作者:施晨、尹丰彬、张晓雯、李林杨、黄俊 等
写在前面
本方案已在阿里云线上多个场景落地,将覆盖阿里云官方答疑群聊、研发答疑机器人、钉钉技术服务助手等。线上工单拦截率提升10+%,答疑采纳率70+%,显著提升答疑效率。
本方案最佳实践已上线阿里云官网,详细介绍了使用PAI和向量检索搭建大模型知识库对话的具体操作步骤,开始服务云上客户使用。详见:PAI+向量检索快速搭建大模型知识库对话
全流程代码分模块系统化实现,开源至:https://github.com/aigc-apps/LLM_Solution
一、背景
ChatGPT和通义千问等大语言模型(LLM),凭借其强大的自然语言处理能力,正引领着人工智能技术的革命。但LLM在生成回复时,在“事实性”、“实时性”等方面存在天然的缺陷,很难直接被用于客服、答疑等一些需要精准回答的领域知识型问答场景。因此,如何帮助LLM使用“工具”,借助外部知识库生成准确的回复,成为解决这类问题的钥匙。
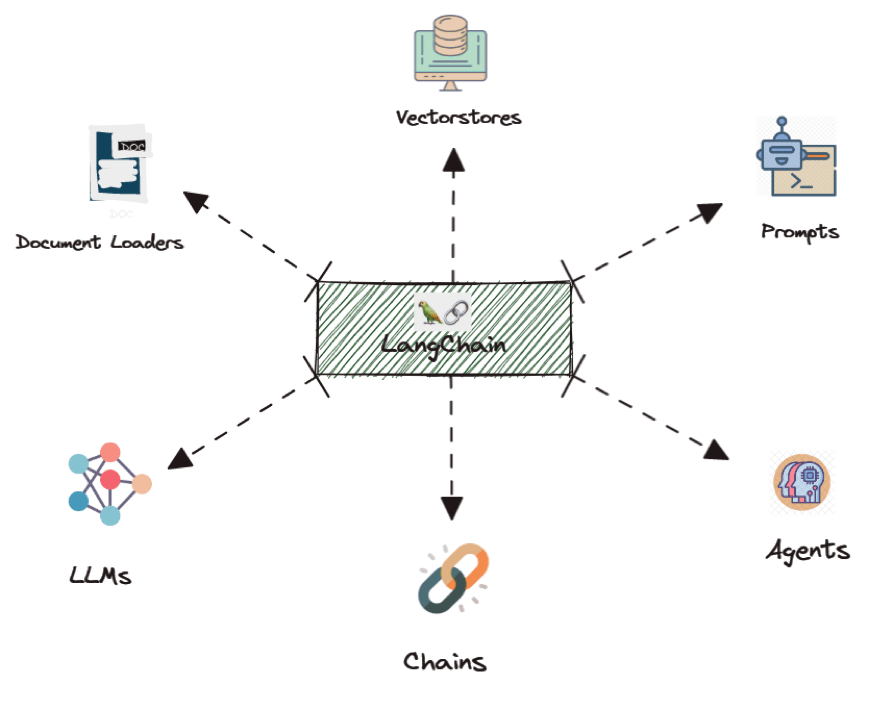
当前业界主流的解决方案是基于 LangChain,进行LLM检索增强并生成回复。其思想是将LLM的能力作为一个模块与其他能力组合,借助向量检索库等模块的检索能力,对用户query进行增强,从而充分利用LLM强大的归纳生成能力,生成符合事实的回复。
LangChain是一套开源框架,可以让AI开发人员将LLM和外部数据结合起来,从而在尽可能少消耗计算资源的情况下,获得更好的性能和效果。通过LangChain将输入的用户知识库文件进行处理,存储在向量检索库中。每次推理时,用户query会先在知识库中查找相近的答案,并将答案与query一起,输入部署好的LLM服务中,从而生成基于知识库的定制答案,解决LLM生成中的“事实性”、“实时性”问题。
下图展示了基于原始的阿里云计算平台产技文档,搭建一套基于大模型检索增强答疑机器人的链路。
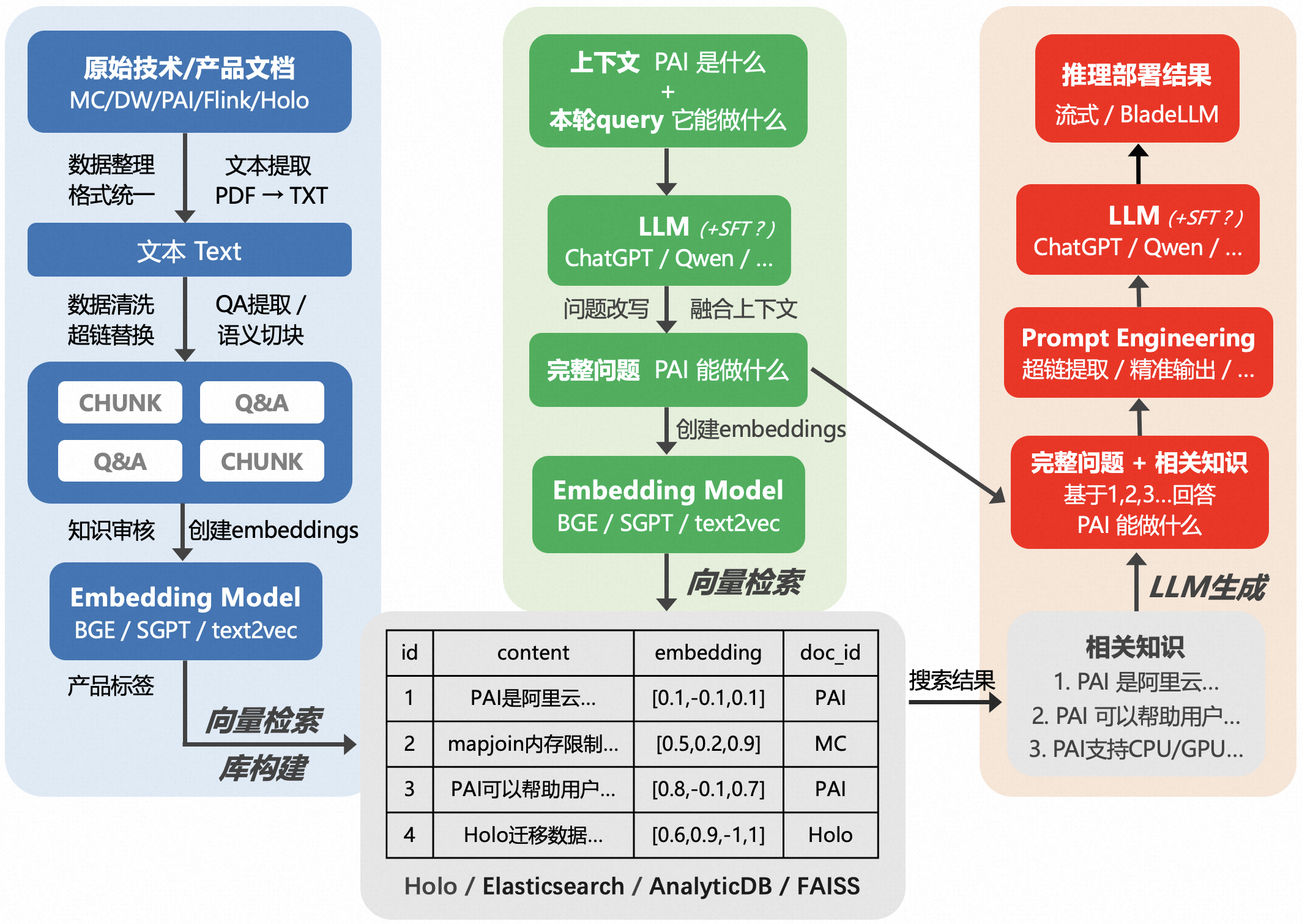
二、模块化
基于LangChain做检索增强的原理较为简单直观,但实际落地应用中会发现,整个流程是一套相对复杂的系统工程,包含如下关键点。
【文本处理】用户的原始知识库格式各式各样,其中文本通常需要经过仔细的清洗与处理,才适合传入向量检索库中用于检索。考虑到大模型输入有长度限制,同时为切分提取出关键信息,需要将清洗后的文本按语义切分为短chunk,或从中提取出QA,再进行后续的Embedding生成。
【Embedding模型】由于在检索增强的链路中,LLM大多只负责检索后的“语句组织与整合”,因此检索本身是否与query强相关,将直接决定最终的生成效果。实际线上经验表明,一个好的Embedding模型,对最终结果带来的影响是决定性的。
【向量检索库】不同向量检索库性能上存在差异,对于不同规模的外部知识库,可以选择与之适应的本地或云上存储方案。
【LLM指令微调】不同种类和规模的LLM,其语句组织能力差异明显。LLM选择时需要平衡模型大小(效果)与推理延迟(性能)。同时考虑是否需要在领域数据上精调(SFT),以提升领域内泛化回复的效果。
【Prompt工程】LLM无视query与检索结果“自由发挥”,或无法精准复现出检索结果中的关键信息,都是LLM生成时常见的问题。通过精心设计的Prompt工程,可以很大概率缓解此类问题。
【推理部署】LLM生成速度太慢是一大瓶颈,在部署为在线推理服务时,可以通过流式输出、BladeLLM加速等技术,加快推理速度,提升用户体验。
下面我们将基于上述流程中的关键点,对各核心模块进行拆解。
三、向量检索库构建
3.1 向量检索库选择
3.1.1 云上数据库产品
用户文档数较多、且有高并发低延时等检索要求时,建议存储在阿里云自研的云上数据库产品。
Hologres
实时数仓Hologres是阿里云自研一站式实时数仓平台,其中向量计算深度集成达摩院Proxima向量计算引擎,提供高吞吐、低延时的向量计算能力,支持向量数据实时写入、实时更新,向量数据写入即可查,索引构建性能、QPS与召回率性能超过开源向量数据库数倍,成为被 OpenAI 和 LangChain 知名大模型社区推荐的向量引擎。支持对接通义千问、ChatGPT、ChatGLM、LLaMA 2等主流大模型,构建企业专属AI问答知识库。在AI问答场景下结合大模型进行高效的知识更新,提升问答的速度与准确度,应用于产品技术支持、智能客服、AI导购、公司企业知识库等场景。
开通Hologres实例并创建数据库。具体操作,请参见购买Hologres。您需要将已创建的数据库名称保存到本地。后续步骤详见这里。
Elasticsearch
阿里云Elasticsearch是基于开源Elasticsearch构建的全托管Elasticsearch云服务,在100%兼容开源功能的同时,支持开箱即用、按需付费。不仅提供云上开箱即用的Elasticsearch、Logstash、Kibana、Beats在内的Elastic Stack生态组件,还与Elastic官方合作提供免费X-Pack(白金版高级特性)商业插件,集成了安全、SQL、机器学习、告警、监控等高级特性,被广泛应用于实时日志分析处理、信息检索、以及数据的多维查询和统计分析等场景。
创建阿里云Elasticsearch实例。具体操作,请参见创建阿里云Elasticsearch实例。后续步骤详见这里。
AnalyticDB
云原生数据仓库AnalyticDB PostgreSQL版是一种大规模并行处理(MPP)数据仓库服务,可提供海量数据在线分析服务。它基于开源项目Greenplum构建,由阿里云深度扩展,兼容ANSI SQL 2003,兼容PostgreSQL/Oracle数据库生态,支持行存储和列存储模式。既提供高性能离线数据处理,也支持高并发在线分析查询,是各行业有竞争力的PB级实时数据仓库方案。
在AnalyticDB PostgreSQL版控制台上创建实例。具体操作,请参见创建实例。后续步骤详见这里。
3.1.2 本地数据库
用户文档数较少、非高频场景,可以考虑使用FAISS等本地数据库方案,轻量级且易于维护。
Faiss
Faiss (Facebook AI Similarity Search) 是FaceBook AI团队开源的针对大规模相似度检索的工具,为稠密向量提供高效相似度搜索和聚类,包含多种搜索任意大小向量集的算法,对10亿量级的索引可以做到毫秒级检索的性能,是目前较成熟的近似近邻搜索库。
