我们上篇文章(高并发内存池(上))介绍了向高并发内存池申请资源的整个过程,本篇文章我们将会对申请后的空间资源释放的整个流程。同时也会对我们自己实现的内存池进行性能测试和优化。
文章目录
一、thread cache 回收资源
二、central cache 回收资源
三、page cache 回收资源
四、大于256KB的空间申请与释放
4、1 大于256KB空间的申请
4、2 大于256KB空间的释放
五、引入定长内存池进行优化
六、释放时的参数优化
七、多线程环境下性能测试
八、采用基数树代替unordered_map
🙋♂️ 作者:@Ggggggtm 🙋♂️
👀 专栏:实战项目 👀
💥 标题:高并发内存池💥
❣️ 寄语:与其忙着诉苦,不如低头赶路,奋路前行,终将遇到一番好风景 ❣️
一、thread cache 回收资源
thread cache 只能处理申请对象的大小需要小于等于256KB。当然,thread cache 也只能处理回收小于等于256KB的对象。这里提问:假设我们申请的对象不再使用,需要对其进行释放,那么是还给了操作系统吗? 并不是还给操作系统,而是还给了thread cache对应的哈希桶所挂的_freeList。
对象释放的思路也很简单:当释放内存小于256k时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push 到_freeLists[i]。我们直接看代码实现:
void ThreadCache::Deallocate(void* ptr, size_t size) { assert(ptr); assert(size <= MAX_BYTES); // 找到对应的桶位置进行头插 size_t index = SizeClass::Index(size); _freeLists[index].Push(ptr); }只考虑把对象插回对应的自由链表就结束了吗?有没有这样一种情况:前期某一个线程申请了很多空间资源,现在基本上有很多都需要释放,那么thread cache 某个桶下会不会占有过多资源呢?答案是会的!当某一个线程的thread cache一个桶下占有过多资源是不是也是一种浪费呢?是的!应该把他们还给central cache,以便后面给其他线程使用。
怎么判断thread cache某个桶当中自由链表长度过长呢?当thread cache某个桶当中自由链表的长度超过它一次批量向central cache申请的对象个数,此时我们就认为它的自由链表长度是过长的!需要把该自由链表当中的这些对象还给central cache。具体实现代码如下:
void ThreadCache::Deallocate(void* ptr, size_t size) { assert(ptr); assert(size <= MAX_BYTES); // 找到对应的桶位置进行头插 size_t index = SizeClass::Index(size); _freeLists[index].Push(ptr); // 当链表长度大于一次批量申请的内存时就开始还一段list给central cache if (_freeLists[index].Size() > _freeLists[index].MaxSize()) { ListTooLong(_freeLists[index], size); } } void ThreadCache::ListTooLong(FreeList& list, size_t size) { void* start = nullptr; void* end = nullptr; list.PopRange(start, end, list.MaxSize()); CentralCache::GetInstance()->ReleaseListToSpans(start, size); }为了很好的获取thread cache中的自由链表下的对象的个数,我们在FreeList中还维护了一个_size的变量,用来统计自由链表下的对象的个数。同时,上述的PopRange就是删除自由链表的一段节点。由于还需要将这段节点还回给central cache 中,所以我们在头插一段时需要两个输出型参数具体实现代码如下:
class FreeList { public: void Push(void* obj) { assert(obj); // 头插 //*(void**)obj = _freeList; NextObj(obj) = _freeList; _freeList = obj; ++_size; } void* Pop() { assert(_freeList); // 头删 void* obj = _freeList; _freeList = NextObj(obj); --_size; return obj; } bool Empty() { return _freeList == nullptr; } void PushRange(void* start, void* end,size_t n) { NextObj(end) = _freeList; _freeList = start; _size += n; } void PopRange(void*& start, void*& end, size_t n) { assert(n <= _size); start = _freeList; end = start; for (size_t i = 0; i < n - 1; ++i) { end = NextObj(end); } _freeList = NextObj(end); NextObj(end) = nullptr; _size -= n; } size_t& MaxSize() { return _maxSize; } size_t Size() { return _size; } private: void* _freeList = nullptr; size_t _maxSize = 1; //用于慢增长部分 size_t _size = 0; };当我们时刻维护着_freeList中的对象的个数时,需要的时候不用遍历去查找,直接获取就行。
我们这里是当thread cache的某个自由链表过长时,我们实际就是把这个自由链表当中全部的对象都还给central cache了。实际上也并没有完全还回去,因为我们还留了一个可申请空间(个人感觉有点少),其次是可能还回有一部分资源并没有释放回来。当然,我们这里也是可以通过PopRange()函数进行控制删除的个数。
二、central cache 回收资源
当我们把一部分对象从thread cache中还给central cache时,也就是使用的下面的接口:
CentralCache::GetInstance()->ReleaseListToSpans(start, size);有的同学就会有所疑问:问什么只传一个start的指针,不用end指针吗?答案是不用的。因为我们在PopRange中已经将最后一个元素指向的下一个空间为nullptr了。所以只需要从开始遍历到nullptr结束就可以。
上篇文章我们也提到了在对page cache进行加锁时,是需要释放掉对应的central cache中的桶锁。这时候就体现出释放桶锁的用处了。因为我们可能还回向central cache中还回空间,并不只是在向central cache申请空间。 因为在向central cache还回空间时,也是需要加锁的。因为可能不仅仅只有一个线程在向central cache进行还回空间。
提问:在向central cache还回空间时,还回给对应的SpanList下的任何一个span都可以吗? 答案是不可以的!你可以先思考一下原因。
因为central cache中的空间资源都是向page cache申请的(这段空间是连续的)。当central cache中的useCount减为0时,说明该span已经完全被还回来了。虽然还回来后是乱序的,但至少可以说明这段空间已经全部还回来了。我们这时就可以将该span还回给page cache,这里可以减少外部的内存碎片,提高整体的内存使用率。
假如我们把一个对象还回给了central cache下SpanList中的任何一个span下,useCount并没有实际意义了,即使对应的useCount减为0,也并不能代表这一段内存已经被完全还回来。这样只会对底层的堆空间造成大量的内存碎片!!!
