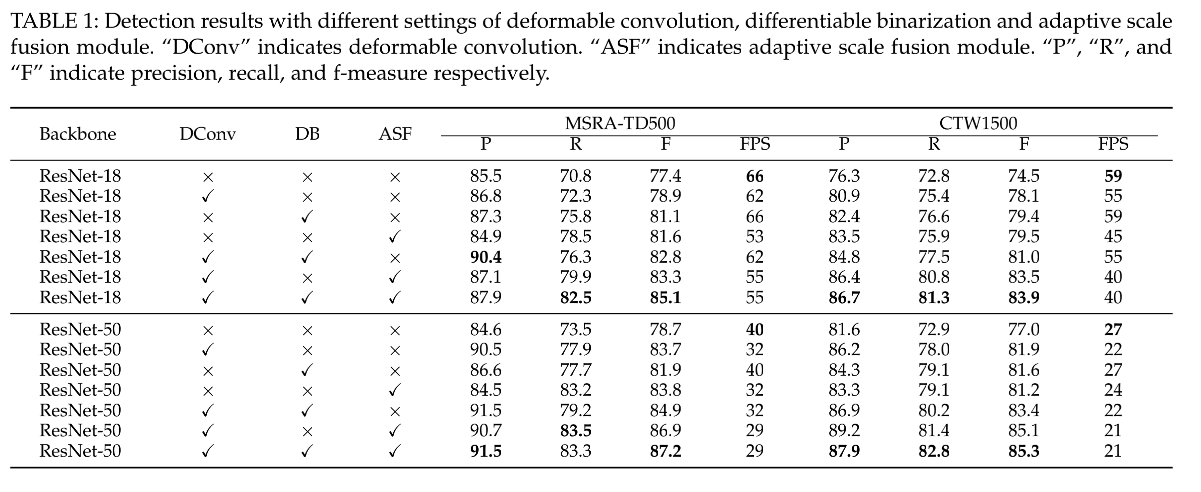
2、ASF 的提升:ASF 中的 spatial attention 在 MSRA-TD500 提升 0.5%,在 CTW1500 提升 1%

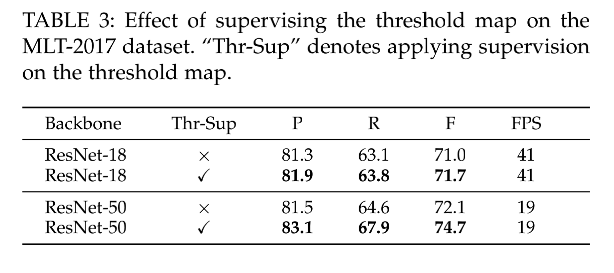
3、对 Threshold map 监督的效果,在 MLT-2017 上,res-18 提升了 0.7%,res-50 提升了 2.6%
4、ASF 和 PPM [64] 及CCA [20] 的对比

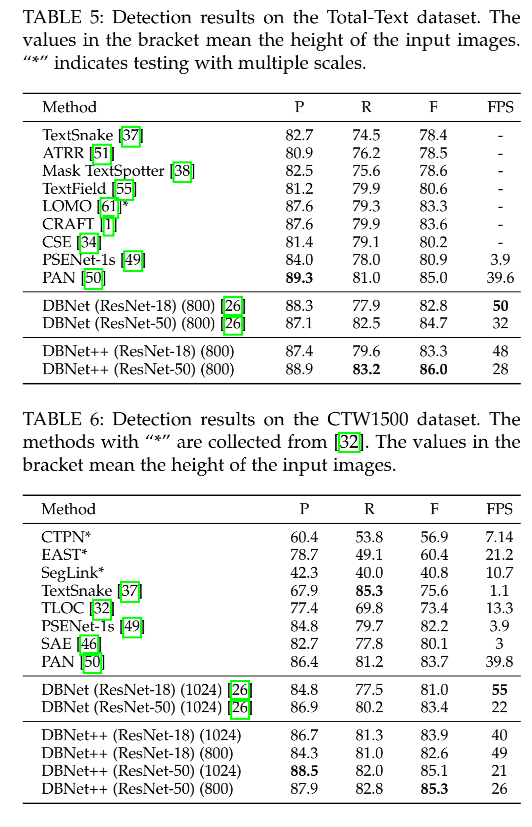
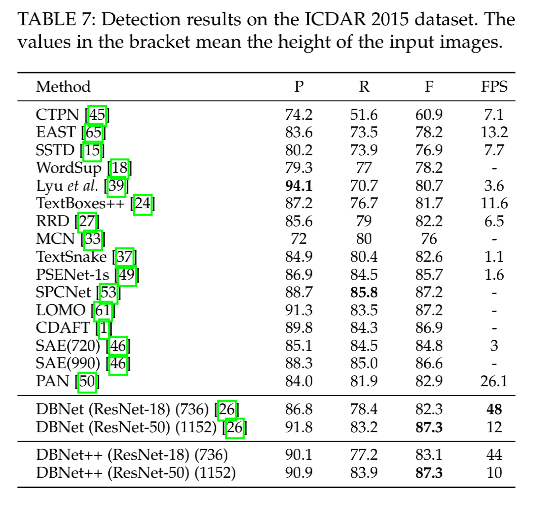
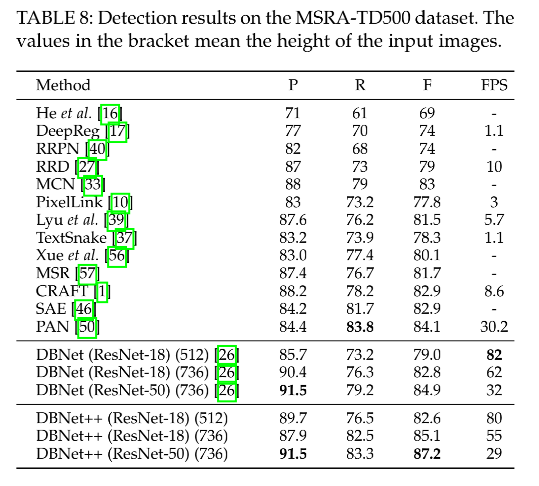
5、和其他方法的对比
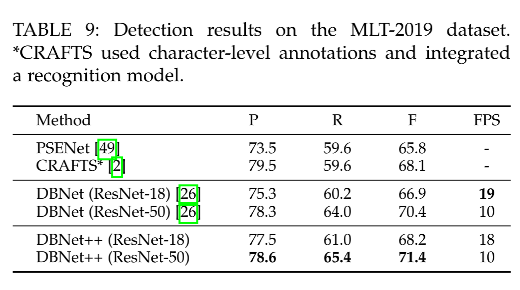
6、和 DBNet 的对比
定量分析:在 res-18 和 res-50 中带来的 F-measure 的提升
- Total-Text:0.5%、1.3%
- CTW1500:2.9%、1.9%
- ICDAR 2015:0.8%、0.0%
- MSRA-TD500:3.6%、2.3%
- MLT-2019:1.3%、1.0%
定性分析:
DBNet++ 有更强的尺度鲁棒能力,尤其对大尺度的文本目标更鲁棒,而 DBNet 出现了一些误检,如图 10。



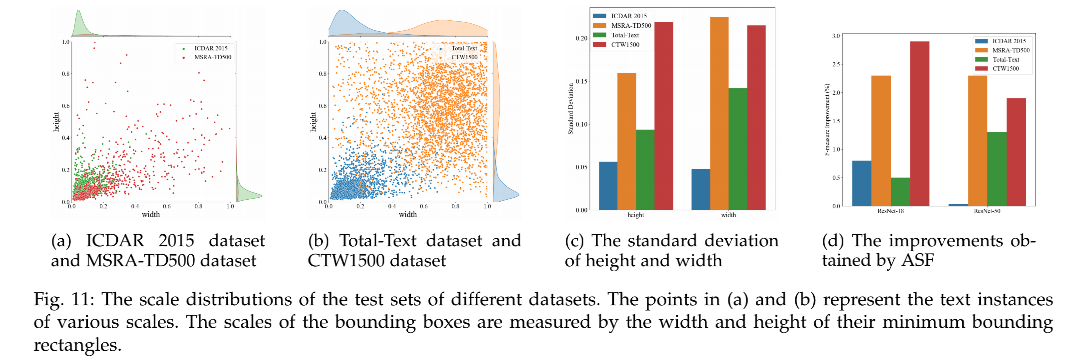
不同数据集的尺度多样性分析:
- ICDAR 2015 和 TotalText 数据集没有 MSRA-TD500 和 CTW1500 数据集中数据的尺度丰富
- 从图 11c 和 图 11d 中也能看出,数据尺度越丰富,ASF 带来的提升就越大,这也证明了 DBNet++ 带来的尺度鲁棒性能的提升
DBNet++ 的限制性:
- 对于 text in text 的情况,难以处理
- 这也是 segmentation-based 方法的局限性