使用Faiss构建本地向量库,无需购买线上向量库产品,也免去了线上开通向量库产品的复杂流程,更轻量易用。
3.2 文本处理
在构建向量检索库前,需要对知识库文档进行文本处理。包括数据清洗(文本提取、超链替换等)、语义切块(chunk)、QA提取等。
数据清洗
如果知识库文本较脏或不规范,需要先做些数据清洗,如将PDF提取为txt文本,将文本中的超链接提取出等。处理代码需要根据具体文本形式定制。如源知识库如果是html格式,需要首先按html标题进行切分,保证内容完整性。并对部分文档类别如常见问题,产品简介,发布记录等进行筛选,单独处理等。
语义切块(chunk)
对于非结构化文档,文本将通过TextSplitter被切分为固定大小的chunks,这些chunks将被作为不同的知识条目,用于辅助LLM生成回答。
如果知识库文本较干净或已经过处理,可以直接根据文档中标题语段进行切分,也可使用LangChain提供的语义切块接口CharacterTextSplitter,代码如下:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size, chunk_overlap)
def split_documents(docs):
return text_splitter.split_documents(docs)完成切chunk后,建议为每个chunk生成对应标题或短摘要,方便后续存入向量库时作为查询主键。
QA提取
实际应用中发现,使用QA替代纯文本语块,在向量检索时效果显著更好。因此可基于现有非结构化文本,自动生成一些QA对,并将其embedding化后存入向量库中。
3.3 Embedding模型
这部分根据切分的chunk或提取出的QA,调用开源的embedding模型,以chunk标题或Q生成的embedding作为索引键,chunk或A生成的embedding作为检索值。这里介绍几种常用的开源embedding模型。
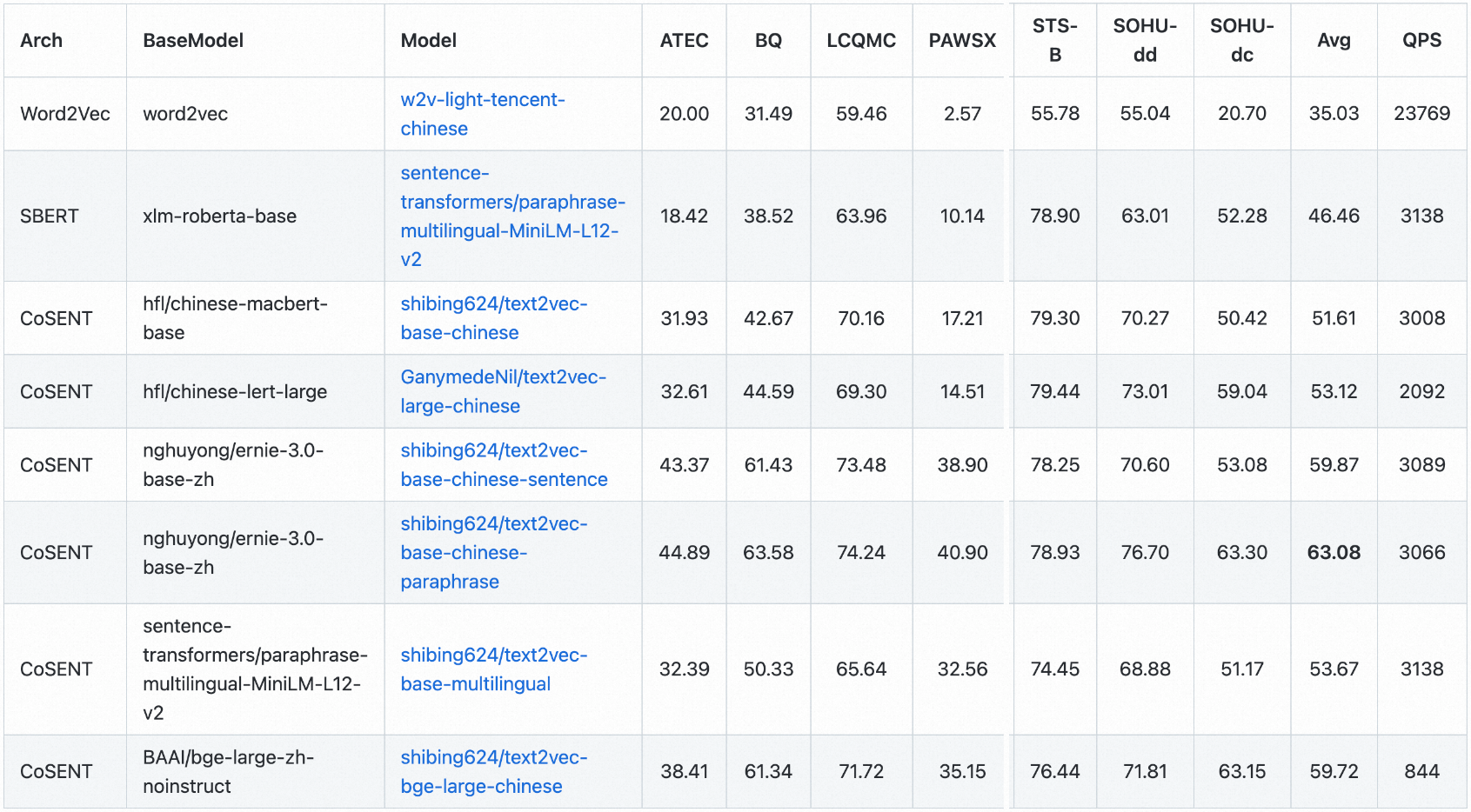
3.3.1 text2vec
text2vec 实现了Word2Vec、RankBM25、BERT、Sentence-BERT、CoSENT等多种文本表征、文本相似度计算模型,并在文本语义匹配(相似度计算)任务上比较了各模型的效果。
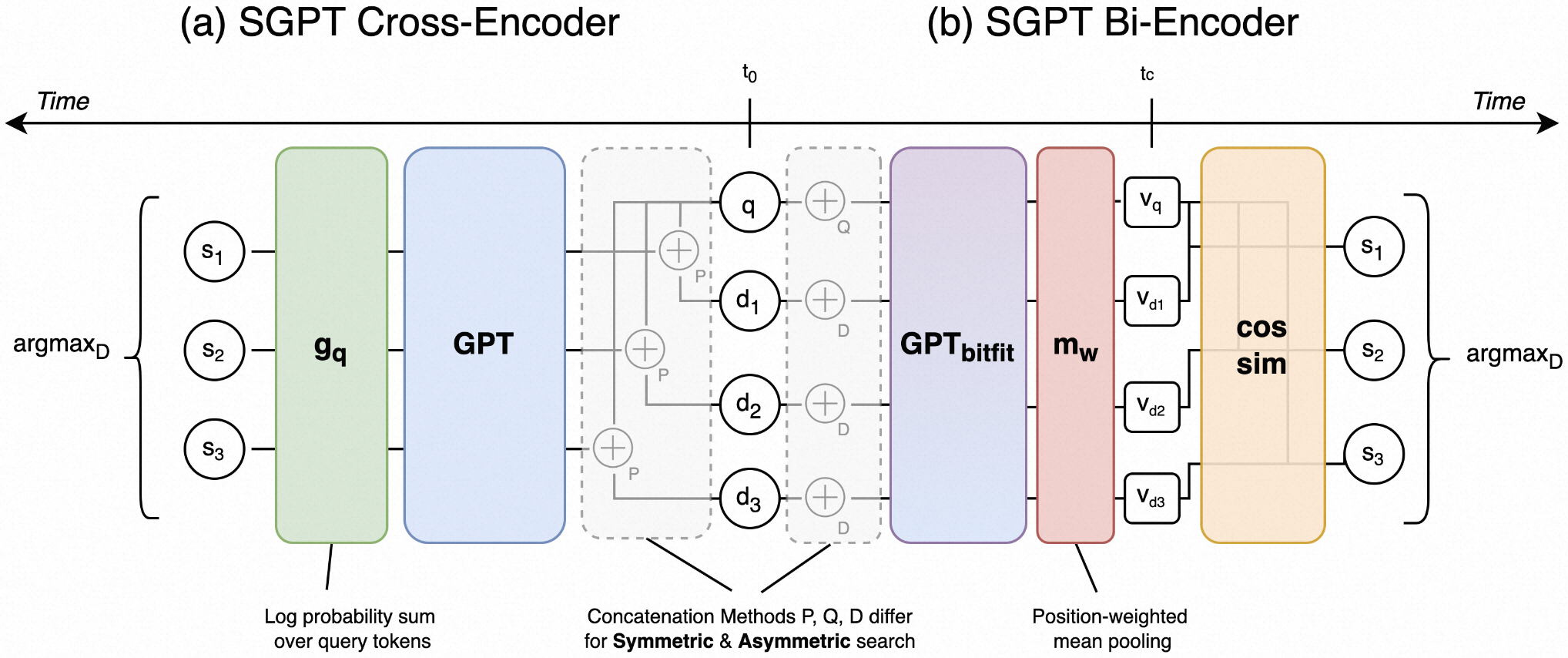
3.3.2 SGPT
SGPT (GPT Sentence Embeddings for Semantic Search) 是一种使用GPT架构生成embedding的方法,模型架构如下,使用 Cross-Encoder 和 Bi-Encoder 两种方式进行嵌入表示学习。
以非对称 Bi-Encoder 的 SGPT 为例,其语义向量检索代码如下:
import torch
from transformers import AutoModel, AutoTokenizer
from scipy.spatial.distance import cosine
# Get our models - The package will take care of downloading the models automatically
# For best performance: Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit
tokenizer = AutoTokenizer.from_pretrained("Muennighoff/SGPT-125M-weightedmean-msmarco-specb-bitfit")
model = AutoModel.from_pretrained("Muennighoff/SGPT-125M-weightedmean-msmarco-specb-bitfit")
# Deactivate Dropout (There is no dropout in the above models so it makes no difference here but other SGPT models may have dropout)
model.eval()
queries = [
"I'm searching for a planet not too far from Earth.",
]
docs = [
"Neptune is the eighth and farthest-known Solar planet from the Sun. In the Solar System, it is the fourth-largest planet by diameter, the third-most-massive planet, and the densest giant planet. It is 17 times the mass of Earth, slightly more massive than its near-twin Uranus.",
"TRAPPIST-1d, also designated as 2MASS J23062928-0502285 d, is a small exoplanet (about 30% the mass of the earth), which orbits on the inner edge of the habitable zone of the ultracool dwarf star TRAPPIST-1 approximately 40 light-years (12.1 parsecs, or nearly 3.7336×1014 km) away from Earth in the constellation of Aquarius.",
"A harsh desert world orbiting twin suns in the galaxy’s Outer Rim, Tatooine is a lawless place ruled by Hutt gangsters. Many settlers scratch out a living on moisture farms, while spaceport cities such as Mos Eisley and Mos Espa serve as home base for smugglers, criminals, and other rogues.",