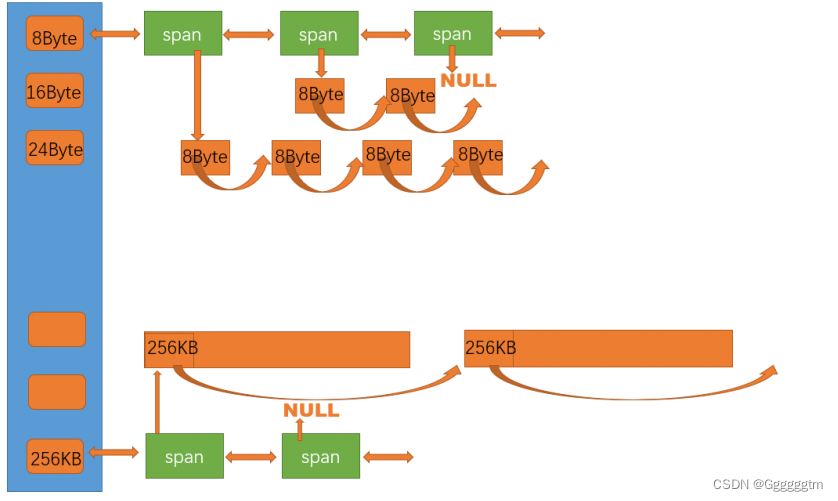
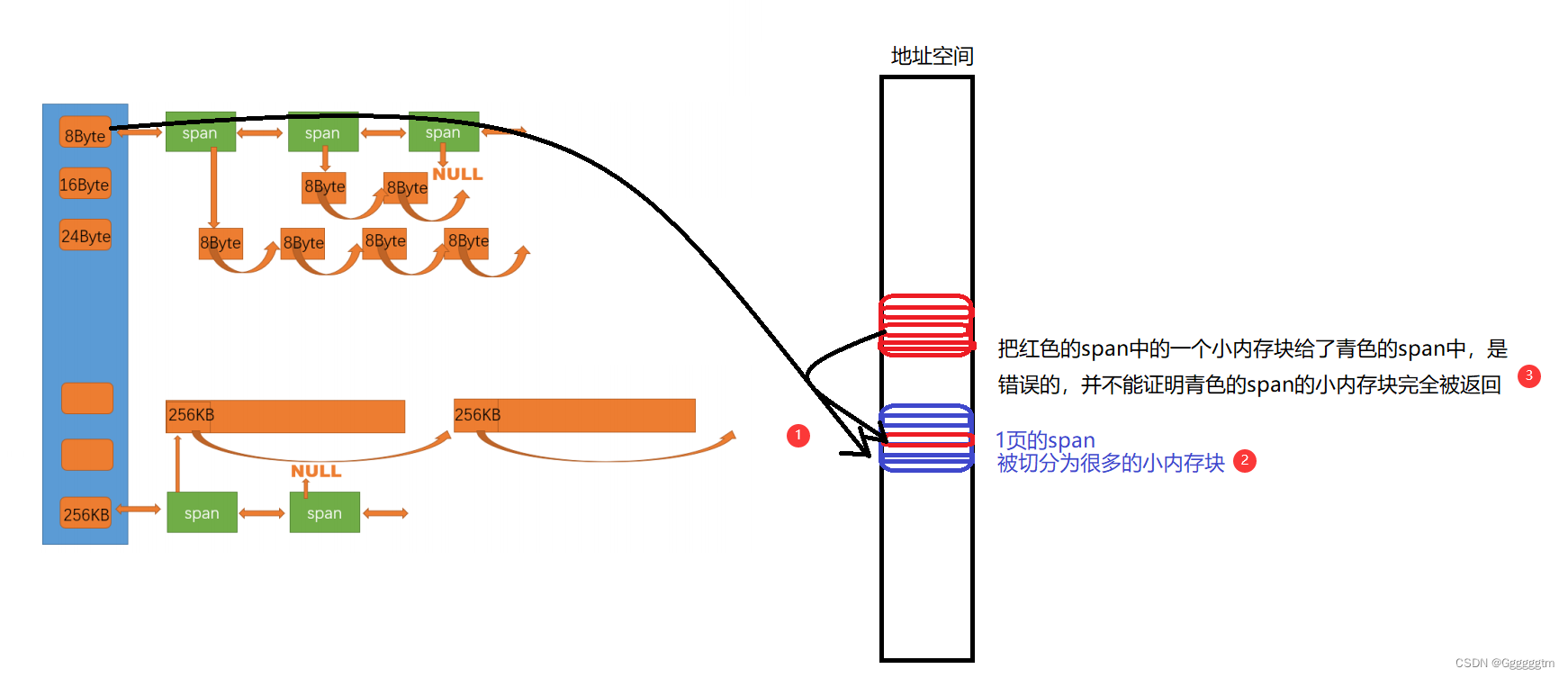
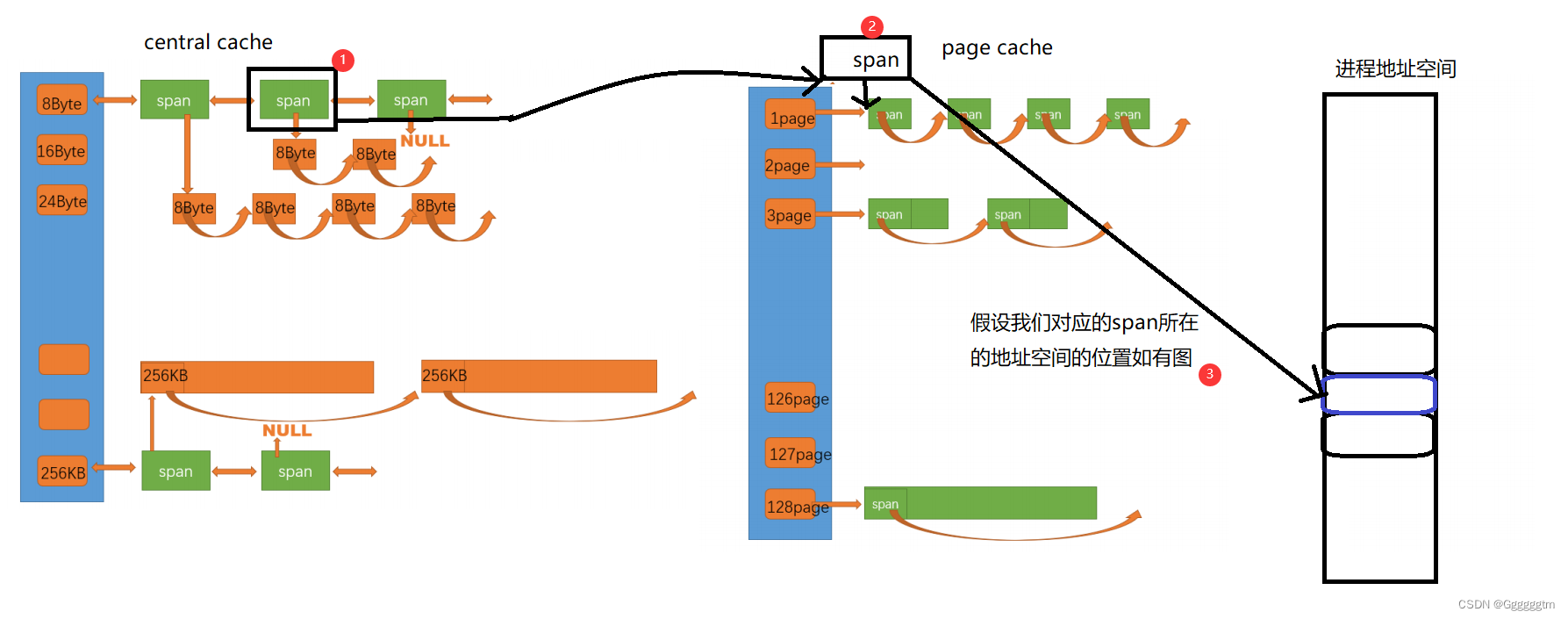
问题来了:怎么找到该小块对象属于那个span呢? 首先我们要清楚的是:某个页当中的所有地址除以页的大小都等于该页的页号。因为我们把余数给省去了。举个例子:我们这里假设一页的大小是100,那么地址0~99都属于第0页,它们除以100都等于0,而地址100~199都属于第1页,它们除以100都等于1。
那么是不是就可以用该对象的地址除以一页的大小,就知道其所在那个页了呢?确实是的。但是我们还需要遍历该SapnList中的每个span,与其span的页号和页数之和进行对比,看是否在该span当中,这样效率就太低了。
为了解决这一问题,我们不如在central cache向page cache申请对应的span时,就建立对应的span的地址与其页号的映射关系,这样当我们知道其页号时也就方便我们后边对span的查找了。
central cache 只有在NewSpan()中是向page cache申请span空间,那我们再来向NewSpan中添加对应的映射关系不就行了!此时大家都会想到用unordered_map来存储他们的映射。我们直接看代码实现:
class PageCache { public: static PageCache* GetInstance() { return &_sInst; } Span* NewSpan(size_t k); Span* MapObjectToSpan(void* obj); // 释放空闲span回到Pagecache,并合并相邻的span void ReleaseSpanToPageCache(Span* span); private: SpanList _spanLists[NPAGES]; std::unordered_map<PAGE_ID, Span*> _idSpanMap; public: std::mutex _pageMtx; private: PageCache() {} PageCache(const PageCache&) = delete; static PageCache _sInst; }; Span* PageCache::NewSpan(size_t k) { assert(k > 0); // 先检查第k个桶里面有没有span if (!_spanLists[k].Empty()) { Span* kSpan = _spanLists[k].PopFront(); // 建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kSpan->_n; ++i) { _idSpanMap[kSpan->_pageId + i] = kSpan; } return kSpan; } // 检查一下后面的桶里面有没有span,如果有可以把他它进行切分 for (size_t i = k + 1; i < NPAGES; ++i) { if (!_spanLists[i].Empty()) { Span* nSpan = _spanLists[i].PopFront(); Span* kSpan = new Span; // 在nSpan的头部切一个k页下来 // k页span返回 // nSpan再挂到对应映射的位置 kSpan->_pageId = nSpan->_pageId; kSpan->_n = k; nSpan->_pageId += k; nSpan->_n -= k; _spanLists[nSpan->_n].PushFront(nSpan); // 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时 // 进行的合并查找 _idSpanMap[nSpan->_pageId] = nSpan; _idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan; // 建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kSpan->_n; ++i) { _idSpanMap[kSpan->_pageId + i] = kSpan; } return kSpan; } } }建立好映射后,通过小块对象的地址查找其对应的span就不难了,前面我们也讲述过思路了。这里我们直接看代码:
Span* PageCache::MapObjectToSpan(void* obj) { std::unique_lock<std::mutex> lock(_pageMtx); auto ret = _idSpanMap.find(id); if (ret != _idSpanMap.end()) { return ret->second; } else { assert(false); return nullptr; } }提问:为什么这里在对_idSpanMap读的时候,也就是通过小对象地址找对应的span时还需要加锁呢?unordered_map的底层实现是哈希表,说白了就是一个动态的数组。当我们在读的时候,有没有可能其他的线程同时在向page cache申请span建立映射关系呢?如果在申请span建立映射关系时,也就是在向_idSpanMap中写入,可能就会进行扩容并且重新建立映射关系,这时候会对我们的读产生影响,所以在这里我们是需要进行加锁的。
现在可以通过小对象地址很好的找到其对应的span。当thread cache还回一段小对象到central span 时,我们拿到的是一段小对象的start,这是我们只需要遍历这段空间到nullptr,通过映射关系找到对应的span,插入其_freeList下就可以,不要忘记对_useCount进行减减操作。具体实现代码如下:
void CentralCache::ReleaseListToSpans(void* start, size_t size) { size_t index = SizeClass::Index(size); _spanLists[index]._mtx.lock(); while (start) { void* next = NextObj(start); Span* span = PageCache::GetInstance()->MapObjectToSpan(start); NextObj(start) = span->_freeList; span->_freeList = start; span->_useCount--; if (span->_useCount == 0) { // 把对应的span还回给page cache } start = next; } _spanLists[index]._mtx.unlock(); }注意:将thread cache中的小对象空间还回给central cache中对应的span时,本质上就是在central cache对应的哈希桶下某个span的_freeList进行头插操作(写操作),所以再进行操作之前是需要加对应的桶锁的。
当我们发现_useCount减为0时,表明该span已经全部被还了回来,这时候我们就可以将该span还回给对应的page cache了。为什么要将span还回给对应的page cache呢?就在central cache对应的哈希桶下的SpanList中放着不就行了,以后thread cache需要的话直接向central cache申请不就得了。这里有两个原因:其一是central cache对应的哈希桶下的SpanList中所挂span的个数大概率不止一个,同时很多span完全被返回的可能性很小。所以不用太过担心central cache中的空间资源不足;其二是将对应的span还回给page cache时,page cache可对前后页的span进行合并(后续会讲解),减少内存碎片。
三、page cache 回收资源
当central cache下的某个span已经全部被还了回来时,这时候我们就可以将该span还回给对应的page cache了。需要将span还回给page cache的原因我们已经解释了,下面我们看还回的细节和具体实现。
假设上图central cache中的span已经被完全返回来了,我们现在将其还回给page cache时,是不是就是把该span从central cache的SpanList中拿出来给了page cache对应的SpanList中就可以了。在向page cache还回时,不要忘记了对page cache整体进行加锁。一样的,当我们从central cache中拿出来了该span时,就可以解除central cache对应的桶锁了,当已经还回给了page cache是,我们再加上桶锁去找下一个小对象块对应的 span,最后全部结束时不要忘记释放桶锁。我们先把central cache中的ReleaseListToSpans()函数中的思路补全,具体代码实现如下:
void CentralCache::ReleaseListToSpans(void* start, size_t size) { size_t index = SizeClass::Index(size); _spanLists[index]._mtx.lock(); while (start) { void* next = NextObj(start); Span* span = PageCache::GetInstance()->MapObjectToSpan(start); NextObj(start) = span->_freeList; span->_freeList = start; span->_useCount--; if (span->_useCount == 0) { _spanLists[index].Erase(span); span->_freeList = nullptr; span->_next = nullptr; span->_prev = nullptr; // 释放span给page cache时,使用page cache的锁就可以了 // 这时把桶锁解掉,以便其他线程可申请和释放资源 _spanLists[index]._mtx.unlock(); PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); // 再加上桶锁,去找list的下一个节点对应的 span _spanLists[index]._mtx.lock(); } start = next; } _spanLists[index]._mtx.unlock(); }
具体将span插入到对应的page cache对应哈希桶下的SpanList就比较简单了。插入确实简单,但是不要忘记了我们还需要对该span前后的span进行合并,以避免外部的内存碎片的问题。
如上图所示,在该span被还会之前其上下的两段空间(也就是对应的以页为单位的span)都已经被还回来了,这时候我们就可以将这三者进行合并出一个更大的span放入到page cache对应的spanList中去。这样后面再次申请时就可以申请更大页的span了!不合并的话,都是小页的span,无法很好的申请出一个大页的span。
这里就又有一个问题:你怎么知道相邻的span已经被还回来了或者没有被使用呢?是不是只有我们在central cache中申请获得一个新的span时,就表明该span正在被使用。其他两种情况下的span表明没有被使用:一种就是在page cache层申请一个128页时被切分出来挂在page cache中,另一种就是从central cache中还回来的。此时我们在span结构中添加一个变量,来记录一下该span是否在被使用,具体实现代码如下:
struct Span { PAGE_ID _pageId = 0; // 大块内存起始页的页号 size_t _n = 0; // 页的数量 Span* _next = nullptr; // 双向链表 Span* _prev = nullptr; size_t _useCount = 0; // 大块内存切好的小块内存已经被分配的数量 void* _freeList = nullptr; // 切好的小块内存的自由链表 bool _isUse = false; // 是否正在被使用 };那么在central cache中获取span(NewSpan)时,修改一下状态就可以,代码如下:
Span* CentralCache::GetOneSpan(SpanList& list,size_t size) { Span* begin = list.Begin(); while (begin != list.End()) { if (begin->_freeList != nullptr) { return begin; } else { begin = begin->_next; } } // 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞 list._mtx.unlock(); // 走到这里说没有空闲span了,只能找page cache要 PageCache::GetInstance()->_pageMtx.lock(); Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size)); span->_isUse = true; PageCache::GetInstance()->_pageMtx.unlock(); char* start = (char*)(span->_pageId << PAGE_SHIFT); // 该span的起始地址 size_t bytes = span->_n << PAGE_SHIFT; // 该span的大小 char* end = start + bytes; //把申请大块内存的span切分成对应小块内存(尾插进_freeList),再连入SpanList中 span->_freeList = start; start += size; void* tail = span->_freeList; while (start < end) { NextObj(tail) = start; tail = NextObj(tail); start += size; } NextObj(tail) = nullptr; // 切好span以后,需要把span挂到桶里面去的时候,再加锁 list._mtx.lock(); list.PushFront(span); return span; }
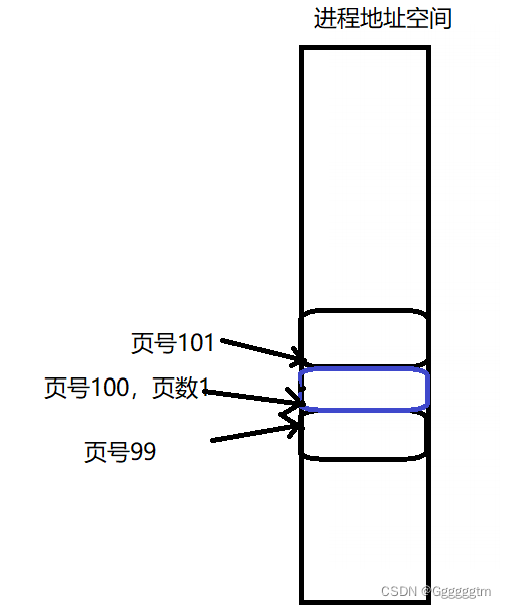
在合并时,我们分为向前合并和向后合并两个步骤。具体如下图:
我们通过页号,就可以找到对应的span,那么其页数我们也就知道了。向前合并或者向后合并时,只要能合并就会一直合并下去。什么时候不能合并呢?
