文章目录
- Linux软件包管理器 - yum
- Linux下安装软件的方式
- yum
- 查找软件包
- 如何实现本地机器和云服务器之间的文件互传
- 卸载软件
- Linux编译器 - gcc/g++
- 程序的翻译过程
- 1.预编译(预处理)
- 2.编译(生成汇编)
- 3.汇编(生成机器可识别代码)
- 4.链接(你写的代码 + C标准库的二进制代码 ==> 生成可执行的二进制程序)
- 解决普通用户无法使用sudo提权
- 静态库与动态库
- 动态链接
- 静态链接:
- debug &&release
- Linux项目自动化构建工具 - make/Makefile
- 依赖关系和依赖方法
- 初步理解makefile的语法
- gcc是怎么知道源文件不需要再编译了呢?
- 为什么执行的指令是make和make clean呢?
- makefile的推导规则
- Makefile的简写
- 缓冲区
- \r和\n
- 倒计时
Linux软件包管理器 - yum
Linux下安装软件的方式
1)下载到程序的源代码,自行进行编译,得到可执行程序。
2)获取rpm安装包,通过rpm命令进行安装。——Linux安装包
3)通过yum进行安装软件。——解决安装源、安装版本、安装依赖
yum
yum是一个在Fedora、RedHat以及CentOS中的前端软件包管理器,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
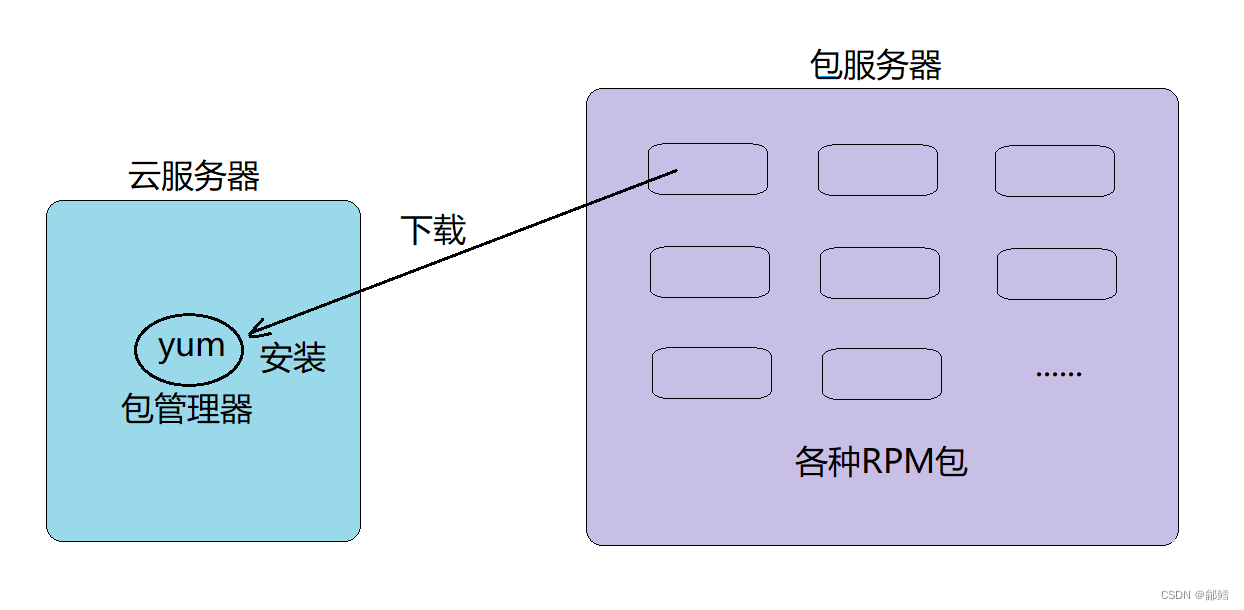
注意:一个服务器同一时刻只允许一个yum进行安装,不能在同一时刻同时安装多个软件。因为yum是从服务器上下载RPM包,所以在下载时必须联网,可以通过ping指令判断当前云服务器是否联网。

查找软件包
通过 yum list 命令可以罗列出当前一共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用 grep 命令只筛选出我们关注的包. 例如:
[cxq@VM-4-10-centos ~]$ yum list |grep lrzsz

注意事项:
- 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
- “x86_64” 后缀表示64位系统的安装包, “i686” 后缀表示32位系统安装包. 选择包时要和系统匹配.
- “el7” 表示操作系统发行版的版本. “el7” 表示的是 centos7/redhat7. “el6” 表示centos6/redhat6.
- 最后一列, os 表示的是 “软件源” 的名称, 类似于 “小米应用商店”, “华为应用商店” 这样的概念.