]
SPECB_QUE_BOS = tokenizer.encode("[", add_special_tokens=False)[0]
SPECB_QUE_EOS = tokenizer.encode("]", add_special_tokens=False)[0]
SPECB_DOC_BOS = tokenizer.encode("{", add_special_tokens=False)[0]
SPECB_DOC_EOS = tokenizer.encode("}", add_special_tokens=False)[0]
def tokenize_with_specb(texts, is_query):
# Tokenize without padding
batch_tokens = tokenizer(texts, padding=False, truncation=True)
# Add special brackets & pay attention to them
for seq, att in zip(batch_tokens["input_ids"], batch_tokens["attention_mask"]):
if is_query:
seq.insert(0, SPECB_QUE_BOS)
seq.append(SPECB_QUE_EOS)
else:
seq.insert(0, SPECB_DOC_BOS)
seq.append(SPECB_DOC_EOS)
att.insert(0, 1)
att.append(1)
# Add padding
batch_tokens = tokenizer.pad(batch_tokens, padding=True, return_tensors="pt")
return batch_tokens
def get_weightedmean_embedding(batch_tokens, model):
# Get the embeddings
with torch.no_grad():
# Get hidden state of shape [bs, seq_len, hid_dim]
last_hidden_state = model(**batch_tokens, output_hidden_states=True, return_dict=True).last_hidden_state
# Get weights of shape [bs, seq_len, hid_dim]
weights = (
torch.arange(start=1, end=last_hidden_state.shape[1] + 1)
.unsqueeze(0)
.unsqueeze(-1)
.expand(last_hidden_state.size())
.float().to(last_hidden_state.device)
)
# Get attn mask of shape [bs, seq_len, hid_dim]
input_mask_expanded = (
batch_tokens["attention_mask"]
.unsqueeze(-1)
.expand(last_hidden_state.size())
.float()
)
# Perform weighted mean pooling across seq_len: bs, seq_len, hidden_dim -> bs, hidden_dim
sum_embeddings = torch.sum(last_hidden_state * input_mask_expanded * weights, dim=1)
sum_mask = torch.sum(input_mask_expanded * weights, dim=1)
embeddings = sum_embeddings / sum_mask
return embeddings
query_embeddings = get_weightedmean_embedding(tokenize_with_specb(queries, is_query=True), model)
doc_embeddings = get_weightedmean_embedding(tokenize_with_specb(docs, is_query=False), model)
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine(query_embeddings[0], doc_embeddings[0])
cosine_sim_0_2 = 1 - cosine(query_embeddings[0], doc_embeddings[1])
cosine_sim_0_3 = 1 - cosine(query_embeddings[0], doc_embeddings[2])
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (queries[0], docs[0][:20] + "...", cosine_sim_0_1))
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (queries[0], docs[1][:20] + "...", cosine_sim_0_2))
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (queries[0], docs[2][:20] + "...", cosine_sim_0_3))3.3.3 BGE
BGE (BAAI General Embedding) 是智源开源的中英文语义向量模型,在3亿条中英文关联文本对上训练。是目前线上表现最好的开源向量模型。
