实验内容:参考附录C.1
设计一个简单语言的词法分析程序,要求能够正确处理关键字、运算符(单个符号的和复合的运算符如>、>=)、分界符、标识符、常数等单词,以及不是单词的换行回车、注释。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define _KEY_WORD_END "waiting for your expanding"
typedef struct
{
int typenum;
char *word;
} WORD;
char input[255];
char token[255]="";
int p_input;
int p_token;
int hang=1;//行数
char ch;
bool flag = true; //正常输出
char * rwtab[]= {"begin","if","then","while","do","end",_KEY_WORD_END};
WORD * scaner();
int main()
{
int over=1;
WORD* oneword=new WORD;
printf("Enter Your words(end with #):");
scanf("%[^#]s",input);
p_input=0;
printf("\nYour words:");
printf("\n-------------------------------\n");
printf("% s \n",input);
printf("-------------------------------\n\n");
while(over<1000&&over!=-1)
{
oneword=scaner();//词扫描函数
if(oneword->typenum<1000&&flag)//正常输出
{
printf("line:%d (% d,% s )\n",hang,oneword->typenum,oneword->word);
}
flag=true;//置为默认正常输出
over=oneword->typenum;
}
printf("\npress # to exit:");
scanf("% [^#]s",input);
}
//从输入缓冲区读取一个字符到ch
char m_getchar()
{
ch=input[p_input];
p_input=p_input+1;
return (ch);
}
//去掉空白字符
void getbc()
{
while(ch==' '||ch==10)
{
if(ch=='\n')
hang++;
ch=input[p_input];
p_input=p_input+1;
}
}
//拼接单词
void concat()
{
token[p_token]=ch;
p_token=p_token+1;
token[p_token]='\0';
}
//判断是否为字母
int letter()
{
if(ch>='a'&&ch<='z'||ch>='A'&&ch<='Z')
return 1;
else
return 0;
}
//判断是否为数字
int digit()
{
if(ch>='0'&&ch<='9')
return 1;
else
return 0;
}
//检索关键字表格
int reserve()
{
int i=0;
while(strcmp(rwtab[i],_KEY_WORD_END))
{
if(!strcmp(rwtab[i],token))
return i+1;
i=i+1;
}
return 10;
}
//回退一个字符
void retract()
{
p_input=p_input-1;
}
//数字转化成二进制,未补全
char* dtb()
{
return NULL;
}
//词法扫描程序
WORD* scaner()
{
WORD *myword=new WORD;
myword->typenum=10;
myword->word="";
p_token=0;
m_getchar();
getbc();
if(letter())
{
while(letter()||digit())
{
concat();//拼接单词
m_getchar();//从输入缓冲区读取一个字符到ch
}
retract();//回退一个字符
myword->typenum=reserve();//检索关键字表格
myword->word=token;
return(myword);
}
else if(digit())
{
while(digit())
{
concat();
m_getchar();
}
retract();
myword->typenum=20;
myword->word=token;
return(myword);
}
else if(ch=='/'){
m_getchar();
if(ch=='/'){ //单行注释
while(ch!='\n'){ //如果不是换行
m_getchar();//一直读取下一个字符