如何实现本地机器和云服务器之间的文件互传
指令: rz -E
通过该指令可选择需要从本地机器上传到云服务器的文件。
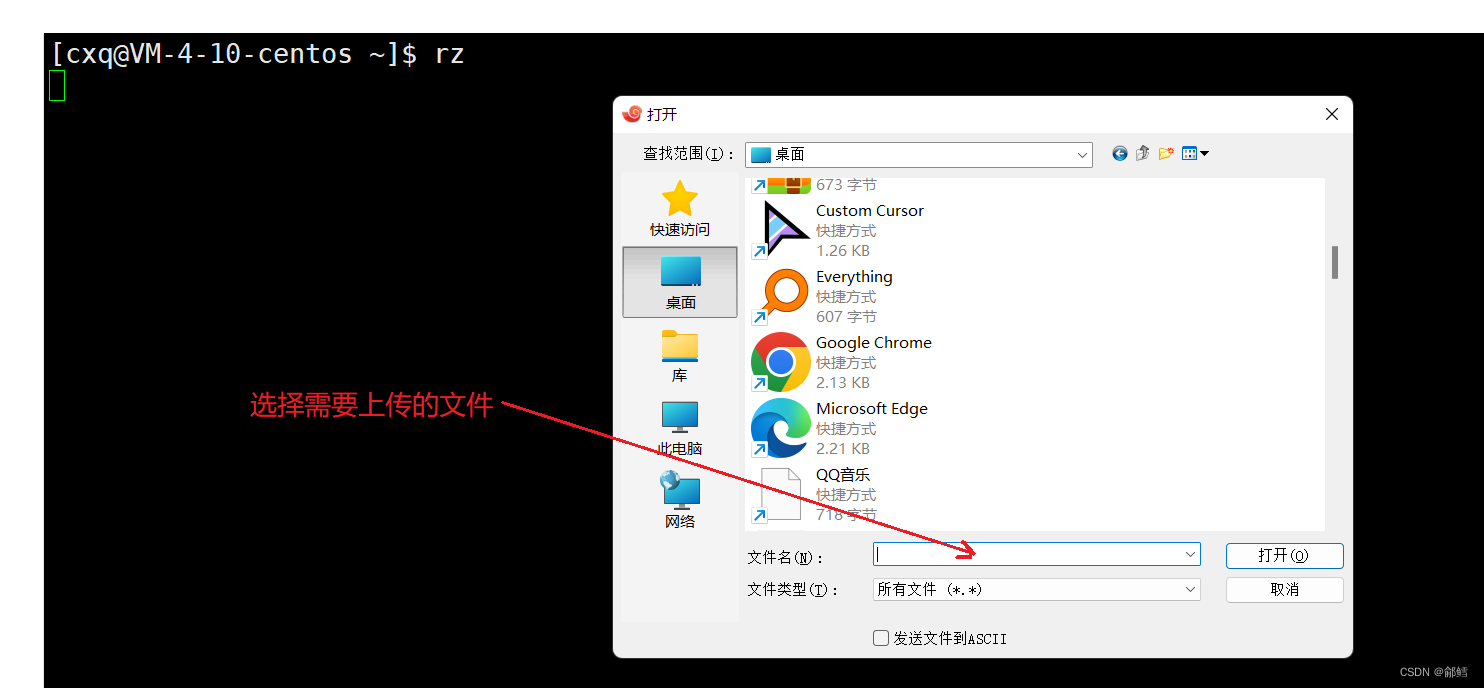
指令: sz 文件名
卸载软件
[root@VM-4-10-centos ~]# yum remove lrzsz.x86_64
yum会自动卸载该软件,这时候输入“y”确认卸载,当出现“complete”字样时,说明卸载完成
Linux编译器 - gcc/g++
程序的翻译过程
1.预编译(预处理)
预处理包含头文件展开,去注释,条件编译,宏替换这四个步骤
指令 gcc -E
[cxq@VM-4-10-centos lesson7]$ gcc -E mycode.c -o mycode.i
-E告诉gcc从现在开始进行程序的编译 ,将预处理工作做完就停下来,不要往后走了!
-o将处理结果输出到指定文件,该选项后需紧跟输出文件名。在这个例子中,-o mycode.i 表示将预处理后的代码输出到名为mycode.i的文件中。
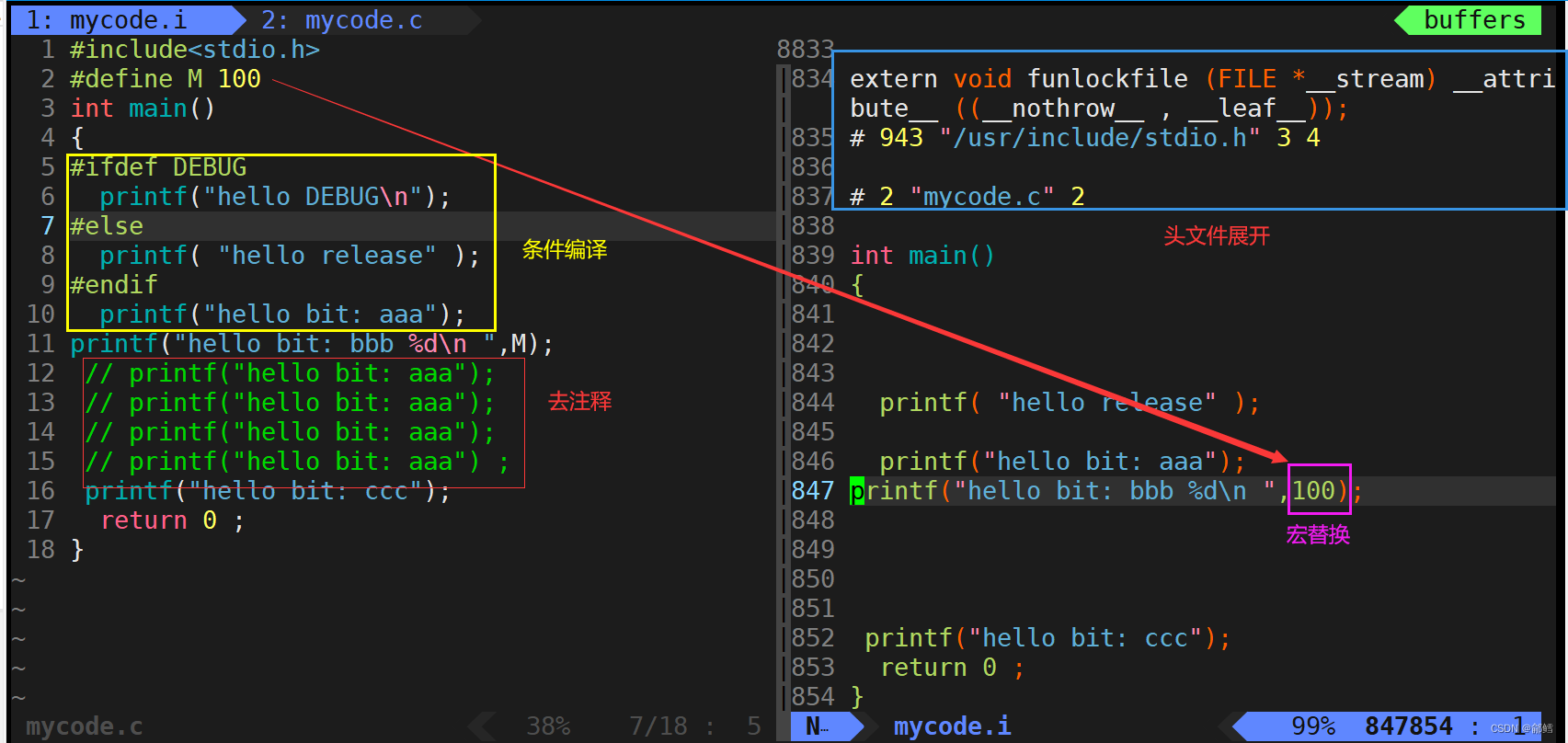
预处理之后的文件中多出来的一大堆代码其实是从Linux中的/usr/include/stdio.h头文件路径下的头文件stdio.h中拷贝过来的,从头文件stdio.h中就可以找到printf函数的声明,具体的实现在C标准函数库里面
总结:
- 预处理功能主要包括头文件展开、去注释、宏替换、条件编译等。
- 预处理指令是以#开头的代码行。
- -E选项的作用是让gcc/g++在预处理结束后停止编译过程。
- -o选项是指目标文件,“xxx.i”文件为已经过预处理的原始程序。
我们为什么能够在windows或者Linux上进行C/C++或者其他形式的开发呢?
我们的系统中一定要提前或者后续安装上,C/C++开发相关的头文件,库文件
C/C++开发环境不仅仅指的是vs,gcc、g++,更重要的是,语言本身的头文件和库文件!
其实我们安装vs2019、vs2022等,我们其实还在安装的时候,选择对应的开发包,同步也在下载c的头文件和库文件
在对编译型语言,安装对应的开发包,必定是下载安装对应的头文件+库文件
2.编译(生成汇编)
-S从现在开始进行程序的翻译,将编译工作做完,就停下来
[cxq@VM-4-10-centos lesson7]$ gcc -S mycode.c -o mycode.s
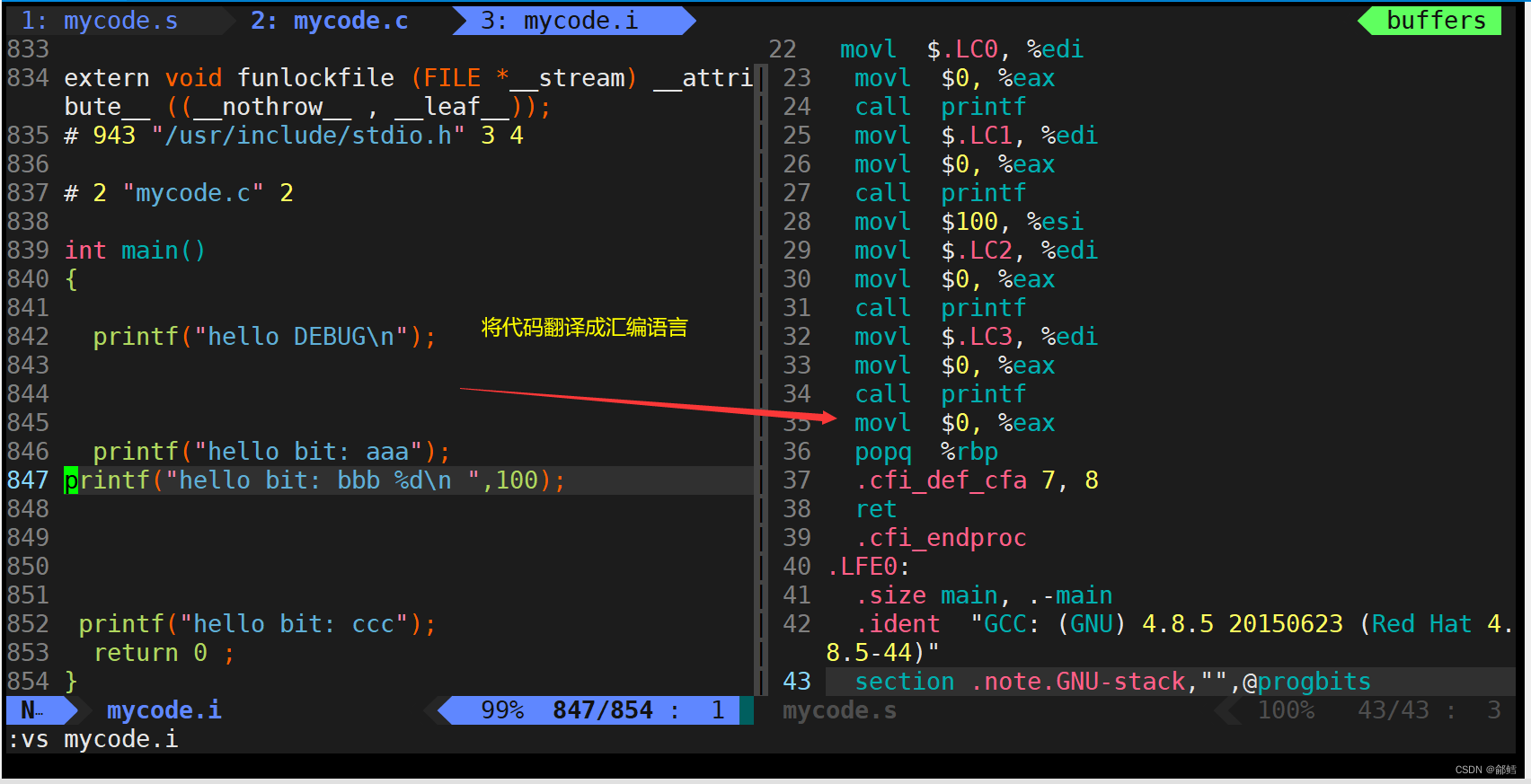
- 在这个阶段中,gcc/g++首先检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,将代码翻译成汇编语言。
- 用户可以使用-S选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
- -o选项是指目标文件,“xxx.s”文件为已经过翻译的原始程序。
3.汇编(生成机器可识别代码)
-c 从现在开始进行程序的翻译,将汇编工作做完,就停下来
[cxq@VM-4-10-centos lesson7]$ gcc -c mycode.s -o mycode.o
[cxq@VM-4-10-centos lesson7]$ od mycode.o//将二进制文件以二进制形式打印到显示器上
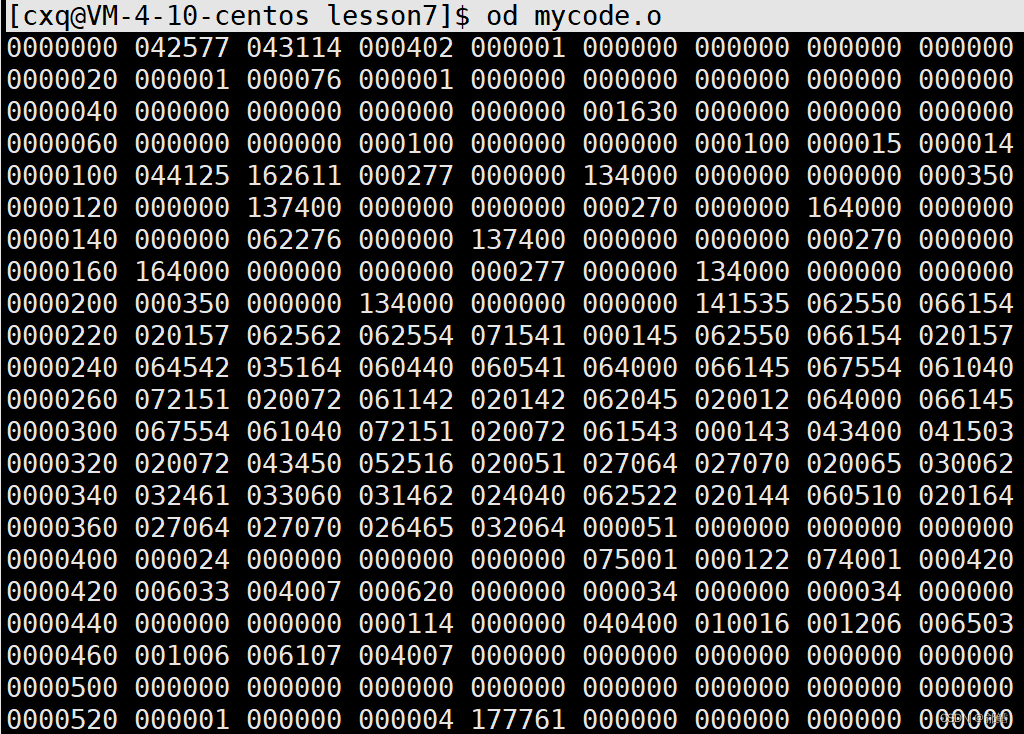
形成的mycode.o文件是可重定位目标二进制文件,简称目标文件,Windows下也有这样的文件 ,在Windows中叫做obj文件
mycode.o这个可重定位目标二进制文件不可以独立执行,虽然已经是二进制了,但是还需要经过链接才能执行
4.链接(你写的代码 + C标准库的二进制代码 ==> 生成可执行的二进制程序)
[cxq@VM-4-10-centos lesson7]$ gcc mycode.o -o mytest//将可重定位目标二进制文件,和库进行链接形成可执行程序
- 在成功完成以上步骤之后,就进入了链接阶段。
- 链接的主要任务就是将生成的各个“xxx.o”文件进行链接,生成可执行文件。
- gcc/g++不带-E、-S、-c选项时,就默认生成预处理、编译、汇编、链接全过程后的文件。
- 若不用-o选项指定生成文件的文件名,则默认生成的可执行文件名为a.out。
注意: 链接后生成的也是二进制文件。
解决普通用户无法使用sudo提权
[root@VM-4-10-centos ~]# vim /etc/sudoers
将用户切换为root,在root中找到/etc/sudoers文件并用vim打开,然后在下面列表中仿照root的格式添加普通用户,最后在底行模式下输入wq!保存并退出
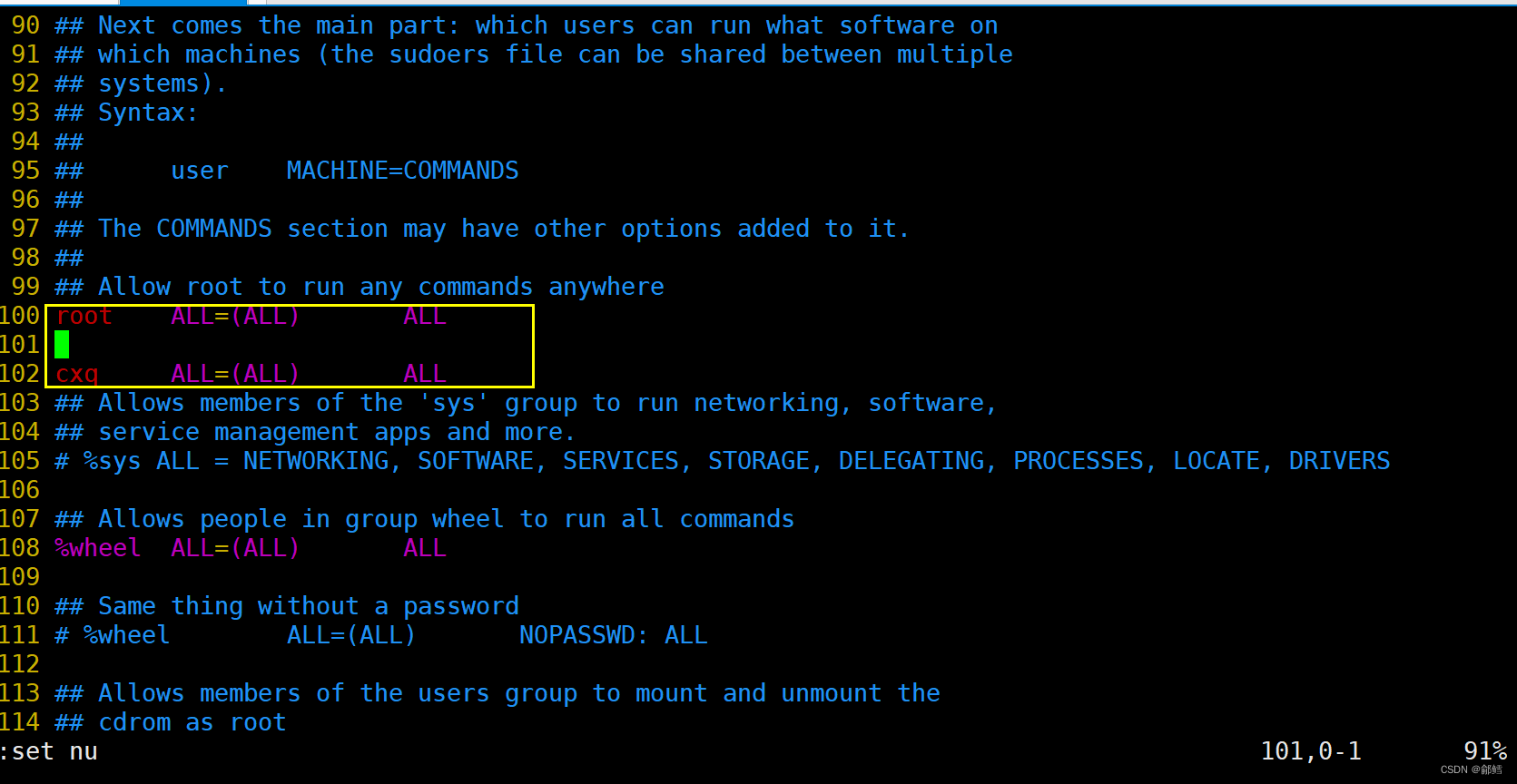
上面步骤完成之后,普通用户也可以使用sudo指令了,因为我们已经将普通用户添加至信任列表了。

静态库与动态库
函数库一般分为静态库和动态库两种:
- 静态库是指编译链接时,把库文件的代码全部加入到可执行文件当中,因此生成的文件比较大,但在运行时也就不再需要库文件了,静态库一般以.a为后缀。
- 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件当中,而是在程序运行时由链接文件加载库,这样可以节省系统的开销,动态库一般以.so为后缀。
总结:
在Linux下库的命名:
动态库:lib作为前缀,.so作为后缀,
静态库:lib作为前缀,.a作为后缀,
去掉前缀和后缀,剩下的就是库名称!
stdio的std就是standard标准的意思
动态链接
优点:省空间(磁盘的空间,内存的空间),体积小,加载速度快。
缺点:依赖动态库,动态库一旦缺失,导致各个程序都无法运行
。
静态链接:
优点:不依赖第三方库,程序的可移植性较高。
缺点:比较消耗磁盘空间,内存空间,网络空间等资源。
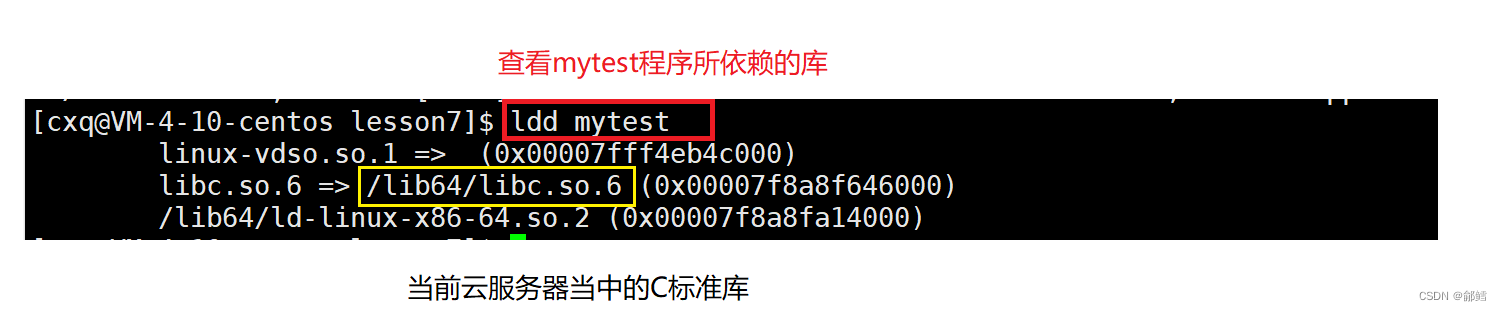
在Linux中,编译形成可执行程序,默认采用的就是动态链接(提供动态库),我们可以使用file指令进行查看。

我们还可以使用ldd指令查看动态链接的可执行文件所依赖的库。
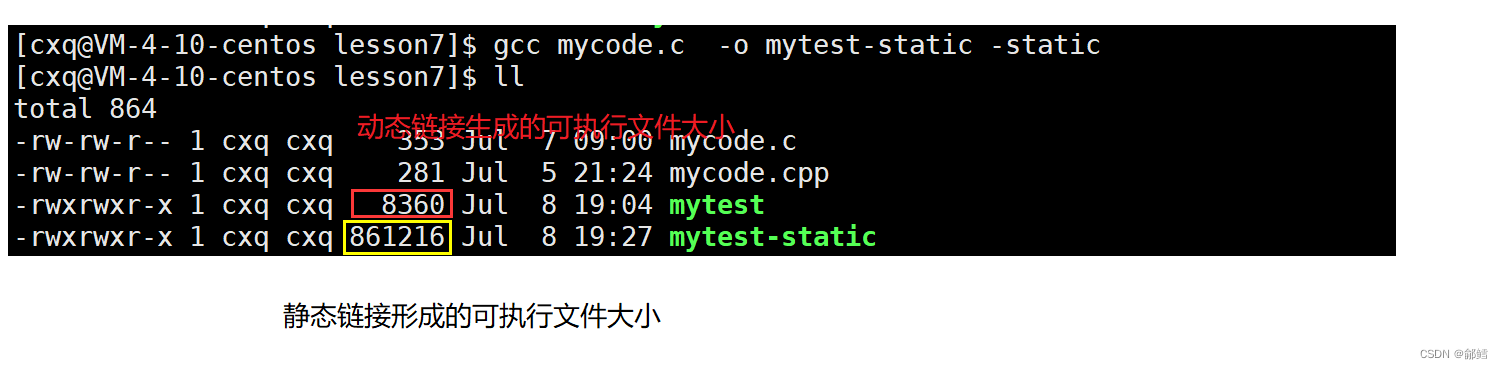
gcc和g++默认采用的是动态链接,在Linux中,如果要按照静态链接的方式,进行形成可执行程序,需要添加-static选项–提供静态库
[cxq@VM-4-10-centos lesson7]$ gcc mycode.c -o mytest-static -static
总结:
1如果我们没有静态库,但是我们就要-static,行不行呢? 不行
2如果我们没有动态库,只有静态库,而且gcc能找到? 能的,gcc默认优先动态链接
3-static的本质:改变优先级,如果加了-static选项,所有的链接要求变成全部变成静态链接
4不一定是纯的全部动态链接或者静态链接,可能是混合的!
扩展:可执行程序形成的时候,不是没有顺序的二进制构成,有自己的格式的,可执行程序有自己的二进制格式,ELF格式
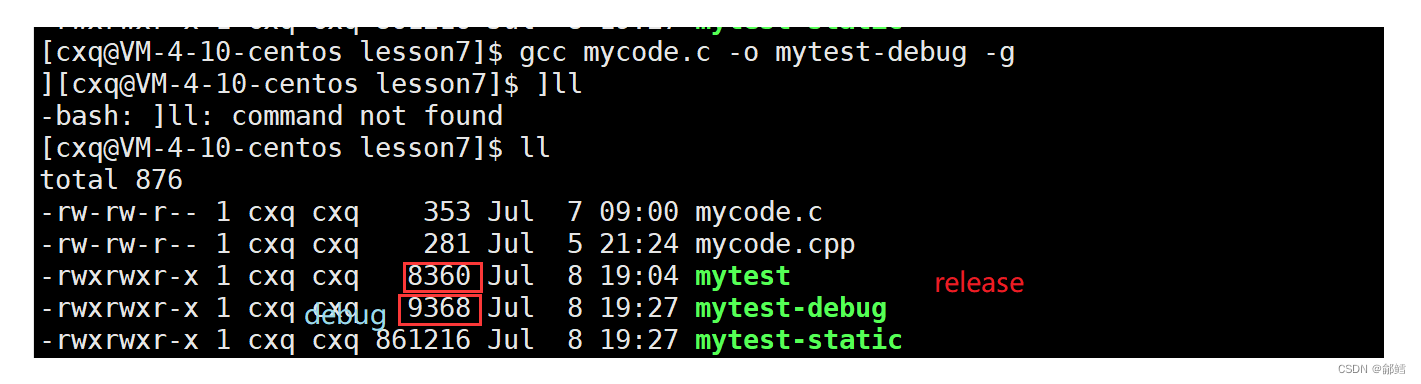
debug &&release
debug可以被追踪调试,在形成可执行程序的时候,添加了debug信息
[cxq@VM-4-10-centos lesson7]$ gcc mycode.c -o mytest-debug -g
[cxq@VM-4-10-centos lesson7]$ readelf -S mytest-debug
Linux项目自动化构建工具 - make/Makefile
make是一条命令,Makefile是一个当前目录下的文件,两个搭配使用,完成项目自动化构建,makefile文件既可以写成makefile,也可以写成Makefile

依赖关系和依赖方法
makefile文件中,要写的是依赖关系和依赖方法,例如生成的可执行程序mycode依赖的就是mycode.c源文件,没有这个源文件,就没有mycode这个可执行程序,生成可执行程序的过程中又依赖方法gcc mycode.c -o mycode也就是需要gcc来编译链接生成可执行程序。

依赖关系: 文件A的变更会影响到文件B,那么就称文件B依赖于文件A
- 例如,mycode文件是由mycode.c文件通过预处理、编译以及汇编之后生成的文件,所以mycode.c文件的改变会影响mycode,所以说mycode文件依赖于mycode.c文件。
依赖方法: 如果文件B依赖于文件A,那么通过文件A得到文件B的方法,就是文件B依赖于文件A的依赖方法
- 例如:mycode依赖于mycode.c,mycode.c 通过 gcc mycode.c -o mycode指令 得到mycode这个可执行程序,那么mycode依赖于mycode.c的依赖方法就是gcc -c -o mycode mycode.c
初步理解makefile的语法

make一次后继续make为什么就不行了? make会根据源文件和源文件生成的可执行程序的新旧,判定是否需要重新执行依赖关系进行编译,从而提供编译效率
如何做到的?