- 拿到页号时,在对应的_idSpanMap中没有找到对应的映射关系时(说明该控件并不是我们所申请的空间,不能越界访问),不要合并;
- 当该span在被使用时,肯定不能将其进行合并;
- span合并后的页数大于128时,就不能合并,因为我们能够存储最大页的span就是128(可自行设置上限)。
我们再来看一下central cache还给page cache时,合并后我们在进行插入。在合并时,应该同步更新_idSpanMap的映射关系。具体实现代码如下:
void PageCache::ReleaseSpanToPageCache(Span* span) { // 对span前后的页,尝试进行合并,缓解内存碎片问题 while (1) { PAGE_ID prevId = span->_pageId - 1; auto ret = _idSpanMap.find(prevId); 前面的页号没有,不合并了 if (ret == _idSpanMap.end()) { break; } // 前面相邻页的span在使用,不合并了 Span* prevSpan = ret; if (prevSpan->_isUse == true) { break; } // 合并出超过128页的span没办法管理,不合并了 if (prevSpan->_n + span->_n > NPAGES - 1) { break; } span->_pageId = prevSpan->_pageId; span->_n += prevSpan->_n; _spanLists[prevSpan->_n].Erase(prevSpan); delete prevSpan; } // 向后合并 while (1) { PAGE_ID nextId = span->_pageId + span->_n; /*auto ret = _idSpanMap.find(nextId); if (ret == _idSpanMap.end()) { break; }*/ auto ret = (Span*)_idSpanMap.get(nextId); if (ret == nullptr) { break; } Span* nextSpan = ret; if (nextSpan->_isUse == true) { break; } if (nextSpan->_n + span->_n > NPAGES - 1) { break; } span->_n += nextSpan->_n; _spanLists[nextSpan->_n].Erase(nextSpan); delete nextSpan; } _spanLists[span->_n].PushFront(span); span->_isUse = false; _idSpanMap[span->_pageId] = span; _idSpanMap[span->_pageId+span->_n-1] = span; }
四、大于256KB的空间申请与释放
4、1 大于256KB空间的申请
我们从开始到现在还没有详细解释怎么处理大于256KB的空间申请与释放。最开始我们就解释道:每个线程的thread cache是用于申请小于等于256KB的内存的。而对于大于256KB的内存,我们直接向page cache申请。
我们首先要做的就是对申请对象的大小进行以页为对齐数进行对齐,看起到底需要几页的大小。大于256KB的话最少也是33页(256KB / 8KB = 32)。page cache中最大的页也就只有128页(也就是128*8KB = 1024KB)的大小。如果申请对象的大小大于1024KB(128页),也就只能直接向堆申请了。如果在33~128页之间的话,正常的去page cache的哈希桶对应的SpanList中申请就行。在申请的同时,也不要忘记了加锁!具体实现代码如下:
//大于256KB的直接去PageCache上申请 if (size > MAX_BYTES) { size_t alignSize = SizeClass::RoundUp(size); size_t kPage = alignSize >> PAGE_SHIFT; PageCache::GetInstance()->_pageMtx.lock(); Span* span = PageCache::GetInstance()->NewSpan(kPage); PageCache::GetInstance()->_pageMtx.unlock(); void* ptr = (void*)(span->_pageId << PAGE_SHIFT); return ptr; }Span* PageCache::NewSpan(size_t k) { assert(k > 0); // 大于128 page的直接向堆申请 if (k > NPAGES - 1) { void* ptr = SystemAlloc(k); //Span* span = new Span; Span* span = _spanPool.New(); span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT; span->_n = k; //_idSpanMap[span->_pageId] = span; _idSpanMap.set(span->_pageId, span); return span; } //…… }
4、2 大于256KB空间的释放
同样,如果释放的空间大小大于256KB,我们直选择释放给page cache。如果对象过大,大于128页的span,那么就选择直接释放给堆空间。具体实现代码如下:
if (size > MAX_BYTES) //大于256KB的内存释放 { Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr); PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); } else { assert(pTLSThreadCache); pTLSThreadCache->Deallocate(ptr, size); } 、// 大于128 page的直接还给堆 if (span->_n > NPAGES - 1) { void* ptr = (void*)(span->_pageId << PAGE_SHIFT); // 系统调用 SystemFree(ptr); delete span; return; }
上述的SystemFree是堆系统调用进行了封装,通过系统调用直接把对象空间还给堆。具体实现代码如下:
inline static void SystemFree(void* ptr) { #ifdef _WIN32 VirtualFree(ptr, 0, MEM_RELEASE); #else // sbrk unmmap等 #endif }
这里说明一下:为了在最开始更好的获取每个线程的TLS对象和申请释放空间,我们这里对申请和释放进行的封装。具体实现代码如下:
static void* ConcurrentAlloc(size_t size) { //大于256KB的直接去PageCache上申请 if (size > MAX_BYTES) { size_t alignSize = SizeClass::RoundUp(size); size_t kPage = alignSize >> PAGE_SHIFT; PageCache::GetInstance()->_pageMtx.lock(); Span* span = PageCache::GetInstance()->NewSpan(kPage); PageCache::GetInstance()->_pageMtx.unlock(); void* ptr = (void*)(span->_pageId << PAGE_SHIFT); return ptr; } else { if (pTLSThreadCache == nullptr) { static ObjectPool<ThreadCache> tcPool; pTLSThreadCache = new ThreadCache; } //cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl; return pTLSThreadCache->Allocate(size); } } static void ConcurrentFree(void* ptr,size_t size) { Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr); if (size > MAX_BYTES) { PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); } else { assert(pTLSThreadCache); pTLSThreadCache->Deallocate(ptr, size); } }
五、引入定长内存池进行优化
不要忘记了,我们所做的就是一个内存池,且以后在多线程的环境下是需要代替malloc的所以应该避免使用malloc和free。当然,new的底层也是调用的malloc,也不可以被使用。
不要忘记了在最开始我们自己实现了一个定长内存池,而我们的span对象不就是一个定长的吗!!!这时候就可以引入我们之前实现的定长内存池了。我们只需要在所有使用new的地方进行替换就可以了。其中较集中使用new的地方就是申请span的时候,下面我们一一将他们进行替换,具体代码如下:
class PageCache { // …… private: ObjectPool<Span> _spanPool; }; Span* PageCache::NewSpan(size_t k) { assert(k > 0); // 大于128 page的直接向堆申请 if (k > NPAGES - 1) { //Span* span = new Span; Span* span = _spanPool.New(); return span; } // 检查一下后面的桶里面有没有span,如果有可以把他它进行切分 for (size_t i = k + 1; i < NPAGES; ++i) { if (!_spanLists[i].Empty()) { Span* nSpan = _spanLists[i].PopFront(); //Span* kSpan = new Span; return kSpan; } } // 走到这个位置就说明后面没有大页的span了 // 这时就去找堆要一个128页的span //Span* bigSpan = new Span; Span* bigSpan = _spanPool.New(); return NewSpan(k); } void PageCache::ReleaseSpanToPageCache(Span* span) { // 大于128 page的直接还给堆 if (span->_n > NPAGES - 1) { //delete span; _spanPool.Delete(span); return; } // 对span前后的页,尝试进行合并,缓解内存碎片问题 while (1) { //delete prevSpan; _spanPool.Delete(prevSpan); } // 向后合并 while (1) { //delete nextSpan; _spanPool.Delete(nextSpan); } }还有就是当每个线程第一次申请内存时都会创建其专属的thread cache,而这个thread cache目前也是new出来的,我们也需要对其进行替换。具体实现如下:
static void* ConcurrentAlloc(size_t size) { //大于256KB的直接去PageCache上申请 } else { if (pTLSThreadCache == nullptr) { static ObjectPool<ThreadCache> tcPool; //pTLSThreadCache = new ThreadCache; pTLSThreadCache = tcPool.New(); } }最后就是在SpanList结构的构造函数中,具体修改后代码如下:
class SpanList { public: SpanList() { _head = _spanPool.New(); } private: Span* _head; static ObjectPool<Span> _spanPool; };
同时不要忘记了,申请时使用的是定长内存池,释放时也就不能再用delete了,应该使用定长内存池提供的Delete()。这里就不再一一列举了,大家可根据使用定长内存池new的地方找出对应的delete进行替换。
六、释放时的参数优化
我们现在正常调用申请和释放的代码如下:
void TestAlloc() { void* ptr = ConcurrentAlloc(7); ConcurrentFree(ptr, 7); }在释放对象时,必须知道对象的大小才能进行释放。因为只有知道对象的大小,才能找到在thread cache中的映射到了那个哈希桶。但是正常情况下我们在释放时都是不用传入所释放对象的大小的。如果不传入释放对象的大小,有应该怎么进行设计呢?现在我们只知道所释放对象的指针(地址)。那么在span中记录该span下_freeList的对象的大小就可以了!我们可通过对象的指针(地址)找到对应的span,进而获取大小。
只需要在获取span时对记录span下的_freeList对象大小进行初始化。对应到的就是我们在central cache中向page cache申请新的span后,需要对span进行切分挂到对应的_freeList中。我们在这时候记录下所对应的span下的小块对象大小就可以了!注意,该大小是对齐后的大小!具体实现代码如下:
struct Span { PAGE_ID _pageId = 0; // 大块内存起始页的页号 size_t _n = 0; // 页的数量 Span* _next = nullptr; // 双向链表 Span* _prev = nullptr; size_t _useCount = 0; // 大块内存切好的小块内存已经被分配的数量 void* _freeList = nullptr; // 切好的小块内存的自由链表 bool _isUse = false; // 是否正在被使用 size_t _objSize = 0; // _freeList中对象的大小 };Span* CentralCache::GetOneSpan(SpanList& list,size_t size) { // …… Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size)); span->_isUse = true; span->_objSize = size; PageCache::GetInstance()->_pageMtx.unlock(); // …… }
那现在我们在释放时不再传对象的大小也是可以的,具体代码如下:
static void ConcurrentFree(void* ptr) { Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr); size_t size = span->_objSize; if (size > MAX_BYTES) { PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); } else { assert(pTLSThreadCache); pTLSThreadCache->Deallocate(ptr, size); } }
七、多线程环境下性能测试
以上即为我们整个高并发内存池的整体实现的思路。接下来我们需要在对线程环境下与malloc进行性能对比测试,看看我们实现的在多线程下的高并发内存池是否比malloc速度要快。下面我们直接给出测试代码:
// ntimes 一轮申请和释放内存的次数 // rounds 轮次 void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds) { std::vector<std::thread> vthread(nworks); std::atomic<size_t> malloc_costtime = 0; std::atomic<size_t> free_costtime = 0; for (size_t k = 0; k < nworks; ++k) { vthread[k] = std::thread([&, k]() { std::vector<void*> v; v.reserve(ntimes); for (size_t j = 0; j < rounds; ++j) { size_t begin1 = clock(); for (size_t i = 0; i < ntimes; i++) { v.push_back(malloc(16)); //v.push_back(malloc((16 + i) % 8192 + 1)); } size_t end1 = clock(); size_t begin2 = clock(); for (size_t i = 0; i < ntimes; i++) { free(v[i]); } size_t end2 = clock(); v.clear(); malloc_costtime += (end1 - begin1); free_costtime += (end2 - begin2); } }); } for (auto& t : vthread) { t.join(); } cout << nworks << " 个线程并发执行 " << rounds << "轮次,每轮次malloc " << ntimes << "次: 花费:" << malloc_costtime << "ms" << endl; cout << nworks << " 个线程并发执行 " << rounds << "轮次,每轮次free " << ntimes << "次: 花费:" << free_costtime << "ms" << endl; cout << nworks << " 个线程并发执行malloc&free " << nworks * rounds * ntimes << "次,总计花费: " << malloc_costtime + free_costtime << "ms" << endl; } void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds) { std::vector<std::thread> vthread(nworks); std::atomic<size_t> malloc_costtime = 0; std::atomic<size_t> free_costtime = 0; for (size_t k = 0; k < nworks; ++k) { vthread[k] = std::thread([&]() { std::vector<void*> v; v.reserve(ntimes); for (size_t j = 0; j < rounds; ++j) { size_t begin1 = clock(); for (size_t i = 0; i < ntimes; i++) { v.push_back(ConcurrentAlloc(16)); //v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1)); } size_t end1 = clock(); size_t begin2 = clock(); for (size_t i = 0; i < ntimes; i++) { ConcurrentFree(v[i]); } size_t end2 = clock(); v.clear(); malloc_costtime += (end1 - begin1); free_costtime += (end2 - begin2); } }); } for (auto& t : vthread) { t.join(); } cout << nworks << " 个线程并发执行 " << rounds << "轮次,每轮次concurrent alloc " << ntimes << "次: 花费:" << malloc_costtime << "ms" << endl; cout << nworks << " 个线程并发执行 " << rounds << "轮次,每轮次concurrent dealloc " << ntimes << "次: 花费:" << free_costtime << "ms" << endl; cout << nworks << " 个线程并发执行concurrent alloc&dealloc " << nworks * rounds * ntimes << "次,总计花费: " << malloc_costtime + free_costtime << "ms" << endl; } int main() { size_t n = 10000; cout << "==========================================================" << endl; BenchmarkConcurrentMalloc(n, 4, 10); cout << endl << endl; BenchmarkMalloc(n, 4, 10); cout << "==========================================================" << endl; return 0; }这段代码是在进行高并发内存池的分配和释放的性能测试。它包含了两函数BenchmarkConcurrentMalloc 和 BenchmarkMalloc,下面我将对这段代码的思路和用途进行详细解释:
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)函数:
- 这个函数用于测试在多线程环境下使用标准的malloc和free函数进行内存分配和释放的性能。
- 参数说明:
- ntimes:每轮次需要执行多少次内存分配和释放操作。
- nworks:并发执行的线程数量。
- rounds:每个线程需要执行的轮次。
- 函数内部:
- 创建了nworks个线程,每个线程执行rounds轮次,每轮次分别执行ntimes次内存分配和释放操作。
- 在每轮次内存分配和释放操作之前,使用clock()函数记录开始时间,操作之后记录结束时间,从而计算出每轮的耗时。
- 最终计算了所有线程的总体耗时,包括内存分配和释放。
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)函数:
- 这个函数用于测试在多线程环境下使用高并发内存池的ConcurrentAaloc和ConcurrentFree函数进行内存分配和释放的性能。
- 这部分代码针对高并发分配和释放内存做了性能测试。
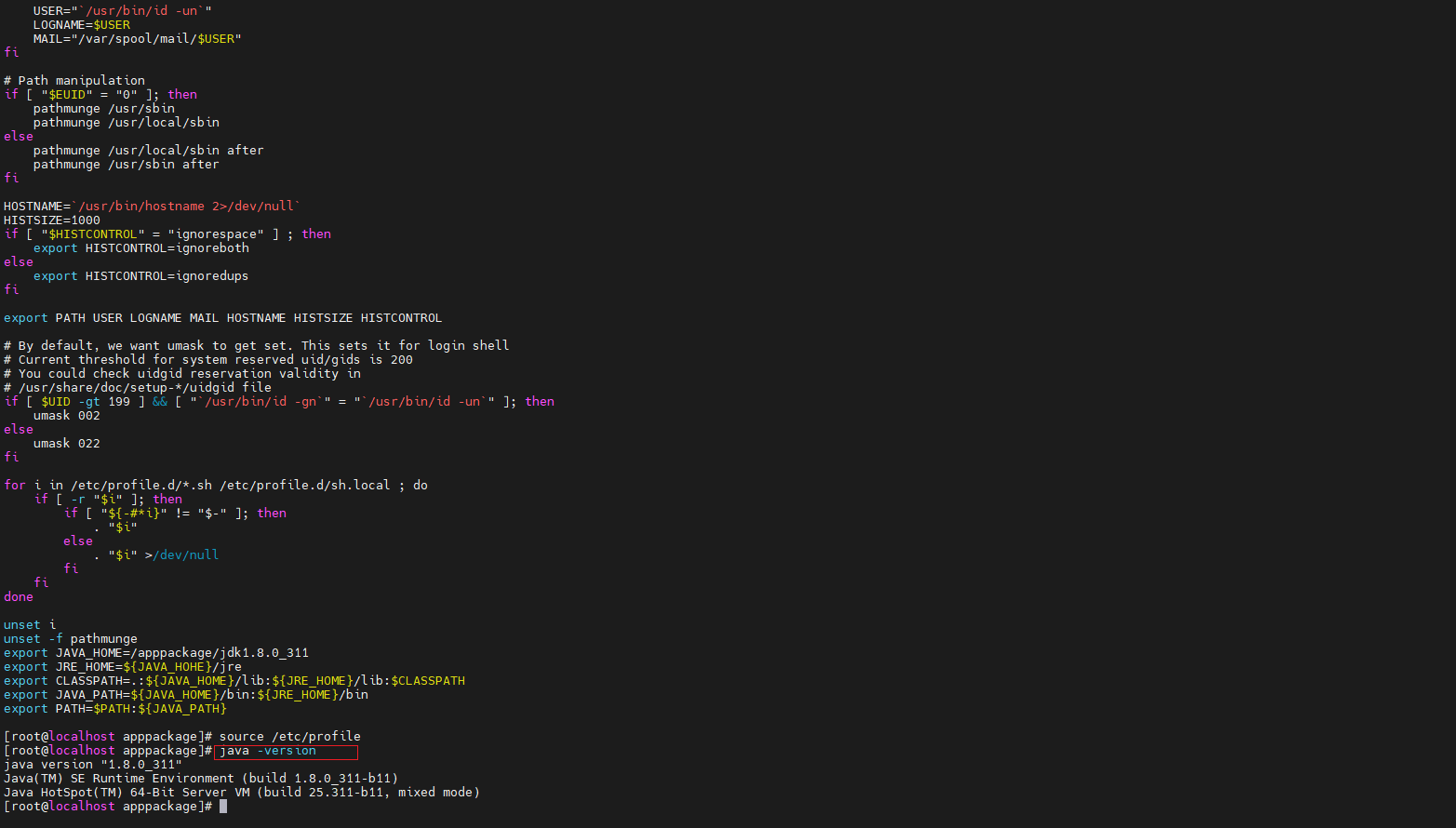
下面我们先来测试debug下均匀的向我们自己设的内存池申请空间,效率如下图:
实际上测试出来的还没有malloc快!我们再来看申请不同大小的速度怎么样:
release下的运行其实也是一样的,也是没有malloc快,运行截图如下:
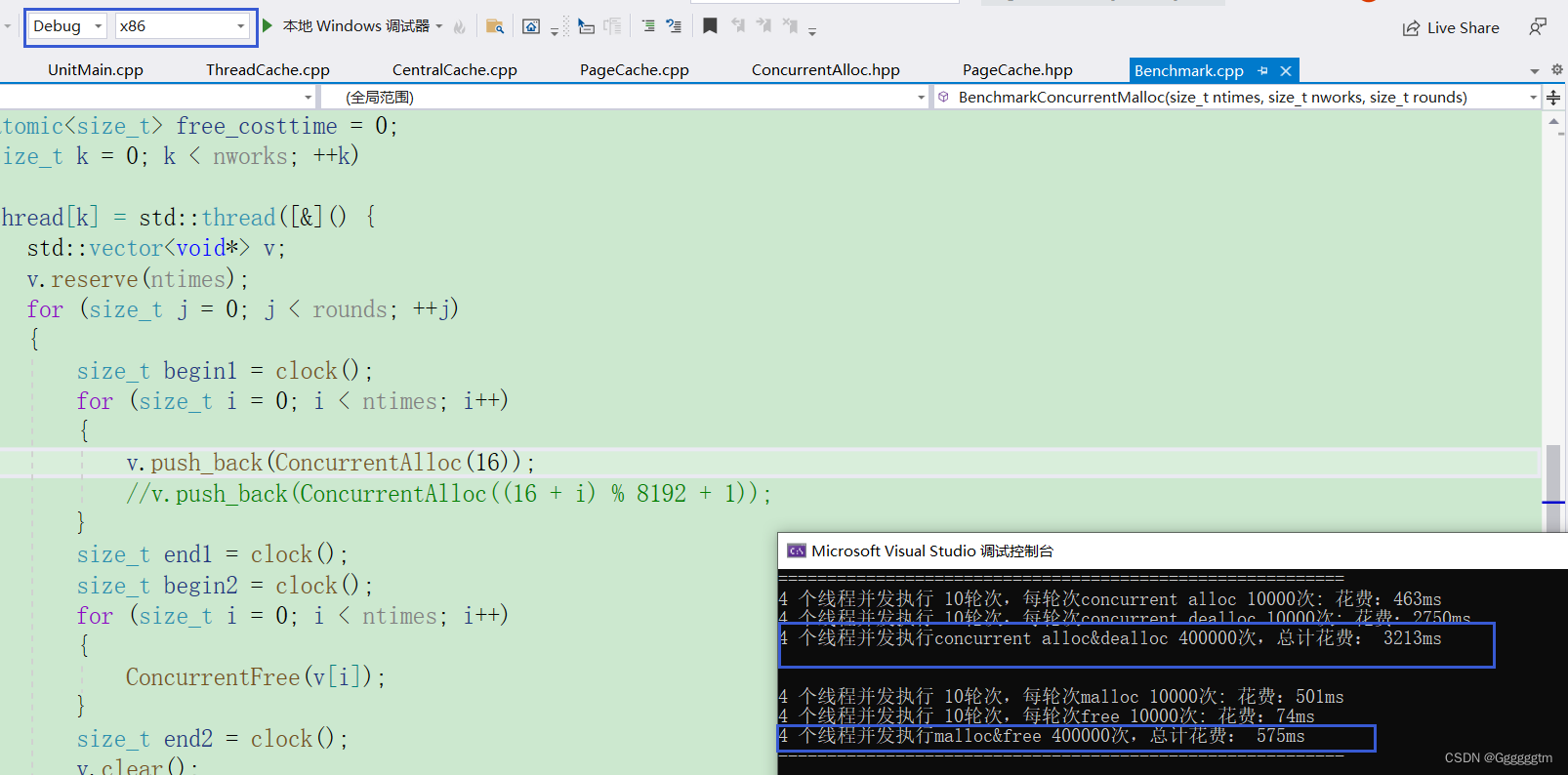

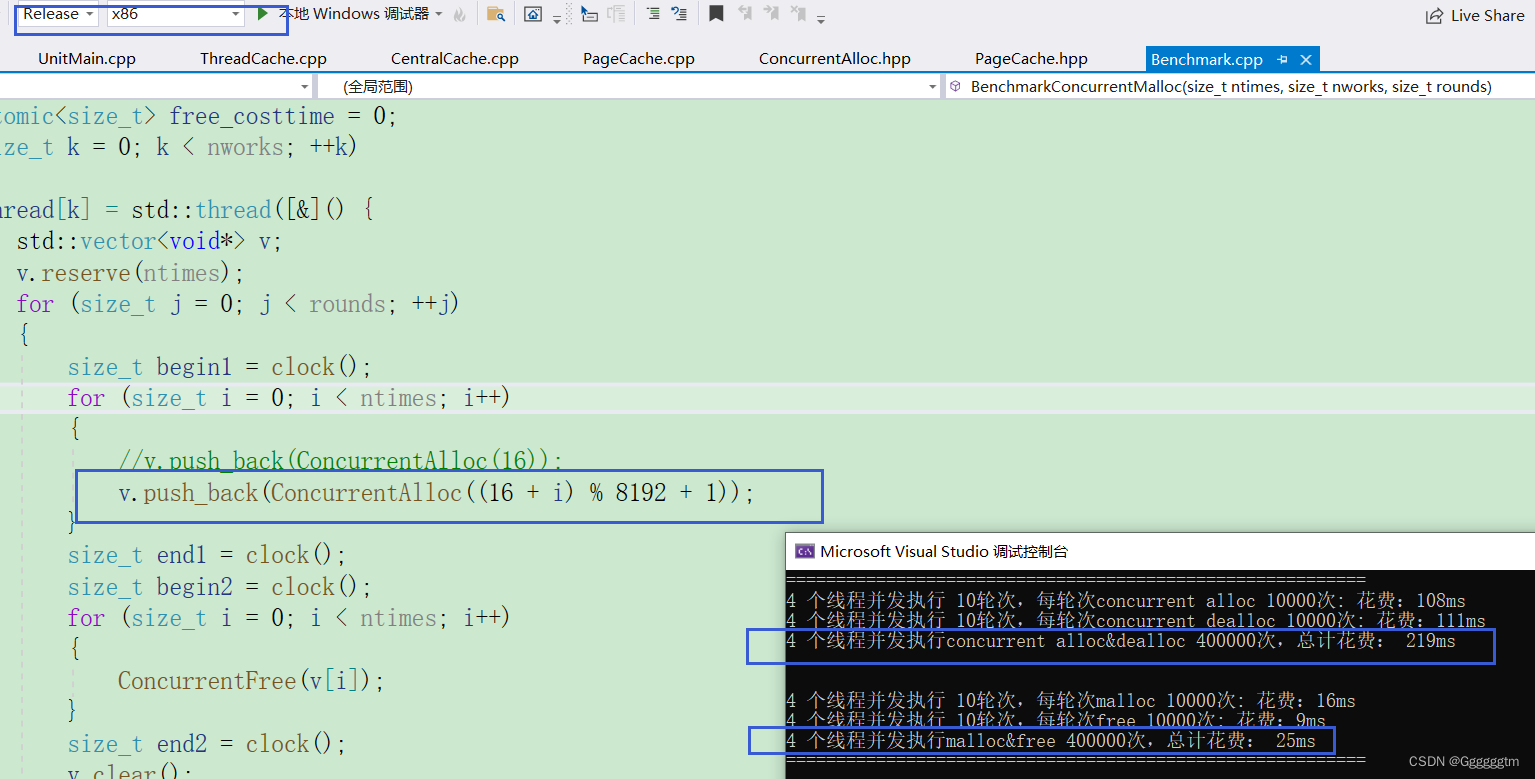
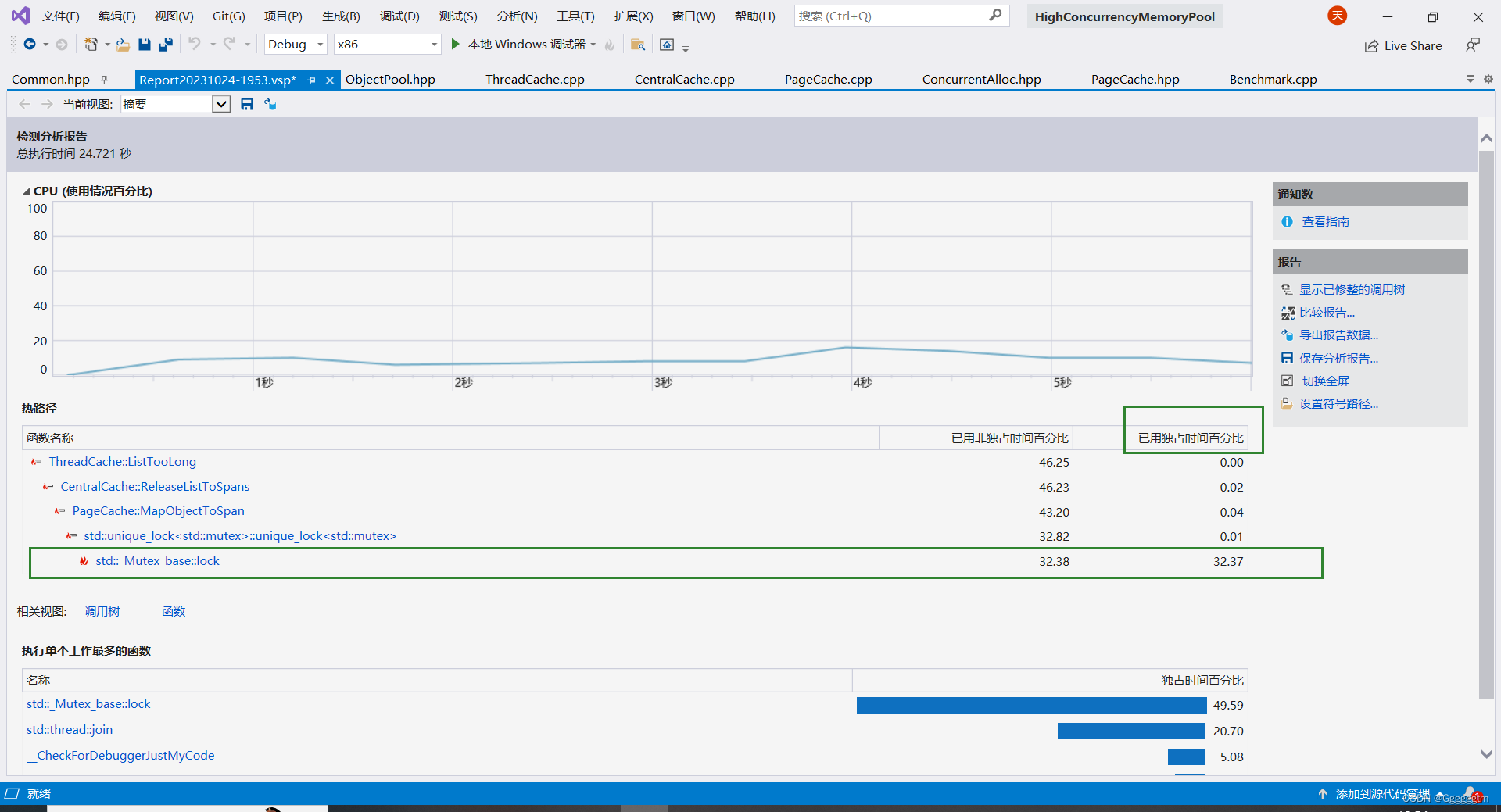
我们发现在多线程情况下设计的并发内存池并没有malloc快,这是为什么呢?不要猜想,直接上vs下自待的性能探测器来进行分析一下。运行分析如下图:
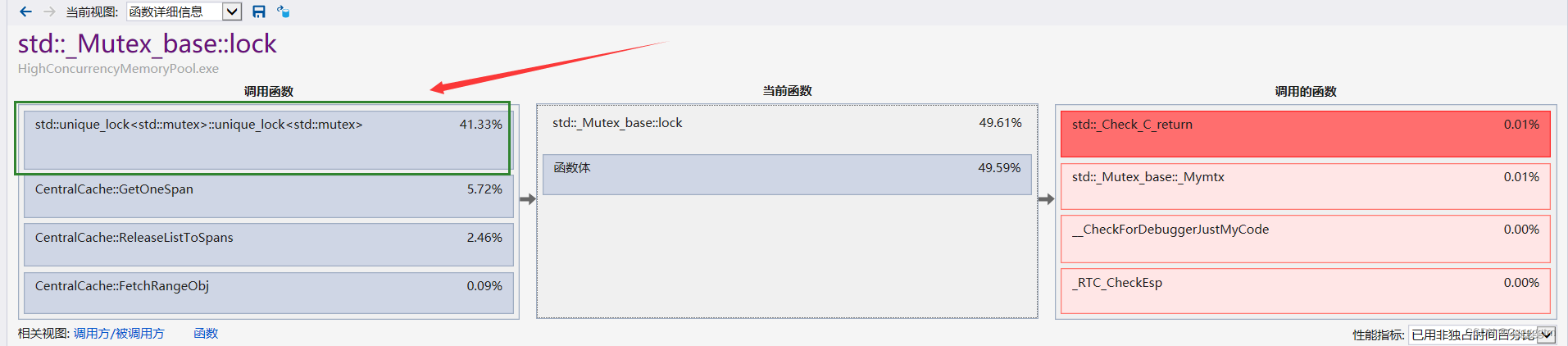
我们发现还是竞争锁资源耗费的时间太多了。我们再接着往下看看到底是哪里的锁:
我们发现是在读取_idMapSpan时加的锁所占用的资源接近了一半!那有什么办法能使这里不在进行加锁吗?采用什么方式进行优化呢?答案是基数树!

八、采用基数树代替unordered_map
再次思考一下:为什么在读取映射的时候需要加锁。 根本原因就在于线程1在读取时,其他线程可能在向_idMapSpan中存取映射关系,进而导致底层扩容。而线程1再次读取时就可能发生数据错误。我们这里底层存储映射关系时,不再采用unordered_map,而是采用基数树来存储。
基数树(Radix Tree)也称为字典树(Trie)或前缀树,是一种用于快速搜索和插入的数据结构。更官方一点的解释:radix tree是一种多叉搜索树。树的叶子结点是实际的数据条目。每一个结点有一个固定的、2^n指针指向子结点(每一个指针称为槽slot,n为划分的基的大小)。
这里不再对基数树进行过多详解。我们这直接看引入后的代码实现:
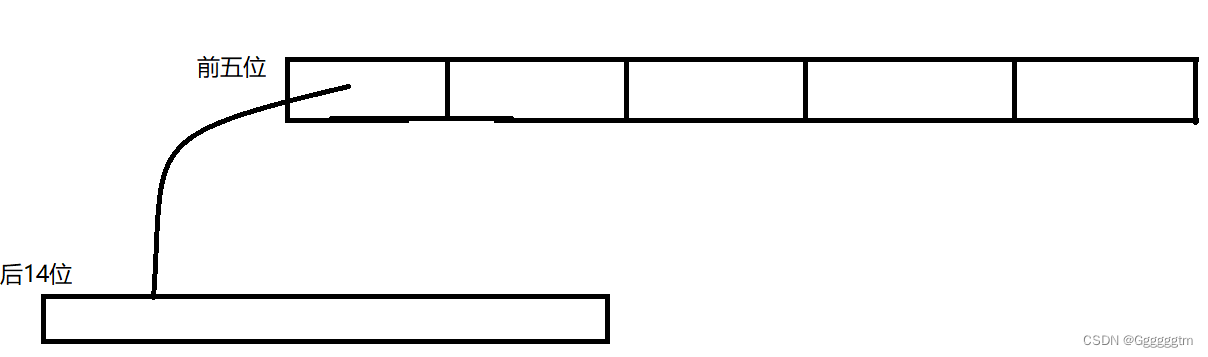
template <int BITS> class TCMalloc_PageMap1 { private: static const int LENGTH = 1 << BITS; void** array_; public: typedef uintptr_t Number; //explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) { explicit TCMalloc_PageMap1() { //array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS)); size_t size = sizeof(void*) << BITS; size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT); array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT); memset(array_, 0, sizeof(void*) << BITS); } // Return the current value for KEY. Returns NULL if not yet set, // or if k is out of range. void* get(Number k) const { if ((k >> BITS) > 0) { return NULL; } return array_[k]; } // REQUIRES "k" is in range "[0,2^BITS-1]". // REQUIRES "k" has been ensured before. // // Sets the value 'v' for key 'k'. void set(Number k, void* v) { array_[k] = v; } }; // Two-level radix tree template <int BITS> class TCMalloc_PageMap2 { private: // Put 32 entries in the root and (2^BITS)/32 entries in each leaf. static const int ROOT_BITS = 5; static const int ROOT_LENGTH = 1 << ROOT_BITS; static const int LEAF_BITS = BITS - ROOT_BITS; static const int LEAF_LENGTH = 1 << LEAF_BITS; // Leaf node struct Leaf { void* values[LEAF_LENGTH]; }; Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes void* (*allocator_)(size_t); // Memory allocator public: typedef uintptr_t Number; //explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) { explicit TCMalloc_PageMap2() { //allocator_ = allocator; memset(root_, 0, sizeof(root_)); PreallocateMoreMemory(); } void* get(Number k) const { const Number i1 = k >> LEAF_BITS; const Number i2 = k & (LEAF_LENGTH - 1); if ((k >> BITS) > 0 || root_[i1] == NULL) { return NULL; } return root_[i1]->values[i2]; } void set(Number k, void* v) { const Number i1 = k >> LEAF_BITS; const Number i2 = k & (LEAF_LENGTH - 1); ASSERT(i1 < ROOT_LENGTH); root_[i1]->values[i2] = v; } bool Ensure(Number start, size_t n) { for (Number key = start; key <= start + n - 1;) { const Number i1 = key >> LEAF_BITS; // Check for overflow if (i1 >= ROOT_LENGTH) return false; // Make 2nd level node if necessary if (root_[i1] == NULL) { //Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf))); //if (leaf == NULL) return false; static ObjectPool<Leaf> leafPool; Leaf* leaf = (Leaf*)leafPool.New(); memset(leaf, 0, sizeof(*leaf)); root_[i1] = leaf; } // Advance key past whatever is covered by this leaf node key = ((key >> LEAF_BITS) + 1) << LEAF_BITS; } return true; } void PreallocateMoreMemory() { // Allocate enough to keep track of all possible pages Ensure(0, 1 << BITS); } };我们这里就对二层的基数树进行解释一下。比如32位平台下,并且固定一页大小为8K,此时页的数目就是2^32 / 2^13= 2^19,因此存储页号最多需要19个比特位。此时传入非类型模板参数的值就是32-13=19。32位平台下指针的大小是4字节,那么存储所有的地址所需要的空间为 2^19 * 4 = 2^21 byte = 2M。整体来说所占用的内存并不算大。64为平台下如果存储全部的地址那么就不太行了,占用的地址太多了。
在二层基数树中,第一层的数组存储19位地址的前五位,第二层的数组存储后14位的地址。全部存储下来也就2M。为什么还要分层呢?因为提供了前五位,从而就可以给很快的给我们筛选出地址所在的区间。当我们在存储映射之前,我们就把2M的空间开出来,后面存储的时候就不会在改变底层的结构!
虽然底层结构不会变了,但是有没有一种可能:某个线程在建立对某一个页读取映射关系时,其他线程刚好也在对该页进行写操作呢(也就是同时对一个页进行读写操作)?答案是不会的!
- 读取时该页的_useCount一定不为0(一定是建立好了的映射)。只在central cache中进行。
- 而建立span映射的都是在_useCount等于0的情况下,也就是central cache向page cache释放span和central cache在向page cache申请span时。只在page cache中进行、
我们再来看一下采用基数数优化后的代码,只需要对_idMapSpan的操作进行修改即可!代码如下:
class PageCache { private: SpanList _spanLists[NPAGES]; //std::unordered_map<PAGE_ID, Span*> _idSpanMap; TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap; }; Span* PageCache::NewSpan(size_t k) { assert(k > 0); // 大于128 page的直接向堆申请 if (k > NPAGES - 1) { //_idSpanMap[span->_pageId] = span; _idSpanMap.set(span->_pageId, span); return span; } // 先检查第k个桶里面有没有span if (!_spanLists[k].Empty()) { // 建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kSpan->_n; ++i) { //_idSpanMap[kSpan->_pageId + i] = kSpan; _idSpanMap.set(kSpan->_pageId + i, kSpan); } return kSpan; } // 检查一下后面的桶里面有没有span,如果有可以把他它进行切分 for (size_t i = k + 1; i < NPAGES; ++i) { if (!_spanLists[i].Empty()) { Span* nSpan = _spanLists[i].PopFront(); //Span* kSpan = new Span; Span* kSpan = _spanPool.New(); // 在nSpan的头部切一个k页下来 // k页span返回 // nSpan再挂到对应映射的位置 kSpan->_pageId = nSpan->_pageId; kSpan->_n = k; nSpan->_pageId += k; nSpan->_n -= k; _spanLists[nSpan->_n].PushFront(nSpan); // 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时 // 进行的合并查找 //_idSpanMap[nSpan->_pageId] = nSpan; //_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan; _idSpanMap.set(nSpan->_pageId, nSpan); _idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan); // 建立id和span的映射,方便central cache回收小块内存时,查找对应的span for (PAGE_ID i = 0; i < kSpan->_n; ++i) { //_idSpanMap[kSpan->_pageId + i] = kSpan; _idSpanMap.set(kSpan->_pageId + i, kSpan); } return kSpan; } } } Span* PageCache::MapObjectToSpan(void* obj) { //PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT); //std::unique_lock<std::mutex> lock(_pageMtx); //auto ret = _idSpanMap.find(id); auto ret = _idSpanMap.find(id); //if (ret != _idSpanMap.end()) //{ // return ret->second; //} //else //{ // assert(false); // return nullptr; //} PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT); auto ret = (Span*)_idSpanMap.get(id); assert(ret != nullptr); return ret; } void PageCache::ReleaseSpanToPageCache(Span* span) { // 对span前后的页,尝试进行合并,缓解内存碎片问题 while (1) { PAGE_ID prevId = span->_pageId - 1; //auto ret = _idSpanMap.find(prevId); 前面的页号没有,不合并了 //if (ret == _idSpanMap.end()) //{ // break; //} auto ret = (Span*)_idSpanMap.get(prevId); if (ret == nullptr) { break; } } // 向后合并 while (1) { PAGE_ID nextId = span->_pageId + span->_n; //auto ret = _idSpanMap.find(nextId); //if (ret == _idSpanMap.end()) //{ // break; //} auto ret = (Span*)_idSpanMap.get(nextId); if (ret == nullptr) { break; } } //_idSpanMap[span->_pageId] = span; //_idSpanMap[span->_pageId+span->_n-1] = span; _idSpanMap.set(span->_pageId, span); _idSpanMap.set(span->_pageId + span->_n - 1, span); }
我们再来测试一下性能,测试的时候我们需要进行相对应的测试。
运行结果如下图:
确实优化后我们自己设计的高并发内存池速度在多线程的情况下比malloc快!
项目源码:HighConcurrencyMemoryPool。感谢阅读ovo~