最新开源的BGE v1.5版本,缓解了相似度分布问题,通过对训练数据进行过滤,删除低质量数据,提高训练时温度系数 temperature 至 0.02,使得相似度数值更加平稳。
BGE v1.5包含large、base、small三种尺寸的模型,调用速度差距不大,相比LLM生成时间基本可忽略,因此实际线上使用时可以直接使用 bge-large。使用代码如下:
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)四、LLM训练及推理
4.1 指令微调
4.1.1 LLM选择
在当前检索增强的链路中,LLM大多只负责检索后的“语句组织与整合”,如根据query与相关检索结果的拼接,生成针对query,同时蕴含检索结果的通顺回复。不同种类和规模的LLM,其语句组织能力差异明显。因此LLM选择时,会面临 模型大小(效果)与 推理延迟(性能)之间的平衡。
4.1.2 SFT训练
如果领域内有批量的QA数据,可以选择对LLM进行领域相关的精调(SFT),考虑到原始LLM已具备了需要的语句组织生成能力,这一步不是必须的。可以根据具体场景,结合优缺点判断:
- 优点:SFT可以提升LLM在领域内的知识能力,使其能更好地理解和处理领域相关的知识、术语和上下文,同时对一些检索库中没有相关内容的问题,具有一定的泛化回复能力。
- 缺点:SFT可能引起“灾难性遗忘”,一定程度损害LLM本身的文本组织生成能力,使其基于检索结果的生成效果变差。
如果选择进行SFT训练,可以按照以下步骤准备数据,并使用开源的 DeepSpeed-Chat 框架进行SFT训练。
- 训练样本示例(以ChatGLM2的prompt格式为例)
[Round 1]
问:弹外VVP用户读写Hologres导致JDBC连接数暴涨
答:报错原因:现在VVP Hologres Connector读写Hologres(除了Binlog),默认都使用了JDBC模式,也就是HoloClient,当并发数很高的情况下会占用很多连接。
解决办法:可以加上参数useRpcMode = 'true' 切回至Rpc模式。- 从Github拉取代码并安装运行环境;
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat
pip install -r requirements.txt- 在 training/utils/data/ 目录下的 data_utils.py 和 raw_datasets.py 文件中新增自定义数据集,训练样本示例如上;
- 在 training/step1_supervised_finetuning/training_scripts 目录下新建训练脚本langchain_sft.sh;
OUTPUT=/path/to/save
ZERO_STAGE=2
if [ "$OUTPUT" == "" ]; then
OUTPUT=./output
fi
if [ "$ZERO_STAGE" == "" ]; then
ZERO_STAGE=3
fi
mkdir -p $OUTPUT
deepspeed main.py \
--data_path /path/to/data \
--data_split 10,0,0 \
--model_name_or_path /path/to/chatglm2-6b \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 16 \
--max_seq_len 2048 \
--learning_rate 9.65e-7 \
--weight_decay 0. \
--num_train_epochs 10 \
--save_per_epoch 5 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--num_warmup_steps 100 \
--seed 1234 \
--gradient_checkpointing \
--zero_stage $ZERO_STAGE \
--deepspeed \
--output_dir $OUTPUT \
|& tee $OUTPUT/training.log- 执行sh脚本,开始训练。
cd training/step1_supervised_finetuning/
bash training_scripts/langchain_sft.sh4.1.3 效果评估
训练结束后,可以对SFT后的LLM进行效果评估。传统的NLP文本评价指标包括基于统计的指标,以及基于BERT等预训练模型的指标。基于统计的方法大多基于N-gram词重叠率,如 BLEU (Papineni等人,2002年)、ROUGE (Lin,2004年)、METEOR (Banerjee等人,2005年) 等,被广泛应用于机器翻译和文本摘要等场景。基于预训练模型的指标以 BERTScore (Zhang等人,2019年) 为代表,通过句子相似度计算进行评估,鲁棒性较好。
不过这些传统评估metrics都无法全面衡量出LLM的能力效果。目前主流的LLM评估方法是使用覆盖各类常见任务的人类试题,来检验模型是否具备世界知识(world knowledge),以及解题能力(problem solving)。当前常见的中文LLM Benchmark包括CMMLU、MMCU、C-Eval、GaoKao、SuperCLUE等,英语/多语言LLM Benchmark包括MMLU、HELM、OpenLLM、OpenCompass、MT-bench、AGIEval、BIG-bench等。
下面以 CMMLU 为例,展示其推理与评估步骤。CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。它涵盖了从基础学科到高级专业水平的67个主题,11528道多项选择题,包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用,因此它是一个完全中国化的中文测试基准。
- 从Github拉取代码与数据集;
git clone https://github.com/haonan-li/CMMLU.git
cd CMMLU/script- 修改 CMMLU/script/chatglm.sh 中的模型路径为微调后的模型checkpoint保存路径;
...
--model_name_or_path /path/to/sft_checkpoint \
...- 运行 chatglm.sh 脚本,模型在各项子领域zero-shot、one-shot、...、five-shot上的分数将会输出在终端屏幕上。
bash llama2_7b_chat.sh4.2 Prompt工程
对于不同的专业垂直领域,可以采取不同的prompt策略,以最大化外部知识对LLM的辅助作用。LLM生成时最主要的问题在于其不可控性,包括:LLM无视query与检索结果“自由发挥”,或LLM无法精准复现出检索结果中的关键信息,如超链接、代码等。我们以下述几个场景为例,展示prompt工程构建思路。
场景一:超链接精准提取
方案一:Prompt控制
思路:对检索出来的知识,若内部有网页链接的将其尽可能提取出来,单独将其额外作为知识在此强调。同时若知识存在网页,会在prompt中增加requirement,强调回答的时候“上方提供的知识中可供参考的链接有什么”。需前调上方知识出现的链接,以免出现别的链接。
import re
prompt = '你是一位智能小助手,请根据下面我所提供的相关知识,对我提出的问题进行回答。回答的内容必须包括其定义、特征、应用领域以及相关网页链接等等内容,同时务必满足下方所提的要求!\n 相关知识如下:\n'
for i in range(len(contents)):
if 'http' in contents[i]:
prompt += str(i + 1) + '、该知识中包含网页链接!' + '\n' + contents[i] +'。'+ '\n' + '知识中包含的链接如下:'
pattern = r'([^:]+):(https?://\S+?)(?=\s|$)'
matches = re.findall(pattern, contents[i])
# 将链接和对应名称内容存储到列表中
links = [(name.strip(), url) for name, url in matches]
for name, url in links:
# print("name",name)
# print("url",url)
prompt += '\n' + name + ':' + url + ';'+'\n'
else:
prompt += str(i + 1) + '、' + contents[i] + '\n'
if 'http' in prompt:
requirement = '回答的内容要求:若提供的知识中存在“网页链接”,则必须将“网页链接”准确无误的输出。不需要输出知识库以外的网页链接'
prompt += '\n' + requirement + '\n' + '\n' +'问题是:1.' + query_text[0] + '?' + '2. 上方提供的知识中可供参考的链接有什么' + '?\n'
else:
prompt += '\n' +'问题是:' + query_text[0] + '\n'效果展示
| query: 为什么同一个odps sql任务,运行时间差异很大? |
| 向量检索结果: odps的sql运行时间长怎么办:如何处理慢作业的常见问题_云原生大数据计算服务 MaxCompute-阿里云帮助中心 |
| prompt优化前结果(链接乱贴): 以下是一些可能有助于解决SQL任务运行时间差异问题的建议: 1. 使用数据库连接池: <https://help.aliyun.com/document_detail/278738.html> 2. 使用索引: <https://help.aliyun.com/document_detail/278738.html> 3. 优化SQL代码: <https://help.aliyun.com/document_detail/278738.html> 4. 增加ODPS集群资源: <https://help.aliyun.com/document_detail/278738.html> |
| prompt优化后结果(链接精准透出): 1. 同一个ODPS SQL任务,运行时间差异很大,可能是由于以下原因: - 数据库连接时间:数据库连接时间会直接影响SQL任务的执行时间,如果数据库连接时间较长,则整个SQL任务的执行时间也会相应增加。 - 查询时间: SQL查询时间也会对任务的执行时间产生影响。如果查询时间较长,则整个SQL任务的执行时间也会相应增加。 - 输出数据量:如果SQL任务需要输出大量的数据,则输出数据量也会对任务的执行时间产生影响。 2. 上方提供的知识中可供参考的链接有: -odps的sql运行时间长怎么办:如何处理慢作业的常见问题_云原生大数据计算服务 MaxCompute-阿里云帮助中心 |
案二:Map reduce
借鉴LangChain官方文档中 Map reduce 思想。

思路:对于一个query,从矢量数据库从检索出n条knowledges,将每条知识与query单独输入LLM中,得到仅对这个知识下的answer,最后将n个answer一同merge,作为输出的结果。
场景二:关键信息精准还原生成
输入query后,对于retrieve到的知识的长度,先做一个检查,可设定一个threshold
- 若长度在100个字以内的,就直接让大模型对知识进行打印
- 否则,改变prompt的形式,让其输出变得可控
-
- 首先,先判断知识是否存在http
-
-
- 若有http,则需要LLM准确打印出http,同时结合两者回答
- 若无http,围绕LLM自身知识与知识库内容,进行回答
-
若没找到知识,则直接依靠LLM自身知识进行回答
def process(self, db_res):
contents = []
for reply in db_res:
contents.append(reply)
if len(contents) >=1:
for i in range(len(contents)):
if len(contents[i]) < 100:
prompt = '你是一位智能小助手,请将我提供的内容的原文直接打印出来,不需要你做别的任何解释与分析!\n 内容如下:\n' + contents[i]
else:
if 'http' in contents[i]:
prompt = '你是一位智能小助手,请针对我提出的问题进行回答。' + '\n'\
'为了帮助你更好的解答这个问题,对于该问题,本地的知识库检索到了相关的标准答案。 \n 知识库中的标准答案是如下:\n'
prompt += str(i + 1) + '、' + contents[i] + '。\n' + '现在,要求你,结合知识库的标准答案与自身知识对提出的问题:\n' + query+',进行回答。'+\
'回答的内容要求如下:1.请控制你回答的内容,紧密的围绕知识库中的标准答案进行回答!\n 2.知识库中涉及网页链接,请将该网页链接正确无误的打印出来!'
else:
prompt = '你是一位智能小助手,请针对我提出的问题进行回答。' + '\n'\
'为了帮助你更好的解答这个问题,对于该问题,本地的知识库检索到了相关的标准答案。 \n 知识库中的标准答案是如下:\n'
prompt += str(i + 1) + '、' + contents[i] + '。\n' + '现在,要求你,结合知识库的标准答案与自身知识对提出的问题:\n' + query+',进行回答。'+\
'回答的内容要求如下:1.请控制你回答的内容,紧密的围绕知识库中的标准答案进行回答!'
else:
prompt = '你是一位智能小助手,请根据你自身的知识储备,对我提出的若干问题进行回答。\n' + '\n' + '回答以下问题:' +'\n' + query 效果展示
| query: odps中删除一个项目? |
| 向量检索结果: odps常见咨询【如何删除项目】:删除空间 步骤如下: 运维平台 --> 我的项目 --> 更多 --> 项目下线 请点击 [运维平台](https://tesla.alibaba-inc.com/abm/#/odps/portal/workbench/my_project/list) |
| prompt优化前结果(关键信息不完整,超链接未透出): 要在ODPS中删除一个项目,请按照以下步骤操作:
请注意,删除一个项目后,它将不再存在于您的ODPS账户中,而且所有相关数据和项目文件都将被永久删除。因此,在删除项目之前,请确保备份任何重要数据。 |
| prompt优化后结果(关键信息完整,超链接准确): 针对odps中删除一个项目的问题,根据知识库中的标准答案,可以得知删除项目的步骤如下:
知识库中涉及网页链接为:https://tesla.alibaba-inc.com/abm/#/odps/portal/workbench/my_project/list。 |
场景三:代码&超链接精准提取
若输入query后,检索到答案,对于retrieve到的知识的长度,先做一个检查,可设定一个threshold
- 若长度在100个字以内的,就直接让大模型对知识进行打印
- 否则,改变prompt的形式
-
- 若先判断知识是否存在“命令”
-
-
- 有"命令",则需要LLM准确打印出code,同时结合知识库中的标准答案两者回答
-
-
- 若判断知识是否存在“http”
-
-
- 有“http”, 则需要LLM准确打印出http,同时结合知识库中的标准答案两者回答
-
-
- 否则,若无http与命令,则LLM结合自身知识与标准答案进行回答
若没找到知识,则直接依靠LLM自身知识进行回答
def process(self, db_res):
contents = []
for reply in db_res:
contents.append(reply)
if len(contents) >=1:
for i in range(len(contents)):
if len(contents[i]) < 100:
prompt = '你是一位智能小助手,请将我提供的内容的原文直接打印出来,不需要你做别的任何解释与分析!\n 内容如下:\n' + contents[i]
else:
if '命令' in contents[i]:
prompt = '你是一位智能小助手,请针对我提出的问题进行回答。' + '\n'\
'为了帮助你更好的解答这个问题,对于该问题,本地的知识库检索到了相关的标准答案。 \n 知识库中的标准答案是如下:\n'
prompt += str(i + 1) + '、' + contents[i] + '。\n' + '现在,要求你,结合标准答案与自身知识对提出的问题:\n' + query+',进行回答。'+\
'\n回答的内容要求如下:\n1.请控制你回答的内容,请紧密的围绕标准答案进行回答!\n2.知识库中涉及命令行和代码,请将每一行命令行和代码正确无误的打印出来!'
elif 'http' in contents[i]:
prompt = '你是一位智能小助手,请针对我提出的问题进行回答。' + '\n'\
'为了帮助你更好的解答这个问题,对于该问题,本地的知识库检索到了相关的标准答案。 \n 知识库中的标准答案是如下:\n'
prompt += str(i + 1) + '、' + contents[i] + '。\n' + '请结合标准答案与自身知识对以下提出问题进行回答:\n' + '1.' + query +\
'\n2.标准答案中存在网页链接,要求你将该网页链接地址正确无误的打印出来!'
else:
prompt = '你是一位智能小助手,请针对我提出的问题进行回答。' + '\n'\
'为了帮助你更好的解答这个问题,对于该问题,本地的知识库检索到了相关的标准答案。 \n 知识库中的标准答案是如下:\n'
prompt += str(i + 1) + '、' + contents[i] + '。\n' + '现在,要求你,结合标准答案与自身知识对提出的问题:\n' + query+',进行回答。'+\
'\n回答的内容要求如下:\n1.请控制你回答的内容,请紧密的围绕知识库中的标准答案进行回答!'
else:
prompt = '你是一位智能小助手,请根据你自身的知识储备,对我提出的若干问题进行回答。\n' + '\n' + '回答以下问题:' +'\n' + query 效果展示
| query: odps报错任务运行如何调整优先级? |
| 向量检索结果: odps如何设置作业优先级:设置作业优先级的方式如下:运行......命令示例如下。set odps.instance.priority=values;//values取值为0~9。运行MaxCompute......命令示例如下。bin/odpscmd --config=xxx --project=xxx --instance-priority=x -e ""通过Java SDK设置作业优先级......命令示例如下。import com.aliyun.odps.Instance;import com.aliyun.odps.LogView;import com.aliyun.odps.Odps;import com.aliyun.odps.OdpsException;import com.aliyun.odps.account.Account;import com.aliyun.odps.account.AliyunAccount;import com.aliyun.odps.task.SQLTask;public class OdpsPriorityDemo {public static void main(String args[]) throws OdpsException {Account account = new AliyunAccount("accessId","accessKey");Odps odps = new Odps(account);String odpsUrl = "http://service.odps.aliyun.com/api"; // 公共云URL。odps.setEndpoint(odpsUrl);odps.setDefaultProject("xxxxxxxxxx");SQLTask task = new SQLTask();task.setName("adhoc_sql_task_1");task.setQuery("select count(*) from aa;");Instance instance = odps.instances().create(task, 5); // 5为作业优先级。LogView logView = new LogView(odps);System.out.println(logView.generateLogView(instance, 24)); // 打印Logview,用于查看Instance执行状态,非必须。instance.waitForSuccess(); // 等待Instance执行完成,非必须。}}通过DataWorks......命令示例如下。set odps.instance.priority=x;//x为优先级取值。 |
| prompt优化前结果(代码不完整): 如果odps任务运行时出现报错,可以尝试以下方式调整作业优先级:
set odps.instance.priority=values; //values取值为0~9 其中,values的取值范围为0~9,可以根据具体需求设置。
在DataWorks中,您可以通过以下命令设置作业优先级:set odps.instance.priority=x; //x为优先级取值 其中,x为优先级取值,可以设置为1、3、5、7或8,数值越大,优先级越高。当您通过DataWorks的基线管理功能设置MaxCompute作业优先级时,MaxCompute作业优先级=9-DataWorks基线优先级。 请注意,以上方式可能会影响任务的执行时间和优先级,需要根据具体情况进行调整。 |
| prompt优化后结果(代码完整透出): 针对odps报错任务运行如何调整优先级的问题,根据本地知识库的检索,可以得出以下解答:
- 在odps客户端中,运行以下命令行:set odps.instance.priority=values; //values取值为0~9,设置作业优先级。 - 然后运行MaxCompute客户端并进入Project空间,设置作业优先级。该方式常用于设置临时查询作业的优先级。通过这种方式,可以确保任务在出现错误时能够得到更快的处理。
以上代码可以在odps任务运行时动态调整任务优先级,确保任务能够更优先地运行。 |
4.3 推理部署
4.3.1 PAI-EAS部署在线服务
模型在线服务 PAI-EAS (Elastic Algorithm Service) 是一种模型在线服务平台,可支持您一键部署模型为在线推理服务或AI-Web应用。它提供的弹性扩缩容和蓝绿部署等功能,可以支撑您以较低的资源成本获取高并发且稳定的在线算法模型服务。此外,PAI-EAS还提供了资源组管理、版本控制以及资源监控等功能,方便您将模型服务应用于业务。PAI-EAS适用于实时推理、近实时异步推理等多种AI推理场景,并具备自动扩缩容和完整运维监控体系等能力。
在LLM检索增强链路中,一般需要部署2个PAI-EAS在线服务:
- LangChain主链路服务:其中会调用向量检索,对用户query与向量检索后的结果进行拼接,添加prompt工程,并调用LLM在线推理服务得到回复,后处理后返回给用户
- LLM在线推理服务:根据query和检索结果拼好的prompt,输入LLM后返回结果
部署PAI-EAS在线服务,需要登陆 PAI控制台,进入PAI EAS模型在线服务页面,根据需求配置相关参数,完成部署后即可得到调用地址url与token。
4.3.2 BladeLLM模型加速与流式输出
BladeLLM 是阿里云PAI平台提供的大模型部署框架,支持主流LLM模型结构,并内置模型量化压缩、 BladeDISC编译等优化技术用于加速模型推理。使用BladeLLM的预构建镜像,能够便捷地在PAI-EAS平台部署大模型推理服务。
BladeLLM可以在PAI-EAS上很方便地进行部署。以7B参数规模的模型为例,使用fp16数值精度推理情况下,可以使用 A10 (24GB) 或 V100 (32GB) 规格的单卡GPU实例。服务启动完成,可通过如下方式调用服务,流式地获取生成文本:
import json
from websockets.sync.client import connect
with connect("ws://localhost:8081/generate_stream") as websocket: prompt = "What's the capital of Canada?" websocket.send(json.dumps({
"prompt": prompt,
"sampling_params": {
"temperature": 0.9,
"top_p": 0.9,
"top_k": 50
},
"stopping_criterial":{"max_new_tokens": 100}
}))
while True:
msg = websocket.recv() msg = json.loads(msg) if msg['is_ok']:
if msg['is_finished']: break
print(msg['tokens'][0]["text"], end="", flush=True) print()
print("-" * 40)线上测试,使用BladeLLM加速后的链路延时,RT可加速约40%。同时支持流式文本生成,大幅减少用户等待时间,提升用户体验。
五、WebUI Demo
以下展示根据上述模块化搭建 LangChain 检索增强 LLM 问答的 WebUI Demo,每个模块均在前端中展示并可进行自定义配置。
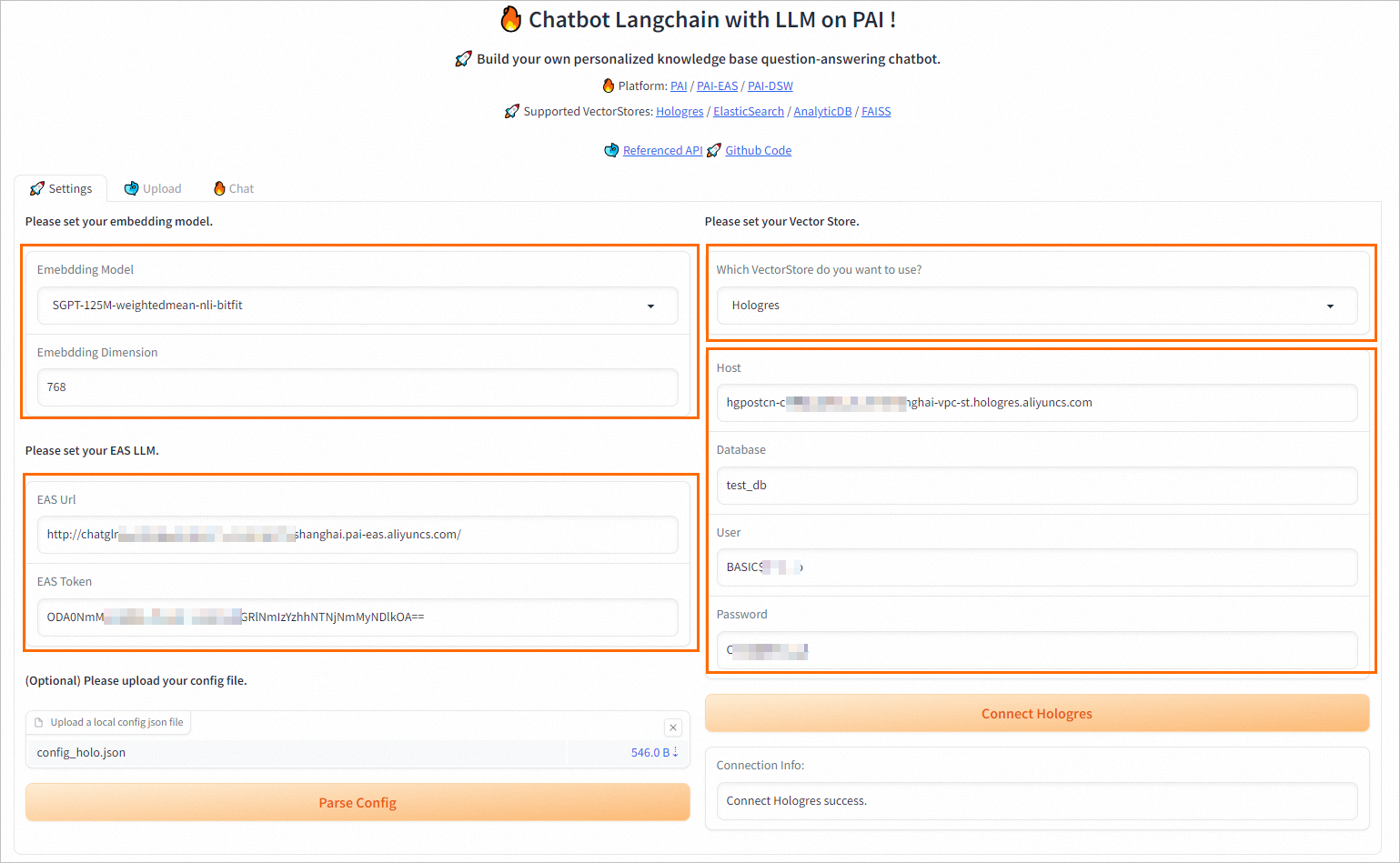
5.1 参数配置界面
支持自定义embedding模型、自选向量检索库与参数配置、在线EAS服务参数配置。
5.2 用户知识上传建库
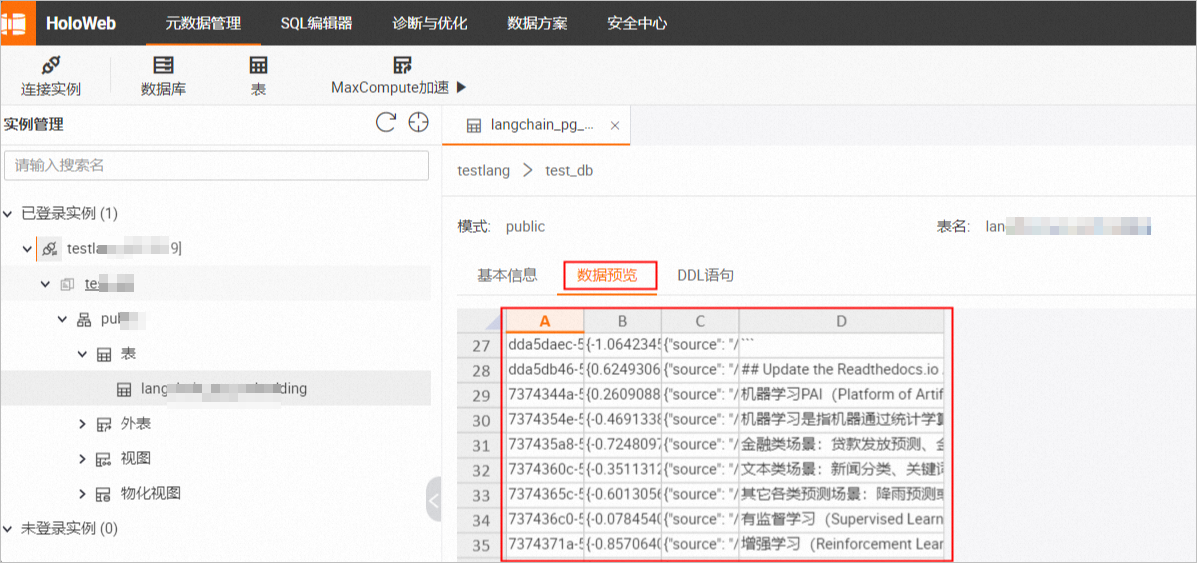
切换到Upload选项卡中,按照界面操作指引上传知识库文件,然后单击Upload。

以Hologres为例,上传成功后,您可以在Hologres数据库中查看写入的数据和向量等信息。具体操作,请参见表。
5.3 多种模式问答
切换到Chat选项卡中,支持 1) 纯向量检索;2) 纯LLM生成;3) LLM检索增强 三种不同模式。选择不同的查询模式,推理效果如下。

六、落地案例
阿里云计算平台大数据产品智能问答系统
传统方案
计算平台中包含了多个大数据产品,这些产品在提供各种能力的同时,也带来了大量答疑问题。传统的方案是基于Elasticsearch进行信息检索,主要存在两个问题:
1、检索面向关键词,缺乏对上下文的理解。
2、强依赖于知识库的建设质量,需要投入大量人力进行语言,交互等细节上的审核工作。
优化方案
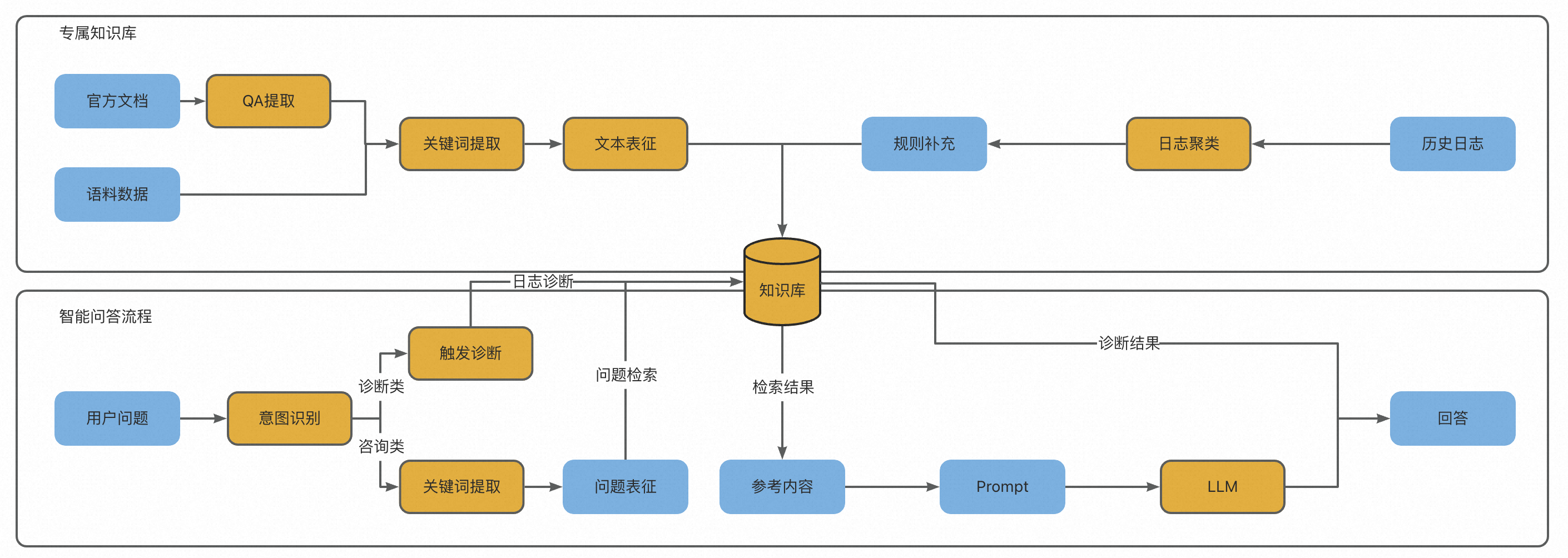
在本项目中,我们致力于借助大模型的知识理解和涌现能力,打造面向计算平台大数据产品的智能问答系统,从而高效且准确地对用户问题进行答疑,降低人工答疑的成本。为了解决在强事实性要求的情况下,大模型容易生成“幻觉”的问题,我们参考了LangChain提供的知识库问答方案,在问题输入时,给模型提供相关知识和限制,使其聚焦在特定的问题中,从而给出更符合要求的回答,同时针对性地使用高质量的业务数据对模型参数进行全量微调,让模型掌握更充分的背景知识。整体系统框架如下:
业务结果
在各算法模块选定和全工程链路落地实现后,我们推动了后续两个阶段的业务试点与效果评估。
研发小二试用
在第一阶段中,让研发小二在解决实际问题的过程中试用模型,并给出相应反馈,辅助我们针对性地对模型进行调优。
在一个月的迭代改进中,我们将问题归为:检索问题、模型总结问题、知识缺失 三类。面向不同类别的问题,我们分别采取了针对性的措施,如调整检索模块,修改prompt模版,加入规则过滤,补充知识库内容等,最终经过一个多月的攻坚,小二采纳率从最初的不到20%提升到了70+%。
线上灰度结果
在第二阶段中,灰度上线,通过真实线上数据变化直观地对模型结果进行检验。主要入口包括:
1) 大数据技术服务助手

2) 研发小蜜答疑机器人

数据表明,在灰度上线的渠道内相比于传统的检索式问答,拦截率提升了10+%,有效地降低了大数据产品的人工答疑成本。
联系我们
我们是阿里云智能-计算平台事业部-机器学习PAI算法团队,在大语言模型相关的各个方向,如LLM检索增强、Continue pretrain、SFT、RLHF、大模型评测、轻量化训练推理等方向上均有技术积累。欢迎对大语言模型相关应用有兴趣的团队一起合作,联系我们,共建各类有价值有落地的应用场景。钉钉群号是 42250004375。