首先我们得清楚一定是源文件形成可执行程序,换句话说先有源文件,才有源文件生成的可执行程序, 所以一般来说,源文件的最近修改时间比源文件生成的可执行程序要新
当我们发现源文件还有bug,我们就会更改源文件,但是历史上曾经还有源文件生成的可执行程序,那么源文件的最近修改时间,一定要比可执行程序要新!
make只需要**比较可执行程序的最近修改时间 和源文件的最近修改时间(Modify)**来判断是否需要重新编译
可执行程序 新于 源文件 ,不需要重新编译
可执行程序 老于 源文件 ,需要重新编译
如果我们想要对应的依赖关系总是被执行? .PHONY (伪目标)
被.PHONY关键字修饰的对象是一个伪目标,该目标总是被执行的。
由于第一条依赖关系和依赖方法没有被.PHONY:修饰,所以如果命令执行过,且源文件没有被改动过的话,make是不允许连续多次执行的,但clean的依赖关系和依赖方法被.PHONY:修饰了,所以它是可以多次执行的
换言之,有了关键字.PHONY:修饰过后,就不要通过对比源文件和可执行程序Modify时间来判断是否能够执行指令了,不走这套规则
gcc是怎么知道源文件不需要再编译了呢?
Modify代表文件内容被修改的时间,Change代表文件属性被修改的时间,Access代表最后一次访问文件的时间
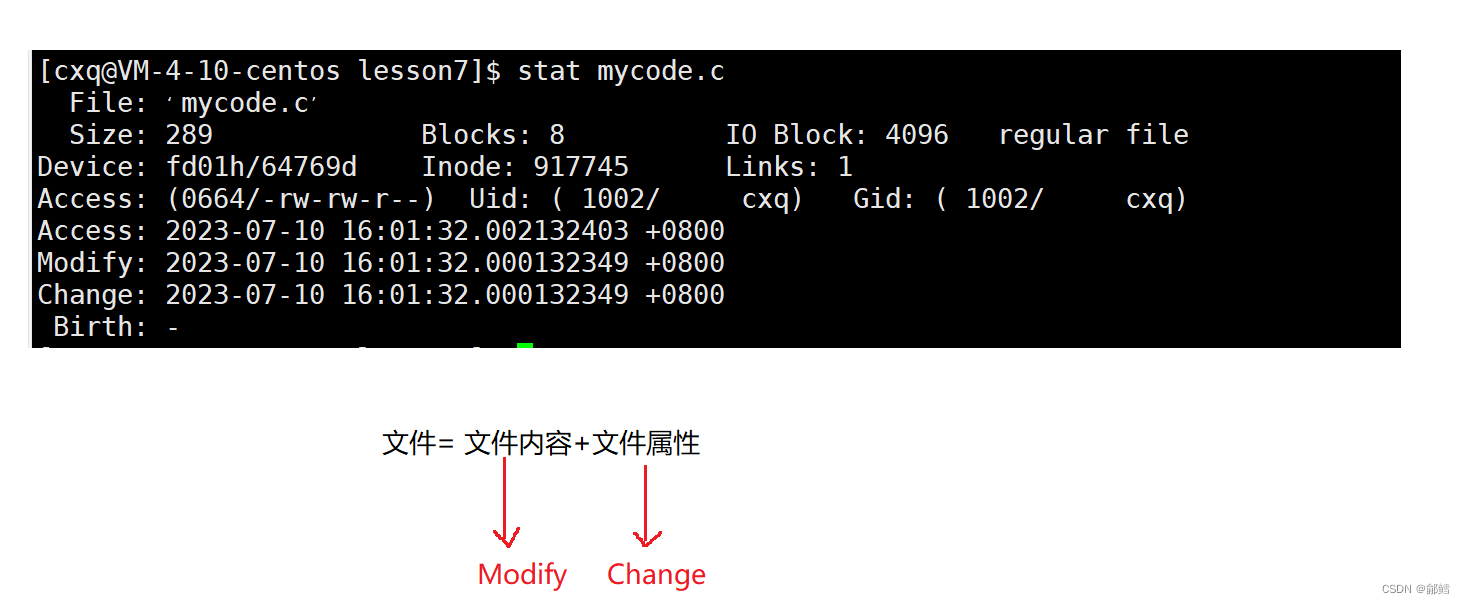
当已经使用make指令过后,无法继续使用时,我们可以用touch,touch后面跟上已存在的文件,可以更新此文件的三个时间,这个时候就又可以用make指令了
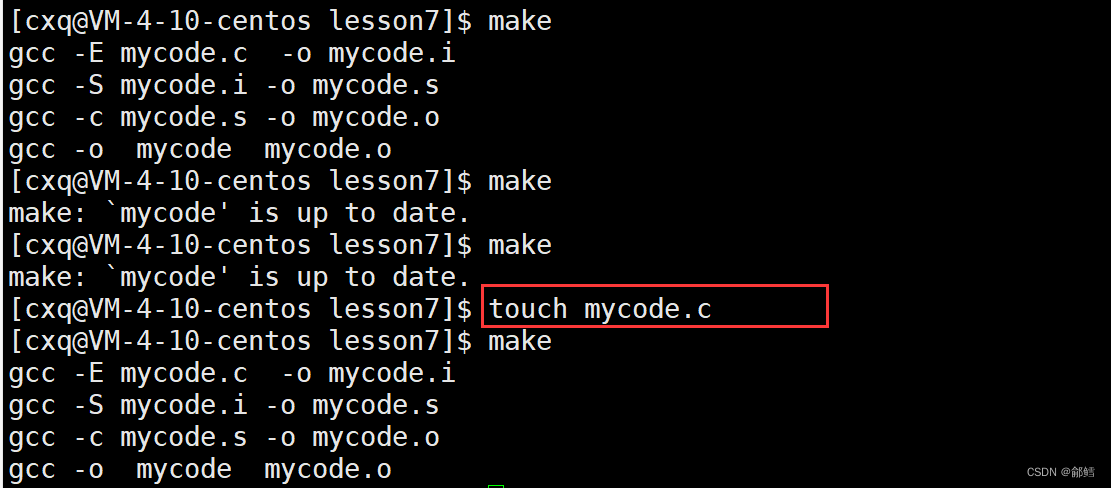
为什么执行的指令是make和make clean呢?
make也可以跟上mycode使用,make默认从上到下扫描文本makefile的时候,第一个扫描到的目标文件可以省略名称使用,例如直接使用make,执行的就是makefile里面的第一个目标文件,并且默认情况下makefile只形成一个目标文件,也就是总目标文件只能有一个。
makefile的推导规则
1 mycode:mycode.o
2 gcc mycode.o -o mycode
3 mycode.o:mycode.s
4 gcc -c mycode.s -o mycode.o
5 mycode.s:mycode.i
6 gcc -S mycode.i -o mycode.s
7 mycode.i:mycode.c
8 gcc -E mycode.c -o mycode.i
9
10 .PHONY:clean
11 clean:
12 rm -f mycode
根据依赖关系列表,make先找mycode,发现没有,那就去找mycode依赖的mycode.o,结果发现也没有,那就去找mycode.o依赖的mycode.s,结果发现还是没有,那就去找mycode.s依赖的mycode.i,结果没找到,那就去找mycode.i依赖的mycode.c结果找到了,那就执行他们之间的依赖方法gcc -E mycode.c -o mycode.i ,然后mycode.i 就有了,然后再一点一点向上执行每条依赖方法
这就是整个make的依赖性,类似于堆栈结构,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件
Makefile的简写
Makefile文件的简写方式:
$@:表示依赖关系中的目标文件(冒号左侧)。
$^:表示依赖关系中的依赖文件列表(冒号右侧全部)。
$<:表示依赖关系中的第一个依赖文件(冒号右侧第一个)。

例如 : $@是冒号左侧的目标文件mycode , $^是mycode.c
缓冲区
缓冲区 :就是由c语言维护的一段内存
代码一:
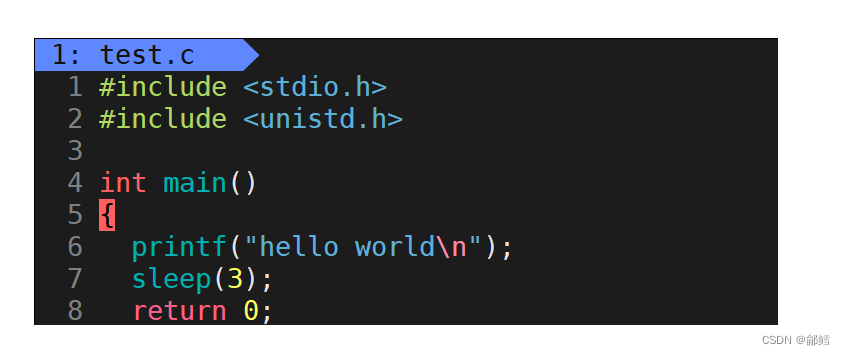
先输出字符串hello world 然后休眠3秒之后结束运行
代码二:
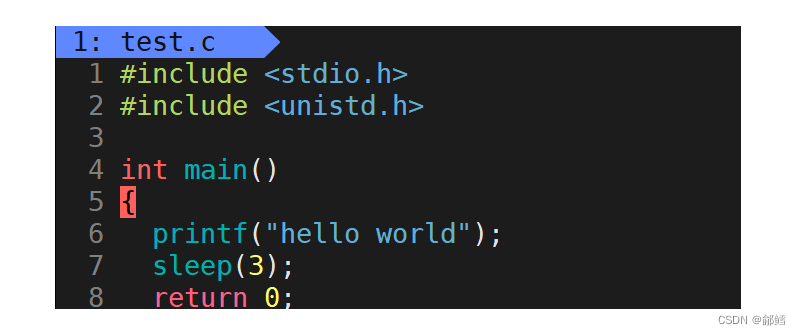
代码中删除了字符串后面的’\n’,结果就截然不同,结果是:先休眠3秒,然后打印字符串hello world之后结束运行。该现象就证明了行缓冲区的存在。
显示器对应的是行刷新,即当缓冲区当中遇到’\n’或是缓冲区被写满才会被打印,代码二中并没有’\n’,所以字符串hello world先被写到缓冲区中,然后休眠3秒后,直到程序运行结束时才将hello world打印到显示器当中。
\r和\n
\r: 回车,使光标回到本行行首。
\n: 换行,使光标下移一格。
倒计时
1: main.c ⮀ ⮂⮂ buffers
1 #include"processBar.h"
2 #include<unistd.h>
3 int main()
4 {
5 //倒计时
6 int count =10 ;
7 while(count>=0 )
8 {
9 printf("%-2d\r",count);
10 fflush (stdout); //刷新数据
11 count --;
12 sleep(1);
13
14 }
15 printf("\n");
16 return 0 ;
17 }


![[Ubuntu 18.04] 搭建文件夹共享之Samba服务器](https://img-blog.csdnimg.cn/f0fd09f6eead4bf5b2116fb3578069fb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBATmV1dGlvbndlaQ==,size_20,color_FFFFFF,t_70,g_se,x_16)