}
flag=false;//不输出
retract();//回退字符,不然行数无法++
return(myword);
}
else if(ch=='*'){ //多行注释开始符号
while(1){
m_getchar();//一直读取下一个字符
if(ch=='\n'){
hang++;//读到换行行数++
}
if(ch=='*'){ //多行注释结束符号
m_getchar();
if(ch=='/'){
flag=false;//不输出
return(myword);
}
}
}
}
else{
retract();
myword->typenum=25;
myword->word="/";
return(myword);
}
}
else switch(ch)
{
case '=':
m_getchar();
if(ch=='=')
{
myword->typenum=39;
myword->word="==";
return(myword);
}
retract();
myword->typenum=21;
myword->word="=";
return(myword);
break;
case '+':
myword->typenum=22;
myword->word="+";
return(myword);
break;
case '-':
myword->typenum=23;
myword->word="-";
return(myword);
break;
case '*':
myword->typenum=24;
myword->word="*";
return(myword);
break;
case '(':
myword->typenum=26;
myword->word="(";
return(myword);
break;
case ')':
myword->typenum=27;
myword->word=")";
return(myword);
break;
case '[':
myword->typenum=28;
myword->word="[";
return(myword);
break;
case ']':
myword->typenum=29;
myword->word="]";
return(myword);
break;
case '{':
myword->typenum=30;
myword->word="{";
return(myword);
break;
case '}':
myword->typenum=31;
myword->word="}";
return(myword);
break;
case ',':
myword->typenum=32;
myword->word=",";
return(myword);
break;
case ':':
myword->typenum=33;
myword->word=":";
return(myword);
break;
case ';':
myword->typenum=34;
myword->word=";";
return(myword);
break;
case '>':
m_getchar();
if(ch=='=')
{
myword->typenum=37;
myword->word=">=";
return(myword);
}
retract();
myword->typenum=35;
myword->word=">";
return(myword);
break;
case '<':
m_getchar();
if(ch=='=')
{
myword->typenum=38;
myword->word="<=";
return(myword);
}
retract();
myword->typenum=36;
myword->word="<";
return(myword);
break;
case '!':
m_getchar();
if(ch=='=')
{
myword->typenum=40;
myword->word="!=";
return(myword);
}
retract();
myword->typenum=-1;
myword->word="ERROR";
return(myword);
break;
case '\0':
myword->typenum=1000;
myword->word="OVER";
return(myword);
break;
default:
myword->typenum=-1;
myword->word="ERROR";
return(myword);
}
}
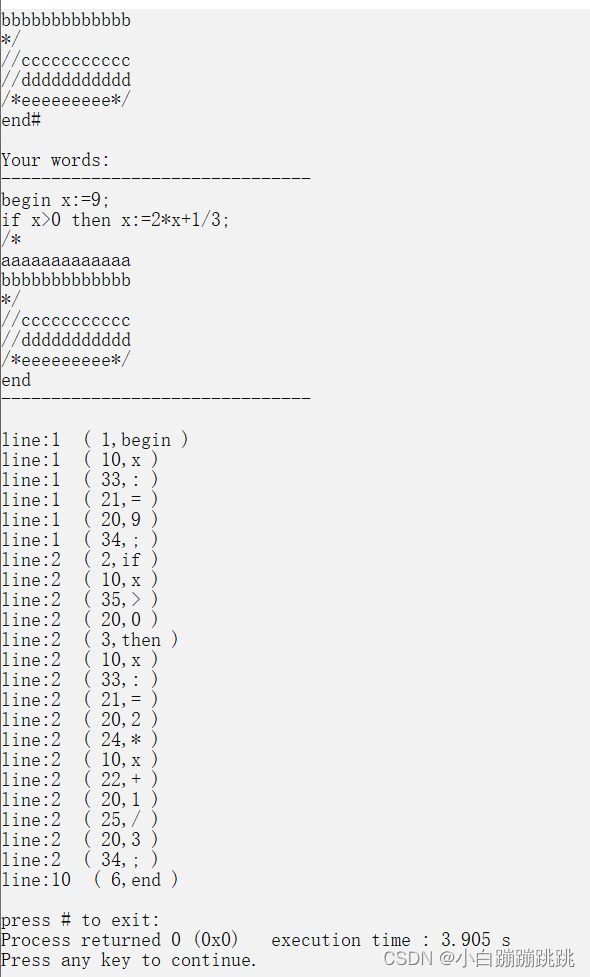
测试数据:
begin x:=9;
if x>0 then x:=2x+1/3;
/
aaaaaaaaaaaaa
bbbbbbbbbbbbb
*/
//ccccccccccc
//ddddddddddd
/eeeeeeeee/
end#
结果: